import logging
import warnings完整流程演示
warnings.simplefilter('ignore')
logging.getLogger('statsforecast').setLevel(logging.ERROR)针对多个时间序列的模型训练、评估和选择
前提条件
本指南假设您对StatsForecast有基本的了解。要查看一个最小示例,请访问快速入门。
请按照本文提供的逐步指南构建一个适合生产的多时间序列预测管道。
在本指南中,您将熟悉核心的StatsForecast类及一些相关方法,如StatsForecast.plot、StatsForecast.forecast和StatsForecast.cross_validation。
我们将使用M4竞赛的经典基准数据集。该数据集包含来自金融、经济和销售等不同领域的时间序列。在本示例中,我们将使用小时数据集的一个子集。
我们将对每个时间序列进行单独建模。在这一层次上的预测也被称为局部预测。因此,您将为每个唯一系列训练一系列模型,然后选择最佳模型。StatsForecast关注速度、简单性和可扩展性,这使其非常适合此任务。
大纲:
- 安装软件包。
- 读取数据。
- 探索数据。
- 针对每个唯一时间序列的每种组合训练多个模型。
- 使用交叉验证评估模型的性能。
- 为每个唯一时间序列选择最佳模型。
本指南未涵盖内容
- 使用云上的集群进行大规模预测。
- 使用Ray集群在5分钟内预测M5数据集。
- 使用Spark集群在5分钟内预测M5数据集。
- 学习如何在不到30分钟内预测100万个系列。
- 对于多季节性的模型训练。
- 学习在本电力负荷预测教程中使用多季节性。
- 使用外部回归变量或外生变量。
- 参考本教程包含外生变量,如天气或假期,或静态变量,如类别或家族。
- 比较StatsForecast与其他流行库。
- 您可以在这里重现我们的基准测试。
安装库
我们假设您已经安装了 StatsForecast。请查看本指南以获取如何安装 StatsForecast的说明。
读取数据
我们将使用pandas来读取存储在parquet文件中的M4小时数据集,以提高效率。您可以使用普通的pandas操作来读取其他格式的数据,例如.csv。
StatsForecast的输入始终是一个长格式的数据框,包含三列:unique_id、ds和y:
unique_id(字符串、整数或类别)表示系列的标识符。ds(日期时间戳或整数)列应该是一个整型时间索引,或者最好采用YYYY-MM-DD格式的日期或YYYY-MM-DD HH:MM:SS格式的时间戳。y(数值型)表示我们希望进行预测的测量值。如果目标列的列名不同,则需要将其重命名为y。
该数据集已经满足这些要求。
根据您的网络连接,此步骤大约需要10秒钟。
import os
import pandas as pd# 这样,预测方法的输出结果中就会包含一个id列。
# 而不是作为索引
os.environ['NIXTLA_ID_AS_COL'] = '1'Y_df = pd.read_parquet('https://datasets-nixtla.s3.amazonaws.com/m4-hourly.parquet')
Y_df.head()| unique_id | ds | y | |
|---|---|---|---|
