CT¶
Carlsson 等人 在 Semantic Re-Tuning With Contrastive Tension (CT) (Github) 中提出了一种仅需要句子的无监督学习方法,用于句子嵌入。
背景¶
在训练过程中,CT 构建了两个独立的编码器(“Model1” 和 “Model2”),它们共享初始参数以编码一对句子。如果 Model1 和 Model2 编码相同的句子,那么这两个句子嵌入的点积应该很大。如果 Model1 和 Model2 编码不同的句子,那么它们的点积应该很小。
原 CT 论文使用包含多个小批次的批次。以 K=7 为例,每个小批次由句子对 (S_A, S_A), (S_A, S_B), (S_A, S_C), ..., (S_A, S_H) 组成,相应的标签为 1, 0, 0, ..., 0。换句话说,一对相同的句子被视为正样本,其他不同句子对被视为负样本(即 1 个正样本 + K 个负样本对)。训练目标是生成的相似度分数与标签之间的二元交叉熵。下图(来自 CT 论文的附录 A.1)说明了这一点:
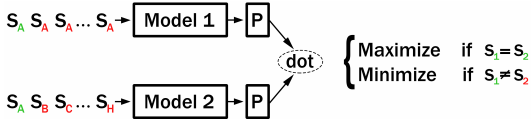
训练后,通常性能更好的 Model2 将被用于推理。
在 CT_Improved 中,我们通过使用批次内负采样对 CT 进行了改进。
性能¶
在一些初步实验中,我们在 STSbenchmark 数据集(使用维基百科的 100 万句子进行训练)和 Quora 重复问题数据集(使用 Quora 的问题进行训练)的释义挖掘任务上比较了性能。
| 方法 | STSb (Spearman) | Quora-Duplicate-Question (平均精度) |
|---|---|---|
| CT | 75.7 | 36.5 |
| CT-Improved | 78.5 | 40.1 |
注意:我们使用了本仓库提供的代码,而不是作者的官方代码。
从句子文件进行 CT 训练¶
train_ct_from_file.py 从提供的文本文件中加载句子。期望该文本文件每行有一个句子。
SimCSE 将使用这些句子进行训练。每隔 500 步将检查点存储到输出文件夹中。
进一步的训练示例¶
train_stsb_ct.py:此示例使用维基百科的 100 万句子进行 CT 训练,并在 STSbenchmark 数据集 上评估性能。
train_askubuntu_ct.py:此示例在 AskUbuntu 问题数据集 上进行训练,该数据集包含 AskUbuntu Stackexchange 论坛的问题。
注意: 这是在 sentence-transformers 中对 CT 的重新实现。有关官方 CT 代码,请参见:FreddeFrallan/Contrastive-Tension。