使用向量嵌入的哲学,通过CQL访问OpenAI和Cassandra / Astra DB
CassIO版本
在这个快速入门中,您将学习如何使用OpenAI的向量嵌入和Apache Cassandra®,或者等效地使用DataStax Astra DB通过CQL,作为数据持久化的向量存储,构建一个“哲学名言查找器和生成器”。
本笔记本的基本工作流程如下所述。您将评估并存储一些著名哲学家的名言的向量嵌入,使用它们构建一个强大的搜索引擎,甚至之后还可以生成新的名言!
该笔记本展示了一些向量搜索的标准使用模式,同时展示了使用Cassandra / Astra DB通过CQL的向量功能有多么容易入门。
有关使用向量搜索和文本嵌入构建问答系统的背景,请查看这个优秀的实践笔记:使用嵌入进行问答。
选择您的框架
请注意,本笔记本使用CassIO库,但我们也涵盖了其他选择的技术来完成相同的任务。查看此文件夹的README以了解其他选项。本笔记本可以作为Colab笔记本或常规Jupyter笔记本运行。
目录: - 设置 - 获取数据库连接 - 连接到OpenAI - 将名言加载到向量存储中 - 用例1:名言搜索引擎 - 用例2:名言生成器 - (可选)利用向量存储中的分区
工作原理
索引
每个引用都被转换为一个嵌入向量,使用OpenAI的Embedding。这些向量被保存在向量存储中,以便以后用于搜索。一些元数据,包括作者的姓名和一些其他预先计算的标签,也被存储在旁边,以允许搜索定制。

搜索
为了找到与提供的搜索引用相似的引用,后者被即时转换为一个嵌入向量,然后使用该向量查询存储以查找相似的向量…即先前索引的相似引用。搜索可以选择性地受到额外元数据的限制(“找到与这个相似的Spinoza的引用��…”)。

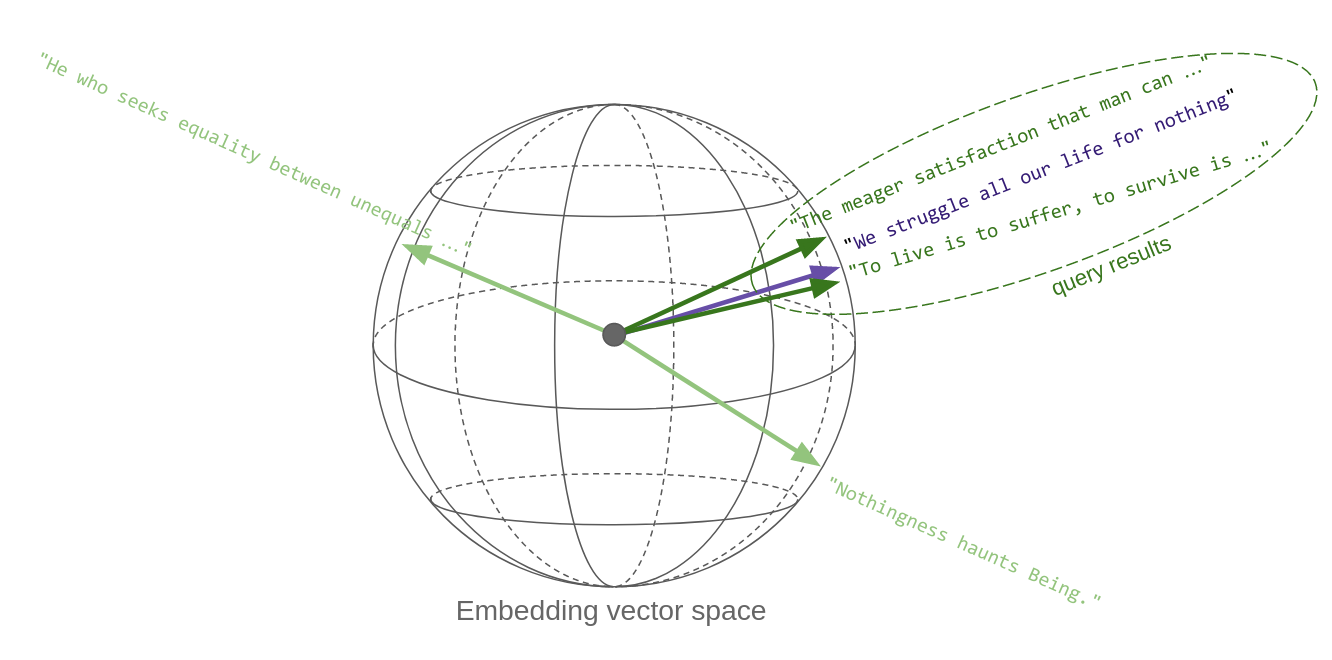
这里的关键点是,“内容相似的引用”在向量空间中转化为彼此在度量上接近的向量:因此,向量相似性搜索有效地实现了语义相似性。这就是向量嵌入如此强大的关键原因。
下面的草图试图传达这个想法。每个引用一旦被转换为一个向量,就是空间中的一个点。嗯,在这种情况下,它在一个球体上,因为OpenAI的嵌入向量,像大多数其他向量一样,被归一化为_单位长度_。哦,这个球实际上不是三维的,而是1536维的!
因此,本质上,向量空间中的相似性搜索返回与查询向量最接近的向量:
生成
给定一个建议(一个主题或一个暂定的引用),执行搜索步骤,并将第一个返回的结果(引用)馈送到LLM提示中,该提示要求生成模型根据传递的示例和初始建议创造一段新文本。

设置
首先安装一些必需的包:
!pip install --quiet "cassio>=0.1.3" "openai>=1.0.0" datasets
from getpass import getpass
from collections import Counter
import cassio
from cassio.table import MetadataVectorCassandraTable
import openai
from datasets import load_dataset
获取数据库连接
