import polars as pl使用Polars的端到端演练
针对多个时间序列的模型训练、评估和选择
介绍 Polars:高性能的 DataFrame 库
本文档旨在突出强调最近将 Polars 集成到 StatsForecast 功能中的情况。Polars 是一个强大且高速的 DataFrame 库,使用 Rust 开发。凭借其灵活和强大的能力,Polars 在数据科学社区迅速建立了良好的声誉,进一步巩固了其作为管理和操作大量数据集的可靠工具的位置。
Polars 可用于 Rust、Python、Node.js 和 R 等多种语言,展现了以高效和速度处理大规模数据集的卓越能力,超越了许多其他 DataFrame 库,如 Pandas。Polars 的开源特性鼓励持续的改进和贡献,增加了其在数据科学领域的吸引力。
Polars 迅速采用的最重要特性包括:
性能效率:使用 Rust 构建的 Polars 展现出以令人惊讶的速度和极少的内存使用管理大型数据集的能力。
惰性求值:Polars 基于“惰性求值”的原则,创建优化的操作逻辑计划以实现高效执行,这一特性与 Apache Spark 的功能相似。
并行执行:Polars 演示了利用多核 CPU 的能力,支持操作的并行执行,大幅加快数据处理任务的速度。
前置条件
本指南假设您对StatsForecast有基本的了解。要查看最小示例,请访问快速入门
按照本文提供的步骤,您将学习如何构建一个适用于多个时间序列的生产级预测管道。
在本指南中,您将熟悉核心的StatsForecast类以及一些相关方法,如StatsForecast.plot、StatsForecast.forecast和StatsForecast.cross_validation。
我们将使用来自M4竞赛的经典基准数据集。该数据集包含来自金融、经济和销售等不同领域的时间序列。在本示例中,我们将使用小时数据集的一个子集。
我们将分别对每个时间序列进行建模。这种层级的预测也被称为局部预测。因此,您将为每个唯一的序列训练一系列模型,然后选择最佳模型。StatsForecast专注于速度、简单性和可扩展性,使其非常适合此任务。
大纲:
- 安装软件包。
- 读取数据。
- 探索数据。
- 为每个独特的时间序列组合训练多个模型。
- 使用交叉验证评估模型的性能。
- 为每个唯一的时间序列选择最佳模型。
本指南未覆盖的内容
- 使用云上的集群进行大规模预测。
- 使用Ray集群在5分钟内预测M5数据集。
- 使用Spark集群在5分钟内预测M5数据集。
- 学习如何在不到30分钟内预测100万序列。
- 在多季节性上训练模型。
- 在这个电力负荷预测教程中学习使用多季节性。
- 使用外部回归变量或外生变量。
- 参见本教程以包含外生变量,例如天气假期或静态变量,如类别或家族。
- 将StatsForecast与其他流行库进行比较。
- 您可以在这里重现我们的基准。
安装库
我们假设您已经安装了 StatsForecast。请查看本指南以获取有关 如何安装 StatsForecast 的说明。
读取数据
我们将使用polars来读取存储在parquet文件中的M4小时数据集,以提高效率。您可以使用普通的polars操作以其他格式(如.csv)读取数据。
StatsForecast的输入始终是一个具有三列的长格式数据框:unique_id、ds和y:
unique_id(字符串、整数或类别)表示序列的标识符。ds(日期戳或整数)列应为整数索引时间或日期戳,理想情况下格式为YYYY-MM-DD(日期)或YYYY-MM-DD HH:MM:SS(时间戳)。y(数值型)表示我们希望进行预测的测量值。
该数据集已经满足这些要求。
根据您的互联网连接情况,这一步骤大约需要10秒钟。
Y_df = pl.read_parquet('https://datasets-nixtla.s3.amazonaws.com/m4-hourly.parquet')
Y_df.head()
shape: (5, 3)
| unique_id | ds | y |
|---|---|---|
| str | i64 | f64 |
| "H1" | 1 | 605.0 |
| "H1" | 2 | 586.0 |
| "H1" | 3 | 586.0 |
| "H1" | 4 | 559.0 |
| "H1" | 5 | 511.0 |
该数据集包含414个唯一系列,平均有900个观察值。为了本示例和可重复性,我们将仅选择10个唯一ID,并仅保留最后一周的数据。根据您的处理基础设施,可以选择更多或更少的系列。
