# %pip 安装 statsforecastMFLES
MFLES 是一种基于梯度提升时间序列分解的简单时间序列方法。
有许多方法可以进入提升循环,这取决于用户提供的参数或一些MFLES自动执行的快速逻辑,这似乎工作得不错。一些这些方法包括:
- SES 集合
- 简单移动平均
- 分段线性趋势
- 傅里叶基函数回归以处理季节性
- 简单中位数
- 一种稳健的线性趋势方法
梯度提升分解
这种方法旨在将时间序列分解(趋势、季节性和外生性)视为梯度提升过程中的“弱”估计器。
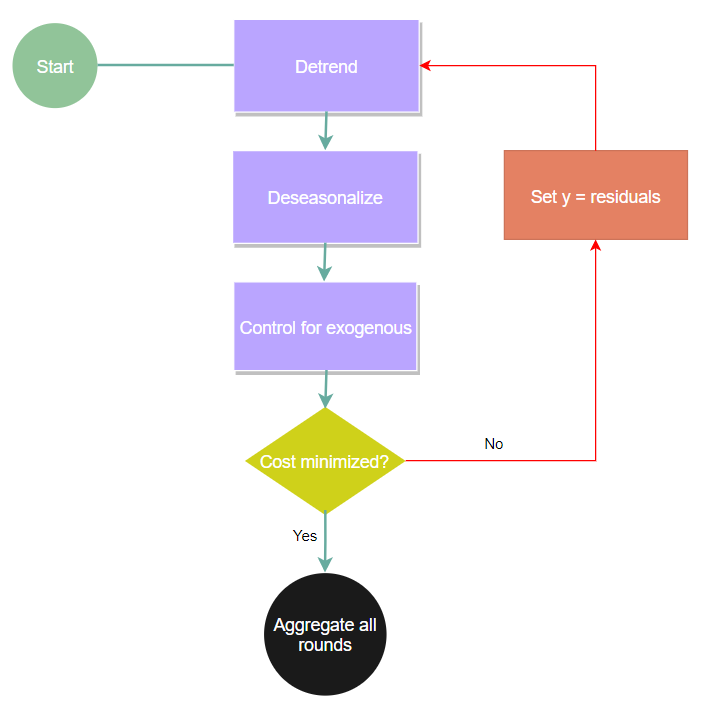
需要注意的主要相关变化有:
- 趋势估计器将始终从简单到复杂。首先是中位数,然后是线性/分段线性,再然后是某种平滑器。
- 多重季节性每次提升轮次拟合一个季节性,而不是同时进行。这意味着你应该按感知的重要性顺序组织你的季节性。此外,理论上,默认情况下你可以有多达50个季节性,但在3个之后你应该预期性能会下降。
- 学习率现在是特定于估计器的,而不是像你在XGBoost中看到的那样是一个单一参数。这在你有外生信号且这些信号也是季节性时特别有用,你可以(这不会自动完成)为季节性信号和外生信号的组合进行优化。
让我们进行预测
在这里,我们将使用Statsforecast中的特定模型对象以及臭名昭著的航空旅客数据集😀:
import pandas as pd
import numpy as np
from statsforecast.models import AutoMFLES
import matplotlib.pyplot as plt
df = pd.read_csv(r'https://raw.githubusercontent.com/jbrownlee/Datasets/master/airline-passengers.csv')
y = df['Passengers'].values # 创建数组
mfles_model = AutoMFLES(
season_length = [12],
test_size = 12,
n_windows=2,
metric = 'smape')
mfles_model.fit(y=y)
predicted = mfles_model.predict(12)['mean']
fitted = mfles_model.predict_in_sample()['fitted']/hdd/github/statsforecast/statsforecast/core.py:30: TqdmExperimentalWarning: Using `tqdm.autonotebook.tqdm` in notebook mode. Use `tqdm.tqdm` instead to force console mode (e.g. in jupyter console)
from tqdm.autonotebook import tqdmplt.plot(np.append(fitted, predicted), linestyle='dashed', color='red')
plt.plot(y)
plt.show()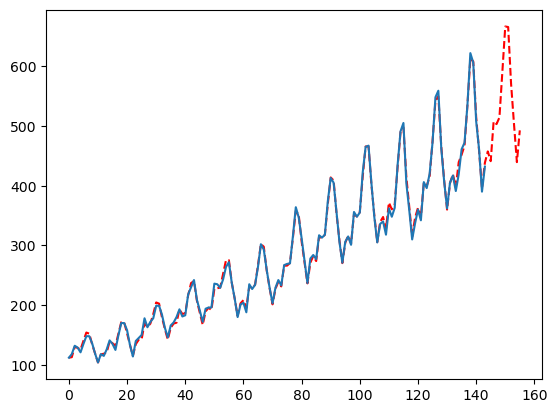
让我们看看标准体验的一些关键参数。
season_length: 一系列季节周期,按感知重要性排序。
