1. 收集关于2020年奥运会的维基百科数据
这个项目的想法是基于提供的几段文本创建一个问答模型。基于GPT-3模型在回答问题时,当答案包含在段落中时表现良好,但是如果答案不包含在段落中,基础模型往往会尽力回答,通常导致虚构的答案。
为了创建一个只有在有足够上下文的情况下才回答问题的模型,我们首先创建了一个基于文本段落的问题和答案数据集。为了训练模型只在有答案时才回答,我们还添加了对抗性示例,即问题与上下文不匹配的情况。在这些情况下,我们要求模型输出“无法回答问题的足够上下文”。
我们将在三个笔记本中执行这个任务: 1. 第一个(本)笔记本侧重于收集最近的数据,这些数据GPT-3在预训练过程中没有看到。我们选择了2020年奥运会的主题(实际上是在2021年夏季举办),并下载了713个独特页面。我们通过单独的部分组织了数据集,这将作为提问和回答问题的上下文。 2. 第二个笔记本将利用Davinci-instruct根据维基百科的一个部分提出一些问题,并根据该部分回答这些问题。 3. 第三个笔记本将利用上下文、问题和答案对的数据集,另外创建对抗性问题和上下文对,其中问题不是在该上下文中生成的。在这些情况下,模型将被提示回答“无法回答问题的足够上下文”。我们还将训练一个鉴别器模型,用于预测问题是否可以根据上下文回答。
1.1 使用维基百科API进行数据提取
提取数据大约需要半个小时,处理数据可能需要同样的时间。
import pandas as pd
import wikipedia
def filter_olympic_2020_titles(titles):
"""
获取与2020年举办的奥运会相关的标题,给定一个标题列表。
"""
titles = [title for title in titles if '2020' in title and 'olympi' in title.lower()]
return titles
def get_wiki_page(title):
"""
根据标题获取维基百科页面
"""
try:
return wikipedia.page(title)
except wikipedia.exceptions.DisambiguationError as e:
return wikipedia.page(e.options[0])
except wikipedia.exceptions.PageError as e:
return None
def recursively_find_all_pages(titles, titles_so_far=set()):
"""
递归查找所有链接到列表中维基百科标题的页面
"""
all_pages = []
titles = list(set(titles) - titles_so_far)
titles = filter_olympic_2020_titles(titles)
titles_so_far.update(titles)
for title in titles:
page = get_wiki_page(title)
if page is None:
continue
all_pages.append(page)
new_pages = recursively_find_all_pages(page.links, titles_so_far)
for pg in new_pages:
if pg.title not in [p.title for p in all_pages]:
all_pages.append(pg)
titles_so_far.update(page.links)
return all_pages
pages = recursively_find_all_pages(["2020 Summer Olympics"])
len(pages)
909
1.2 过滤维基百科页面并按标题拆分成各个部分
我们移除不太可能包含文本信息的部分,并确保每个部分的长度不超过标记限制。
import re
from typing import Set
from transformers import GPT2TokenizerFast
import numpy as np
from nltk.tokenize import sent_tokenize
tokenizer = GPT2TokenizerFast.from_pretrained("gpt2")
def count_tokens(text: str) -> int:
"""计算字符串中的标记数量"""
return len(tokenizer.encode(text))
def reduce_long(
long_text: str, long_text_tokens: bool = False, max_len: int = 590
) -> str:
"""
将长文本缩减至最多 `max_len` 个令牌,可能会在句子结束处进行截断。
"""
if not long_text_tokens:
long_text_tokens = count_tokens(long_text)
if long_text_tokens > max_len:
sentences = sent_tokenize(long_text.replace("\n", " "))
ntokens = 0
for i, sentence in enumerate(sentences):
ntokens += 1 + count_tokens(sentence)
if ntokens > max_len:
return ". ".join(sentences[:i]) + "."