Note
处理时间取决于可用的计算资源。在AWS的c5d.24xlarge(96个核心)实例上运行此示例的完整数据集大约需要10分钟。
uids = Y_df['unique_id'].unique(maintain_order=True)[:10] # 选择10个ID以加快示例速度
Y_df = Y_df.filter(pl.col('unique_id').is_in(uids))
Y_df = Y_df.group_by('unique_id').tail(7 * 24) #选择最近7天的数据以加快示例运行速度使用plot方法探索数据
使用 StatsForecast 类中的 plot 方法绘制一些时间序列。该方法从数据集中随机打印8个时间序列,对于基本的探索性数据分析(EDA)非常有用。
Note
StatsForecast.plot 方法默认使用matplotlib作为引擎。您可以通过设置 engine="plotly" 来更改为plotly。
from statsforecast import StatsForecast/hdd/github/statsforecast/statsforecast/core.py:26: TqdmExperimentalWarning: Using `tqdm.autonotebook.tqdm` in notebook mode. Use `tqdm.tqdm` instead to force console mode (e.g. in jupyter console)
from tqdm.autonotebook import tqdmStatsForecast.plot(Y_df) 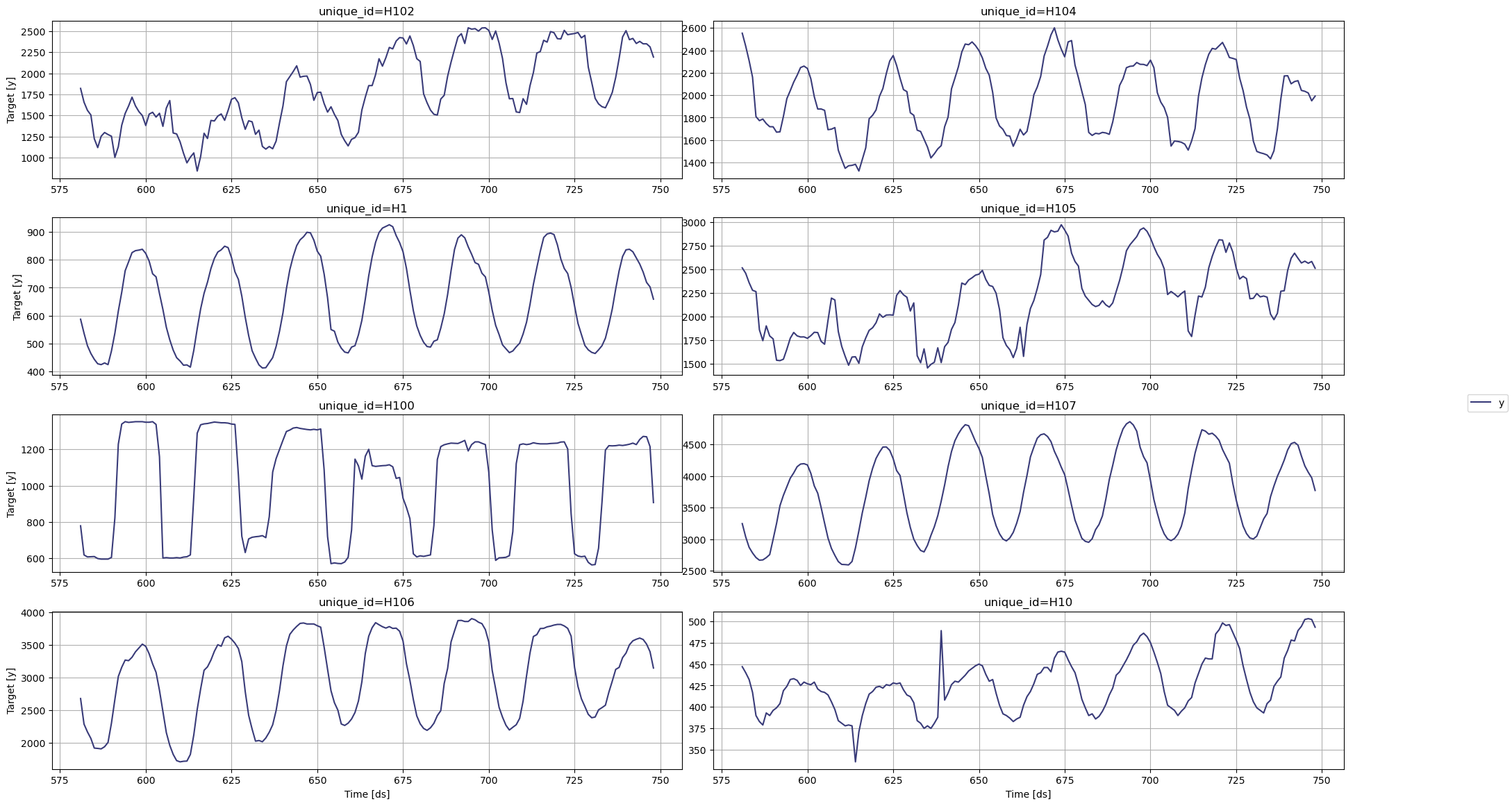
为多个序列训练多个模型
StatsForecast 可以高效地在多个时间序列上训练多个模型。
开始导入和实例化所需的模型。StatsForecast提供了多种模型,分为以下几类:
自动预测(Auto Forecast): 自动预测工具搜索最佳参数并为一系列时间序列选择最佳模型。这些工具适用于大量单变量时间序列。包括:Arima、ETS、Theta、CES的自动版本。
指数平滑(Exponential Smoothing): 使用所有过去观察值的加权平均,权重随时间呈指数下降。适合没有明显趋势或季节性的数据显示。例子:SES、Holt的冬季法、SSO。
基准模型(Benchmark models): 用于建立基线的经典模型。例子:均值、天真法、随机游走。
间歇性或稀疏模型(Intermittent or Sparse models): 适合具有非常少的非零观察值的序列。例子:CROSTON、ADIDA、IMAPA。
多重季节性(Multiple Seasonalities): 适合具有多个明显季节性的信号。对于像电力和日志这样的低频数据非常有用。例子:MSTL。
Theta模型(Theta Models): 适合于去季节化时间序列,使用不同的技术来获取和组合两个theta线以生成最终预测。例子:Theta、DynamicTheta。
在这里您可以查看完整的模型列表。
在本例中,我们将使用:
AutoARIMA:自动选择最佳的ARIMA(自回归积分滑动平均)模型,使用信息准则。参考文献:AutoARIMA。HoltWinters:三重指数平滑,Holt-Winters方法是对同时包含趋势和季节性的序列的指数平滑扩展。参考文献:HoltWinters。SeasonalNaive:内存高效的季节性天真预测。参考文献:SeasonalNaive。HistoricAverage:算术均值。参考文献:HistoricAverage。DynamicOptimizedTheta:theta系列模型在各种数据集(如M3)中表现良好。对去季节化时间序列建模。参考文献:DynamicOptimizedTheta。
导入并实例化模型。设置 season_length 参数有时比较棘手。大师 Rob Hyndmann 的这篇关于 季节周期 的文章可能会很有帮助。
from statsforecast.models import (
HoltWinters,
CrostonClassic as Croston,
HistoricAverage,
DynamicOptimizedTheta as DOT,
SeasonalNaive
)# 创建一个模型及其实例化参数的列表
models = [
HoltWinters(),
Croston(),
SeasonalNaive(season_length=24),
