多时间序列、预训练模型和协变量¶
本笔记本作为以下内容的教程:
在多个时间序列上训练单个模型
使用预训练模型来获取任何在训练期间未见过的时序数据的预测
使用协变量训练和使用模型
使用一个或多个多变量时间序列训练和使用模型
首先,一些必要的导入:
[1]:
# fix python path if working locally
from utils import fix_pythonpath_if_working_locally
fix_pythonpath_if_working_locally()
import pandas as pd
import numpy as np
import torch
import matplotlib.pyplot as plt
from darts import TimeSeries, concatenate
from darts.utils.callbacks import TFMProgressBar
from darts.utils.timeseries_generation import (
gaussian_timeseries,
linear_timeseries,
sine_timeseries,
)
from darts.models import (
RNNModel,
TCNModel,
TransformerModel,
NBEATSModel,
BlockRNNModel,
VARIMA,
)
from darts.metrics import mape, smape, mae
from darts.dataprocessing.transformers import Scaler
from darts.utils.timeseries_generation import datetime_attribute_timeseries
from darts.datasets import AirPassengersDataset, MonthlyMilkDataset, ElectricityDataset
import logging
logging.disable(logging.CRITICAL)
import warnings
warnings.filterwarnings("ignore")
%matplotlib inline
# for reproducibility
torch.manual_seed(1)
np.random.seed(1)
def generate_torch_kwargs():
# run torch models on CPU, and disable progress bars for all model stages except training.
return {
"pl_trainer_kwargs": {
"accelerator": "cpu",
"callbacks": [TFMProgressBar(enable_train_bar_only=True)],
}
}
读取数据¶
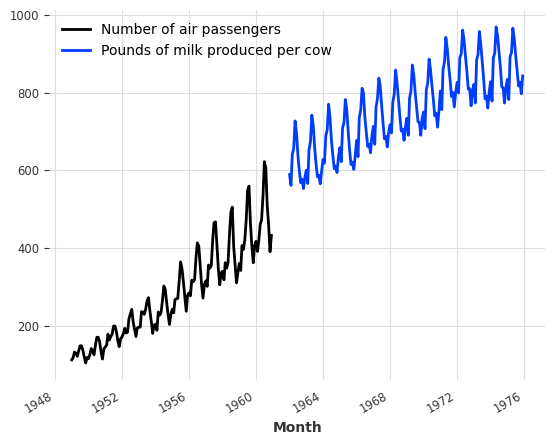
首先,我们读取两个时间序列——一个包含每月的航空乘客数量,另一个包含每头牛的每月牛奶产量。这些时间序列之间没有太多关联,除了它们都具有明显的年度周期性和上升趋势的月度频率,并且(完全巧合地)它们包含数量级可比的数据。
[2]:
series_air = AirPassengersDataset().load()
series_milk = MonthlyMilkDataset().load()
series_air.plot(label="Number of air passengers")
series_milk.plot(label="Pounds of milk produced per cow")
plt.legend();
预处理¶
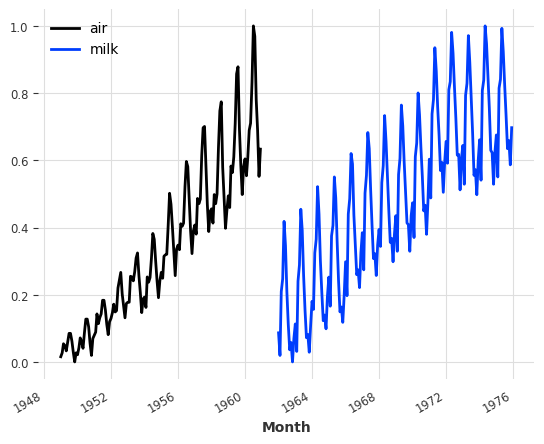
通常神经网络在归一化/标准化的数据上表现更好。这里我们将使用 Scaler 类将我们的两个时间序列归一化到0到1之间:
[3]:
scaler_air, scaler_milk = Scaler(), Scaler()
series_air_scaled = scaler_air.fit_transform(series_air)
series_milk_scaled = scaler_milk.fit_transform(series_milk)
series_air_scaled.plot(label="air")
series_milk_scaled.plot(label="milk")
plt.legend();
训练 / 验证 分割¶
让我们保留这两个系列的最后36个月作为验证:
[4]:
train_air, val_air = series_air_scaled[:-36], series_air_scaled[-36:]
train_milk, val_milk = series_milk_scaled[:-36], series_milk_scaled[-36:]
全球预测模型¶
Darts 包含许多预测模型,但并非所有模型都可以在多个时间序列上进行训练。支持在多个系列上训练的模型称为 全局 模型。全局模型的完整列表可以在此处找到 这里 (表格底部),例如:
线性回归模型
BlockRNNModel
时序卷积网络 (TCNModel)
N-Beats (NBEATSModel)
TiDEModel
