N-BEATS¶
在这个笔记本中,我们展示了一个如何将 N-BEATS 与 darts 结合使用的示例。如果你是 darts 的新手,我们建议你首先跟随 快速入门 笔记本。
N-BEATS 是一个最先进的模型,展示了在时间序列预测背景下 纯深度学习架构 的潜力。它在 M3 和 M4 竞赛中优于已建立的统计方法。有关该模型的更多详情,请参阅:https://arxiv.org/pdf/1905.10437.pdf。
[1]:
# fix python path if working locally
from utils import fix_pythonpath_if_working_locally
fix_pythonpath_if_working_locally()
%matplotlib inline
[2]:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from darts import TimeSeries, concatenate
from darts.utils.callbacks import TFMProgressBar
from darts.models import NBEATSModel
from darts.dataprocessing.transformers import Scaler, MissingValuesFiller
from darts.metrics import mape, r2_score
from darts.datasets import EnergyDataset
from darts import concatenate
import warnings
warnings.filterwarnings("ignore")
import logging
logging.disable(logging.CRITICAL)
def generate_torch_kwargs():
# run torch models on CPU, and disable progress bars for all model stages except training.
return {
"pl_trainer_kwargs": {
"accelerator": "cpu",
"callbacks": [TFMProgressBar(enable_train_bar_only=True)],
}
}
[3]:
def display_forecast(pred_series, ts_transformed, forecast_type, start_date=None):
plt.figure(figsize=(8, 5))
if start_date:
ts_transformed = ts_transformed.drop_before(start_date)
ts_transformed.univariate_component(0).plot(label="actual")
pred_series.plot(label=("historic " + forecast_type + " forecasts"))
plt.title(
"R2: {}".format(r2_score(ts_transformed.univariate_component(0), pred_series))
)
plt.legend()
每日能量生成示例¶
我们在一个来自径流式发电厂的每日发电数据集上测试NBEATS,因为它表现出不同程度的季节性。
[4]:
df = EnergyDataset().load().pd_dataframe()
df["generation hydro run-of-river and poundage"].plot()
plt.title("Hourly generation hydro run-of-river and poundage")
[4]:
Text(0.5, 1.0, 'Hourly generation hydro run-of-river and poundage')
为了简化操作,我们处理每日生成数据,并通过使用 MissingValuesFiller 来填补数据中缺失的值:
[5]:
df_day_avg = df.groupby(df.index.astype(str).str.split(" ").str[0]).mean().reset_index()
filler = MissingValuesFiller()
scaler = Scaler()
series = filler.transform(
TimeSeries.from_dataframe(
df_day_avg, "time", ["generation hydro run-of-river and poundage"]
)
).astype(np.float32)
train, val = series.split_after(pd.Timestamp("20170901"))
train_scaled = scaler.fit_transform(train)
val_scaled = scaler.transform(val)
series_scaled = scaler.transform(series)
train_scaled.plot(label="training")
val_scaled.plot(label="val")
plt.title("Daily generation hydro run-of-river and poundage")
[5]:
Text(0.5, 1.0, 'Daily generation hydro run-of-river and poundage')
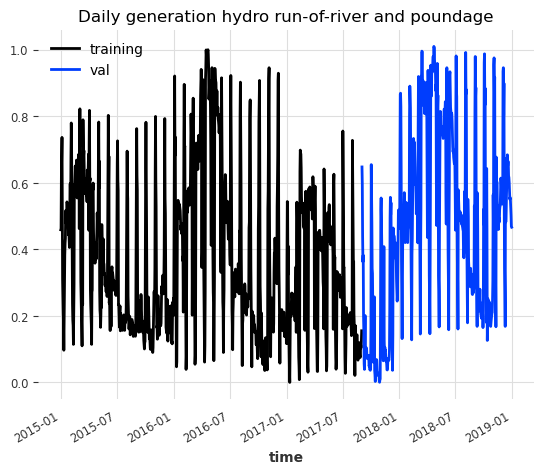
我们将数据分为训练集和验证集。通常我们需要使用一个额外的测试集来验证模型在未见数据上的表现,但在这个例子中我们将跳过这一步。
通用架构¶
N-BEATS 是一种单变量模型架构,提供两种配置:一种是*通用*配置,另一种是*可解释*配置。**通用架构**尽可能少地使用先验知识,没有特征工程,没有缩放,也没有可能被认为是时间序列特定的内部架构组件。
首先,我们使用一个具有N-BEATS通用架构的模型:
[6]:
model_name = "nbeats_run"
model_nbeats = NBEATSModel(
input_chunk_length=30,
output_chunk_length=7,
