# 此单元格不会被渲染,但用于隐藏警告
import warnings
warnings.filterwarnings("ignore")
import logging
logging.getLogger('statsforecast').setLevel(logging.ERROR)
import pandas as pd
pd.set_option('display.max_rows', 6)AutoARIMA模型
使用
Statsforecast的AutoARIMA模型逐步指南。
本文的目标是提供一个关于如何使用Statsforecast构建Arima模型的逐步指南。
在这次演练中,我们将熟悉主要的StatsForecast类以及一些相关的方法,如StatsForecast.plot、StatsForecast.forecast和StatsForecast.cross_validation。
目录
什么是StatsForecast中的AutoArima?
autoARIMA是一种时间序列模型,它使用自动化的过程为给定的时间序列选择最优的ARIMA(自回归积分滑动平均)模型参数。ARIMA是一种广泛使用的统计模型,用于建模和预测时间序列。
autoARIMA模型中的自动参数选择过程使用统计和优化技术,例如赤池信息量准则(AIC)和交叉验证,来识别自回归、积分和滑动平均参数的最佳值。
自动参数选择非常有用,因为在没有深入理解生成时间序列的底层随机过程的情况下,很难确定给定时间序列的ARIMA模型的最优参数。autoARIMA模型自动化了参数选择过程,能够为时间序列建模和预测提供快速有效的解决方案。
statsforecast.models库中的AutoARIMA函数是Python提供的一个autoARIMA实现,能够根据时间序列自动选择ARIMA模型的最优参数。
ARIMA模型的定义
ARIMA模型(自回归积分滑动平均)过程是自回归过程AR(p)、积分I(d)和滑动平均过程MA(q)的组合。
和ARMA过程一样,ARIMA过程指出当前值依赖于过去的值,这来自AR(p)部分,以及过去的误差,这来自MA(q)部分。然而,ARIMA过程使用的是差分后的系列,记作\(y'_{t}\),而不是原始系列,记作\(y_t\)。注意,\(y'_{t}\)可以表示经过多次差分的系列。
因此,ARIMA(p,d,q)过程的数学表达式表示差分系列\(y'_{t}\)的当前值等于一个常数\(C\)、差分系列的过去值\(\phi_{p}y'_{t-p}\)、差分系列的均值\(\mu\)、过去的误差项\(\theta_{q}\varepsilon_{t-q}\)和当前的误差项\(\varepsilon_{t}\)的总和,如下方程所示:
\[\begin{equation} y'_{t} = c + \phi_{1}y'_{t-1} + \cdots + \phi_{p}y'_{t-p} + \theta_{1}\varepsilon_{t-1} + \cdots + \theta_{q}\varepsilon_{t-q} + \varepsilon_{t}, \tag{1} \end{equation}\]
其中\(y'_{t}\)是差分系列(它可能已经差分多次)。右侧的“预测变量”包括\(y_{t}\)的滞后值和滞后误差。我们称之为ARIMA( p,d,q)模型,其中:
| p | 自回归部分的阶数 |
| d | 涉及的首次差分的程度 |
| q | 滑动平均部分的阶数 |
与自回归和滑动平均模型使用的平稳性和可逆性条件也适用于ARIMA模型。
我们已经讨论的许多模型都是ARIMA模型的特例,如下表所示:
| 模型 | p d q | 差分形式 | 方法 |
|---|---|---|---|
| ARIMA(0,0,0) | 0 0 0 | \(y_t=Y_t\) | 白噪声 |
| ARIMA (0,1,0) | 0 1 0 | \(y_t = Y_t - Y_{t-1}\) | 随机游走 |
| ARIMA (0,2,0) | 0 2 0 | \(y_t = Y_t - 2Y_{t-1} + Y_{t-2}\) | 常数 |
| ARIMA (1,0,0) | 1 0 0 | \(\hat Y_t = \mu + \Phi_1 Y_{t-1} + \epsilon\) | AR(1): 一阶回归模型 |
| ARIMA (2, 0, 0) | 2 0 0 | \(\hat Y_t = \Phi_0 + \Phi_1 Y_{t-1} + \Phi_2 Y_{t-2} + \epsilon\) | AR(2): 二阶回归模型 |