在下面,我们将区分两种时间序列:
目标时间序列 是我们感兴趣的、希望根据其历史数据进行预测的时间序列。
协变量时间序列 是一个可能有助于目标序列预测的时间序列,但我们并不对其进行预测。它有时也被称为 外部数据。
注意:静态协变量在时间上是不变的,并且对应于与 目标时间序列 的组成部分相关联的附加信息。有关这种协变量的详细信息,请参见 静态协变量笔记本。
我们进一步区分协变量序列,取决于它们是否可以提前知道:
过去协变量 表示在预测时已知其过去值的时间序列。这些通常是需要测量或观察的事物。
未来协变量 表示在预测时间点上,其未来值在预测范围内已知的时间序列。例如,这些可以表示已知的未来假期,或天气预报。
一些模型仅使用过去的协变量,另一些仅使用未来的协变量,还有一些模型可能两者都使用。我们将在其他笔记本中深入探讨这个话题,但这个 表格 详细列出了每个模型支持的协变量。
上述所有全局模型都支持在多个序列上进行训练。此外,它们也都支持 多变量序列 。这意味着它们可以无缝地用于多维时间序列;目标序列可以包含一个(通常情况下)或多个维度。具有多个维度的时间序列实际上只是一个常规时间序列,其中每个时间戳的值是向量而不是标量。
例如,BlockRNNModel、N-Beats、TCN 和 Transformer 模型遵循“块”架构。它们包含一个神经网络,该网络接收时间序列的块作为输入,并输出(预测的)未来时间序列值的块。输入维度是目标序列的维度(组件)数量,加上所有协变量的组件数量 - 堆叠在一起。输出维度仅是目标序列的维度数量: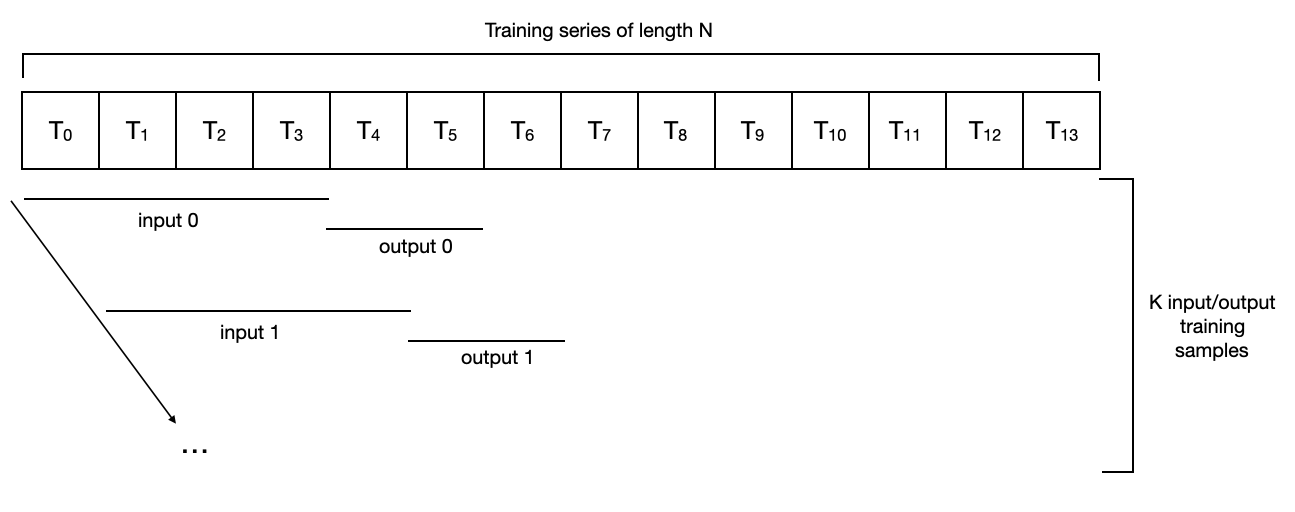
RNNModel 的工作方式不同,以递归的方式进行(这也是为什么它们支持未来协变量)。好消息是,作为用户,我们不必过多担心不同的模型类型和输入/输出维度。维度是根据训练数据自动推断的,而对过去或未来协变量的支持则通过 past_covariates 或 future_covariates 参数简单处理。
在构建模型时,我们仍然需要指定两个重要参数:
input_chunk_length: 这是模型的回溯窗口长度;因此,每个输出将由模型通过读取前input_chunk_length个点来计算。output_chunk_length: 这是内部模型生成的输出(预测)的长度。然而,“外部” Darts 模型(例如NBEATSModel、TCNModel等)的predict()方法可以用于更长的时间范围。在这些情况下,如果predict()被调用的时间范围超过output_chunk_length,内部模型将简单地被重复调用,以自回归的方式依赖其自身的先前输出。如果使用past_covariates,则需要这些协变量提前足够长的时间已知。
一个系列的例子¶
让我们来看一个第一个例子。我们将构建一个N-BEATS模型,该模型具有24个点的回溯窗口(input_chunk_length=24),并预测接下来的12个点(output_chunk_length=12)。我们选择这些值,以便我们的模型一次产生一年的连续预测,同时查看过去两年的数据。
[5]:
model_air = NBEATSModel(
input_chunk_length=24,
output_chunk_length=12,
n_epochs=200,
random_state=0,
**generate_torch_kwargs()
)
该模型可以像其他 Darts 预测模型一样使用,适用于单个时间序列的拟合:
[6]:
model_air.fit(train_air)
[6]:
NBEATSModel(generic_architecture=True, num_stacks=30, num_blocks=1, num_layers=4, layer_widths=256, expansion_coefficient_dim=5, trend_polynomial_degree=2, dropout=0.0, activation=ReLU, input_chunk_length=24, output_chunk_length=12, n_epochs=200, random_state=0, pl_trainer_kwargs={'accelerator': 'cpu', 'callbacks': [<darts.utils.callbacks.TFMProgressBar object at 0x103d1a710>]})
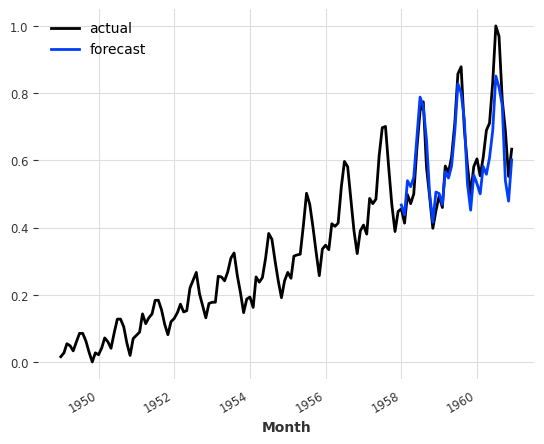
就像其他任何Darts预测模型一样,我们可以通过调用 predict() 来获取预测。请注意,下面我们使用36的预测范围调用 predict() ,这比模型内部 output_chunk_length 的12要长。这在这里不是问题——如上所述,在这种情况下,内部模型将简单地在其自身输出上自动回归调用。在这种情况下,它将被调用三次,以便三个12点的输出构成最终的36点预测——但所有这些都在幕后透明地完成。
[7]:
pred = model_air.predict(n=36)
series_air_scaled.plot(label="actual")
pred.plot(label="forecast")
plt.legend()
print("MAPE = {:.2f}%".format(mape(series_air_scaled, pred)))
MAPE = 8.02%
训练过程(幕后)¶
那么,当我们调用 model_air.fit() 时发生了什么?