HistoricAverage(),
DOT(season_length=24)
]我们通过实例化一个新的 StatsForecast 对象来拟合模型,使用以下参数:
models:模型列表。选择您想要的模型并从 models 中导入。freq:一个字符串,表示数据的频率。(参见 panda 的可用频率。)这在 Polars 中也可用。n_jobs:int,平行处理使用的作业数量,使用 -1 表示所有核心。fallback_model:一个模型,用于在模型失败时使用。
所有设置都会传递到构造函数中。然后调用它的 fit 方法并传入历史数据框。
# 实例化 StatsForecast 类为 sf
sf = StatsForecast(
models=models,
freq=1,
n_jobs=-1,
fallback_model=SeasonalNaive(season_length=7),
verbose=True
)
Note
StatsForecast 通过 Numba 的 JIT 编译实现了惊人的速度。第一次调用 statsforecast 类时,fit 方法大约需要 5 秒钟。第二次 -一旦 Numba 编译了您的设置- 应该少于 0.2 秒。
forecast 方法接受两个参数:预测下一个 h(时间跨度)和 level。
h(整数):表示预测未来的 h 步。在这个例子中,是指12个月之后。level(浮点数列表):这个可选参数用于概率预测。设置你的预测区间的level(或置信百分位)。例如,level=[90]意味着模型期望真实值在该区间内90%的时间。
这里的 forecast 对象是一个新的数据框,包含一个模型名称的列和 y hat 值,以及不确定性区间的列。根据你的计算机,这一步应该大约需要1分钟。(如果你想把时间缩短到几秒钟,请移除像 ARIMA 和 Theta 这样的自动模型)
Note
forecast 方法与分布式集群兼容,因此不存储任何模型参数。如果您想为每个模型存储参数,可以使用 fit 和 predict 方法。然而,这些方法并未在像 Spark、Ray 或 Dask 这样的分布式引擎中定义。
forecasts_df = sf.forecast(df=Y_df, h=48, level=[90])
forecasts_df.head()
shape: (5, 17)
| unique_id | ds | HoltWinters | HoltWinters-lo-90 | HoltWinters-hi-90 | CrostonClassic | CrostonClassic-lo-90 | CrostonClassic-hi-90 | SeasonalNaive | SeasonalNaive-lo-90 | SeasonalNaive-hi-90 | HistoricAverage | HistoricAverage-lo-90 | HistoricAverage-hi-90 | DynamicOptimizedTheta | DynamicOptimizedTheta-lo-90 | DynamicOptimizedTheta-hi-90 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| str | i64 | f32 | f32 | f32 | f32 | f32 | f32 | f32 | f32 | f32 | f32 | f32 | f32 | f32 | f32 | f32 |
| "H1" | 749 | 829.0 | -246.367554 | 1904.367554 | 829.0 | -246.367554 | 1904.367554 | 635.0 | 537.471191 | 732.528809 | 660.982117 | 398.03775 | 923.926514 | 592.701843 | 577.677307 | 611.652649 |
| "H1" | 750 | 807.0 | -268.367554 | 1882.367554 | 807.0 | -268.367554 | 1882.367554 | 572.0 | 474.471222 | 669.528809 | 660.982117 | 398.03775 | 923.926514 | 525.589111 | 505.449738 | 546.621826 |