| ARIMA (1, 1, 0) | 1 1 0 | \(\hat Y_t = \mu + Y_{t-1} + \Phi_1 (Y_{t-1}- Y_{t-2})\) | 差分一阶自回归模型 |
| ARIMA (0, 1, 1) | 0 1 1 | \(\hat Y_t = Y_{t-1} - \Phi_1 e^{t-1}\) | 简单指数平滑 |
| ARIMA (0, 0, 1) | 0 0 1 | \(\hat Y_t = \mu_0+ \epsilon_t - \omega_1 \epsilon_{t-1}\) | MA(1): 一阶回归模型 |
| ARIMA (0, 0, 2) | 0 0 2 | \(\hat Y_t = \mu_0+ \epsilon_t - \omega_1 \epsilon_{t-1} - \omega_2 \epsilon_{t-2}\) | MA(2): 二阶回归模型 |
| ARIMA (1, 0, 1) | 1 0 1 | \(\hat Y_t = \Phi_0 + \Phi_1 Y_{t-1}+ \epsilon_t - \omega_1 \epsilon_{t-1}\) | ARMA模型 |
| ARIMA (1, 1, 1) | 1 1 1 | \(\Delta Y_t = \Phi_1 Y_{t-1} + \epsilon_t - \omega_1 \epsilon_{t-1}\) | ARIMA模型 |
| ARIMA (1, 1, 2) | 1 1 2 | \(\hat Y_t = Y_{t-1} + \Phi_1 (Y_{t-1} - Y_{t-2} )- \Theta_1 e_{t-1} - \Theta_1 e_{t-1}\) | 阶段衰减线性指数平滑 |
| ARIMA (0, 2, 1)或(0,2,2) | 0 2 1 | \(\hat Y_t = 2 Y_{t-1} - Y_{t-2} - \Theta_1 e_{t-1} - \Theta_2 e_{t-2}\) | 线性指数平滑 |
一旦我们以这种方式开始组合组件以形成更复杂的模型,使用反向推迟符号将更加方便。例如,方程(1)可以用反向推迟符号写成:
\[\begin{equation} \tag{2} \begin{array}{c c c c} (1-\phi_1B - \cdots - \phi_p B^p) & (1-B)^d y_{t} &= &c + (1 + \theta_1 B + \cdots + \theta_q B^q)\varepsilon_t\\ {\uparrow} & {\uparrow} & &{\uparrow}\\ \text{AR($p$)} & \text{$d$次差分} & & \text{MA($q$)}\\ \end{array} \end{equation}\]
选择p、d和q的适当值可能很困难。然而,statsforecast中的AutoARIMA()函数将自动为您完成这一工作。
更多信息请 点击这里
加载库和数据
使用 AutoARIMA() 模型对时间序列进行建模和预测有几个优点,包括:
参数选择过程的自动化:
AutoARIMA()函数自动化了 ARIMA 模型的参数选择过程,这可以通过消除手动尝试不同参数组合的需要,节省用户的时间和精力。预测误差的减少:通过自动选择最佳参数,ARIMA 模型可以提高预测的准确性,相较于手动选择的 ARIMA 模型。
复杂模式的识别:
AutoARIMA()函数可以识别数据中可能难以用目视或其他时间序列建模技术检测的复杂模式。参数选择方法的灵活性:ARIMA 模型可以使用不同的方式来选择最佳参数,例如赤池信息量准则(AIC)、交叉验证等,这允许用户选择最适合自己需求的方法。
总体而言,使用 AutoARIMA() 函数可以帮助提高时间序列建模和预测的效率和准确性,特别是对于对 ARIMA 模型手动参数选择不熟悉的用户。
主要结果
我们将准确性和速度与pmdarima、Rob Hyndman 的forecast包以及Facebook的Prophet进行了比较。我们使用了来自M4比赛的Daily、Hourly和Weekly数据。
以下表格总结了结果。如表所示,我们的auto_arima在准确性(通过MASE损失衡量)和时间方面都是最佳模型,甚至与R中的原始实现相比。
| 数据集 | 指标 | auto_arima_nixtla | auto_arima_pmdarima [1] | auto_arima_r | prophet |