为了训练内部神经网络,Darts首先从提供的时间序列(在此例中:series_air_scaled)创建输入/输出示例的数据集。有几种方法可以实现这一点,Darts在``darts.utils.data``包中包含了几种不同的数据集实现。
默认情况下,NBEATSModel 将实例化一个 darts.utils.data.PastCovariatesSequentialDataset,它简单地构建了序列中所有存在的输入/输出子序列(长度分别为 input_chunk_length 和 output_chunk_length)的连续对。
对于一个长度为14的示例系列,使用 input_chunk_length=4 和 output_chunk_length=2,它看起来如下:
对于这样的数据集,一系列长度为 N 将产生一个包含 N - input_chunk_length - output_chunk_length + 1 个样本的“训练集”。在上面的玩具示例中,我们有 N=14,input_chunk_length=4 和 output_chunk_length=2,因此用于训练的样本数量将是 K = 9。在这种情况下,训练的 epoch 包括完整地遍历所有样本(可能由多个小批次组成)。
请注意,不同的模型默认可能会使用不同的数据集。例如,darts.utils.data.HorizonBasedDataset 受到 N-BEATS 论文 的启发,生成的样本接近序列的末尾,甚至可能忽略序列的开头。
如果你需要控制从 TimeSeries 实例生成训练样本的方式,你可以通过继承抽象的 darts.utils.data.TrainingDataset 类来实现你自己的训练数据集。Darts 数据集继承自 torch 的 Dataset,这意味着实现懒加载版本非常容易,即不会一次性加载所有数据到内存中。一旦你有了自己的数据集实例,你可以直接调用 fit_from_dataset() 方法,所有全局预测模型都支持该方法。
在多个时间序列上训练模型¶
所有这些机制都可以无缝地用于多个时间序列。以下是一个序列数据集的示例,其中 input_chunk_length=4 和 output_chunk_length=2,适用于长度为 N 和 M 的两个序列:
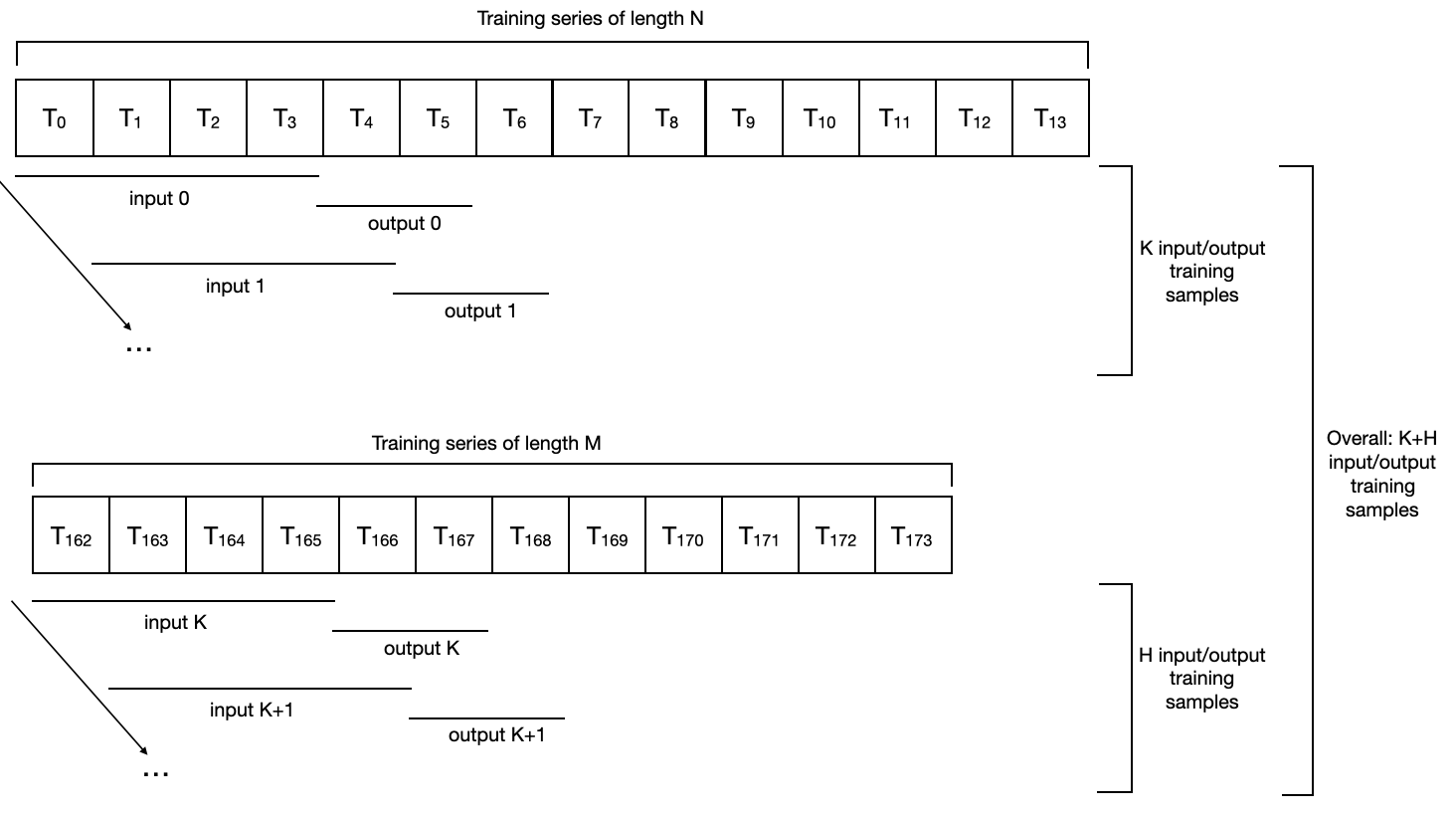
注意以下几点:
不同的系列不需要具有相同的长度,甚至不需要共享相同的时间戳。
事实上,它们甚至不需要具有相同的频率。
训练数据集中样本的总数将是每个系列中包含的所有训练样本的并集;因此,一个训练周期现在将涵盖所有系列中的所有样本。
在航空交通和牛奶系列上的训练¶
让我们看另一个例子,我们在我们的两个时间序列(航空乘客和牛奶生产)上拟合另一个模型实例。由于使用两个(大致)相同长度的序列(大致)使训练数据集大小翻倍,我们将使用一半的训练轮数:
[8]:
model_air_milk = NBEATSModel(
input_chunk_length=24,
output_chunk_length=12,
n_epochs=100,
random_state=0,
**generate_torch_kwargs()
)
然后,在两个(或更多)序列上拟合模型就像在 fit() 函数的参数中提供一个序列列表(而不是单个序列)一样简单:
[9]:
model_air_milk.fit([train_air, train_milk])
[9]:
NBEATSModel(generic_architecture=True, num_stacks=30, num_blocks=1, num_layers=4, layer_widths=256, expansion_coefficient_dim=5, trend_polynomial_degree=2, dropout=0.0, activation=ReLU, input_chunk_length=24, output_chunk_length=12, n_epochs=100, random_state=0, pl_trainer_kwargs={'accelerator': 'cpu', 'callbacks': [<darts.utils.callbacks.TFMProgressBar object at 0x2af748f10>]})
在系列结束后的预测生成¶
现在,重要的是,在计算预测时,我们必须指定我们想要预测未来的是哪个时间序列。
我们之前没有这个限制。当仅在一个序列上拟合模型时,模型会在内部记住这个序列,如果在调用 predict() 时没有提供 series 参数,它会返回对(唯一)训练序列的预测。一旦模型在多个序列上拟合,这种情况就不再适用 - 在这种情况下,predict() 的 series 参数变为强制性的。
所以,假设我们想要预测未来的航空交通。在这种情况下,我们向 predict() 函数指定 series=train_air,以便表明我们想要获得 train_air 之后的预测:
[10]:
pred = model_air_milk.predict(n=36, series=train_air)
series_air_scaled.plot(label="actual")
pred.plot(label="forecast")
plt.legend()
print("MAPE = {:.2f}%".format(mape(series_air_scaled, pred)))