要通过CQL连接到您的Astra DB,您需要两样东西: -
一个带有角色“数据库管理员”的令牌(看起来像 AstraCS:...) -
数据库ID(看起来像 3df2a5b6-...)
确保您拥有这两个字符串–这些字符串在您登录后在Astra UI中获得。有关更多信息,请参见这里:数据库ID 和 令牌。
如果您想要_连接到一个Cassandra集群_(但是必须支持矢量搜索),请将
cassio.init(session=..., keyspace=...)
替换为适合您集群的Session和keyspace名称。
astra_token = getpass("Please enter your Astra token ('AstraCS:...')")
database_id = input("Please enter your database id ('3df2a5b6-...')")
Please enter your Astra token ('AstraCS:...') ········
Please enter your database id ('3df2a5b6-...') 01234567-89ab-dcef-0123-456789abcdef
cassio.init(token=astra_token, database_id=database_id)
创建数据库连接
这是通过CQL连接到Astra DB的方法:
(顺便提一下,您也可以通过更改以下Cluster实例化的参数来连接到任何提供Vector功能的Cassandra集群,具体操作请参考更改参数。)
通过CassIO 创建向量存储
您需要一个支持向量并带有元数据的表。将其命名为”philosophers_cassio”:
v_table = MetadataVectorCassandraTable(table="philosophers_cassio", vector_dimension=1536)
连接到OpenAI
设置您的秘钥
OPENAI_API_KEY = getpass("Please enter your OpenAI API Key: ")
Please enter your OpenAI API Key: ········
获取嵌入向量的测试调用
快速检查如何获取一组输入文本的嵌入向量:
client = openai.OpenAI(api_key=OPENAI_API_KEY)
embedding_model_name = "text-embedding-3-small"
result = client.embeddings.create(
input=[
"This is a sentence",
"A second sentence"
],
model=embedding_model_name,
)
注意:以上是针对OpenAI v1.0+的语法。如果使用之前的版本,获取嵌入向量的代码会有所不同。
print(f"len(result.data) = {len(result.data)}")
print(f"result.data[1].embedding = {str(result.data[1].embedding)[:55]}...")