|---|---|---|---|---|---|
| 每日 | MASE | 3.26 | 3.35 | 4.46 | 14.26 |
| 每日 | 时间 | 1.41 | 27.61 | 1.81 | 514.33 |
| 每小时 | MASE | 0.92 | — | 1.02 | 1.78 |
| 每小时 | 时间 | 12.92 | — | 23.95 | 17.27 |
| 每周 | MASE | 2.34 | 2.47 | 2.58 | 7.29 |
| 每周 | 时间 | 0.42 | 2.92 | 0.22 | 19.82 |
[1] pmdarima中的模型auto_arima在每小时数据上出现了问题。已开启一个问题。
以下表格总结了数据的详细信息。
| 组别 | 系列数 | 平均长度 | 标准长度 | 最小长度 | 最大长度 |
|---|---|---|---|---|---|
| 每日 | 4,227 | 2,371 | 1,756 | 107 | 9,933 |
| 每小时 | 414 | 901 | 127 | 748 | 1,008 |
| 每周 | 359 | 1,035 | 707 | 93 | 2,610 |
加载库和数据
Tip
将需要使用Statsforecast。有关安装,请参见说明。
接下来,我们导入绘图库并配置绘图样式。
import numpy as np
import pandas as pd
import scipy.stats as statsimport matplotlib.pyplot as plt
import seaborn as sns
from statsmodels.graphics.tsaplots import plot_acf
from statsmodels.graphics.tsaplots import plot_pacf
plt.style.use('fivethirtyeight')
plt.rcParams['lines.linewidth'] = 1.5
dark_style = {
'figure.facecolor': '#212946',
'axes.facecolor': '#212946',
'savefig.facecolor':'#212946',
'axes.grid': True,
'axes.grid.which': 'both',
'axes.spines.left': False,
'axes.spines.right': False,
'axes.spines.top': False,
'axes.spines.bottom': False,
'grid.color': '#2A3459',
'grid.linewidth': '1',
'text.color': '0.9',
'axes.labelcolor': '0.9',
'xtick.color': '0.9',
'ytick.color': '0.9',
'font.size': 12 }
plt.rcParams.update(dark_style)
from pylab import rcParams
rcParams['figure.figsize'] = (18,7)加载数据
df = pd.read_csv("https://raw.githubusercontent.com/Naren8520/Serie-de-tiempo-con-Machine-Learning/main/Data/candy_production.csv")
df.head()| observation_date | IPG3113N | |
|---|---|---|
| 0 | 1972-01-01 | 85.6945 |
| 1 | 1972-02-01 | 71.8200 |
| 2 | 1972-03-01 | 66.0229 |
| 3 | 1972-04-01 | 64.5645 |
| 4 | 1972-05-01 | 65.0100 |
StatsForecast 的输入始终是一个具有三列的长格式数据框:unique_id、ds 和 y:
unique_id(字符串、整数或类别)表示序列的标识符。ds(日期戳)列应为 Pandas 所期望的格式,理想情况下为 YYYY-MM-DD 的日期格式或 YYYY-MM-DD HH:MM:SS 的时间戳格式。y(数值)表示我们希望进行预测的测量值。
df["unique_id"]="1"