| "H1" | 751 | 785.0 | -290.367554 | 1860.367554 | 785.0 | -290.367554 | 1860.367554 | 532.0 | 434.471222 | 629.528809 | 660.982117 | 398.03775 | 923.926514 | 489.251801 | 462.072876 | 512.424133 |
| "H1" | 752 | 756.0 | -319.367554 | 1831.367554 | 756.0 | -319.367554 | 1831.367554 | 493.0 | 395.471222 | 590.528809 | 660.982117 | 398.03775 | 923.926514 | 456.195038 | 430.554291 | 478.260956 |
| "H1" | 753 | 719.0 | -356.367554 | 1794.367554 | 719.0 | -356.367554 | 1794.367554 | 477.0 | 379.471222 | 574.528809 | 660.982117 | 398.03775 | 923.926514 | 436.290527 | 411.051239 | 461.815948 |
使用StatsForecast.plot方法绘制8个随机序列的结果。
sf.plot(Y_df,forecasts_df)
StatsForecast.plot 允许进一步自定义。例如,绘制不同模型和唯一 ID 的结果。
# 将图表绘制为唯一标识符,并选择一些模型
sf.plot(Y_df, forecasts_df, models=["HoltWinters","DynamicOptimizedTheta"], unique_ids=["H10", "H105"], level=[90])
# 探索其他模型
sf.plot(Y_df, forecasts_df, models=["SeasonalNaive"], unique_ids=["H10", "H105"], level=[90])
评估模型的性能
在前面的步骤中,我们使用历史数据来预测未来。然而,为了评估其准确性,我们还希望了解模型在过去的表现。为了评估模型在数据上的准确性和稳健性,请执行交叉验证。
对于时间序列数据,交叉验证是通过定义一个滑动窗口来完成的,该窗口横跨历史数据并预测其后面的时间段。这种形式的交叉验证使我们能够更好地估计模型在更广泛的时间实例上的预测能力,同时保持训练集中数据的连续性,这是我们模型所要求的。
下图描述了这样的交叉验证策略:

时间序列模型的交叉验证被认为是一种最佳实践,但大多数实现速度非常慢。statsforecast库将交叉验证实现为分布式操作,使得执行过程不那么耗时。如果您有大型数据集,还可以使用Ray、Dask或Spark在分布式集群中执行交叉验证。
在这种情况下,我们希望评估每个模型在过去2天的表现(n_windows=2),每隔一天进行一次预测(step_size=48)。根据您的计算机,这一步应该大约需要1分钟。
Tip
设置 n_windows=1 是模拟传统的训练-测试划分,其中我们的历史数据作为训练集,而最后48小时的数据作为测试集。
StatsForecast类中的cross_validation方法接受以下参数。
df:训练数据框h(整数):表示预测的未来h步。在这种情况下,预测24小时。step_size(整数):每个窗口之间的步长。换句话说:您希望多频繁运行预测过程。n_windows(整数):用于交叉验证的窗口数量。换句话说:您希望评估过去多少个预测过程。
crossvaldation_df = sf.cross_validation(
df=Y_df,
h=24,
step_size=24,
n_windows=2
)crossvaldation_df对象是一个新的数据框,包括以下列:
unique_id索引:(如果您不喜欢使用索引,只需运行forecasts_cv_df.resetindex())ds:日期戳或时间索引cutoff:n_windows的最后一个日期戳或时间索引。如果n_windows=1,则有一个唯一的截止值;如果n_windows=2,则有两个唯一的截止值。y:真实值"model":包含模型名称和拟合值的列。
crossvaldation_df.head()
shape: (5, 9)
| unique_id | ds | cutoff | y | HoltWinters | CrostonClassic | SeasonalNaive | HistoricAverage | DynamicOptimizedTheta |
