如何进行“自我查询”检索
前往集成查看有关支持自查询的向量存储的文档。
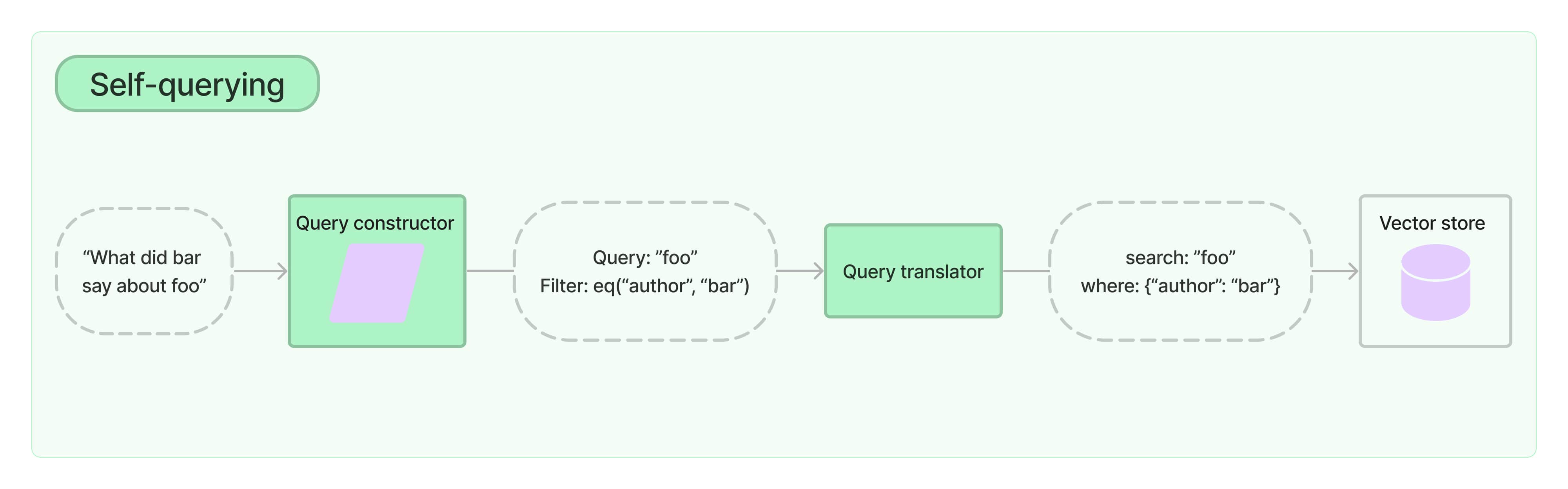
自查询检索器,顾名思义,具有自我查询的能力。具体来说,给定任何自然语言查询,检索器使用查询构建的LLM链来编写结构化查询,然后将该结构化查询应用于其底层的向量存储。这使得检索器不仅可以使用用户输入的查询与存储文档的内容进行语义相似性比较,还可以从用户查询中提取存储文档元数据的过滤器,并执行这些过滤器。
开始使用
为了演示目的,我们将使用一个Chroma向量存储。我们创建了一个包含电影摘要的小型演示文档集。
注意: 自查询检索器要求你安装 lark 包。
%pip install --upgrade --quiet lark langchain-chroma
from langchain_chroma import Chroma
from langchain_core.documents import Document
from langchain_openai import OpenAIEmbeddings
docs = [
Document(
page_content="A bunch of scientists bring back dinosaurs and mayhem breaks loose",
metadata={"year": 1993, "rating": 7.7, "genre": "science fiction"},
),
Document(
page_content="Leo DiCaprio gets lost in a dream within a dream within a dream within a ...",
metadata={"year": 2010, "director": "Christopher Nolan", "rating": 8.2},
),
Document(
page_content="A psychologist / detective gets lost in a series of dreams within dreams within dreams and Inception reused the idea",
metadata={"year": 2006, "director": "Satoshi Kon", "rating": 8.6},
),
Document(
page_content="A bunch of normal-sized women are supremely wholesome and some men pine after them",
metadata={"year": 2019, "director": "Greta Gerwig", "rating": 8.3},
),
Document(
page_content="Toys come alive and have a blast doing so",
metadata={"year": 1995, "genre": "animated"},
),
Document(
page_content="Three men walk into the Zone, three men walk out of the Zone",
metadata={
"year": 1979,
"director": "Andrei Tarkovsky",
"genre": "thriller",
"rating": 9.9,
},
),
]
vectorstore = Chroma.from_documents(docs, OpenAIEmbeddings())
创建我们的自查询检索器
现在我们可以实例化我们的检索器。为此,我们需要提前提供一些关于我们的文档支持的元数据字段的信息以及文档内容的简短描述。
from langchain.chains.query_constructor.schema import AttributeInfo
from langchain.retrievers.self_query.base import SelfQueryRetriever
from langchain_openai import ChatOpenAI
metadata_field_info = [
AttributeInfo(
name="genre",
description="The genre of the movie. One of ['science fiction', 'comedy', 'drama', 'thriller', 'romance', 'action', 'animated']",
type="string",
),
AttributeInfo(
name="year",
description="The year the movie was released",
type="integer",
),
AttributeInfo(
name="director",
description="The name of the movie director",
type="string",
),
AttributeInfo(
name="rating", description="A 1-10 rating for the movie", type="float"
),
]
document_content_description = "Brief summary of a movie"
llm = ChatOpenAI(temperature=0)
retriever = SelfQueryRetriever.from_llm(
llm,
vectorstore,
document_content_description,
metadata_field_info,
)
测试一下
现在我们可以实际尝试使用我们的检索器了!