test_size: AutoMFLES通过时间序列交叉验证进行优化。测试大小决定每个测试折叠中使用多少个周期。这是优化时最重要的参数,您在设置时应权衡季节长度、预测时间范围和一般数据长度。但一个好的经验法则是使用最重要的季节长度或其一半,以便让MFLES能够捕捉季节性。
n_windows: 用于优化参数的测试集数量。在这个例子中,2意味着我们总共使用24个月(12 * 2),分为2个窗口。
metric: 这个很简单,它只是我们想要优化的参数度量。在这里,我们使用默认值,即默认设置为重现M4实验结果的smape。您还可以传入’rmse’、’mape’或’mae’来优化其他度量。
更深入地探讨一个更自定义的模型
之前的拟合是通过99%的自动逻辑检查和网格搜索参数完成的。但我们可以大大调整拟合(可能调整得过多)。本节将概述一些非常重要的参数及其如何影响输出。
参数网格搜索
首先,看看 AutoMFLES 将尝试的默认参数网格:
config = {
'seasonality_weights': [True, False],
'smoother': [True, False],
'ma': [int(min(seasonal_period)), int(min(seasonal_period)/2), None],
'seasonal_period': [None, seasonal_period],
}- seasonality_weights:如果为 True,在计算季节性时,我们将更加强调较新的观察值。这使得确定性季节性能够更好地反映最近的变化。
- smoother:True 表示我们将在几轮增强后使用简单的指数平滑方法来拟合残差。如果该参数为 False,则使用简单的移动平均。
- ma:此参数是使用移动平均时要包含的过去观察值的数量,None 表示在 ‘smoother’ 为 True 的情况下将半自动设置或忽略。为了优化,我们搜索由您提供的最小季节长度或该数字除以 2。
- seasonal_period:这是您提供的 season_length 列表。
现在让我们看看如何将配置传递给 AutoMFLES,因为这就是我们在后台使用的,结果将是相同的!
season_length = [12]
config = {
'seasonality_weights': [True, False],
'smoother': [True, False],
'ma': [int(min(season_length)), int(min(season_length)/2),None],
'seasonal_period': [None, season_length],
}
mfles_model = AutoMFLES(
season_length = season_length,
test_size = 12,
n_windows=2,
metric = 'smape',
config=config) # 手动添加配置字典
mfles_model.fit(y=y)
predicted = mfles_model.predict(12)['mean']
fitted = mfles_model.predict_in_sample()['fitted']
plt.plot(np.append(fitted, predicted), linestyle='dashed', color='red')
plt.plot(y)
plt.show()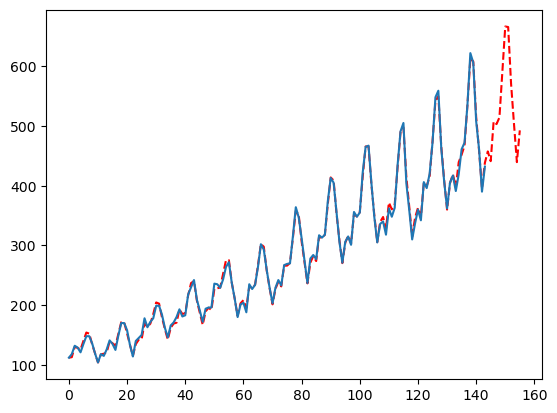
如果你想要强制一个不那么敏感的预测,该怎么办?