print(f"len(result.data[1].embedding) = {len(result.data[1].embedding)}")
len(result.data) = 2
result.data[1].embedding = [-0.010821706615388393, 0.001387271680869162, 0.0035479...
len(result.data[1].embedding) = 1536
将报价加载到向量存储中
注意:以上是针对OpenAI v1.0+的语法。如果使用之前的版本,获取嵌入向量的代码会有所不同。
philo_dataset = load_dataset("datastax/philosopher-quotes")["train"]
快速检查:
print("An example entry:")
print(philo_dataset[16])
An example entry:
{'author': 'aristotle', 'quote': 'Love well, be loved and do something of value.', 'tags': 'love;ethics'}
检查数据集大��小:
author_count = Counter(entry["author"] for entry in philo_dataset)
print(f"Total: {len(philo_dataset)} quotes. By author:")
for author, count in author_count.most_common():
print(f" {author:<20}: {count} quotes")
Total: 450 quotes. By author:
aristotle : 50 quotes
schopenhauer : 50 quotes
spinoza : 50 quotes
hegel : 50 quotes
freud : 50 quotes
nietzsche : 50 quotes
sartre : 50 quotes
plato : 50 quotes
kant : 50 quotes
将引用插入向量存储
您将计算引用的嵌入并将其保存到向量存储中,同时保存文本本身和以后使用的元数据。请注意,作者将作为元数据字段与引用本身已经找到的“标签”一起添加。
为了优化速度并减少调用次数,您将对嵌入OpenAI服务执行批量调用。
(注意:为了更快的执行速度,Cassandra和CassIO可以让您执行并发插入,但我们在这里没有这样做,以便提供更简单的演示代码。)
BATCH_SIZE = 50
num_batches = ((len(philo_dataset) + BATCH_SIZE - 1) // BATCH_SIZE)
quotes_list = philo_dataset["quote"]
authors_list = philo_dataset["author"]
tags_list = philo_dataset["tags"]
print("Starting to store entries:")
for batch_i in range(num_batches):
b_start = batch_i * BATCH_SIZE
b_end = (batch_i + 1) * BATCH_SIZE
# 计算这一批数据的嵌入向量
b_emb_results = client.embeddings.create(
input=quotes_list[b_start : b_end],
model=embedding_model_name,
)
# 准备插入的行
print("B ", end="")
for entry_idx, emb_result in zip(range(b_start, b_end), b_emb_results.data):
if tags_list[entry_idx]:
tags = {
tag
for tag in tags_list[entry_idx].split(";")
}
else:
tags = set()
author = authors_list[entry_idx]
quote = quotes_list[entry_idx]
v_table.put(
row_id=f"q_{author}_{entry_idx}",
body_blob=quote,
vector=emb_result.embedding,
metadata={**{tag: True for tag in tags}, **{"author": author}},
)
print("*", end="")
print(f" done ({len(b_emb_results.data)})")
print("\nFinished storing entries.")
Starting to store entries:
B ************************************************** done (50)
B ************************************************** done (50)
B ************************************************** done (50)
B ************************************************** done (50)
B ************************************************** done (50)
B ************************************************** done (50)
B ************************************************** done (50)
B ************************************************** done (50)
B ************************************************** done (50)
Finished storing entries.