| 0 | H1 | 1 | 605.0 |
| 1 | H1 | 2 | 586.0 |
| 2 | H1 | 3 | 586.0 |
| 3 | H1 | 4 | 559.0 |
| 4 | H1 | 5 | 511.0 |
该数据集中包含414个独特系列,平均有900条观察值。为了示例和可重复性,我们将仅选择10个独特ID,并仅保留最后一周的数据。根据您的处理基础设施,可以自由选择更多或更少的系列。
Note
处理时间取决于可用的计算资源。使用完整数据集运行此示例需要大约10分钟,在AWS的c5d.24xlarge(96核)实例上。
uids = Y_df['unique_id'].unique()[:10] # 选择10个ID以加快示例速度
Y_df = Y_df.query('unique_id in @uids')
Y_df = Y_df.groupby('unique_id').tail(7 * 24) #选择最近7天的数据以加快示例运行速度使用 plot 方法探索数据
使用StatsForecast类中的plot方法绘制一些序列。该方法从数据集中随机打印8个序列,对于基本的探索性数据分析(EDA)非常有用。
Note
StatsForecast.plot 方法默认使用 Plotly 作为引擎。您可以通过设置 engine="matplotlib" 来更改为 MatPlotLib。
from statsforecast import StatsForecastStatsForecast.plot(Y_df)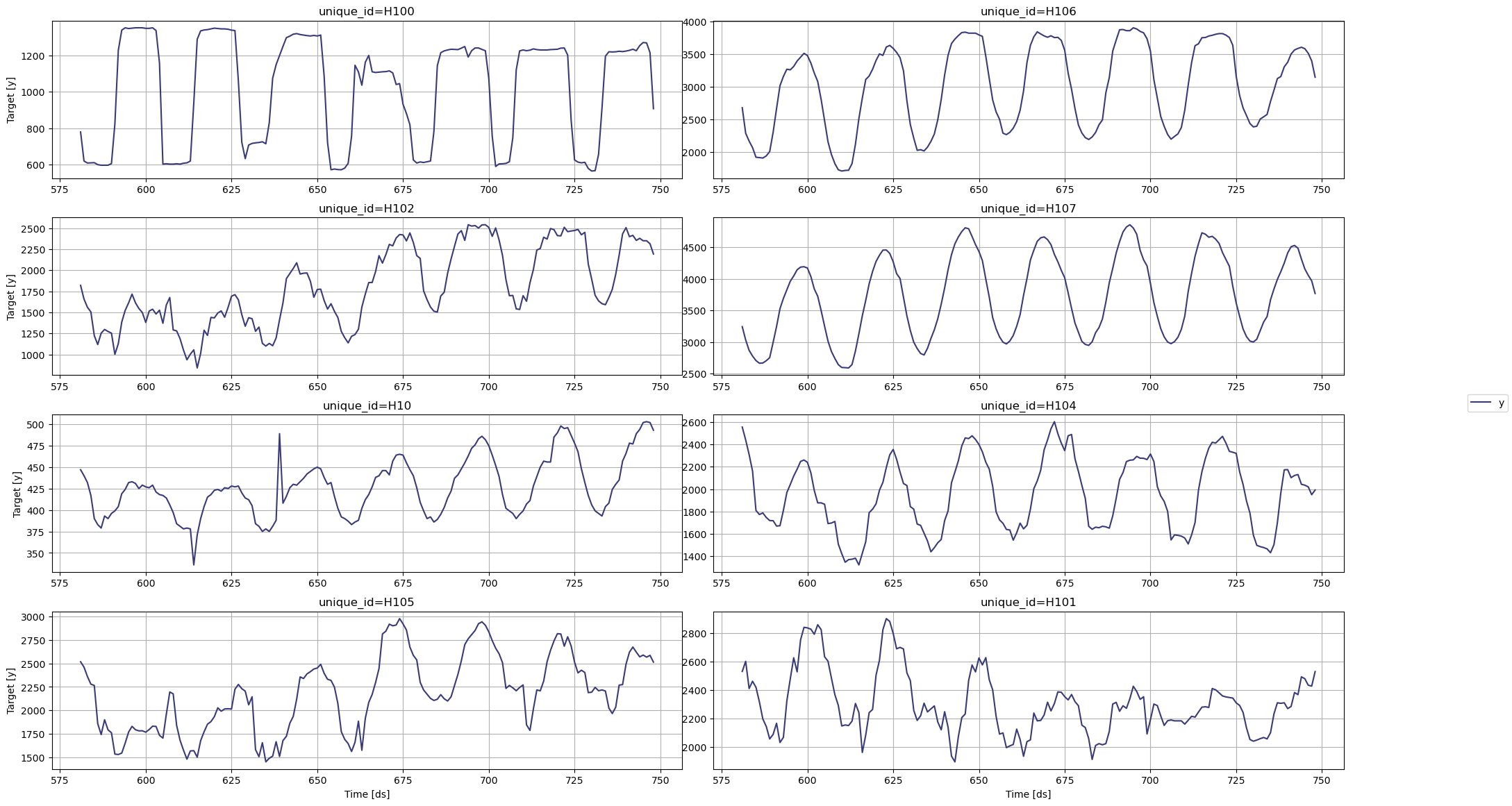
为多个时间序列训练多个模型
StatsForecast 可以高效地在多个时间序列上训练多个模型。
首先导入并实例化所需的模型。StatsForecast 提供了多种模型,分为以下几类:
自动预测: 自动预测工具会寻找最佳参数,并为一系列时间序列选择最佳模型。这些工具对于大规模单变量时间序列集合非常有用。包括以下模型的自动版本:Arima、ETS、Theta、CES。
指数平滑: 使用所有历史观察值的加权平均,其中权重呈指数递减,适用于没有明显趋势或季节性的数据。示例:SES、Holt-Winters、SSO。
基准模型: 用于建立基线的经典模型。示例:平均值、天真模型、随机游走。
间歇性或稀疏模型: 适用于非零观察值非常少的系列。示例:CROSTON、ADIDA、IMAPA。
多重季节性: 适用于具有多个明显季节性的信号。这对于低频数据(如电力和日志)非常有用。示例:MSTL。
Theta模型: 在去季节化时间序列上拟合两条theta线,使用不同的技术获取和结合两条theta线以生成最终预测。示例:Theta、DynamicTheta。
在这里,您可以查看完整的 模型列表。
在这个例子中,我们将使用:
AutoARIMA:使用信息准则自动选择最佳的ARIMA(自回归积分滑动平均)模型。参考:AutoARIMA。HoltWinters:三重指数平滑,Holt-Winters方法是对同时包含趋势和季节性的序列进行指数平滑的扩展。参考:HoltWinters。SeasonalNaive:内存效率高的季节性天真预测。参考:SeasonalNaive。HistoricAverage:算术平均值。参考:HistoricAverage。DynamicOptimizedTheta:Theta模型家族在各种数据集(如M3)中表现良好。对去季节化时间序列建模。参考:DynamicOptimizedTheta。