MAPE = 7.58%
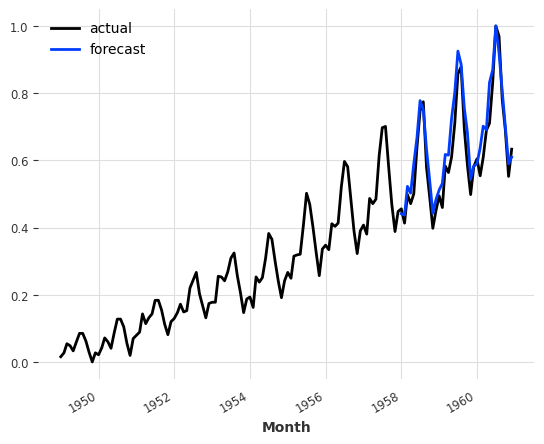
等等……这是否意味着牛奶生产有助于预测航空交通?¶
好吧,在这个特定的模型实例中,似乎确实是这种情况(至少在MAPE误差方面)。不过,如果你仔细想想,这并不奇怪。航空交通在很大程度上具有年度季节性和上升趋势的特点。牛奶系列也表现出这两种特征,在这种情况下,它可能有助于模型捕捉这些特征。
需要注意的是,这指向了 预训练 预测模型的可能性;一次性训练模型,然后使用它们来预测不在训练集中的序列。通过我们的玩具模型,我们确实可以预测任何其他序列的未来值,即使是训练过程中从未见过的序列。为了举例说明,假设我们想要预测某个任意正弦波序列的未来:
[11]:
any_series = sine_timeseries(length=50, freq="M")
pred = model_air_milk.predict(n=36, series=any_series)
any_series.plot(label='"any series, really"')
pred.plot(label="forecast")
plt.legend()
[11]:
<matplotlib.legend.Legend at 0x2af20d5d0>
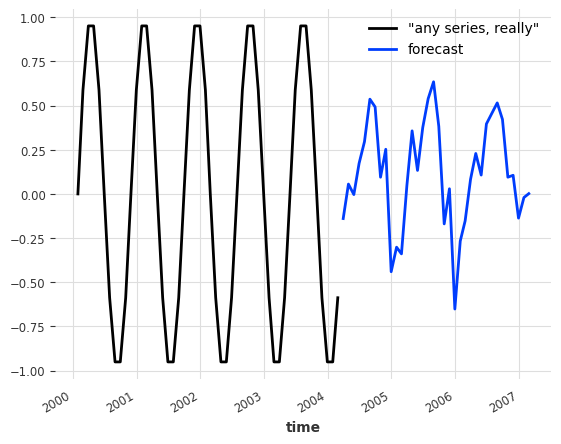
这个预测并不好(正弦函数甚至没有年度季节性),但你可以理解这个概念。
类似于 fit() 函数支持的功能,我们也可以在 predict() 函数的参数中提供一个序列列表,在这种情况下,它将返回一个预测序列列表。例如,我们可以一次性获取航空交通和牛奶序列的预测,如下所示:
[12]:
pred_list = model_air_milk.predict(n=36, series=[train_air, train_milk])
for series, label in zip(pred_list, ["air passengers", "milk production"]):
series.plot(label=f"forecast {label}")
plt.legend()
[12]:
<matplotlib.legend.Legend at 0x2b56bb9d0>
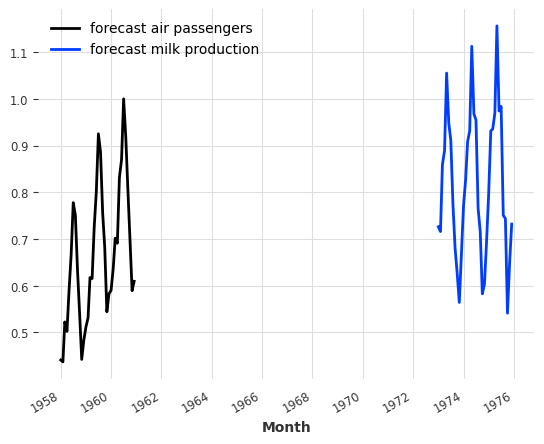
返回的两个序列分别对应于 train_air 和 train_milk 结束后的预测。
协变量序列¶
到目前为止,我们只使用了仅依赖于 目标 系列历史数据来预测其未来的模型。然而,如上所述,全局 Darts 模型还支持使用 协变量 时间序列。这些是“外部数据”的时间序列,我们不一定对其预测感兴趣,但我们仍然希望将其作为模型的输入,因为它们可能包含宝贵的信息。
构建协变量¶
让我们看一个简单的例子,使用我们的空气和牛奶系列,我们将尝试使用年份和月份作为协变量:
[13]:
# build year and month series:
air_year = datetime_attribute_timeseries(series_air_scaled, attribute="year")
air_month = datetime_attribute_timeseries(series_air_scaled, attribute="month")
milk_year = datetime_attribute_timeseries(series_milk_scaled, attribute="year")
milk_month = datetime_attribute_timeseries(series_milk_scaled, attribute="month")
# stack year and month to obtain series of 2 dimensions (year and month):
air_covariates = air_year.stack(air_month)
milk_covariates = milk_year.stack(milk_month)
# split in train/validation sets:
air_train_covariates, air_val_covariates = air_covariates[:-36], air_covariates[-36:]
milk_train_covariates, milk_val_covariates = (
milk_covariates[:-36],
milk_covariates[-36:],
)
# scale them between 0 and 1:
scaler_covariates = Scaler()
air_train_covariates, milk_train_covariates = scaler_covariates.fit_transform(
[air_train_covariates, milk_train_covariates]
)
air_val_covariates, milk_val_covariates = scaler_covariates.transform(
[air_val_covariates, milk_val_covariates]
)