使用案例1:报价搜索引擎
对于引用搜索功能,您需要首先将输入的引用转换为向量,然后使用它来查询存储库(除了处理可选的元数据到搜索调用中)。
将搜索引擎功能封装到一个函数中,以便于重复使用:
def find_quote_and_author(query_quote, n, author=None, tags=None):
query_vector = client.embeddings.create(
input=[query_quote],
model=embedding_model_name,
).data[0].embedding
metadata = {}
if author:
metadata["author"] = author
if tags:
for tag in tags:
metadata[tag] = True
#
results = v_table.ann_search(
query_vector,
n=n,
metadata=metadata,
)
return [
(result["body_blob"], result["metadata"]["author"])
for result in results
]
将搜索功能进行测试
只传递一个引用:
find_quote_and_author("We struggle all our life for nothing", 3)
[('Life to the great majority is only a constant struggle for mere existence, with the certainty of losing it at last.',
'schopenhauer'),
('We give up leisure in order that we may have leisure, just as we go to war in order that we may have peace.',
'aristotle'),
('Perhaps the gods are kind to us, by making life more disagreeable as we grow older. In the end death seems less intolerable than the manifold burdens we carry',
'freud')]
搜索限制为作者:
find_quote_and_author("We struggle all our life for nothing", 2, author="nietzsche")
[('To live is to suffer, to survive is to find some meaning in the suffering.',
'nietzsche'),
('What makes us heroic?--Confronting simultaneously our supreme suffering and our supreme hope.',
'nietzsche')]
搜索限定为标签(从先前用引号保存的标签中选择):
find_quote_and_author("We struggle all our life for nothing", 2, tags=["politics"])
[('Mankind will never see an end of trouble until lovers of wisdom come to hold political power, or the holders of power become lovers of wisdom',
'plato'),
('Everything the State says is a lie, and everything it has it has stolen.',
'nietzsche')]
剔除不相关的结果
向量相似性搜索通常会返回与查询最接近的向量,即使这意味着如果没有更好的结果,可能会返回一些不太相关的结果。
为了控制这个问题,您可以获取查询与每个结果之间的实际“距离”,然后设置一个阈值,有效地丢弃超出该阈值的结果。正确调整这个阈值并不是一件容易的问题:在这里,我们只是向您展示一种方法。
为了感受一下这是如何工作的,请尝试以下查询,并尝试选择引用和阈值来比较结果:
注(对于数学倾向者):这个“距离”恰好是两个向量之间的余弦相似度,即标量积除以两个向量范数的乘积。因此,它是一个从-1到+1的数字,其中-1表示完全相对的向量,+1表示完全定向的向量。在其他地方(例如在这个演示的“CQL”对应部分),您将获得这个数量的重新调整,以适应[0, 1]区间,这意味着结果的数值和相应的阈值会相应地进行转换。
quote = "Animals are our equals."
# 引文 = "Be good."
# 引文 = "This teapot is strange."
metric_threshold = 0.84
quote_vector = client.embeddings.create(
input=[quote],
model=embedding_model_name,
).data[0].embedding
results = list(v_table.metric_ann_search(
quote_vector,
n=8,
metric="cos",
metric_threshold=metric_threshold,
))
print(f"{len(results)} quotes within the threshold:")
for idx, result in enumerate(results):
print(f" {idx}. [distance={result['distance']:.3f}] \"{result['body_blob'][:70]}...\"")
3 quotes within the threshold:
0. [distance=0.855] "The assumption that animals are without rights, and the illusion that ..."
1. [distance=0.843] "Animals are in possession of themselves; their soul is in possession o..."
2. [distance=0.841] "At his best, man is the noblest of all animals; separated from law and..."
使用案例2:报价生成器
对于这个任务,您需要另一个来自OpenAI的组件,即一个LLM来为我们生成报价(基于通过查询向量存储获取的输入)。
您还需要一个用于提示模板,该模板将用于填充生成报价LLM完成任务。
completion_model_name = "gpt-3.5-turbo"
generation_prompt_template = """"Generate a single short philosophical quote on the given topic,
similar in spirit and form to the provided actual example quotes.
Do not exceed 20-30 words in your quote.