导入并实例化模型。设置 season_length 参数有时比较棘手。大师 Rob Hyndmann 关于 季节周期 的文章可能会很有帮助。
from statsforecast.models import (
HoltWinters,
CrostonClassic as Croston,
HistoricAverage,
DynamicOptimizedTheta as DOT,
SeasonalNaive
)# 创建一个模型及其实例化参数的列表
models = [
HoltWinters(),
Croston(),
SeasonalNaive(season_length=24),
HistoricAverage(),
DOT(season_length=24)
]我们通过实例化一个新的 StatsForecast 对象来拟合模型,使用以下参数:
models: 模型列表。选择你想要的模型并从 models 中导入。freq: 表示数据频率的字符串。(请参见 pandas 可用频率。)n_jobs: n_jobs: int, 在并行处理时使用的作业数,使用 -1 表示使用所有核心。fallback_model: 如果某个模型失败,则使用的模型。
任何设置都会传递给构造函数。然后你调用它的 fit 方法,并传入历史数据框。
# 实例化 StatsForecast 类为 sf
sf = StatsForecast(
models=models,
freq=1,
fallback_model = SeasonalNaive(season_length=7),
n_jobs=-1,
)
Note
StatsForecast通过Numba的JIT编译实现了惊人的速度。第一次调用statsforecast类时,fit方法大约需要5秒钟。第二次调用时——一旦Numba编译了你的设置——它应该少于0.2秒。
forecast 方法接受两个参数:预测未来 h(时间范围)和 level。
h(整数):表示预测未来 h 步。这种情况下是12个月。level(浮点数列表):这是一个可选参数,用于概率预测。设置预测区间的level(或置信百分位数)。例如,level=[90]意味着模型期望真实值在该区间内的概率为90%。
此处的预测对象是一个新的数据框,其中包含模型名称列和 y hat 值,以及用于不确定性区间的列。根据您的计算机,这一步大约需要1分钟。(如果您想将时间缩短到几秒,移除像 ARIMA 和 Theta 这样的自动模型)
Note
forecast 方法与分布式集群兼容,因此不存储任何模型参数。如果您想为每个模型存储参数,可以使用 fit 和 predict 方法。然而,这些方法并未针对 Spark、Ray 或 Dask 等分布式引擎定义。
forecasts_df = sf.forecast(df=Y_df, h=48, level=[90])