df.columns=["ds", "y", "unique_id"]
df.head()| ds | y | unique_id | |
|---|---|---|---|
| 0 | 1972-01-01 | 85.6945 | 1 |
| 1 | 1972-02-01 | 71.8200 | 1 |
| 2 | 1972-03-01 | 66.0229 | 1 |
| 3 | 1972-04-01 | 64.5645 | 1 |
| 4 | 1972-05-01 | 65.0100 | 1 |
print(df.dtypes)ds object
y float64
unique_id object
dtype: object我们需要将 ds 从 object 类型转换为 datetime。
df["ds"] = pd.to_datetime(df["ds"])使用plot方法探索数据
使用StatsForecast类中的plot方法绘制序列。此方法从数据集中打印随机序列,对于基本的探索性数据分析(EDA)非常有用。
from statsforecast import StatsForecast
StatsForecast.plot(df, engine="matplotlib")
自相关图
fig, axs = plt.subplots(nrows=1, ncols=2)
plot_acf(df["y"], lags=60, ax=axs[0],color="fuchsia")
axs[0].set_title("Autocorrelation");
plot_pacf(df["y"], lags=60, ax=axs[1],color="lime")
axs[1].set_title('Partial Autocorrelation')
plt.show();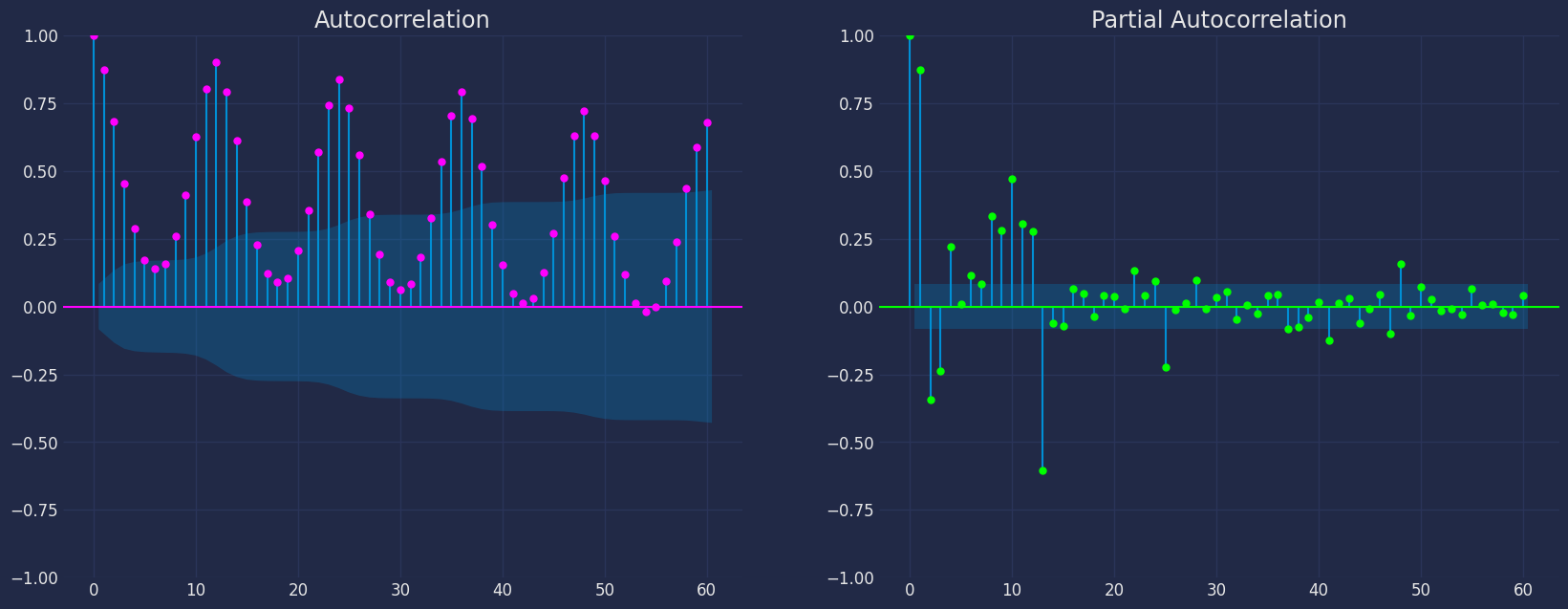
时间序列的分解
如何分解时间序列以及为什么?
在时间序列分析中,为了预测新值,了解过去数据是非常重要的。更正式地说,了解随时间变化的值所遵循的模式是非常重要的。有很多原因可能导致我们的预测值走向错误的方向。基本上,一个时间序列由四个组成部分构成。这些组成部分的变化导致时间序列模式的变化。这些组成部分是:
- 水平(Level): 这是随时间平均的主要值。
- 趋势(Trend): 趋势是导致时间序列中出现上升或下降模式的值。
- 季节性(Seasonality): 这是在时间序列中短时间内发生的周期性事件,并导致时间序列中出现短期的上升或下降模式。
- 残差/噪声(Residual/Noise): 这些是时间序列中的随机变化。
这些组成部分随时间的组合导致时间序列的形成。大多数时间序列由水平和噪声/残差组成,趋势或季节性是可选值。
如果季节性和趋势是时间序列的一部分,那么将会对预测值产生影响。因为预测时间序列的模式可能与之前的时间序列有所不同。
时间序列组成部分的组合可以有两种类型: * 加性(Additive) * 乘性(Multiplicative)
加性时间序列
如果时间序列的组成部分是相加形成时间序列的,则该时间序列称为加性时间序列。通过可视化,我们可以说,如果时间序列的上升或下降模式在整个序列中是相似的,则时间序列是加性的。任何加性时间序列的数学函数可以表示为: \[y(t) = level + Trend + seasonality + noise\]
乘性时间序列
如果时间序列的组成部分是相乘在一起的,那么该时间序列称为乘性时间序列。通过可视化,如果时间序列随着时间的推移呈现指数增长或下降,则该时间序列可以视为乘性时间序列。乘性时间序列的数学函数可以表示为: \[y(t) = Level * Trend * seasonality * Noise\]
from statsmodels.tsa.seasonal import seasonal_decompose
a = seasonal_decompose(df["y"], model = "add", period=12)
a.plot();
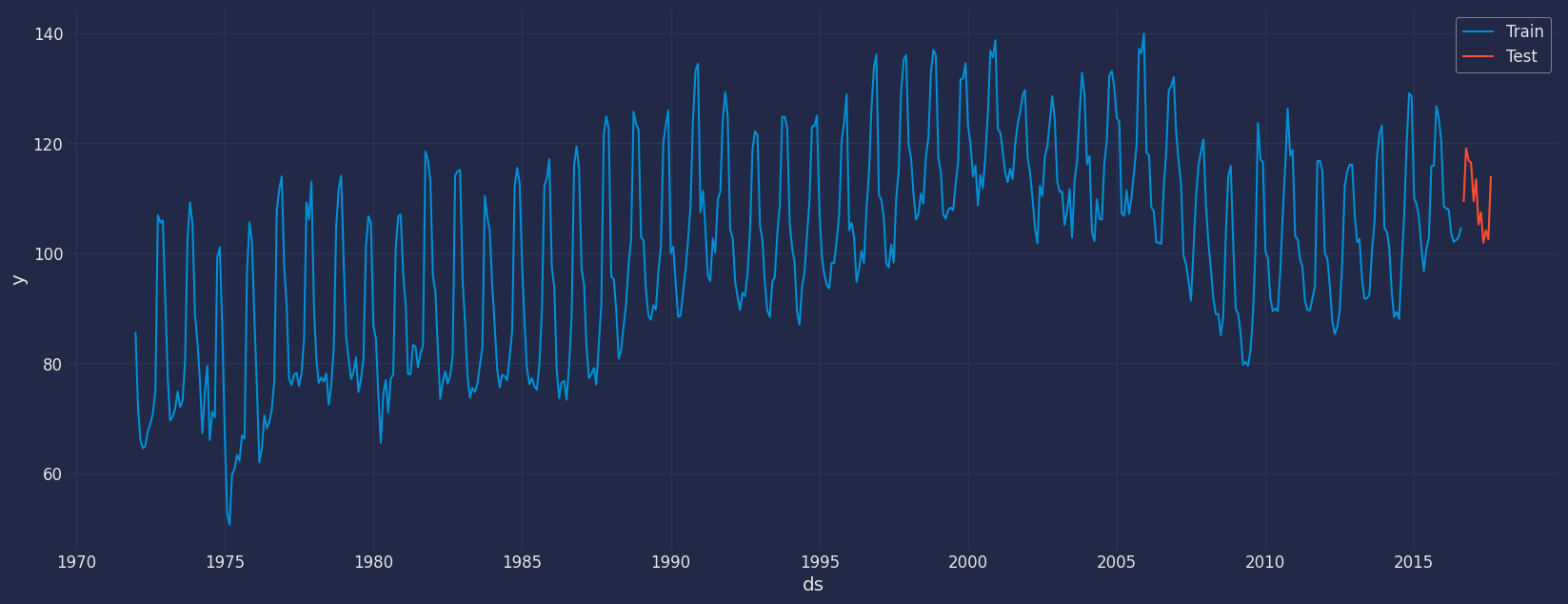
将数据划分为训练集和测试集
让我们将数据划分为几组 1. 用于训练我们的 AutoArima 模型的数据 2. 用于测试我们模型的数据
对于测试数据,我们将使用过去12个月的数据来测试和评估我们模型的性能。
Y_train_df = df[df.ds<='2016-08-01']