REFERENCE TOPIC: "{topic}"
ACTUAL EXAMPLES:
{examples}
"""
与搜索功能类似,这个功能最好封装在一个方便的函数中(内部使用搜索功能):
def generate_quote(topic, n=2, author=None, tags=None):
quotes = find_quote_and_author(query_quote=topic, n=n, author=author, tags=tags)
if quotes:
prompt = generation_prompt_template.format(
topic=topic,
examples="\n".join(f" - {quote[0]}" for quote in quotes),
)
# 少量日志记录:
print("** quotes found:")
for q, a in quotes:
print(f"** - {q} ({a})")
print("** end of logging")
#
response = client.chat.completions.create(
model=completion_model_name,
messages=[{"role": "user", "content": prompt}],
temperature=0.7,
max_tokens=320,
)
return response.choices[0].message.content.replace('"', '').strip()
else:
print("** no quotes found.")
return None
注意:与嵌入计算的情况类似,在OpenAI v1.0之前,Chat Completion API的代码会略有不同。
测试引用生成
只是传递一段文本(一个“引用”,但实际上可以只是建议一个主题,因为它的向量嵌入最终仍将出现在向量空间中的正确位置):
q_topic = generate_quote("politics and virtue")
print("\nA new generated quote:")
print(q_topic)
** quotes found:
** - Happiness is the reward of virtue. (aristotle)
** - Our moral virtues benefit mainly other people; intellectual virtues, on the other hand, benefit primarily ourselves; therefore the former make us universally popular, the latter unpopular. (schopenhauer)
** end of logging
A new generated quote:
Virtuous politics purifies society, while corrupt politics breeds chaos and decay.
从一个哲学家那里获得灵感:
q_topic = generate_quote("animals", author="schopenhauer")
print("\nA new generated quote:")
print(q_topic)
** quotes found:
** - Because Christian morality leaves animals out of account, they are at once outlawed in philosophical morals; they are mere 'things,' mere means to any ends whatsoever. They can therefore be used for vivisection, hunting, coursing, bullfights, and horse racing, and can be whipped to death as they struggle along with heavy carts of stone. Shame on such a morality that is worthy of pariahs, and that fails to recognize the eternal essence that exists in every living thing, and shines forth with inscrutable significance from all eyes that see the sun! (schopenhauer)
** - The assumption that animals are without rights, and the illusion that our treatment of them has no moral significance, is a positively outrageous example of Western crudity and barbarity. Universal compassion is the only guarantee of morality. (schopenhauer)
** end of logging
A new generated quote:
The true measure of humanity lies not in our dominion over animals, but in our ability to show compassion and respect for all living beings.
(可选)分区
在完成这个快速入门之前,有一个有趣的主题需要研究。一般来说,标签和引用可以有任何关系(例如,引用可以有多个标签),但是_作者_实际上是一个精确的分组(它们在引用集合上定义了一个“不相交的分区”):每个引用都有一个作者(至少对我们来说是这样)。
现在,假设您事先知道您的应用程序通常(或总是)会对_单个作者_运行查询。那么,您可以充分利用底层数据库结构:如果将引用分组在分区中(每个作者一个分区),仅对一个作者进行向量查询将使用更少的资源并且返回速度更快。
我们不会在这里深入讨论细节,这些细节涉及Cassandra存储内部:重要的信息是如果您的查询在一个组内运行,请考虑相应地分区以提高性能。
现在,您将看到这个选择的实际效果。
首先,您需要一个不同的表抽象化,而不是CassIO:
from cassio.table import ClusteredMetadataVectorCassandraTable
v_table_partitioned = ClusteredMetadataVectorCassandraTable(table="philosophers_cassio_partitioned", vector_dimension=1536)
现在在新表上重复执行计算嵌入并插入步骤。
与之前看到的情况相比,现在一个关键的区别是,现在引用的作者被存储为插入行的_partition id,而不是被添加到通用的“metadata”字典中。
在进行这个操作的同时,为了演示,您将同时插入给定作者的所有引用:使用CassIO,这是通过使用异步的put_async方法为每个引用完成的,收集生成的Future对象列表,并在之后调用它们的result()方法,以确保它们都已执行。Cassandra
/ Astra DB很好地支持I/O操作的高度并发。
(注意:可以缓存先前计算的嵌入以节省一些API令牌,但在这里,我们希望保持代码更易于检查。)
BATCH_SIZE = 50
num_batches = ((len(philo_dataset) + BATCH_SIZE - 1) // BATCH_SIZE)
quotes_list = philo_dataset["quote"]
authors_list = philo_dataset["author"]
tags_list = philo_dataset["tags"]
print("Starting to store entries:")
for batch_i in range(num_batches):
b_start = batch_i * BATCH_SIZE
b_end = (batch_i + 1) * BATCH_SIZE
# 计算这一批数据的嵌入向量
b_emb_results = client.embeddings.create(
input=quotes_list[b_start : b_end],
model=embedding_model_name,
)
# 准备插入的行
futures = []
print("B ", end="")
for entry_idx, emb_result in zip(range(b_start, b_end), b_emb_results.data):
if tags_list[entry_idx]:
tags = {
tag
for tag in tags_list[entry_idx].split(";")
}
else:
tags = set()
author = authors_list[entry_idx]
quote = quotes_list[entry_idx]
futures.append(v_table_partitioned.put_async(
partition_id=author,
row_id=f"q_{author}_{entry_idx}",
body_blob=quote,
vector=emb_result.embedding,
metadata={tag: True for tag in tags},
))
#
for future in futures:
future.result()
#
print(f" done ({len(b_emb_results.data)})")
print("\nFinished storing entries.")