forecasts_df.head()| unique_id | ds | HoltWinters | HoltWinters-lo-90 | HoltWinters-hi-90 | CrostonClassic | CrostonClassic-lo-90 | CrostonClassic-hi-90 | SeasonalNaive | SeasonalNaive-lo-90 | SeasonalNaive-hi-90 | HistoricAverage | HistoricAverage-lo-90 | HistoricAverage-hi-90 | DynamicOptimizedTheta | DynamicOptimizedTheta-lo-90 | DynamicOptimizedTheta-hi-90 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | H1 | 749 | 829.0 | -246.367554 | 1904.367554 | 829.0 | -246.367554 | 1904.367554 | 635.0 | 537.471191 | 732.528809 | 660.982117 | 398.03775 | 923.926514 | 592.701843 | 577.677307 | 611.652649 |
| 1 | H1 | 750 | 807.0 | -268.367554 | 1882.367554 | 807.0 | -268.367554 | 1882.367554 | 572.0 | 474.471222 | 669.528809 | 660.982117 | 398.03775 | 923.926514 | 525.589111 | 505.449738 | 546.621826 |
| 2 | H1 | 751 | 785.0 | -290.367554 | 1860.367554 | 785.0 | -290.367554 | 1860.367554 | 532.0 | 434.471222 | 629.528809 | 660.982117 | 398.03775 | 923.926514 | 489.251801 | 462.072876 | 512.424133 |
| 3 | H1 | 752 | 756.0 | -319.367554 | 1831.367554 | 756.0 | -319.367554 | 1831.367554 | 493.0 | 395.471222 | 590.528809 | 660.982117 | 398.03775 | 923.926514 | 456.195038 | 430.554291 | 478.260956 |
| 4 | H1 | 753 | 719.0 | -356.367554 | 1794.367554 | 719.0 | -356.367554 | 1794.367554 | 477.0 | 379.471222 | 574.528809 | 660.982117 | 398.03775 | 923.926514 | 436.290527 | 411.051239 | 461.815948 |
绘制8个随机时间序列的结果,使用StatsForecast.plot方法。
sf.plot(Y_df,forecasts_df)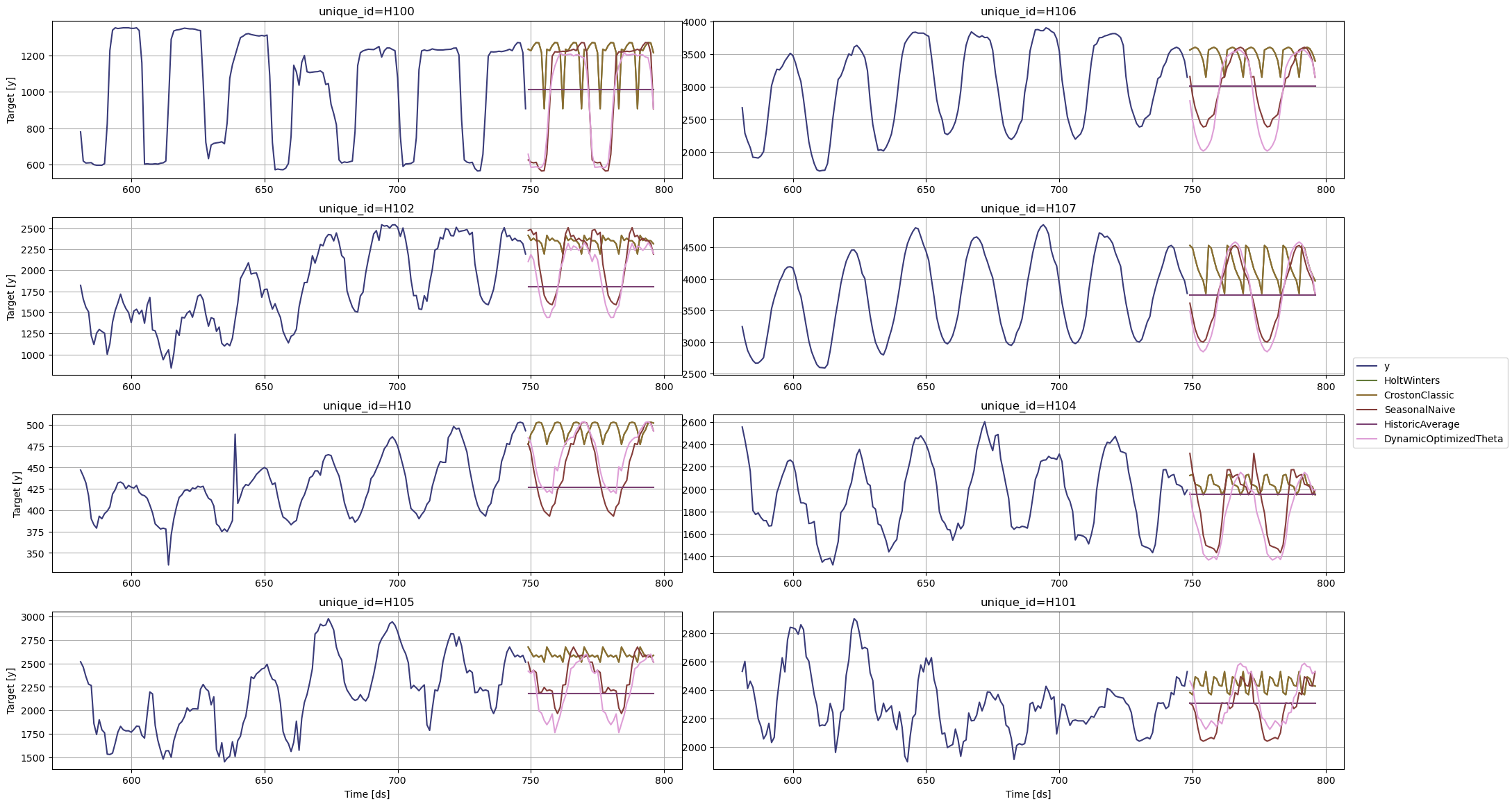
StatsForecast.plot 允许进一步的自定义。例如,可以绘制不同模型和唯一 ID 的结果。