return long_text
discard_categories = ['See also', 'References', 'External links', 'Further reading', "Footnotes",
"Bibliography", "Sources", "Citations", "Literature", "Footnotes", "Notes and references",
"Photo gallery", "Works cited", "Photos", "Gallery", "Notes", "References and sources",
"References and notes",]
def extract_sections(
wiki_text: str,
title: str,
max_len: int = 1500,
discard_categories: Set[str] = discard_categories,
) -> str:
"""
提取维基百科页面�的部分内容,舍弃参考文献和其他低信息含量的部分。
"""
if len(wiki_text) == 0:
return []
# 查找所有标题及其对应内容
headings = re.findall("==+ .* ==+", wiki_text)
for heading in headings:
wiki_text = wiki_text.replace(heading, "==+ !! ==+")
contents = wiki_text.split("==+ !! ==+")
contents = [c.strip() for c in contents]
assert len(headings) == len(contents) - 1
cont = contents.pop(0).strip()
outputs = [(title, "Summary", cont, count_tokens(cont)+4)]
# 摒弃了传统的丢弃类别,转而采用一种树状结构进行统计
max_level = 100
keep_group_level = max_level
remove_group_level = max_level
nheadings, ncontents = [], []
for heading, content in zip(headings, contents):
plain_heading = " ".join(heading.split(" ")[1:-1])
num_equals = len(heading.split(" ")[0])
if num_equals <= keep_group_level:
keep_group_level = max_level
if num_equals > remove_group_level:
if (
num_equals <= keep_group_level
):
continue
keep_group_level = max_level
if plain_heading in discard_categories:
remove_group_level = num_equals
keep_group_level = max_level
continue
nheadings.append(heading.replace("=", "").strip())
ncontents.append(content)
remove_group_level = max_level
# 统计每个部分的令牌数
ncontent_ntokens = [
count_tokens(c)
+ 3
+ count_tokens(" ".join(h.split(" ")[1:-1]))
- (1 if len(c) == 0 else 0)
for h, c in zip(nheadings, ncontents)
]
# 创建一个包含��以下元素的元组:(标题、章节名称、内容、标记数量)
outputs += [(title, h, c, t) if t<max_len
else (title, h, reduce_long(c, max_len), count_tokens(reduce_long(c,max_len)))
for h, c, t in zip(nheadings, ncontents, ncontent_ntokens)]
return outputs
# 示例页面正在被处理成各个部分
bermuda_page = get_wiki_page('Bermuda at the 2020 Summer Olympics')
ber = extract_sections(bermuda_page.content, bermuda_page.title)
# 示例部分
ber[-1]
('Bermuda at the 2020 Summer Olympics',
'Equestrian',
"Bermuda entered one dressage rider into the Olympic competition by finishing in the top four, outside the group selection, of the individual FEI Olympic Rankings for Groups D and E (North, Central, and South America), marking the country's recurrence to the sport after an eight-year absence. The quota was later withdrawn, following an injury of Annabelle Collins' main horse Joyero and a failure to obtain minimum eligibility requirements (MER) aboard a new horse Chuppy Checker.",
104)
1.2.1 我们创建一个数据集,并过滤掉少于40个标记的部分,因为这些部分可能没有足够的上下文来提出一个好问题。
res = []
for page in pages:
res += extract_sections(page.content, page.title)
df = pd.DataFrame(res, columns=["title", "heading", "content", "tokens"])
df = df[df.tokens>40]
df = df.drop_duplicates(['title','heading'])
df = df.reset_index().drop('index',axis=1) # 重置索引
df.head()
Token indices sequence length is longer than the specified maximum sequence length for this model (1060 > 1024). Running this sequence through the model will result in indexing errors
| title | heading | content | tokens | |
|---|---|---|---|---|
| 0 | 2020 Summer Olympics | Summary | The 2020 Summer Olympics (Japanese: 2020年夏季オリン... | 713 |
| 1 | 2020 Summer Olympics | Host city selection | The International Olympic Committee (IOC) vote... | 126 |
| 2 | 2020 Summer Olympics | Impact of the COVID-19 pandemic | In January 2020, concerns were raised about th... | 369 |
| 3 | 2020 Summer Olympics | Qualifying event cancellation and postponement | Concerns about the pandemic began to affect qu... | 298 |
| 4 | 2020 Summer Olympics | Effect on doping tests | Mandatory doping tests were being severely res... | 163 |
保存部分数据集
我们将保存部分数据集,供下一个笔记本使用。
df.to_csv('olympics-data/olympics_sections.csv', index=False)
1.3(可选)探索数据
df.title.value_counts().head()
Concerns and controversies at the 2020 Summer Olympics 51
United States at the 2020 Summer Olympics 46
Great Britain at the 2020 Summer Olympics 42
Canada at the 2020 Summer Olympics 39
Olympic Games 39
Name: title, dtype: int64
似乎有2020年冬季��和夏季奥运会。尽管我们只对2020年夏季奥运会感兴趣,但我们选择在数据集中保留一些模糊性和噪音。
df.title.str.contains('Summer').value_counts()
True 3567
False 305
Name: title, dtype: int64
df.title.str.contains('Winter').value_counts()
False 3774
True 98
Name: title, dtype: int64
import pandas as pd
from matplotlib import pyplot as plt
df = pd.read_csv('olympics-data/olympics_sections.csv')
df[['tokens']].hist()
# 添加轴描述和标题
plt.xlabel('Number of tokens')
plt.ylabel('Number of Wikipedia sections')
plt.title('Distribution of number of tokens in Wikipedia sections')
plt.show()
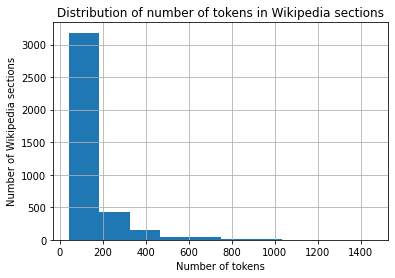
我们可以看到大部分章节都相当短(少于500个标记)。