Starting to store entries:
B done (50)
B done (50)
B done (50)
B done (50)
B done (50)
B done (50)
B done (50)
B done (50)
B done (50)
Finished storing entries.
使用这个新表,相似性搜索也相应发生变化(注意ann_search的参数):
def find_quote_and_author_p(query_quote, n, author=None, tags=None):
query_vector = client.embeddings.create(
input=[query_quote],
model=embedding_model_name,
).data[0].embedding
metadata = {}
partition_id = None
if author:
partition_id = author
if tags:
for tag in tags:
metadata[tag] = True
#
results = v_table_partitioned.ann_search(
query_vector,
n=n,
partition_id=partition_id,
metadata=metadata,
)
return [
(result["body_blob"], result["partition_id"])
for result in results
]
这就是:新表仍然支持“通用”相似性搜索…
find_quote_and_author_p("We struggle all our life for nothing", 3)
[('Life to the great majority is only a constant struggle for mere existence, with the certainty of losing it at last.',
'schopenhauer'),
('We give up leisure in order that we may have leisure, just as we go to war in order that we may have peace.',
'aristotle'),
('Perhaps the gods are kind to us, by making life more disagreeable as we grow older. In the end death seems less intolerable than the manifold burdens we carry',
'freud')]
…但是当指定作者时,您会注意到一个巨大的性能优势:
find_quote_and_author_p("We struggle all our life for nothing", 2, author="nietzsche")
[('To live is to suffer, to survive is to find some meaning in the suffering.',
'nietzsche'),
('What makes us heroic?--Confronting simultaneously our supreme suffering and our supreme hope.',
'nietzsche')]
嗯,如果你有一个真实大小的数据集,你会注意到性能的提升。在这个演示中,只有几十个条目,并没有明显的差异,但你可以理解其中的道理。
结论
恭喜!您已经学会了如何使用OpenAI进行向量嵌入和使用CQL将数据存储在Cassandra / Astra DB中,以构建一个复杂的哲学搜索引擎和引用生成器。
本示例使用CassIO来与Vector Store进行接口交互 - 但这并不是唯一的选择。请查看README以了解其他选项和与流行框架的集成。
要了解更多关于Astra DB的向量搜索功能如何成为您的ML/GenAI应用程序中的关键要素,请访问Astra DB关于该主题的网页。
清理
如果您想要删除此演示中使用的所有资源,请运行此单元格(警告:这将删除表和其中插入的数据!):
# 我们查看CassIO的配置,以直接获取数据库连接的句柄。
session = cassio.config.resolve_session()
keyspace = cassio.config.resolve_keyspace()
session.execute(f"DROP TABLE IF EXISTS {keyspace}.philosophers_cassio;")
session.execute(f"DROP TABLE IF EXISTS {keyspace}.philosophers_cassio_partitioned;")
<cassandra.cluster.ResultSet at 0x7fdcc42e8f10>