Y_test_df = df[df.ds>'2016-08-01'] Y_train_df.shape, Y_test_df.shape((536, 3), (12, 3))现在让我们绘制训练数据和测试数据。
sns.lineplot(Y_train_df,x="ds", y="y", label="Train")
sns.lineplot(Y_test_df, x="ds", y="y", label="Test")
plt.show()
AutoArima的实现与StatsForecast
要更深入了解AutoARIMA模型的函数参数,以下是相关列表。有关更多信息,请访问文档
d : Optional[int]
首次差分的阶数。
D : Optional[int]
季节性差分的阶数。
max_p : int
最大自回归阶数p。
max_q : int
最大移动平均阶数q。
max_P : int
最大季节性自回归阶数P。
max_Q : int
最大季节性移动平均阶数Q。
max_order : int
如果不使用逐步选择,最大p+q+P+Q值。
max_d : int
最大非季节性差分。
max_D : int
最大季节性差分。
start_p : int
逐步程序中p的起始值。
start_q : int
逐步程序中q的起始值。
start_P : int
逐步程序中P的起始值。
start_Q : int
逐步程序中Q的起始值。
stationary : bool
如果为True,限制搜索为平稳模型。
seasonal : bool
如果为False,限制搜索为非季节性模型。
ic : str
用于模型选择的信息准则。
stepwise : bool
如果为True,将进行逐步选择(更快)。
nmodels : int
在逐步搜索中考虑的模型数量。
trace : bool
如果为True,将报告搜索的ARIMA模型。
approximation : Optional[bool]
如果为True,使用条件平方和估计,最终MLE。
method : Optional[str]
最大似然或平方和之间的拟合方法。
truncate : Optional[int]
用于模型选择的观察值截断序列。
test : str
使用的单位根检验。有关详情,请参见`ndiffs`。
test_kwargs : Optional[str]
单位根检验的附加参数。
seasonal_test : str
季节差分的选择方法。
seasonal_test_kwargs : Optional[dict]
季节单位根检验参数。
allowdrift : bool (default True)
如果为True,考虑漂移模型项。
allowmean : bool (default True)
如果为True,考虑非零均值模型。
blambda : Optional[float]
Box-Cox变换参数。
biasadj : bool
使用调整后的反向变换均值Box-Cox。
season_length : int
每个时间单位的观察数。例如:24小时数据。
alias : str
模型的自定义名称。
prediction_intervals : Optional[ConformalIntervals]
用于计算保型预测区间的信息。
默认情况下,模型将计算原生预测区间。加载库
from statsforecast import StatsForecast
from statsforecast.models import AutoARIMA
from statsforecast.arima import arima_string实例化模型
导入并实例化模型。设置参数有时比较棘手。罗布·海德曼(Rob Hyndmann)的这篇关于季节周期 的文章可能会有所帮助。season_length
season_length = 12 # 月度数据
horizon = len(Y_test_df) # 预测数量
models = [AutoARIMA(season_length=season_length)]我们通过实例化一个新的 StatsForecast 对象来拟合模型,使用以下参数:
模型:一个模型列表。从模型中选择所需的模型并导入它们。
freq:一个字符串,指示数据的频率。(参见 pandas 提供的可用频率。)n_jobs:n_jobs: int,进行并行处理时使用的作业数量,使用 -1 表示所有核心。fallback_model:如果某个模型失败时使用的备选模型。
任何设置都将传递给构造函数。然后调用其 fit 方法并传入历史数据框。