只需将smoother设为False,并相对你的季节性调整ma的大小。
season_length = [12]
config = {
'seasonality_weights': [True, False],
'smoother': [False],
'ma': [30],
'seasonal_period': [None, season_length],
}
mfles_model = AutoMFLES(
season_length = season_length,
test_size = 12,
n_windows=2,
metric = 'smape',
config=config) # 手动添加配置字典
mfles_model.fit(y=y)
predicted = mfles_model.predict(12)['mean']
fitted = mfles_model.predict_in_sample()['fitted']
plt.plot(np.append(fitted, predicted), linestyle='dashed', color='red')
plt.plot(y)
plt.show()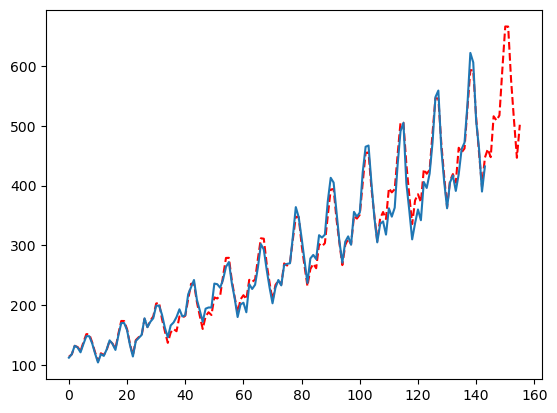
强制 季节性
有时季节性序列会在非季节性设置中自动拟合,要调整这一点并强制季节性,只需在 seasonal_period 列表中去掉 ‘None’ 设置。
这也减少了 MFLES 尝试的配置数量,从而加快了拟合速度。
season_length = [12]
config = {
'seasonality_weights': [True, False],
'smoother': [False],
'ma': [30],
'seasonal_period': [season_length],
}
mfles_model = AutoMFLES(
season_length = season_length,
test_size = 12,
n_windows=2,
metric = 'smape',
config=config) # 手动添加配置字典
mfles_model.fit(y=y)
predicted = mfles_model.predict(12)['mean']
fitted = mfles_model.predict_in_sample()['fitted']
plt.plot(np.append(fitted, predicted), linestyle='dashed', color='red')
plt.plot(y)
plt.show()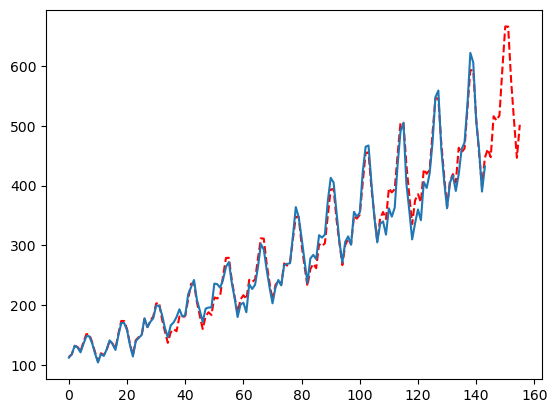
控制复杂性
控制复杂性的一种最佳方法是使用max_rounds参数。默认情况下,此值设置为50,但大多数情况下,模型收敛的速度要快得多。在第4轮时,我们开始将平滑器作为趋势部分实施,因此如果您不想要这个,请将max_rounds设置为3!不过,您可能会想要平滑器!