# This example only specifies a filter
retriever.invoke("I want to watch a movie rated higher than 8.5")
[Document(page_content='Three men walk into the Zone, three men walk out of the Zone', metadata={'director': 'Andrei Tarkovsky', 'genre': 'thriller', 'rating': 9.9, 'year': 1979}),
Document(page_content='A psychologist / detective gets lost in a series of dreams within dreams within dreams and Inception reused the idea', metadata={'director': 'Satoshi Kon', 'rating': 8.6, 'year': 2006})]
# This example specifies a query and a filter
retriever.invoke("Has Greta Gerwig directed any movies about women")
[Document(page_content='A bunch of normal-sized women are supremely wholesome and some men pine after them', metadata={'director': 'Greta Gerwig', 'rating': 8.3, 'year': 2019})]
# This example specifies a composite filter
retriever.invoke("What's a highly rated (above 8.5) science fiction film?")
[Document(page_content='A psychologist / detective gets lost in a series of dreams within dreams within dreams and Inception reused the idea', metadata={'director': 'Satoshi Kon', 'rating': 8.6, 'year': 2006}),
Document(page_content='Three men walk into the Zone, three men walk out of the Zone', metadata={'director': 'Andrei Tarkovsky', 'genre': 'thriller', 'rating': 9.9, 'year': 1979})]
# This example specifies a query and composite filter
retriever.invoke(
"What's a movie after 1990 but before 2005 that's all about toys, and preferably is animated"
)
[Document(page_content='Toys come alive and have a blast doing so', metadata={'genre': 'animated', 'year': 1995})]
筛选 k
我们也可以使用自我查询检索器来指定k:要获取的文档数量。
我们可以通过将enable_limit=True传递给构造函数来实现这一点。
retriever = SelfQueryRetriever.from_llm(
llm,
vectorstore,
document_content_description,
metadata_field_info,
enable_limit=True,
)
# This example only specifies a relevant query
retriever.invoke("What are two movies about dinosaurs")
[Document(page_content='A bunch of scientists bring back dinosaurs and mayhem breaks loose', metadata={'genre': 'science fiction', 'rating': 7.7, 'year': 1993}),
Document(page_content='Toys come alive and have a blast doing so', metadata={'genre': 'animated', 'year': 1995})]
从头开始构建LCEL
要了解内部发生了什么,并拥有更多的自定义控制,我们可以从头开始重建我们的检索器。
首先,我们需要创建一个查询构建链。这个链将接收用户查询并生成一个StructuredQuery对象,该对象捕获用户指定的过滤器。我们提供了一些辅助函数来创建提示和输出解析器。这些函数有许多可调参数,为了简单起见,我们在这里忽略它们。
from langchain.chains.query_constructor.base import (
StructuredQueryOutputParser,
get_query_constructor_prompt,
)
prompt = get_query_constructor_prompt(
document_content_description,
metadata_field_info,
)
output_parser = StructuredQueryOutputParser.from_components()
query_constructor = prompt | llm | output_parser
让我们看看我们的提示:
print(prompt.format(query="dummy question"))
Your goal is to structure the user's query to match the request schema provided below.
<< Structured Request Schema >>
When responding use a markdown code snippet with a JSON object formatted in the following schema:
\`\`\`json
{
"query": string \ text string to compare to document contents
"filter": string \ logical condition statement for filtering documents
}
\`\`\`
The query string should contain only text that is expected to match the contents of documents. Any conditions in the filter should not be mentioned in the query as well.
A logical condition statement is composed of one or more comparison and logical operation statements.