sf = StatsForecast(df=Y_train_df,
models=models,
freq='MS',
n_jobs=-1)拟合模型
sf.fit()StatsForecast(models=[AutoARIMA])一旦我们输入了模型,就可以使用 arima_string 函数查看模型找到的参数。
arima_string(sf.fitted_[0,0].model_)'ARIMA(1,0,0)(0,1,2)[12] '自动化过程告诉我们,找到的最佳模型是形如 ARIMA(1,0,0)(0,1,2)[12] 的模型,这意味着我们的模型包含 \(p=1\),也就是说它具有一个非季节性自回归元素;另一方面,我们的模型包含一个季节性部分,其阶数为 \(D=1\),也就是说它具有一个季节性差分,以及 \(q=2\),这包含两个移动平均元素。
要了解我们模型术语的值,我们可以使用以下语句来了解模型产生的所有结果。
result=sf.fitted_[0,0].model_
print(result.keys())
print(result['arma'])dict_keys(['coef', 'sigma2', 'var_coef', 'mask', 'loglik', 'aic', 'arma', 'residuals', 'code', 'n_cond', 'nobs', 'model', 'bic', 'aicc', 'ic', 'xreg', 'x', 'lambda'])
(1, 0, 0, 2, 12, 0, 1)现在让我们来可视化我们模型的残差。
如我们所见,上述结果以字典形式输出,为了从字典中提取每个元素,我们将使用 .get() 函数提取元素,然后将其保存到 pd.DataFrame() 中。
residual=pd.DataFrame(result.get("residuals"), columns=["residual Model"])
residual| residual Model | |
|---|---|
| 0 | 0.085694 |
| 1 | 0.071820 |
| 2 | 0.066023 |
| ... | ... |
| 533 | 1.258873 |
| 534 | 1.585062 |
| 535 | -6.199166 |
536 rows × 1 columns
fig, axs = plt.subplots(nrows=2, ncols=2)
# 情节[1,1]
residual.plot(ax=axs[0,0])
axs[0,0].set_title("Residuals");
# 情节
sns.distplot(residual, ax=axs[0,1]);
axs[0,1].set_title("Density plot - Residual");
# 情节
stats.probplot(residual["residual Model"], dist="norm", plot=axs[1,0])
axs[1,0].set_title('Plot Q-Q')
# 情节
plot_acf(residual, lags=35, ax=axs[1,1],color="fuchsia")
axs[1,1].set_title("Autocorrelation");
plt.show();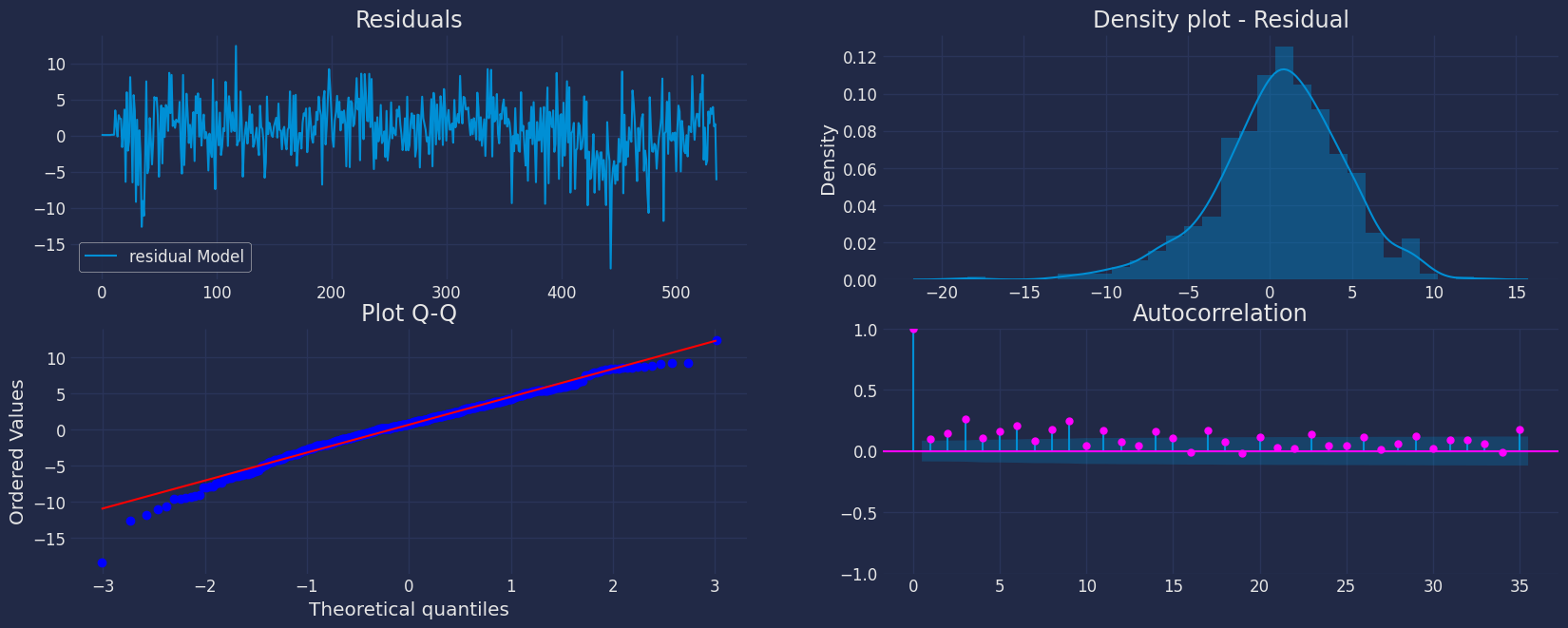
要生成预测,我们只需使用预测方法并指定预测范围(h)。此外,若要计算与预测相关的预测区间,我们可以包含参数 level,该参数接收我们想要构建的预测区间的水平列表。在这种情况下,我们只会计算 90% 的预测区间(level=[90])。
预测方法
如果您想在生产环境中提高速度,并且有多个系列或模型,我们建议使用 StatsForecast.forecast 方法,而不是 .fit 和 .predict。
主要区别在于 .forecast 不会存储拟合值,并且在分布式环境中具有很强的可伸缩性。
预测方法接受两个参数:预测下一个 h(时间跨度)和 level。
h (int):表示向未来预测 h 步。在这种情况下,指的是提前 12 个月。level (list of floats):此可选参数用于概率预测。设置您的预测区间的水平(或置信百分位)。例如,level=[90]意味着模型期望实际值在该区间内的概率为 90%。