# concatenate for the full scaled series; we can feed this to model.fit()/predict() as Darts will extract the required covariates for you
air_covariates = concatenate([air_train_covariates, air_val_covariates])
milk_covariates = concatenate([milk_train_covariates, milk_val_covariates])
# plot the covariates:
plt.figure()
air_covariates.plot()
plt.title("Air traffic covariates (year and month)")
plt.figure()
milk_covariates.plot()
plt.title("Milk production covariates (year and month)")
[13]:
Text(0.5, 1.0, 'Milk production covariates (year and month)')
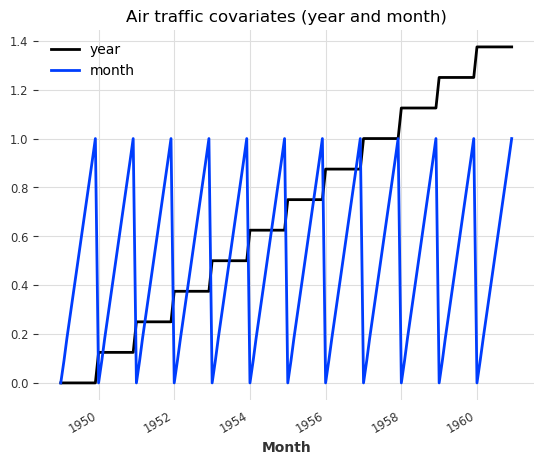
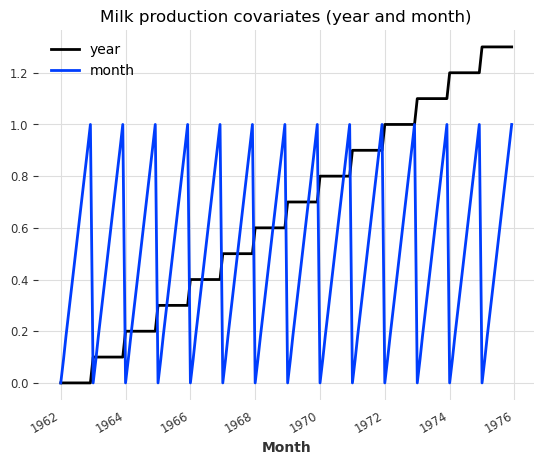
好,因此对于每个目标系列(空气和牛奶),我们已经构建了一个具有相同时间轴并包含年份和月份的协变量系列。
请注意,这里的协变量序列是 多元时间序列:它们包含两个维度——一个维度表示年份,另一个维度表示月份。
带有协变量的训练¶
让我们再次回顾我们的例子,这次加上协变量。我们将在这里构建一个 BlockRNNModel。我们激活检查点功能,以便随着时间的推移跟踪模型在验证集上的性能。
[14]:
model_name = "BlockRNN_test"
model_pastcov = BlockRNNModel(
model="LSTM",
input_chunk_length=24,
output_chunk_length=12,
n_epochs=100,
random_state=0,
model_name=model_name,
save_checkpoints=True, # store model states: latest and best performing of validation set
force_reset=True,
**generate_torch_kwargs()
)
现在,要使用协变量训练模型,只需将协变量(以与目标序列匹配的列表形式)作为 fit() 函数的 past_covariates 参数提供即可。该参数命名为 past_covariates 是为了提醒我们,模型可以使用这些协变量的过去值来进行预测。我们可以将包括训练集和测试集在内的整个空气和牛奶协变量提供给 model.fit()/predict(),Darts 将自动为您提取所需的协变量。
此外,我们传递一个验证系列以避免模型过拟合。
[15]:
model_pastcov.fit(
series=[train_air, train_milk],
past_covariates=[air_covariates, milk_covariates],
val_series=[val_air, val_milk],
val_past_covariates=[air_covariates, milk_covariates],
)
[15]:
BlockRNNModel(model=LSTM, hidden_dim=25, n_rnn_layers=1, hidden_fc_sizes=None, dropout=0.0, input_chunk_length=24, output_chunk_length=12, n_epochs=100, random_state=0, model_name=BlockRNN_test, save_checkpoints=True, force_reset=True, pl_trainer_kwargs={'accelerator': 'cpu', 'callbacks': [<darts.utils.callbacks.TFMProgressBar object at 0x2b56bb640>]})
现在我们加载在验证集上表现最佳的模型状态,以避免过拟合。
[16]:
model_pastcov = BlockRNNModel.load_from_checkpoint(model_name=model_name, best=True)
由于在这个例子中协变量可以很容易地在将来被知道,我们也可以定义一个 RNNModel 并使用它们作为 future_covariate 来训练它:
[17]:
model_name = "RNN_test"
model_futcov = RNNModel(
model="LSTM",
hidden_dim=20,
batch_size=8,
n_epochs=100,
random_state=0,
training_length=35,
input_chunk_length=24,
model_name=model_name,
save_checkpoints=True, # store model states: latest and best performing of validation set