A comparison statement takes the form: `comp(attr, val)`:
- `comp` (eq | ne | gt | gte | lt | lte | contain | like | in | nin): comparator
- `attr` (string): name of attribute to apply the comparison to
- `val` (string): is the comparison value
A logical operation statement takes the form `op(statement1, statement2, ...)`:
- `op` (and | or | not): logical operator
- `statement1`, `statement2`, ... (comparison statements or logical operation statements): one or more statements to apply the operation to
Make sure that you only use the comparators and logical operators listed above and no others.
Make sure that filters only refer to attributes that exist in the data source.
Make sure that filters only use the attributed names with its function names if there are functions applied on them.
Make sure that filters only use format `YYYY-MM-DD` when handling date data typed values.
Make sure that filters take into account the descriptions of attributes and only make comparisons that are feasible given the type of data being stored.
Make sure that filters are only used as needed. If there are no filters that should be applied return "NO_FILTER" for the filter value.
<< Example 1. >>
Data Source:
\`\`\`json
{
"content": "Lyrics of a song",
"attributes": {
"artist": {
"type": "string",
"description": "Name of the song artist"
},
"length": {
"type": "integer",
"description": "Length of the song in seconds"
},
"genre": {
"type": "string",
"description": "The song genre, one of "pop", "rock" or "rap""
}
}
}
\`\`\`
User Query:
What are songs by Taylor Swift or Katy Perry about teenage romance under 3 minutes long in the dance pop genre
Structured Request:
\`\`\`json
{
"query": "teenager love",
"filter": "and(or(eq(\"artist\", \"Taylor Swift\"), eq(\"artist\", \"Katy Perry\")), lt(\"length\", 180), eq(\"genre\", \"pop\"))"
}
\`\`\`
<< Example 2. >>
Data Source:
\`\`\`json
{
"content": "Lyrics of a song",
"attributes": {
"artist": {
"type": "string",
"description": "Name of the song artist"
},
"length": {
"type": "integer",
"description": "Length of the song in seconds"
},
"genre": {
"type": "string",
"description": "The song genre, one of "pop", "rock" or "rap""
}
}
}
\`\`\`
User Query:
What are songs that were not published on Spotify
Structured Request:
\`\`\`json
{
"query": "",
"filter": "NO_FILTER"
}
\`\`\`
<< Example 3. >>
Data Source:
\`\`\`json
{
"content": "Brief summary of a movie",
"attributes": {
"genre": {
"description": "The genre of the movie. One of ['science fiction', 'comedy', 'drama', 'thriller', 'romance', 'action', 'animated']",
"type": "string"
},
"year": {
"description": "The year the movie was released",
"type": "integer"
},
"director": {
"description": "The name of the movie director",
"type": "string"
},
"rating": {
"description": "A 1-10 rating for the movie",
"type": "float"
}
}
}
\`\`\`
User Query:
dummy question
Structured Request:
我们的完整链条产生的结果:
query_constructor.invoke(
{
"query": "What are some sci-fi movies from the 90's directed by Luc Besson about taxi drivers"
}
)
StructuredQuery(query='taxi driver', filter=Operation(operator=<Operator.AND: 'and'>, arguments=[Comparison(comparator=<Comparator.EQ: 'eq'>, attribute='genre', value='science fiction'), Operation(operator=<Operator.AND: 'and'>, arguments=[Comparison(comparator=<Comparator.GTE: 'gte'>, attribute='year', value=1990), Comparison(comparator=<Comparator.LT: 'lt'>, attribute='year', value=2000)]), Comparison(comparator=<Comparator.EQ: 'eq'>, attribute='director', value='Luc Besson')]), limit=None)
查询构造器是自查询检索器的关键元素。要构建一个优秀的检索系统,您需要确保您的查询构造器工作良好。通常这需要调整提示、提示中的示例、属性描述等。有关如何在一些酒店库存数据上优化查询构造器的示例,请查看此烹饪书。
下一个关键元素是结构化查询翻译器。这是负责将通用的StructuredQuery对象转换为向量存储中使用的元数据过滤器的对象。LangChain 提供了许多内置的翻译器。要查看所有翻译器,请前往集成部分。
from langchain_community.query_constructors.chroma import ChromaTranslator
retriever = SelfQueryRetriever(
query_constructor=query_constructor,
vectorstore=vectorstore,
structured_query_translator=ChromaTranslator(),
)
retriever.invoke(
"What's a movie after 1990 but before 2005 that's all about toys, and preferably is animated"
)
[Document(page_content='Toys come alive and have a blast doing so', metadata={'genre': 'animated', 'year': 1995})]