这里的预测对象是一个新的数据框,其中包括一个模型名称列和 y hat 值,以及不确定性区间的列。根据您的计算机,这一步大约需要 1 分钟。(如果您希望将时间缩短到几秒钟,请移除像 ARIMA 和 Theta 的自动模型)
Y_hat_df = sf.forecast(horizon, fitted=True)
Y_hat_df.head()| ds | AutoARIMA | |
|---|---|---|
| unique_id | ||
| 1 | 2016-09-01 | 109.955437 |
| 1 | 2016-10-01 | 121.920509 |
| 1 | 2016-11-01 | 122.458389 |
| 1 | 2016-12-01 | 120.562027 |
| 1 | 2017-01-01 | 106.864670 |
values=sf.forecast_fitted_values()
values| ds | y | AutoARIMA | |
|---|---|---|---|
| unique_id | |||
| 1 | 1972-01-01 | 85.694504 | 85.608803 |
| 1 | 1972-02-01 | 71.820000 | 71.748177 |
| 1 | 1972-03-01 | 66.022903 | 65.956879 |
| ... | ... | ... | ... |
| 1 | 2016-06-01 | 102.404404 | 101.145523 |
| 1 | 2016-07-01 | 102.951202 | 101.366135 |
| 1 | 2016-08-01 | 104.697701 | 110.896866 |
536 rows × 3 columns
添加95%的置信区间与预测方法
sf.forecast(h=12, level=[95])| ds | AutoARIMA | AutoARIMA-lo-95 | AutoARIMA-hi-95 | |
|---|---|---|---|---|
| unique_id | ||||
| 1 | 2016-09-01 | 109.955437 | 102.116188 | 117.794685 |
| 1 | 2016-10-01 | 121.920509 | 112.380608 | 131.460403 |
| 1 | 2016-11-01 | 122.458389 | 112.200500 | 132.716278 |
| ... | ... | ... | ... | ... |
| 1 | 2017-06-01 | 96.751160 | 85.873802 | 107.628525 |
| 1 | 2017-07-01 | 97.451607 | 86.572372 | 108.330833 |
| 1 | 2017-08-01 | 103.420616 | 92.540489 | 114.300743 |
12 rows × 4 columns
Y_hat_df=Y_hat_df.reset_index()
Y_hat_df| unique_id | ds | AutoARIMA | |
|---|---|---|---|
| 0 | 1 | 2016-09-01 | 109.955437 |
| 1 | 1 | 2016-10-01 | 121.920509 |
| 2 | 1 | 2016-11-01 | 122.458389 |
| ... | ... | ... | ... |
| 9 | 1 | 2017-06-01 | 96.751160 |
| 10 | 1 | 2017-07-01 | 97.451607 |
| 11 | 1 | 2017-08-01 | 103.420616 |
12 rows × 3 columns
Y_test_df['unique_id'] = Y_test_df['unique_id'].astype(int)
Y_hat_df = Y_test_df.merge(Y_hat_df, how='left', on=['unique_id', 'ds'])
fig, ax = plt.subplots(1, 1, figsize = (18, 7))
plot_df = pd.concat([Y_train_df, Y_hat_df]).set_index('ds')
plot_df[['y', 'AutoARIMA']].plot(ax=ax, linewidth=2)
ax.set_title(' Forecast', fontsize=22)