|---|---|---|---|---|---|---|---|---|
| str | i64 | i64 | f32 | f32 | f32 | f32 | f32 | f32 |
| "H1" | 701 | 700 | 619.0 | 847.0 | 742.668762 | 691.0 | 661.674988 | 612.767517 |
| "H1" | 702 | 700 | 565.0 | 820.0 | 742.668762 | 618.0 | 661.674988 | 536.846252 |
| "H1" | 703 | 700 | 532.0 | 790.0 | 742.668762 | 563.0 | 661.674988 | 497.82428 |
| "H1" | 704 | 700 | 495.0 | 784.0 | 742.668762 | 529.0 | 661.674988 | 464.723236 |
| "H1" | 705 | 700 | 481.0 | 752.0 | 742.668762 | 504.0 | 661.674988 | 440.972351 |
接下来,我们将使用常见的误差指标(如平均绝对误差(MAE)或均方误差(MSE))评估每个模型在每个系列上的性能。 定义一个实用函数来评估交叉验证数据框的不同误差指标。
首先从datasetsforecast.losses导入所需的误差指标。然后定义一个实用函数,该函数接受一个交叉验证数据框作为参数,并返回一个评估数据框,包含每个唯一ID和拟合模型及所有截断值的误差指标平均值。
from utilsforecast.losses import mse
from utilsforecast.evaluation import evaluatedef evaluate_cross_validation(df, metric):
models = [c for c in df.columns if c not in ('unique_id', 'ds', 'cutoff', 'y')]
evals = []
# 计算每个唯一标识符和截止时间的损失。
for cutoff in df['cutoff'].unique():
eval_ = evaluate(df.filter(pl.col('cutoff') == cutoff), metrics=[metric], models=models)
evals.append(eval_)
evals = pl.concat(evals).drop('metric')
# Calculate the mean of each 'unique_id' group
evals = evals.group_by(['unique_id'], maintain_order=True).mean()
# For each row in evals (excluding 'unique_id'), find the model with the lowest value
best_model = [min(row, key=row.get) for row in evals.drop('unique_id').rows(named=True)]
# Add a 'best_model' column to evals dataframe with the best model for each 'unique_id'
evals = evals.with_columns(pl.Series(best_model).alias('best_model')).sort(by=['unique_id'])
return evals
Warning
您也可以使用平均绝对百分比误差 (MAPE),然而对于细粒度的预测,MAPE 值非常难以判断,并且对评估预测质量没有帮助。
创建一个数据框,包含使用均方误差指标评估的交叉验证数据框的结果。
evaluation_df = evaluate_cross_validation(crossvaldation_df, mse)
evaluation_df.head()
shape: (5, 7)
| unique_id | HoltWinters | CrostonClassic | SeasonalNaive | HistoricAverage | DynamicOptimizedTheta | best_model |