force_reset=True,
**generate_torch_kwargs()
)
model_futcov.fit(
series=[train_air, train_milk],
future_covariates=[air_covariates, milk_covariates],
val_series=[val_air, val_milk],
val_future_covariates=[air_covariates, milk_covariates],
)
[17]:
RNNModel(model=LSTM, hidden_dim=20, n_rnn_layers=1, dropout=0.0, training_length=35, batch_size=8, n_epochs=100, random_state=0, input_chunk_length=24, model_name=RNN_test, save_checkpoints=True, force_reset=True, pl_trainer_kwargs={'accelerator': 'cpu', 'callbacks': [<darts.utils.callbacks.TFMProgressBar object at 0x2b69cb9d0>]})
现在我们加载在验证集上表现最佳的模型状态,以避免过拟合。
[18]:
model_futurecov = RNNModel.load_from_checkpoint(model_name=model_name, best=True)
使用协变量进行预测¶
同样地,获取预测现在只需为 BlockRNNModel 的 predict() 函数指定 past_covariates 参数即可:
[19]:
pred_cov = model_pastcov.predict(n=36, series=train_air, past_covariates=air_covariates)
series_air_scaled.plot(label="actual")
pred_cov.plot(label="forecast")
plt.legend()
[19]:
<matplotlib.legend.Legend at 0x2b6abd4b0>
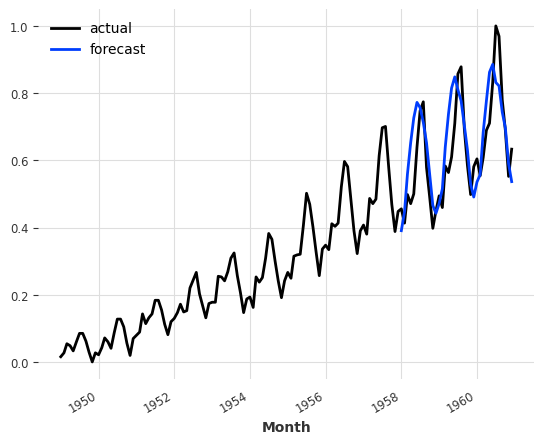
请注意,这里我们使用了一个预测范围 n 来调用 predict(),这个范围大于我们训练模型时使用的 output_chunk_length。我们之所以能够这样做,是因为尽管 BlockRNNModel 使用了过去的协变量,但在这种情况下,这些协变量在未来也是已知的,因此 Darts 能够自回归地计算未来 n 个时间步的预测。
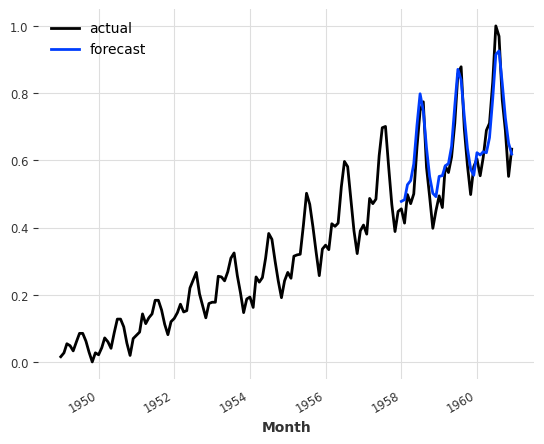
对于 RNNModel ,我们可以通过向 predict() 函数提供 future_covariates 来使用类似的方法:
[20]:
pred_cov = model_futcov.predict(
n=36, series=train_air, future_covariates=air_covariates
)
series_air_scaled.plot(label="actual")
pred_cov.plot(label="forecast")
plt.legend()
[20]:
<matplotlib.legend.Legend at 0x2b6ba5540>
带有协变量的回测¶
我们也可以使用协变量对模型进行回测。例如,我们可能对从验证序列开始时起,以12个月为预测期的运行准确性进行评估。
我们从验证系列的开始时间开始(
start=val_air.start_time())。每个预测的长度将为
forecast_horizon=12。下一次预测将从上一次之后的
stride=12点开始我们保留每次预测的所有预测值(
last_points_only=False)我们继续,直到输入数据耗尽
最终我们将历史预测连接起来,得到一个单一的连续(在时间轴上)的时间序列
[21]:
backtest_pastcov = model_pastcov.historical_forecasts(
series_air_scaled,
past_covariates=air_covariates,
start=val_air.start_time(),
forecast_horizon=12,
stride=12,
last_points_only=False,
retrain=False,
verbose=True,
)
backtest_pastcov = concatenate(backtest_pastcov)
print(
"MAPE (BlockRNNModel with past covariates) = {:.2f}%".format(
mape(series_air_scaled, backtest_pastcov)
)
)
backtest_futcov = model_futcov.historical_forecasts(
series_air_scaled,
future_covariates=air_covariates,
start=val_air.start_time(),
forecast_horizon=12,
stride=12,