season_length = [12]
config = {
'seasonality_weights': [True, False],
'smoother': [True, False],
'ma': [int(min(season_length)), int(min(season_length)/2),None],
'seasonal_period': [None, season_length],
'max_rounds': [3],
}
mfles_model = AutoMFLES(
season_length = season_length,
test_size = 12,
n_windows=2,
metric = 'smape',
config=config) # 手动添加配置字典
mfles_model.fit(y=y)
predicted = mfles_model.predict(12)['mean']
fitted = mfles_model.predict_in_sample()['fitted']
plt.plot(np.append(fitted, predicted), linestyle='dashed', color='red')
plt.plot(y)
plt.show()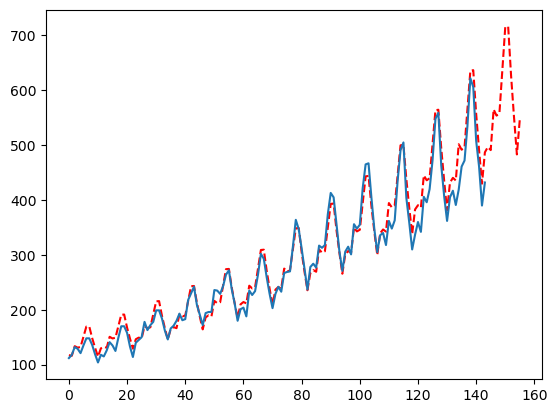
您还可以利用特定估计器的学习率,这些学习率应用于单个估计器,而不是整个提升轮次。当您注意到残差平滑器过快地消耗了太多信号时,这非常有用:
season_length = [12]
config = {
'seasonality_weights': [True, False],
'smoother': [True, False],
'ma': [int(min(season_length)), int(min(season_length)/2),None],
'seasonal_period': [None, season_length],
'rs_lr': [.2],
}
mfles_model = AutoMFLES(
season_length = season_length,
test_size = 12,
n_windows=2,
metric = 'smape',
config=config) # 手动添加配置字典
mfles_model.fit(y=y)
predicted = mfles_model.predict(12)['mean']
fitted = mfles_model.predict_in_sample()['fitted']
plt.plot(np.append(fitted, predicted), linestyle='dashed', color='red')
plt.plot(y)
plt.show()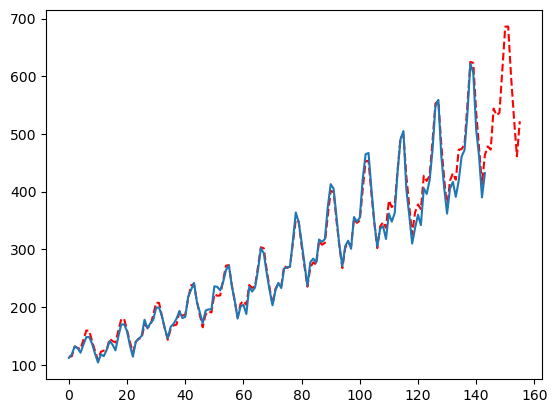
提示与技巧
由于大多数设置都是针对交叉验证优化的,因此准确性和计算之间始终存在权衡。
默认设置是在经过广泛测试后制定的,旨在为您提供一种平衡的方法。希望它能在较短的时间内提供良好的准确性。
但是,还有一些方法可以使您获得更多的准确性(虽然不是革命性的,但可以略微提升)或显著减少运行时间(且不会牺牲太多准确性)。
下一部分将回顾一些这些设置!