|---|---|---|---|---|---|---|
| str | f32 | f32 | f32 | f32 | f32 | str |
| "H1" | 44888.019531 | 28038.734375 | 1422.666748 | 20927.666016 | 1296.333984 | "DynamicOptimiz… |
| "H10" | 2812.916504 | 1483.483887 | 96.895828 | 1980.367676 | 379.621094 | "SeasonalNaive" |
| "H100" | 121625.375 | 91945.140625 | 12019.0 | 78491.195312 | 21699.648438 | "SeasonalNaive" |
| "H101" | 28453.394531 | 16183.631836 | 10944.458008 | 18208.404297 | 63698.070312 | "SeasonalNaive" |
| "H102" | 232924.84375 | 132655.3125 | 12699.896484 | 309110.46875 | 31393.519531 | "SeasonalNaive" |
| 模型 | 表现最佳的序列数量 |
|---|---|
| Arima | 10 |
| Seasonal Naive | 10 |
| Theta | 2 |
select_cols = ['best_model', 'unique_id']
summary_df = (
evaluation_df
.group_by('best_model')
.n_unique()
[select_cols]
.sort(by='unique_id')
.rename(dict(zip(select_cols, ["Model", "Nr. of unique_ids"])))
)
summary_df
shape: (2, 2)
| Model | Nr. of unique_ids |
|---|---|
| str | u32 |
| "DynamicOptimiz… | 4 |
| "SeasonalNaive" | 6 |
您可以通过绘制特定模型获胜的 unique_ids 来进一步探索您的结果。
seasonal_ids = evaluation_df.filter(pl.col('best_model') == 'SeasonalNaive')['unique_id']
sf.plot(Y_df,forecasts_df, unique_ids=seasonal_ids, models=["SeasonalNaive","DynamicOptimizedTheta"])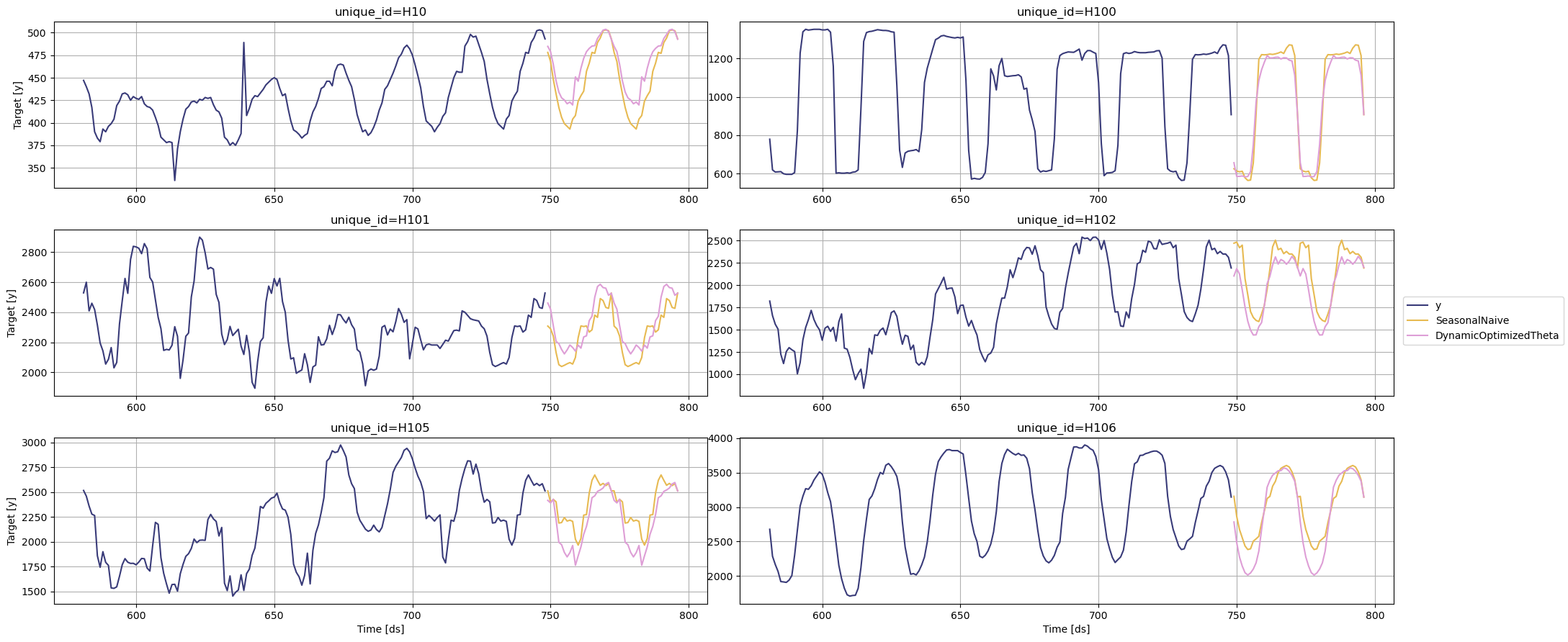
为每个独特系列选择最佳模型
定义一个工具函数,该函数接受包含预测的你的预测数据框和评估数据框,并返回每个 unique_id 的最佳预测数据框。def get_best_model_forecast(forecasts_df, evaluation_df):
# Melt the 'forecasts_df' dataframe to long format, where each row represents
# a unique ID, a timestamp, a model, and that model's forecast.
df = (
forecasts_df
.melt(
id_vars=["unique_id", "ds"],
value_vars=forecasts_df.columns[2:],
variable_name="model",
value_name="best_model_forecast"
)
# Join this dataframe with 'evaluation_df' on 'unique_id', attaching
# the 'best_model' for each unique ID.
.join(
evaluation_df[['unique_id', 'best_model']],
on='unique_id',
how="left",
)
)