last_points_only=False,
retrain=False,
verbose=True,
)
backtest_futcov = concatenate(backtest_futcov)
print(
"MAPE (RNNModel with future covariates) = {:.2f}%".format(
mape(series_air_scaled, backtest_futcov)
)
)
MAPE (BlockRNNModel with past covariates) = 12.09%
MAPE (RNNModel with future covariates) = 10.26%
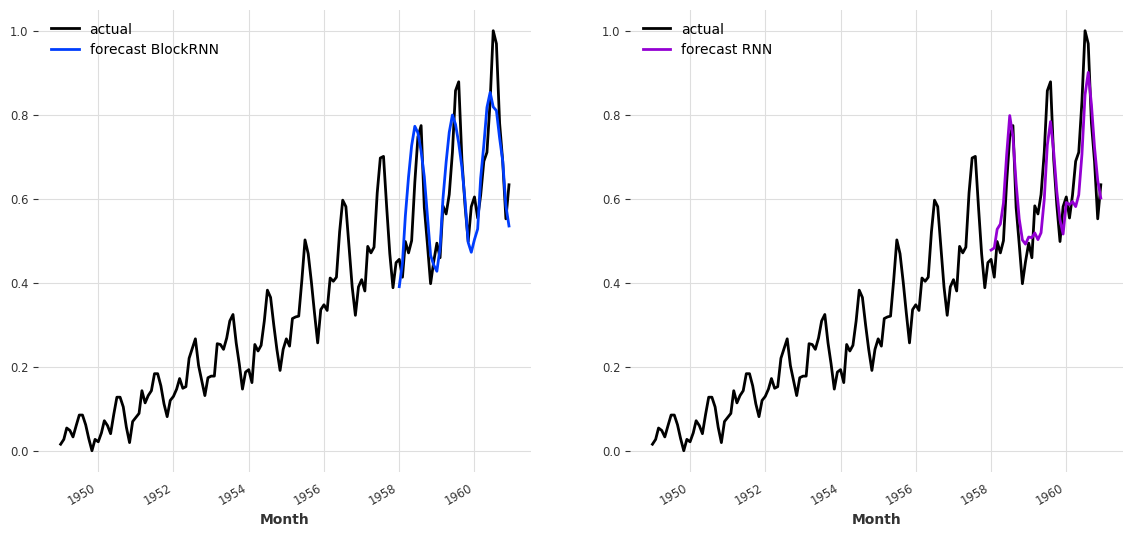
在选定的超参数(和随机种子)下,使用 past_covariates 的 BlockRNNModel``(MAPE=10.48%)似乎优于使用 ``future_covariates 的 ``RNNModel``(MAPE=15.21%)。为了更好地了解这两个模型获得的预测结果,可以将它们并排绘制出来:
[22]:
fig, axs = plt.subplots(1, 2, figsize=(14, 6))
series_air_scaled.plot(label="actual", ax=axs[0])
backtest_pastcov.plot(label="forecast BlockRNN", ax=axs[0])
axs[0].legend()
series_air_scaled.plot(label="actual", ax=axs[1])
backtest_futcov.plot(label="forecast RNN", ax=axs[1], color="darkviolet")
axs[1].legend()
plt.show()
关于过去协变量、未来协变量和其他条件的几点说明¶
目前,Darts 支持本身是时间序列的协变量。这些协变量被用作模型输入,但它们本身并不受预测。协变量不需要与目标序列对齐(例如,它们不需要同时开始)。Darts 将使用 TimeSeries 时间轴的实际时间值,以便在训练和推理时正确地共同切片目标和协变量。当然,协变量仍然需要有足够的跨度,否则 Darts 会报错。
如上所述,TCNModel、NBEATSModel、BlockRNNModel、TransformerModel 使用过去的协变量(如果你尝试使用 future_covariates,它们会报错)。如果这些过去的协变量恰好也已知未来值,那么这些模型也能够以自回归的方式为 n > output_chunk_length 生成预测(如上文 BlockRNNModel 所示)。
相比之下,RNNModel 使用未来协变量(如果你尝试指定 past_covariates,它会报错)。这意味着使用此模型进行预测时,需要预测时间之后至少 n 个时间步的协变量。
过去和未来的协变量(以及它们被不同模型使用的方式)是一个重要但复杂的主题,我们计划在未来的笔记本(或文章)中进一步解释这一点。
训练和预测多变量时间序列¶
现在,我们不再需要仅预测一个变量,而是希望同时预测多个变量。与使用两个不同的单变量数据集训练单个模型的多系列训练相比,训练集由包含多个变量(称为 components)观测值的单一系列组成。这些 components 通常具有相同的性质(测量相同的指标),但情况不一定总是如此。
即使在本例中未涉及,也可以通过向 fit 方法提供一系列此类序列来使用多个多元 TimeSeries 训练模型(当然,前提是模型支持多元 TimeSeries)。
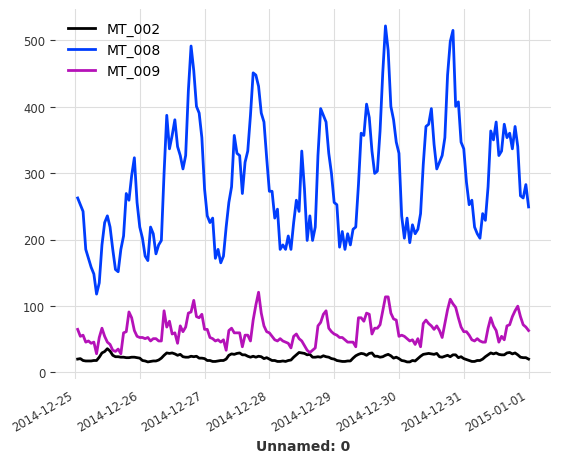
为了说明这个例子,将使用 ``ElectricityDataset``(在 Darts 中也可用)。这个数据集包含了 370 个客户的电力消耗测量值(以 kW 为单位),采样率为 15 分钟。
[23]:
multi_serie_elec = ElectricityDataset().load()
由于这个多变量序列特别大(370个分量,140,256个值),我们在重新采样序列之前只保留3个分量,采样频率为1小时。最后,保留最后168个值(一周)以缩短训练时间。
[24]:
# retaining only three components in different ranges
retained_components = ["MT_002", "MT_008", "MT_009"]
multi_serie_elec = multi_serie_elec[retained_components]
# resampling the multivariate time serie
multi_serie_elec = multi_serie_elec.resample(freq="1H")
# keep the values for the last 5 days
multi_serie_elec = multi_serie_elec[-168:]
[25]:
multi_serie_elec.plot()
plt.show()
数据准备和推理例程¶
我们将数据集分为训练集(6天)和验证集(1天),并进行归一化处理。在Darts中,所有模型都是通过调用 fit 进行训练,并通过 predict 进行推断,因此可以定义一个简短的函数 fit_and_pred 来封装这两个步骤。