# 将图表绘制到唯一标识符和一些选定的模型上
sf.plot(Y_df, forecasts_df, models=["HoltWinters","DynamicOptimizedTheta"], unique_ids=["H10", "H105"], level=[90])
# 探索其他模型
sf.plot(Y_df, forecasts_df, models=["SeasonalNaive"], unique_ids=["H10", "H105"], level=[90])
评估模型的性能
在之前的步骤中,我们利用历史数据来预测未来。然而,评估其准确性时,我们也希望了解模型在过去的表现。为了评估模型在数据上的准确性和稳健性,请执行交叉验证。
对于时间序列数据,交叉验证通过在历史数据上定义一个滑动窗口并预测其后的时间段来进行。这种形式的交叉验证使我们能够更好地估计模型在更广泛的时间实例上的预测能力,同时保持训练集中的数据是连续的,这是我们模型所要求的。
下图展示了这种交叉验证策略:

时间序列模型的交叉验证被认为是一种最佳实践,但大多数实现都非常缓慢。statsforecast库将交叉验证实现为分布式操作,使得这一过程执行起来不那么耗时。如果您拥有大型数据集,还可以使用Ray、Dask或Spark在分布式集群中执行交叉验证。
在这种情况下,我们希望评估每个模型在最后两天(n_windows=2)的性能,每隔一天进行一次预测(step_size=48)。根据你的计算机,这一步大约需要1分钟。
Tip
设置 n_windows=1 模拟了传统的训练-测试划分,其中我们的历史数据作为训练集,而最后48小时的数据作为测试集。
StatsForecast类中的cross_validation方法接受以下参数。
df: 训练数据框h(int): 表示预测未来的h步。在这种情况下,即24小时提前。step_size(int): 每个窗口之间的步长。换句话说:你想多久运行一次预测过程。n_windows(int): 用于交叉验证的窗口数量。换句话说:你想评估过去的多少个预测过程。
crossvaldation_df = sf.cross_validation(
df=Y_df,
h=24,
step_size=24,
n_windows=2
)crossvaldation_df对象是一个新的数据框,包含以下列:
unique_id: 系列标识符ds: 日期戳或时间索引cutoff:n_windows的最后一个日期戳或时间索引。如果n_windows=1,则有一个唯一的截止值;如果n_windows=2,则有两个唯一的截止值。y: 真实值"model": 包含模型名称和拟合值的列。
crossvaldation_df.head()| unique_id | ds | cutoff | y | HoltWinters | CrostonClassic | SeasonalNaive | HistoricAverage | DynamicOptimizedTheta | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | H1 | 701 | 700 | 619.0 | 847.0 | 742.668762 | 691.0 | 661.674988 | 612.767517 |
| 1 | H1 | 702 | 700 | 565.0 | 820.0 | 742.668762 | 618.0 | 661.674988 | 536.846252 |
| 2 | H1 | 703 | 700 | 532.0 | 790.0 | 742.668762 | 563.0 | 661.674988 | 497.824280 |
| 3 | H1 | 704 | 700 | 495.0 | 784.0 | 742.668762 | 529.0 | 661.674988 | 464.723236 |
| 4 | H1 | 705 | 700 | 481.0 | 752.0 | 742.668762 | 504.0 | 661.674988 | 440.972351 |
接下来,我们将使用常见的错误度量标准,如平均绝对误差(MAE)或均方误差(MSE)来评估每个模型在每个系列上的表现。 定义一个实用函数,以评估交叉验证数据框的不同错误度量。
首先,从 mlforecast.losses 导入所需的错误度量。然后定义一个实用函数,该函数将交叉验证数据框作为参数,并返回一个评估数据框,其中包含每个唯一 id 和拟合模型及所有截止值的错误度量平均值。
from utilsforecast.losses import mse
from utilsforecast.evaluation import evaluatedef evaluate_cross_validation(df, metric):
models = df.drop(columns=['unique_id', 'ds', 'cutoff', 'y']).columns.tolist()
evals = []
# 计算每个唯一标识符和截止时间的损失。
for cutoff in df['cutoff'].unique():
eval_ = evaluate(df[df['cutoff'] == cutoff], metrics=[metric], models=models)
evals.append(eval_)
evals = pd.concat(evals)
evals = evals.groupby('unique_id').mean(numeric_only=True) # 对每种模型和unique_id组合的所有截止值的误差指标取平均值。
evals['best_model'] = evals.idxmin(axis=1)
return evals
Warning
您也可以使用平均绝对百分比误差(MAPE),然而对于细粒度预测,MAPE 值非常 难以判断 并且对于评估预测质量没有帮助。
创建一个数据框,包含使用均方误差指标对你的交叉验证数据框评估的结果。
evaluation_df = evaluate_cross_validation(crossvaldation_df, mse)
evaluation_df.head()| HoltWinters | CrostonClassic | SeasonalNaive | HistoricAverage | DynamicOptimizedTheta | best_model | |
|---|---|---|---|---|---|---|
| unique_id | ||||||
| H1 | 44888.019531 | 28038.736328 | 1422.666748 | 20927.664062 | 1296.333984 | DynamicOptimizedTheta |
| H10 | 2812.916504 | 1483.484131 | 96.895828 | 1980.367432 | 379.621124 | SeasonalNaive |
| H100 | 121625.375000 | 91945.140625 | 12019.000000 | 78491.187500 | 21699.648438 | SeasonalNaive |
| H101 | 28453.394531 | 16183.634766 | 10944.458008 | 18208.404297 | 63698.082031 | SeasonalNaive |
| H102 | 232924.843750 | 132655.296875 | 12699.896484 | 309110.468750 | 31393.519531 | SeasonalNaive |
| 模型 | 表现最佳的系列数量 |
|---|---|
| Arima | 10 |
| Seasonal Naive | 10 |
| Theta | 2 |
summary_df = evaluation_df.groupby('best_model').size().sort_values().to_frame()
summary_df.reset_index().columns = ["Model", "Nr. of unique_ids"]您可以通过绘制特定模型获胜的 unique_ids 来进一步探索您的结果。
seasonal_ids = evaluation_df.query('best_model == "SeasonalNaive"').index
sf.plot(Y_df,forecasts_df, unique_ids=seasonal_ids, models=["SeasonalNaive","DynamicOptimizedTheta"])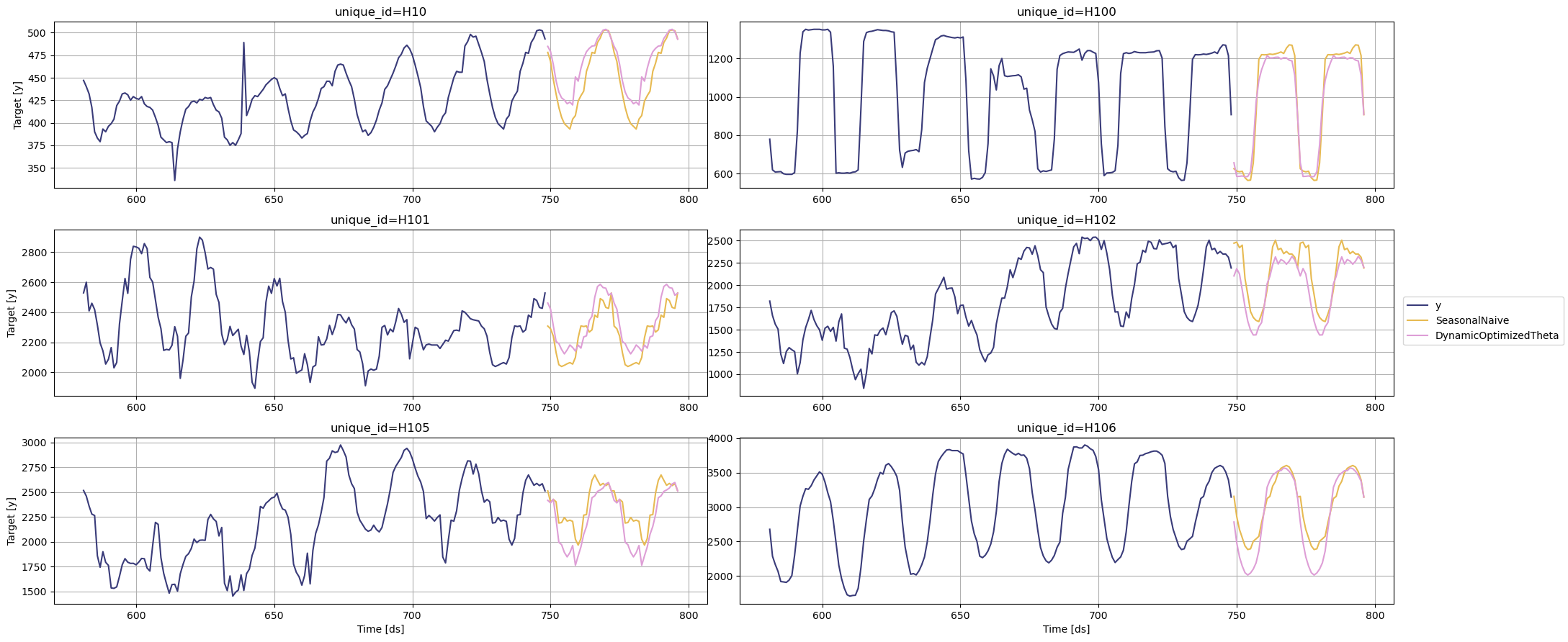
为每个独特系列选择最佳模型
import pandas as pd
def get_best_forecast(forecast_df, evaluation_df):
"""
定义一个实用函数,该函数接受包含预测的预测数据框和评估数据框,
并返回一个数据框,包含每个唯一_id 的最佳预测。
参数:
forecast_df (DataFrame): 包含预测结果的 DataFrame,包含 'unique_id' 和预测值。
evaluation_df (DataFrame): 包含实际值和评估指标的 DataFrame, 包含 'unique_id' 和实际值。
返回:
DataFrame: 包含每个唯一_id 的最佳预测的数据框。
"""
# Merge the forecast and evaluation dataframes on unique_id
merged_df = pd.merge(forecast_df, evaluation_df, on='unique_id', suffixes=('_pred', '_actual'))
# Evaluate the predictions
merged_df['error'] = (merged_df['pred'] - merged_df['actual']).abs()