# Clean up the 'model' names by removing "-lo-90" and "-hi-90" from them,
# and store the cleaned names in a new column called 'clean_model'.
# Filter the dataframe to keep only the rows where 'clean_model' matches 'best_model'.
# After that, drop the 'clean_model' and 'best_model' columns, as they are no longer needed.
df = (
df
.with_columns(
pl.col('model').str.replace("-lo-90|-hi-90", "").alias("clean_model")
)
.filter(pl.col('clean_model') == pl.col('best_model'))
.drop('clean_model', 'best_model')
)
# Rename all the 'model' names to "best_model" for clarity,
# because at this point the dataframe only contains forecasts from the best model for each unique ID.
# Then, reshape the dataframe back to wide format using the 'pivot()' method.
# The pivoted dataframe has one row per unique ID and timestamp, with a column for each 'model'
# (in this case, all models are renamed to 'best_model'), and the value in each cell is the 'best_model_forecast'.
# The 'pivot()' method requires an aggregate function to apply if there are multiple values for the same index and column.
# Here, it uses 'first', meaning it keeps the first value if there are multiple.
# Finally, sort the dataframe by 'unique_id' and 'ds'.
return (
df
.with_columns(
pl.col('model').str.replace("[A-Za-z0-9]+", "best_model")
)
.pivot(
values='best_model_forecast',
index=['unique_id', 'ds'],
columns='model',
aggregate_function='first',
)
.sort(by=['unique_id', 'ds'])
)
创建一个生产就绪的数据框,以便为每个 unique_id 提供最佳预测。
prod_forecasts_df = get_best_model_forecast(forecasts_df, evaluation_df)
prod_forecasts_df.head()
shape: (5, 5)
| unique_id | ds | best_model | best_model-lo-90 | best_model-hi-90 |
|---|---|---|---|---|
| str | i64 | f32 | f32 | f32 |
| "H1" | 749 | 592.701843 | 577.677307 | 611.652649 |
| "H1" | 750 | 525.589111 | 505.449738 | 546.621826 |
| "H1" | 751 | 489.251801 | 462.072876 | 512.424133 |
| "H1" | 752 | 456.195038 | 430.554291 | 478.260956 |
| "H1" | 753 | 436.290527 | 411.051239 | 461.815948 |
绘制结果。
sf.plot(Y_df, prod_forecasts_df, level=[90])
Give us a ⭐ on Github