generic_architecture=True,
num_stacks=10,
num_blocks=1,
num_layers=4,
layer_widths=512,
n_epochs=100,
nr_epochs_val_period=1,
batch_size=800,
random_state=42,
model_name=model_name,
save_checkpoints=True,
force_reset=True,
**generate_torch_kwargs(),
)
[7]:
model_nbeats.fit(train_scaled, val_series=val_scaled)
[7]:
NBEATSModel(generic_architecture=True, num_stacks=10, num_blocks=1, num_layers=4, layer_widths=512, expansion_coefficient_dim=5, trend_polynomial_degree=2, dropout=0.0, activation=ReLU, input_chunk_length=30, output_chunk_length=7, n_epochs=100, nr_epochs_val_period=1, batch_size=800, random_state=42, model_name=nbeats_run, save_checkpoints=True, force_reset=True, pl_trainer_kwargs={'accelerator': 'cpu', 'callbacks': [<darts.utils.callbacks.TFMProgressBar object at 0x2b3d98fd0>]})
让我们从验证集上表现最好的检查点加载模型。
[8]:
model_nbeats = NBEATSModel.load_from_checkpoint(model_name=model_name, best=True)
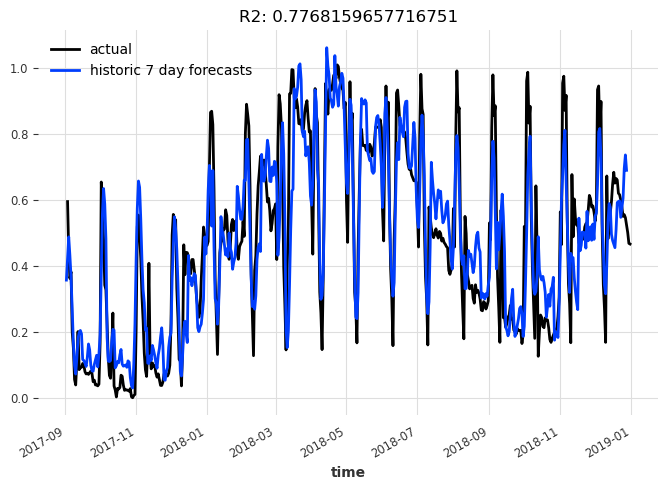
让我们看看模型在扩展训练窗口和7个预测时间步长的情况下,会产生什么样的历史预测:
[9]:
pred_series = model_nbeats.historical_forecasts(
series_scaled,
start=val.start_time(),
forecast_horizon=7,
stride=7,
last_points_only=False,
retrain=False,
verbose=True,
)
pred_series = concatenate(pred_series)
[10]:
display_forecast(
pred_series,
series_scaled,
"7 day",
start_date=val.start_time(),
)
可解释模型¶
N-BEATS 提供了一个 可解释的架构 ,由两个堆栈组成:一个 趋势 堆栈和一个 季节性 堆栈。该架构的设计使得:
趋势成分在输入进入季节性堆栈之前被移除
趋势和季节性的部分预测是可用的 作为单独的可解释输出
[11]:
model_name = "nbeats_interpretable_run"
model_nbeats = NBEATSModel(
input_chunk_length=30,
output_chunk_length=7,
generic_architecture=False,
num_blocks=3,
num_layers=4,
layer_widths=512,
n_epochs=100,
nr_epochs_val_period=1,
batch_size=800,
random_state=42,
model_name=model_name,
save_checkpoints=True,
force_reset=True,
**generate_torch_kwargs(),
)
[12]:
model_nbeats.fit(series=train_scaled, val_series=val_scaled)
[12]:
NBEATSModel(generic_architecture=False, num_stacks=30, num_blocks=3, num_layers=4, layer_widths=512, expansion_coefficient_dim=5, trend_polynomial_degree=2, dropout=0.0, activation=ReLU, input_chunk_length=30, output_chunk_length=7, n_epochs=100, nr_epochs_val_period=1, batch_size=800, random_state=42, model_name=nbeats_interpretable_run, save_checkpoints=True, force_reset=True, pl_trainer_kwargs={'accelerator': 'cpu', 'callbacks': [<darts.utils.callbacks.TFMProgressBar object at 0x2b3fc0790>]})
[13]:
model_nbeats = NBEATSModel.load_from_checkpoint(model_name=model_name, best=True)
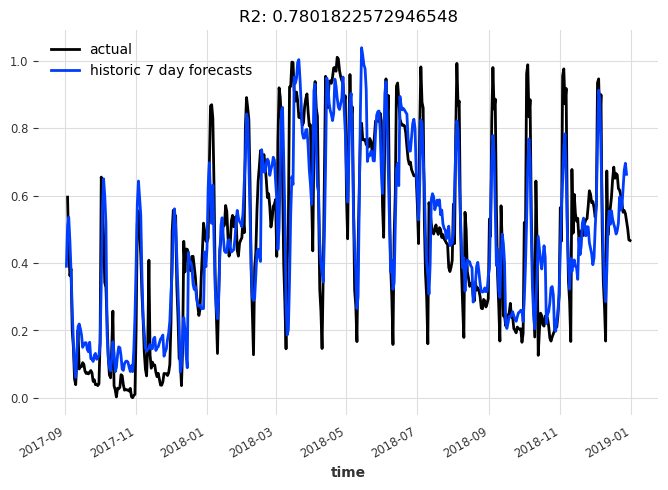
让我们看看模型在扩展训练窗口和7个预测时间步长的情况下,会产生什么样的历史预测:
[14]:
pred_series = model_nbeats.historical_forecasts(
series_scaled,
start=val_scaled.start_time(),
forecast_horizon=7,
stride=7,
last_points_only=False,
retrain=False,
verbose=True,
)
pred_series = concatenate(pred_series)
[15]:
display_forecast(
pred_series, series_scaled, "7 day", start_date=val_scaled.start_time()
)
[ ]: