# 此单元格将不会被渲染,但用于隐藏警告并限制显示的行数。
import warnings
warnings.filterwarnings("ignore")
import logging
logging.getLogger('statsforecast').setLevel(logging.ERROR)
import pandas as pd
pd.set_option('display.max_rows', 6)动态标准Theta模型
使用
Statsforecast的动态标准Theta模型的逐步指南。
在本教程中,我们将熟悉主要的StatsForecast类以及一些相关的方法,如StatsForecast.plot、StatsForecast.forecast和StatsForecast.cross_validation等。
目录
动态标准Theta模型 (DSTM)
动态标准Theta模型是优化动态Theta模型的一种特定案例变体。
此外,对于\(\theta=2\),我们有一个Theta的随机方法,以下称为动态标准Theta模型(DSTM)。
加载库和数据
Tip
需要使用Statsforecast。要安装,请参阅说明。
接下来,我们导入绘图库并配置绘图风格。
import matplotlib.pyplot as plt
import seaborn as sns
from statsmodels.graphics.tsaplots import plot_acf, plot_pacf
plt.style.use('grayscale') # 五三八 灰度 经典
plt.rcParams['lines.linewidth'] = 1.5
dark_style = {
'figure.facecolor': '#008080', # #212946
'axes.facecolor': '#008080',
'savefig.facecolor': '#008080',
'axes.grid': True,
'axes.grid.which': 'both',
'axes.spines.left': False,
'axes.spines.right': False,
'axes.spines.top': False,
'axes.spines.bottom': False,
'grid.color': '#000000', #2A3459
'grid.linewidth': '1',
'text.color': '0.9',
'axes.labelcolor': '0.9',
'xtick.color': '0.9',
'ytick.color': '0.9',
'font.size': 12 }
plt.rcParams.update(dark_style)
from pylab import rcParams
rcParams['figure.figsize'] = (18,7)读取数据
import pandas as pd
df = pd.read_csv("https://raw.githubusercontent.com/Naren8520/Serie-de-tiempo-con-Machine-Learning/main/Data/milk_production.csv", usecols=[1,2])
df.head()| month | production | |
|---|---|---|
| 0 | 1962-01-01 | 589 |
| 1 | 1962-02-01 | 561 |
| 2 | 1962-03-01 | 640 |
| 3 | 1962-04-01 | 656 |
| 4 | 1962-05-01 | 727 |
StatsForecast的输入始终是一个长格式的数据框,包含三列:unique_id、ds和y:
unique_id(字符串、整数或类别)表示序列的标识符。ds(日期戳)列应为Pandas期望的格式,理想情况下是YYYY-MM-DD的日期格式或YYYY-MM-DD HH:MM:SS的时间戳格式。y(数值型)表示我们希望进行预测的测量值。
df["unique_id"]="1"
df.columns=["ds", "y", "unique_id"]
df.head()| ds | y | unique_id | |
|---|---|---|---|
| 0 | 1962-01-01 | 589 | 1 |
| 1 | 1962-02-01 | 561 | 1 |
| 2 | 1962-03-01 | 640 | 1 |
| 3 | 1962-04-01 | 656 | 1 |
| 4 | 1962-05-01 | 727 | 1 |
print(df.dtypes)ds object
y int64
unique_id object
dtype: object我们可以看到我们的时间变量 (ds) 是以对象格式存储的,我们需要将其转换为日期格式。
df["ds"] = pd.to_datetime(df["ds"])使用plot方法探索数据
使用StatsForecast类中的plot方法绘制一些时间序列。该方法从数据集中打印出一个随机的时间序列,对于基本的探索性数据分析(EDA)非常有用。
from statsforecast import StatsForecast
StatsForecast.plot(df)
自相关图
fig, axs = plt.subplots(nrows=1, ncols=2)
plot_acf(df["y"], lags=30, ax=axs[0],color="fuchsia")
axs[0].set_title("Autocorrelation");
plot_pacf(df["y"], lags=30, ax=axs[1],color="lime")
axs[1].set_title('Partial Autocorrelation')
plt.show();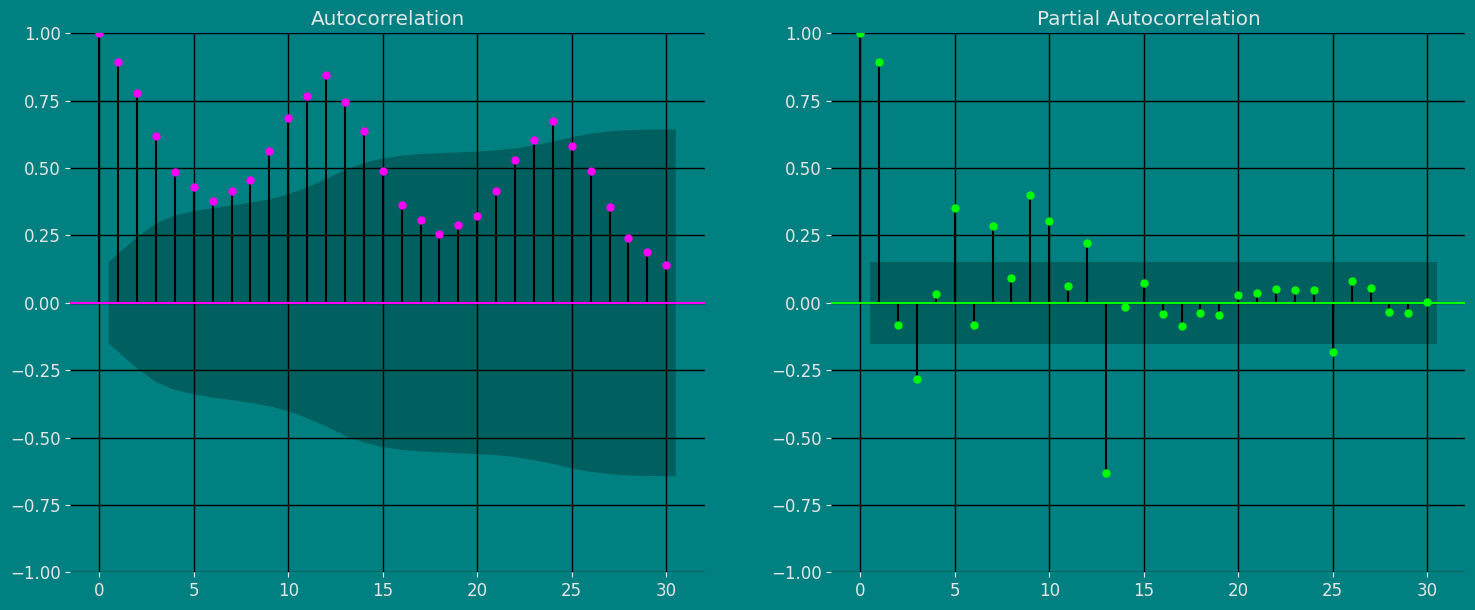
时间序列的分解
如何分解时间序列以及为什么要这样做?
在时间序列分析中,预测新值时,了解过去的数据是非常重要的。更正式地说,了解值随时间变化的模式是至关重要的。有许多原因可能导致我们的预测值出现错误的方向。基本上,一个时间序列由四个组件组成。这些组件的变化导致时间序列模式的变化。这些组件包括:
- 水平(Level): 这是随时间平均的主要值。
- 趋势(Trend): 趋势是导致时间序列中出现增加或减少模式的值。
- 季节性(Seasonality): 这是一个在时间序列中短期出现的周期性事件,导致时间序列中出现短期的增加或减少模式。
- 残差/噪声(Residual/Noise): 这些是时间序列中的随机变化。
随着时间的推移,将这些组件组合在一起形成一个时间序列。大多数时间序列由水平和噪声/残差组成,而趋势或季节性是可选的值。
如果季节性和趋势是时间序列的一部分,那么它们将会影响预测值。因为预测的时间序列的模式可能与之前的时间序列不同。
时间序列中组件的组合可以分为两种类型: * 加法型 * 乘法型
加法时间序列
如果时间序列的组件是通过相加来形成的,那么该时间序列被称为加法时间序列。通过可视化,可以说如果时间序列的增加或减少模式在整个序列中是相似的,则时间序列是加法性的。任何加法时间序列的数学函数可以表示为: \[y(t) = level + trend + seasonality + noise\]
乘法时间序列
如果时间序列的组件是通过相乘组合在一起的,则该时间序列被称为乘法时间序列。通过可视化,如果时间序列随时间呈指数增长或下降,则该时间序列可以被视为乘法时间序列。乘法时间序列的数学函数可以表示为: \[y(t) = level * trend * seasonality * noise\]
加法性
from statsmodels.tsa.seasonal import seasonal_decompose
a = seasonal_decompose(df["y"], model = "additive", period=12)
a.plot();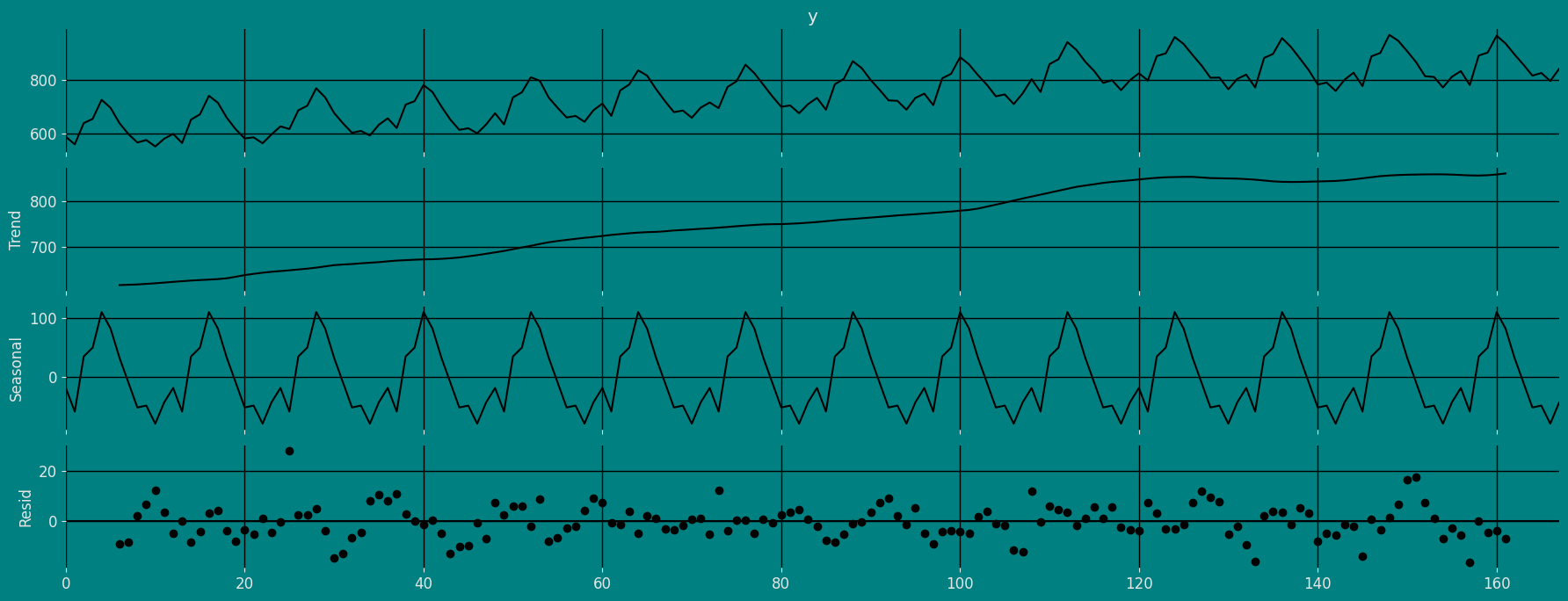
乘法性
from statsmodels.tsa.seasonal import seasonal_decompose
a = seasonal_decompose(df["y"], model = "Multiplicative", period=12)
a.plot();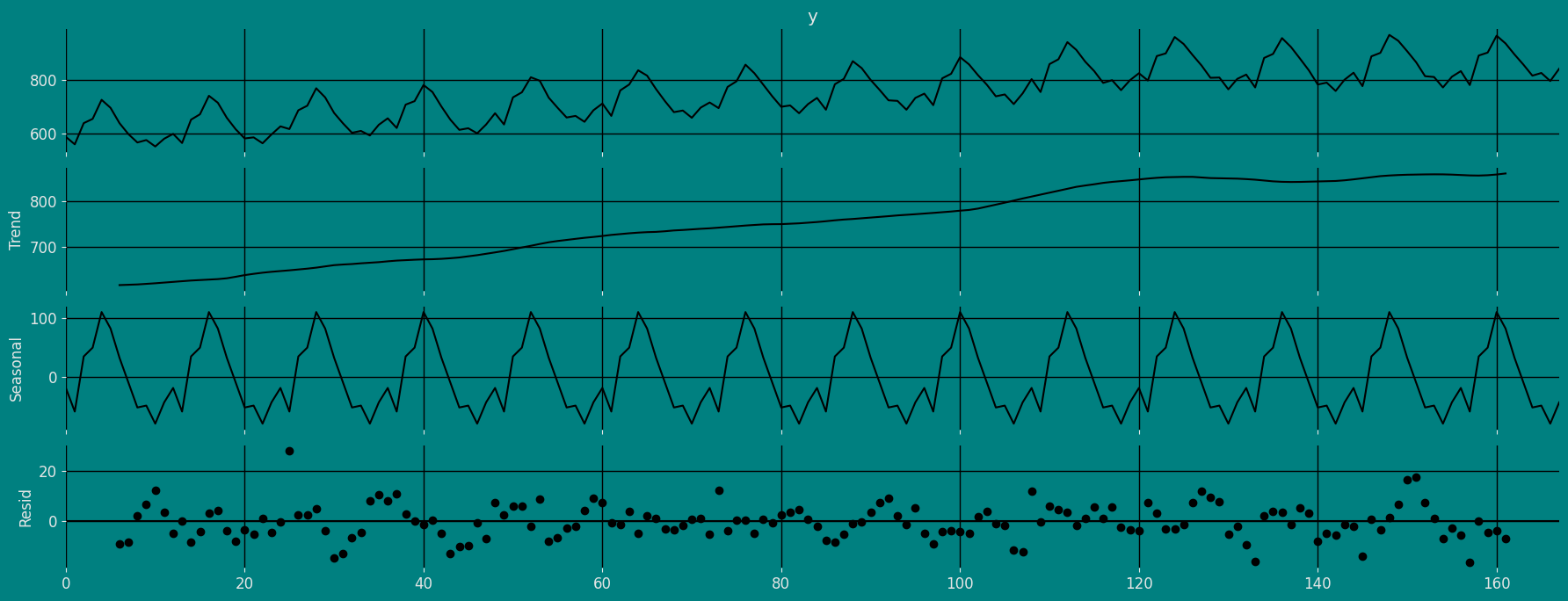
将数据拆分为训练集和测试集
让我们将我们的数据分为几个部分: 1. 用于训练我们的 动态标准Theta模型 的数据 2. 用于测试我们的模型的数据
对于测试数据,我们将使用最后12个月的数据来测试和评估我们模型的性能。
train = df[df.ds<='1974-12-01']
test = df[df.ds>'1974-12-01'] train.shape, test.shape((156, 3), (12, 3))现在让我们绘制训练数据和测试数据。
sns.lineplot(train,x="ds", y="y", label="Train", linestyle="--")
sns.lineplot(test, x="ds", y="y", label="Test")
plt.title("Monthly Milk Production")
plt.show()
DynamicStandardTheta的实现与StatsForecast
要了解DynamicStandardTheta模型函数的参数,下面列出了相关内容。欲了解更多信息,请访问文档。
season_length : int
每单位时间的观察数量。例如:24小时数据。
decomposition_type : str
季节分解类型,'multiplicative'(默认)或'additive'。
alias : str
模型的自定义名称。加载库
from statsforecast import StatsForecast
from statsforecast.models import DynamicTheta实例化模型
导入并实例化模型。有时设置参数会很棘手。大师 Rob Hyndmann 撰写的关于季节性周期的文章,对于 season_length 的理解可能很有帮助。
season_length = 12 # 月度数据
horizon = len(test) # 预测数量
models = [DynamicTheta(season_length=season_length,
decomposition_type="additive")] # 乘法加法我们通过实例化一个新的 StatsForecast 对象并使用以下参数来拟合模型:
模型:模型的列表。从模型中选择您想要的模型并导入它们。
freq:一个字符串,指示数据的频率。(请参见 pandas 可用频率。)n_jobs:n_jobs: int,用于并行处理的作业数量,使用 -1 表示所有核心。fallback_model:如果模型失败,则使用的模型。
任何设置都传递给构造函数。然后您调用它的 fit 方法并传入历史数据框。
sf = StatsForecast(df=train,
models=models,
freq='MS',
n_jobs=-1)拟合模型
sf.fit()StatsForecast(models=[DynamicTheta])让我们看看我们的 动态标准Theta模型 的结果。我们可以通过以下指令进行观察:
result=sf.fitted_[0,0].model_
print(result.keys())
print(result['fit'])dict_keys(['mse', 'amse', 'fit', 'residuals', 'm', 'states', 'par', 'n', 'modeltype', 'mean_y', 'decompose', 'decomposition_type', 'seas_forecast', 'fitted'])
results(x=array([393.28739991, 0.76875 ]), fn=10.787112115489615, nit=20, simplex=array([[399.92916541, 0.771875 ],
[393.28739991, 0.76875 ],
[384.74798713, 0.771875 ]]))现在让我们可视化我们模型的残差。
正如我们所看到的,上述结果的输出是一个字典,为了从字典中提取每个元素,我们将使用 .get() 函数提取元素,然后将其保存到 pd.DataFrame() 中。
residual=pd.DataFrame(result.get("residuals"), columns=["residual Model"])
residual| residual Model | |
|---|---|
| 0 | -18.247131 |
| 1 | -46.247131 |
| 2 | 17.140198 |
| ... | ... |
| 153 | -58.941711 |
| 154 | -91.055420 |
| 155 | -42.624939 |
156 rows × 1 columns
import scipy.stats as stats
fig, axs = plt.subplots(nrows=2, ncols=2)
residual.plot(ax=axs[0,0])
axs[0,0].set_title("Residuals");
sns.distplot(residual, ax=axs[0,1]);
axs[0,1].set_title("Density plot - Residual");
stats.probplot(residual["residual Model"], dist="norm", plot=axs[1,0])
axs[1,0].set_title('Plot Q-Q')
plot_acf(residual, lags=35, ax=axs[1,1],color="fuchsia")
axs[1,1].set_title("Autocorrelation");
plt.show();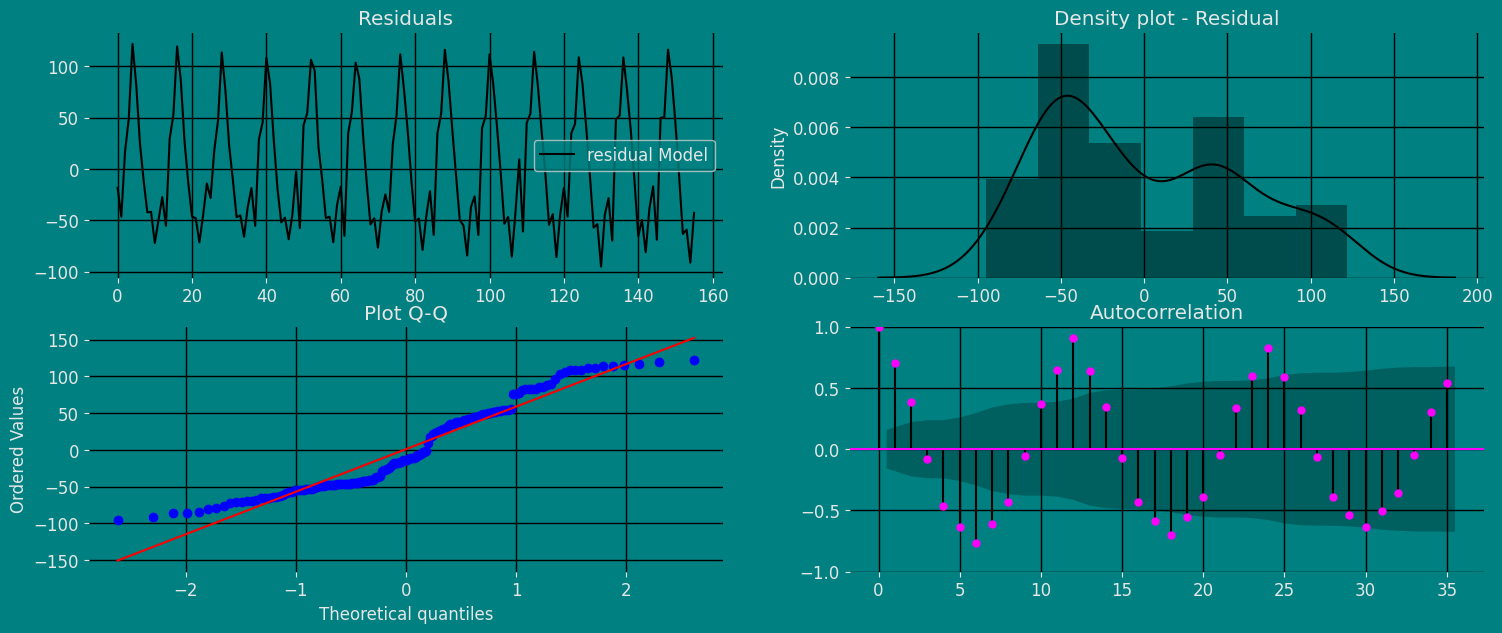
预测方法
如果您希望在生产环境中加速处理多个系列或模型,建议使用 StatsForecast.forecast 方法,而不是 .fit 和 .predict。
主要区别在于 .forecast 不存储拟合值,并且在分布式环境中具有高度可扩展性。
预测方法需要两个参数:预测下一个 h(时间范围)和 level。
h (int):代表预测未来 h 步。在本例中,是指提前 12 个月。level (list of floats):此可选参数用于概率预测。设置您的预测区间的水平(或置信百分位)。例如,level=[90]表示模型期望真实值在该区间内的概率为 90%。
这里的预测对象是一个新的数据框,其中包含模型名称的列和 y hat 值,以及不确定性区间的列。根据您的计算机,这一步应该大约需要 1 分钟。
Y_hat = sf.forecast(horizon, fitted=True)
Y_hat| ds | DynamicTheta | |
|---|---|---|
| unique_id | ||
| 1 | 1975-01-01 | 838.531555 |
| 1 | 1975-02-01 | 800.154968 |
| 1 | 1975-03-01 | 893.430786 |
| ... | ... | ... |
| 1 | 1975-10-01 | 815.959351 |
| 1 | 1975-11-01 | 786.716431 |
| 1 | 1975-12-01 | 823.539368 |
12 rows × 2 columns
values=sf.forecast_fitted_values()
values.head()| ds | y | DynamicTheta | |
|---|---|---|---|
| unique_id | |||
| 1 | 1962-01-01 | 589.0 | 607.247131 |
| 1 | 1962-02-01 | 561.0 | 607.247131 |
| 1 | 1962-03-01 | 640.0 | 622.859802 |
| 1 | 1962-04-01 | 656.0 | 606.987793 |
| 1 | 1962-05-01 | 727.0 | 605.021179 |
StatsForecast.plot(values)
添加95%的置信区间与预测方法
sf.forecast(h=horizon, level=[95])| ds | DynamicTheta | DynamicTheta-lo-95 | DynamicTheta-hi-95 | |
|---|---|---|---|---|
| unique_id | ||||
| 1 | 1975-01-01 | 838.531555 | 741.237366 | 954.407166 |
| 1 | 1975-02-01 | 800.154968 | 640.697327 | 945.673157 |
| 1 | 1975-03-01 | 893.430786 | 703.900635 | 1065.418579 |
| ... | ... | ... | ... | ... |
| 1 | 1975-10-01 | 815.959351 | 536.423035 | 1086.643677 |
| 1 | 1975-11-01 | 786.716431 | 484.476562 | 1033.687012 |
| 1 | 1975-12-01 | 823.539368 | 509.187408 | 1104.107788 |
12 rows × 4 columns
Y_hat=Y_hat.reset_index()
Y_hat| unique_id | ds | DynamicTheta | |
|---|---|---|---|
| 0 | 1 | 1975-01-01 | 838.531555 |
| 1 | 1 | 1975-02-01 | 800.154968 |
| 2 | 1 | 1975-03-01 | 893.430786 |
| ... | ... | ... | ... |
| 9 | 1 | 1975-10-01 | 815.959351 |
| 10 | 1 | 1975-11-01 | 786.716431 |
| 11 | 1 | 1975-12-01 | 823.539368 |
12 rows × 3 columns
test['unique_id'] = test['unique_id'].astype(int)
Y_hat1 = test.merge(Y_hat, how='left', on=['unique_id', 'ds'])
Y_hat1| ds | y | unique_id | DynamicTheta | |
|---|---|---|---|---|
| 0 | 1975-01-01 | 834 | 1 | 838.531555 |
| 1 | 1975-02-01 | 782 | 1 | 800.154968 |
| 2 | 1975-03-01 | 892 | 1 | 893.430786 |
| ... | ... | ... | ... | ... |
| 9 | 1975-10-01 | 827 | 1 | 815.959351 |
| 10 | 1975-11-01 | 797 | 1 | 786.716431 |
| 11 | 1975-12-01 | 843 | 1 | 823.539368 |
12 rows × 4 columns
fig, ax = plt.subplots(1, 1)
plot_df = pd.concat([train, Y_hat1]).set_index('ds')
plot_df[['y', "DynamicTheta"]].plot(ax=ax, linewidth=2)
ax.set_title(' Forecast', fontsize=22)
ax.set_ylabel('Monthly Milk Production', fontsize=20)
ax.set_xlabel('Timestamp [t]', fontsize=20)
ax.legend(prop={'size': 15})
ax.grid(True)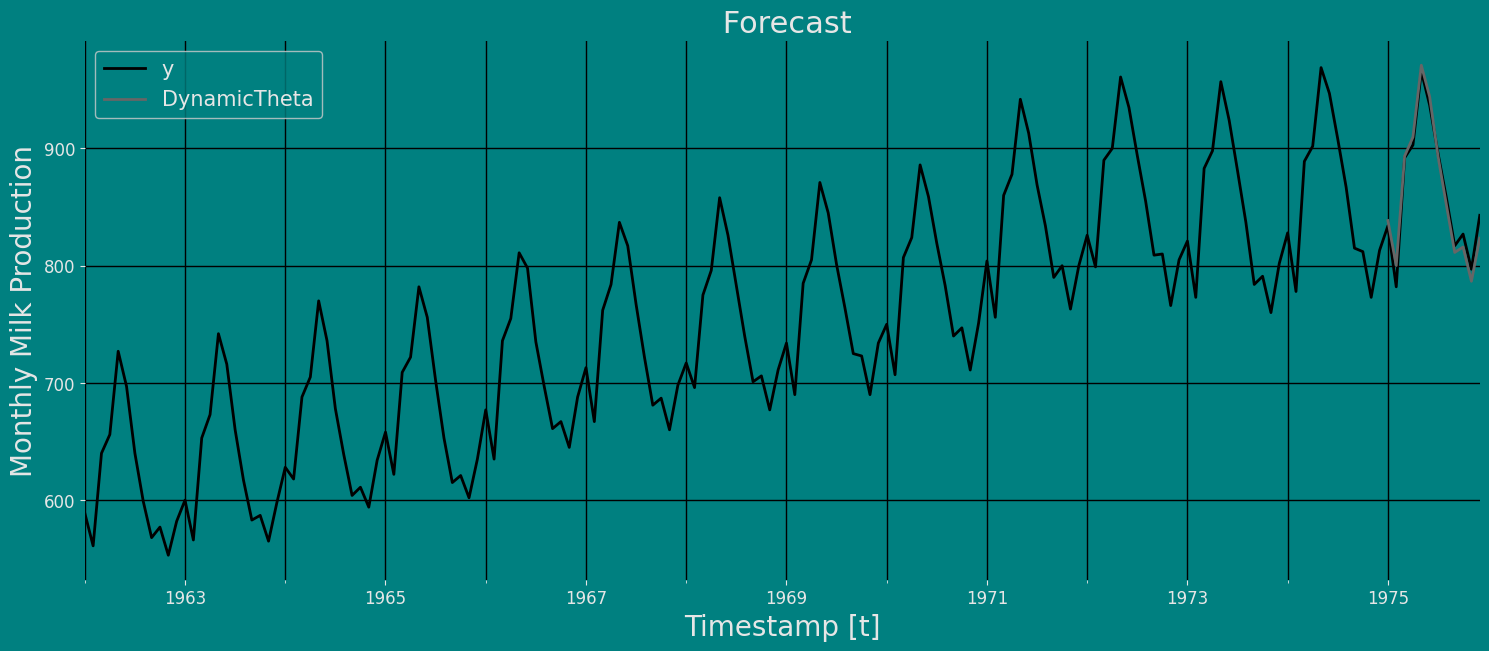
带有置信区间的预测方法
要生成预测,请使用预测方法。
预测方法接受两个参数:预测下一个 h(代表时间范围)和 level。
h (int):代表向未来预测 h 步。在本例中,代表 12 个月。level (list of floats):这个可选参数用于概率预测。设置你的预测区间的级别(或置信百分位)。例如,level=[95]意味着模型期望实际值在该区间内 95% 的时间。
这里的预测对象是一个新的数据框,其中包括一个模型名称的列和 y hat 值,以及不确定性区间的列。
此步骤应少于 1 秒。
sf.predict(h=horizon) | ds | DynamicTheta | |
|---|---|---|
| unique_id | ||
| 1 | 1975-01-01 | 838.531555 |
| 1 | 1975-02-01 | 800.154968 |
| 1 | 1975-03-01 | 893.430786 |
| ... | ... | ... |
| 1 | 1975-10-01 | 815.959351 |
| 1 | 1975-11-01 | 786.716431 |
| 1 | 1975-12-01 | 823.539368 |
12 rows × 2 columns
forecast_df = sf.predict(h=horizon, level=[80,95])
forecast_df| ds | DynamicTheta | DynamicTheta-lo-80 | DynamicTheta-hi-80 | DynamicTheta-lo-95 | DynamicTheta-hi-95 | |
|---|---|---|---|---|---|---|
| unique_id | ||||||
| 1 | 1975-01-01 | 838.531555 | 765.423828 | 927.285400 | 741.237366 | 954.407166 |
| 1 | 1975-02-01 | 800.154968 | 701.099854 | 899.316223 | 640.697327 | 945.673157 |
| 1 | 1975-03-01 | 893.430786 | 758.326416 | 1007.631287 | 703.900635 | 1065.418579 |
| ... | ... | ... | ... | ... | ... | ... |
| 1 | 1975-10-01 | 815.959351 | 608.699524 | 992.552856 | 536.423035 | 1086.643677 |
| 1 | 1975-11-01 | 786.716431 | 558.429626 | 970.648560 | 484.476562 | 1033.687012 |
| 1 | 1975-12-01 | 823.539368 | 588.707153 | 1031.565063 | 509.187408 | 1104.107788 |
12 rows × 6 columns
我们可以使用pandas函数 pd.concat() 将预测结果与历史数据连接起来,然后可以使用这个结果进行绘图。
pd.concat([df, forecast_df]).set_index('ds')| y | unique_id | DynamicTheta | DynamicTheta-lo-80 | DynamicTheta-hi-80 | DynamicTheta-lo-95 | DynamicTheta-hi-95 | |
|---|---|---|---|---|---|---|---|
| ds | |||||||
| 1962-01-01 | 589.0 | 1 | NaN | NaN | NaN | NaN | NaN |
| 1962-02-01 | 561.0 | 1 | NaN | NaN | NaN | NaN | NaN |
| 1962-03-01 | 640.0 | 1 | NaN | NaN | NaN | NaN | NaN |
| ... | ... | ... | ... | ... | ... | ... | ... |
| 1975-10-01 | NaN | NaN | 815.959351 | 608.699524 | 992.552856 | 536.423035 | 1086.643677 |
| 1975-11-01 | NaN | NaN | 786.716431 | 558.429626 | 970.648560 | 484.476562 | 1033.687012 |
| 1975-12-01 | NaN | NaN | 823.539368 | 588.707153 | 1031.565063 | 509.187408 | 1104.107788 |
180 rows × 7 columns
现在让我们可视化我们的预测结果和时间序列的历史数据,同时绘制我们在以95%的置信度进行预测时所获得的置信区间。
def plot_forecasts(y_hist, y_true, y_pred, models):
_, ax = plt.subplots(1, 1, figsize = (20, 7))
y_true = y_true.merge(y_pred, how='left', on=['unique_id', 'ds'])
df_plot = pd.concat([y_hist, y_true]).set_index('ds').tail(12*10)
df_plot[['y'] + models].plot(ax=ax, linewidth=3 , )
colors = ['green', "lime"]
ax.fill_between(df_plot.index,
df_plot['DynamicTheta-lo-80'],
df_plot['DynamicTheta-lo-80'],
alpha=.20,
color='orange',
label='DynamicTheta_level_80')
ax.fill_between(df_plot.index,
df_plot['DynamicTheta-lo-95'],
df_plot['DynamicTheta-hi-95'],
alpha=.3,
color='lime',
label='DynamicTheta_level_95')
ax.set_title('', fontsize=22)
ax.set_ylabel("Montly Mil Production", fontsize=20)
ax.set_xlabel('Month-Days', fontsize=20)
ax.legend(prop={'size': 20})
ax.grid(True)
plt.show()plot_forecasts(train, test, forecast_df, models=['DynamicTheta'])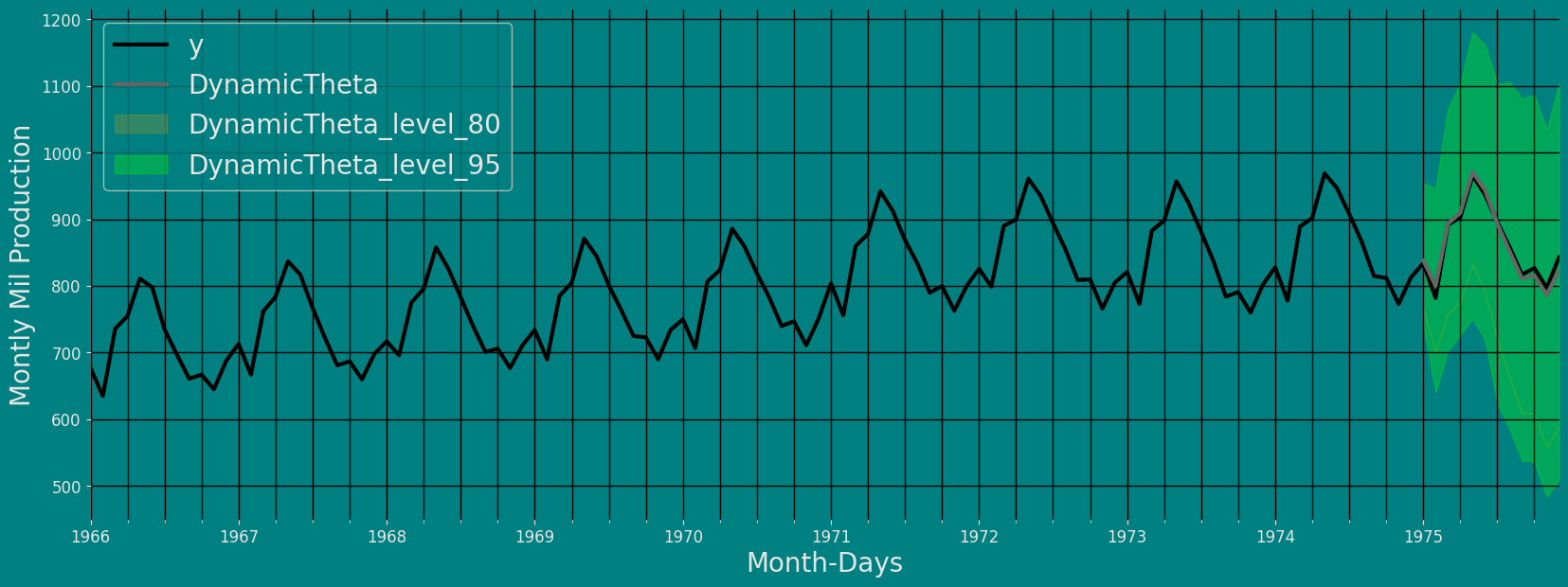
让我们使用 Statsforecast 中的 plot 函数绘制相同的图,如下所示。
sf.plot(df, forecast_df, level=[95])
交叉验证
在之前的步骤中,我们利用历史数据来预测未来。然而,为了评估其准确性,我们还希望了解模型在过去的表现。为了评估模型在数据上的准确性和稳健性,请执行交叉验证。
对于时间序列数据,交叉验证是通过定义一个滑动窗口对历史数据进行处理,并预测其后的时间段来完成的。这种形式的交叉验证使我们能够更好地估计模型在更广泛时间实例下的预测能力,同时保持训练集中数据的连续性,这也是我们的模型所要求的。
下图描述了这种交叉验证策略:

执行时间序列交叉验证
时间序列模型的交叉验证被认为是一种最佳实践,但大多数实现非常缓慢。statsforecast库将交叉验证实现为一种分布式操作,使得这一过程的执行不那么耗时。如果您有大型数据集,还可以使用Ray、Dask或Spark在分布式集群中执行交叉验证。
在这种情况下,我们希望评估每个模型在过去5个月的表现(n_windows=5),每隔两个月进行一次预测(step_size=12)。根据您的计算机,这一步应该大约需要1分钟。
StatsForecast类的cross_validation方法接受以下参数。
df:训练数据框h (int):代表被预测的未来h步。在本例中,预测12个月之后的情况。step_size (int):每个窗口之间的步长。换句话说:您希望多频繁地运行预测过程。n_windows(int):用于交叉验证的窗口数量。换句话说:您希望评估过去多少个预测过程。
crossvalidation_df = sf.cross_validation(df=train,
h=horizon,
step_size=12,
n_windows=3)crossvaldation_df对象是一个新的数据框,包含以下列:
unique_id:索引。如果您不喜欢使用索引,可以运行crossvalidation_df.resetindex()ds:日期戳或时间索引cutoff:n_windows的最后日期戳或时间索引y:真实值"model":包含模型名称和拟合值的列。
crossvalidation_df| ds | cutoff | y | DynamicTheta | |
|---|---|---|---|---|
| unique_id | ||||
| 1 | 1972-01-01 | 1971-12-01 | 826.0 | 827.107239 |
| 1 | 1972-02-01 | 1971-12-01 | 799.0 | 789.924194 |
| 1 | 1972-03-01 | 1971-12-01 | 890.0 | 879.664429 |
| ... | ... | ... | ... | ... |
| 1 | 1974-10-01 | 1973-12-01 | 812.0 | 804.398560 |
| 1 | 1974-11-01 | 1973-12-01 | 773.0 | 775.329285 |
| 1 | 1974-12-01 | 1973-12-01 | 813.0 | 811.767639 |
36 rows × 4 columns
模型评估
我们现在可以使用适当的准确性指标计算预测的准确性。在这里,我们将使用均方根误差(RMSE)。要做到这一点,我们首先需要安装 datasetsforecast,这是一个由 Nixtla 开发的 Python 库,包含一个计算 RMSE 的函数。
%%capture
!pip install datasetsforecastfrom datasetsforecast.losses import rmse计算RMSE的函数接受两个参数:
- 实际值。
- 预测值,在这种情况下是
动态标准Theta模型。
rmse = rmse(crossvalidation_df['y'], crossvalidation_df["DynamicTheta"])
print("RMSE using cross-validation: ", rmse)RMSE using cross-validation: 12.610596正如您所注意到的,我们使用交叉验证的结果来对我们的模型进行评估。
现在我们将根据预测的结果来评估我们的模型,我们将使用不同类型的指标 MAE,MAPE,MASE,RMSE,SMAPE 来评估 准确性。
from datasetsforecast.losses import (mae, mape, mase, rmse, smape)def evaluate_performace(y_hist, y_true, y_pred, model):
y_true = y_true.merge(y_pred, how='left', on=['unique_id', 'ds'])
evaluation = {}
evaluation[model] = {}
for metric in [mase, mae, mape, rmse, smape]:
metric_name = metric.__name__
if metric_name == 'mase':
evaluation[model][metric_name] = metric(y_true['y'].values,
y_true[model].values,
y_hist['y'].values, seasonality=12)
else:
evaluation[model][metric_name] = metric(y_true['y'].values, y_true[model].values)
return pd.DataFrame(evaluation).Tevaluate_performace(train, test, Y_hat, model="DynamicTheta")| mae | mape | mase | rmse | smape | |
|---|---|---|---|---|---|
| DynamicTheta | 8.182119 | 0.97361 | 0.367965 | 9.817624 | 0.974804 |
致谢
我们要感谢Naren Castellon撰写本教程。
参考文献
- Kostas I. Nikolopoulos, Dimitrios D. Thomakos. 《利用Theta方法的预测-理论与应用》。2019年,约翰·威利父子有限公司。
- Jose A. Fiorucci, Tiago R. Pellegrini, Francisco Louzada, Fotios Petropoulos, Anne B. Koehler (2016). “优化theta方法的模型及其与状态空间模型的关系”。《国际预报杂志》。
- Nixtla 参数。
- Pandas 可用频率。
- Rob J. Hyndman和George Athanasopoulos (2018). “预测原则与实践,时间序列交叉验证”。。
- 季节周期- Rob J Hyndman。
Give us a ⭐ on Github