# Find the best forecast for each unique_id based on minimum error
best_forecast_df = merged_df.loc[merged_df.groupby('unique_id')['error'].idxmin()]
return best_forecast_df[['unique_id', 'pred', 'actual', 'error']]def get_best_model_forecast(forecasts_df, evaluation_df):
df = forecasts_df.set_index(['unique_id', 'ds']).stack().to_frame().reset_index(level=2) # 宽到长
df.columns = ['model', 'best_model_forecast']
df = df.join(evaluation_df[['best_model']])
df = df.query('model.str.replace("-lo-90|-hi-90", "", regex=True) == best_model').copy()
df.loc[:, 'model'] = [model.replace(bm, 'best_model') for model, bm in zip(df['model'], df['best_model'])]
df = df.drop(columns='best_model').set_index('model', append=True).unstack()
df.columns = df.columns.droplevel()
df.columns.name = None
df = df.reset_index()
return df创建您的生产就绪数据框,以获得每个 unique_id 的最佳预测。
prod_forecasts_df = get_best_model_forecast(forecasts_df, evaluation_df)
prod_forecasts_df.head()| unique_id | ds | best_model | best_model-hi-90 | best_model-lo-90 | |
|---|---|---|---|---|---|
| 0 | H1 | 749 | 592.701843 | 611.652649 | 577.677307 |
| 1 | H1 | 750 | 525.589111 | 546.621826 | 505.449738 |
| 2 | H1 | 751 | 489.251801 | 512.424133 | 462.072876 |
| 3 | H1 | 752 | 456.195038 | 478.260956 | 430.554291 |
| 4 | H1 | 753 | 436.290527 | 461.815948 | 411.051239 |
绘制结果。
sf.plot(Y_df, prod_forecasts_df, level=[90])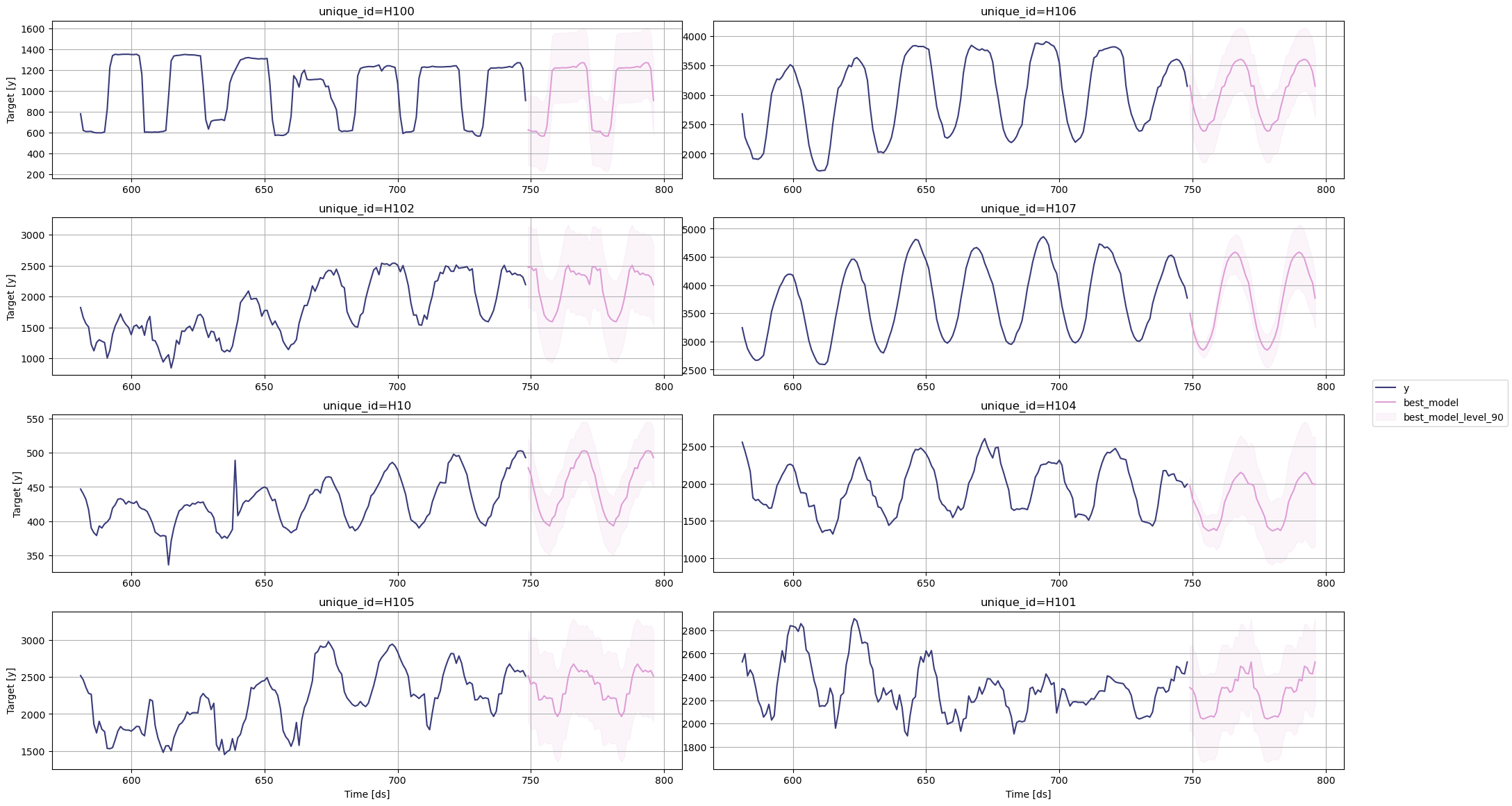
Give us a ⭐ on Github