测试窗口的数量
在使用时间序列交叉验证进行优化时,窗口的数量直接影响我们为每个参数拟合模型的次数。这里的默认值是 2,但如果您的数据允许,增加到 3 应该会给您带来更一致的结果。显然,窗口数量越多,效果越好,但这会根据您的数据而有所不同。相反,将窗口数量减少到 1 意味着您是基于单一的保留集选择参数,这可能会降低准确性。
season_length = [12]
mfles_model = AutoMFLES(
season_length = season_length,
test_size = 12,
n_windows = 1, # 这里只尝试1个窗口
metric = 'smape')
mfles_model.fit(y=y)
predicted = mfles_model.predict(12)['mean']
fitted = mfles_model.predict_in_sample()['fitted']
plt.plot(np.append(fitted, predicted), linestyle='dashed', color='red')
plt.plot(y)
plt.show()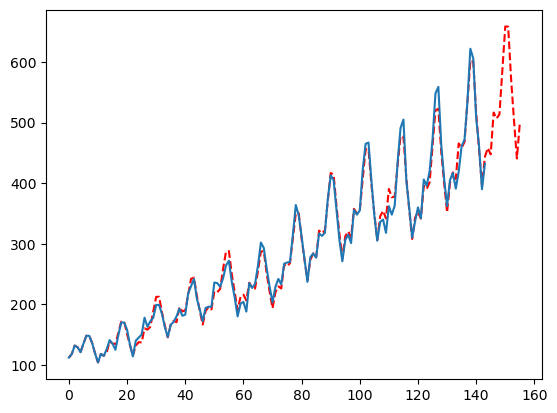
现在尝试使用3,注意到拟合结果不同!
season_length = [12]
mfles_model = AutoMFLES(
season_length = season_length,
test_size = 12,
n_windows = 3, # 这里只尝试1个窗口
metric = 'smape')
mfles_model.fit(y=y)
predicted = mfles_model.predict(12)['mean']
fitted = mfles_model.predict_in_sample()['fitted']
plt.plot(np.append(fitted, predicted), linestyle='dashed', color='red')
plt.plot(y)
plt.show()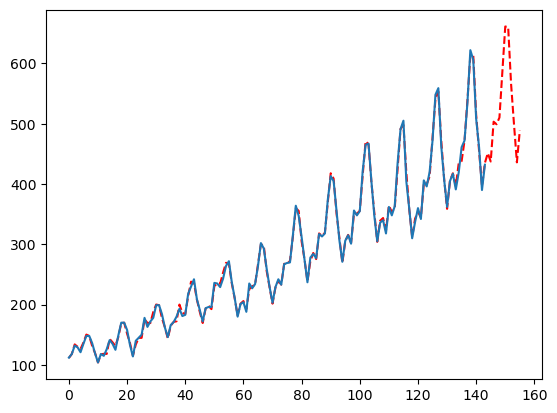
移动平均参数
默认情况下,我们将尝试您的季节长度的最小值,并将其一半作为’ma’参数。这在实际应用中效果很好,但您可能希望大大加深这个搜索。如果您需要从MFLES中获得更高的准确性,这是调整的最佳参数之一。只需将更多参数传递到列表中,理想情况下,这些数字应基于季节性、预测范围或其他一些信息。在我们的案例中,由于这是每月数据,我还将传递3和4。由于这增加了要尝试的参数数量,所以也会增加计算时间。
season_length = [12]
config = {
'seasonality_weights': [True, False],
'smoother': [True, False],
'ma': [3, 4, int(min(season_length)), int(min(season_length)/2),None],
'seasonal_period': [None, season_length],
}
mfles_model = AutoMFLES(
season_length = season_length,
test_size = 12,
n_windows=2,
metric = 'smape',
config=config) # 手动添加配置字典
mfles_model.fit(y=y)
predicted = mfles_model.predict(12)['mean']
