MLM¶
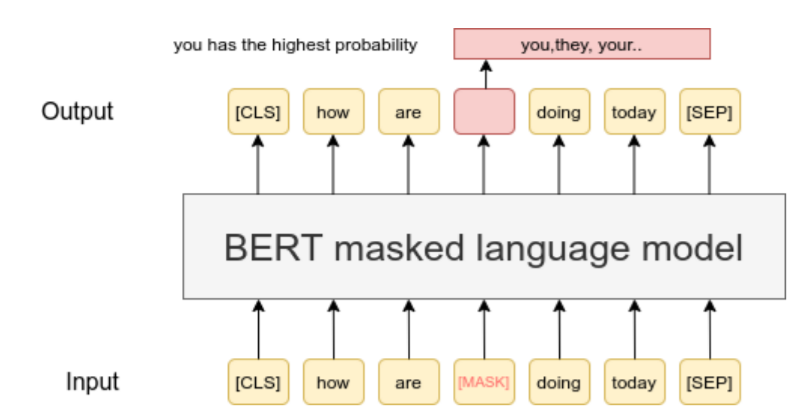
掩码语言模型(Masked Language Model,简称MLM)是BERT预训练的过程。已有研究表明,在自己的数据上继续进行MLM可以提升性能(参见不要停止预训练:适应语言模型到领域和任务)。在我们的TSDAE论文中,我们也展示了MLM是一种强大的预训练策略,适用于学习句子嵌入。当你在某些专业领域工作时,这种情况尤为突出。
**注意:**仅运行MLM不会产生良好的句子嵌入。但你可以首先在你特定领域的数据上使用MLM调整你喜欢的变压器模型。然后,你可以使用你拥有的标注数据或使用其他数据集如NLI、释义或STS对模型进行微调。
运行 MLM¶
train_mlm.py 脚本提供了一个简单的方法来在你的数据上运行MLM。你可以通过以下方式运行此脚本:
python train_mlm.py distilbert-base path/train.txt
你也可以提供一个可选的验证数据集:
python train_mlm.py distilbert-base path/train.txt path/dev.txt
train.txt / dev.txt 中的每一行都被解释为变压器网络的一个输入,即一个句子或段落。
有关如何使用huggingface transformers运行MLM的更多信息,请参见语言模型训练示例。