[26]:
# split in train/validation sets
training_set, validation_set = multi_serie_elec[:-24], multi_serie_elec[-24:]
# define a scaler, by default, normalize each component between 0 and 1
scaler_dataset = Scaler()
# scaler is fit on training set only to avoid leakage
training_scaled = scaler_dataset.fit_transform(training_set)
validation_scaled = scaler_dataset.transform(validation_set)
def fit_and_pred(model, training, validation):
model.fit(training)
forecast = model.predict(len(validation))
return forecast
现在,我们将使用上述定义的函数来定义并训练一个 VARIMA 模型和一个 RNNModel。由于数据集是整数索引的,VARIMA 模型的 trend 参数必须设置为 None,这在上述图中没有明显的趋势,因此不会造成问题。
[27]:
model_VARIMA = VARIMA(p=12, d=0, q=0, trend="n")
model_GRU = RNNModel(
input_chunk_length=24,
model="LSTM",
hidden_dim=25,
n_rnn_layers=3,
training_length=36,
n_epochs=200,
**generate_torch_kwargs()
)
# training and prediction with the VARIMA model
forecast_VARIMA = fit_and_pred(model_VARIMA, training_scaled, validation_scaled)
print("MAE (VARIMA) = {:.2f}".format(mae(validation_scaled, forecast_VARIMA)))
# training and prediction with the RNN model
forecast_RNN = fit_and_pred(model_GRU, training_scaled, validation_scaled)
print("MAE (RNN) = {:.2f}".format(mae(validation_scaled, forecast_RNN)))
MAE (VARIMA) = 0.11
MAE (RNN) = 0.10
由于我们使用了 Scaler 来标准化多元序列的每个组成部分,因此我们不能忘记将它们缩放回去,以便能够正确地可视化预测值。
[28]:
forecast_VARIMA = scaler_dataset.inverse_transform(forecast_VARIMA)
forecast_RNN = scaler_dataset.inverse_transform(forecast_RNN)
labels = [f"forecast {component}" for component in retained_components]
fig, axs = plt.subplots(1, 2, figsize=(14, 6))
validation_set.plot(ax=axs[0])
forecast_VARIMA.plot(label=labels, ax=axs[0])
axs[0].set_ylim(0, 500)
axs[0].set_title("VARIMA model forecast")
axs[0].legend(loc="upper left")
validation_set.plot(ax=axs[1])
forecast_RNN.plot(label=labels, ax=axs[1])
axs[1].set_ylim(0, 500)
axs[1].set_title("RNN model forecast")
axs[1].legend(loc="upper left")
plt.show()
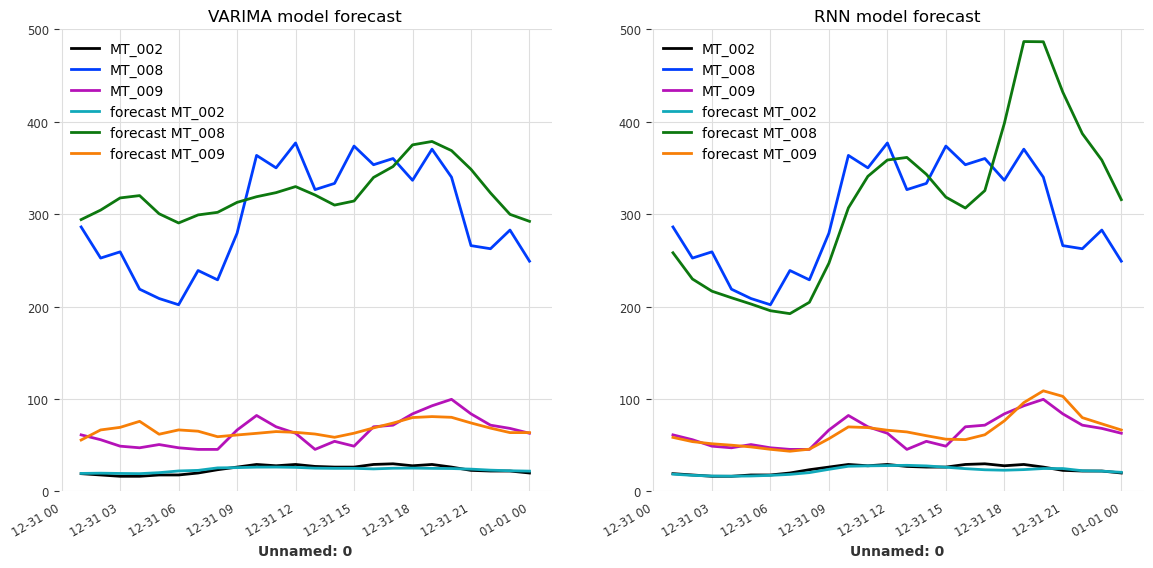
由于参数选择偏向速度而非准确性,预测的质量并不高。使用原始数据集中的更多成分或增加训练集的大小应能提高两种模型的准确性。另一个可能的改进是通过在 VARIMA 模型中将 ``p``(时间滞后)设置为 24 而不是 12 来考虑数据集的每日季节性,并重新训练模型。
关于使用多元序列进行训练的评论¶
前面展示的所有单变量 TimeSeries 的功能,特别是使用协变量(过去和未来)或序列的系列,当然也与多变量 TimeSeries 兼容(只需确保所使用的模型实际上支持它们)。
此外,支持多元时间序列的模型可能使用不同的方法。例如,TFTModel 使用一个专门的模块来选择相关特征,而 NBEATSModel 将序列的组成部分展平为一个单变量序列,并依赖其全连接层来捕捉特征之间的相互作用。