fitted = mfles_model.predict_in_sample()['fitted']
plt.plot(np.append(fitted, predicted), linestyle='dashed', color='red')
plt.plot(y)
plt.show()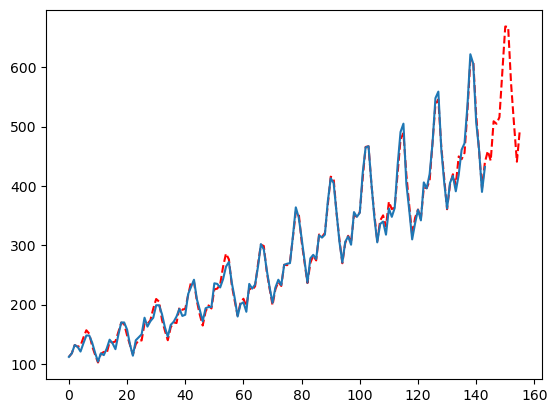
变更点
默认情况下,MFLES会自动检测是否应该使用变更点。这在准确性上有一些好处,但计算开销巨大。您可以禁用变更点,并通常看到接近的准确性,但速度大幅提升:
season_length = [12]
config = {
'changepoints': [False],
'seasonality_weights': [True, False],
'smoother': [True, False],
'ma': [int(min(season_length)), int(min(season_length)/2),None],
'seasonal_period': [None, season_length],
}
mfles_model = AutoMFLES(
season_length = season_length,
test_size = 12,
n_windows=2,
metric = 'smape',
config=config) # 手动添加配置字典
mfles_model.fit(y=y)
predicted = mfles_model.predict(12)['mean']
fitted = mfles_model.predict_in_sample()['fitted']
plt.plot(np.append(fitted, predicted), linestyle='dashed', color='red')
plt.plot(y)
plt.show()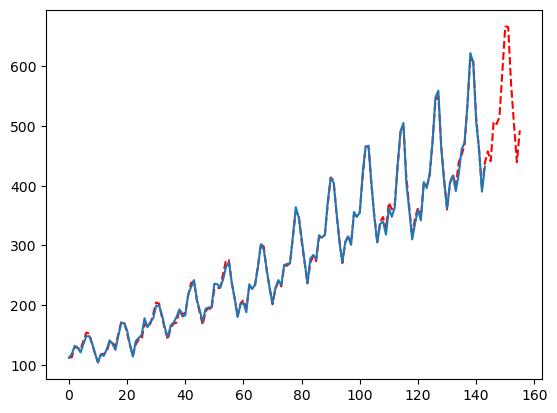
季节性权重
大多数时间序列不会在季节性信号上有显著的变化,或者至少没有值得为之额外计算的变化。为了加快计算速度,您可以禁用此选项。然而,有时禁用此功能可能会导致准确性的大幅下降。
season_length = [12]
config = {
'seasonality_weights': [False],
'smoother': [True, False],
'ma': [int(min(season_length)), int(min(season_length)/2),None],
'seasonal_period': [None, season_length],
}
mfles_model = AutoMFLES(
season_length = season_length,
test_size = 12,
n_windows=2,
metric = 'smape',
config=config) # 手动添加配置字典
mfles_model.fit(y=y)
predicted = mfles_model.predict(12)['mean']
fitted = mfles_model.predict_in_sample()['fitted']
plt.plot(np.append(fitted, predicted), linestyle='dashed', color='red')
plt.plot(y)
plt.show()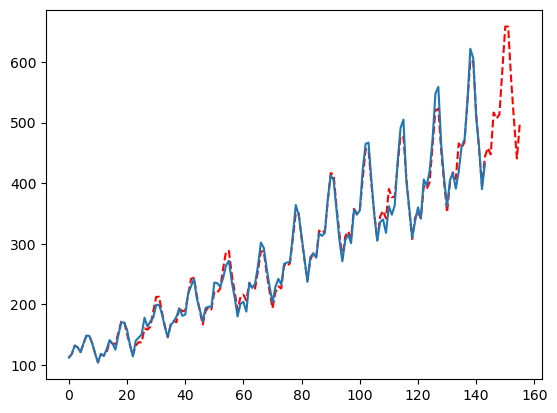
Give us a ⭐ on Github