ax.set_ylabel('Monthly ', fontsize=20)
ax.set_xlabel('Timestamp [t]', fontsize=20)
ax.legend(prop={'size': 15})
ax.grid()
带置信区间的预测方法
要生成预测,请使用预测方法。
预测方法接受两个参数:预测接下来的 h(表示时间跨度)和 level。
h (int):代表预测的步数,这里是12个月。level (float 列表):这个可选参数用于概率预测。设置您的预测区间的水平(或置信百分位)。例如,level=[95]意味着模型预计真实值在该区间内的概率为95%。
这里的预测对象是一个新的数据框,它包括一个包含模型名称的列和y hat值,以及不确定性区间的列。
此步骤应在1秒内完成。
sf.predict(h=12) | ds | AutoARIMA | |
|---|---|---|
| unique_id | ||
| 1 | 2016-09-01 | 109.955437 |
| 1 | 2016-10-01 | 121.920509 |
| 1 | 2016-11-01 | 122.458389 |
| ... | ... | ... |
| 1 | 2017-06-01 | 96.751160 |
| 1 | 2017-07-01 | 97.451607 |
| 1 | 2017-08-01 | 103.420616 |
12 rows × 2 columns
forecast_df = sf.predict(h=12, level = [80, 95])
forecast_df| ds | AutoARIMA | AutoARIMA-lo-95 | AutoARIMA-lo-80 | AutoARIMA-hi-80 | AutoARIMA-hi-95 | |
|---|---|---|---|---|---|---|
| unique_id | ||||||
| 1 | 2016-09-01 | 109.955437 | 102.116188 | 104.829628 | 115.081245 | 117.794685 |
| 1 | 2016-10-01 | 121.920509 | 112.380608 | 115.682701 | 128.158310 | 131.460403 |
| 1 | 2016-11-01 | 122.458389 | 112.200500 | 115.751114 | 129.165665 | 132.716278 |
| ... | ... | ... | ... | ... | ... | ... |
| 1 | 2017-06-01 | 96.751160 | 85.873802 | 89.638840 | 103.863487 | 107.628525 |
| 1 | 2017-07-01 | 97.451607 | 86.572372 | 90.338058 | 104.565147 | 108.330833 |
| 1 | 2017-08-01 | 103.420616 | 92.540489 | 96.306480 | 110.534752 | 114.300743 |
12 rows × 6 columns
我们可以使用 pandas 函数 pd.concat() 将预测结果与历史数据合并,然后可以使用这个结果进行图形绘制。
df_plot=pd.concat([df, forecast_df]).set_index('ds').tail(220)
df_plot| y | unique_id | AutoARIMA | AutoARIMA-lo-95 | AutoARIMA-lo-80 | AutoARIMA-hi-80 | AutoARIMA-hi-95 | |
|---|---|---|---|---|---|---|---|
| ds | |||||||
| 2000-05-01 | 108.7202 | 1 | NaN | NaN | NaN | NaN | NaN |
| 2000-06-01 | 114.2071 | 1 | NaN | NaN | NaN | NaN | NaN |
| 2000-07-01 | 111.8737 | 1 | NaN | NaN | NaN | NaN | NaN |
| ... | ... | ... | ... | ... | ... | ... | ... |
| 2017-06-01 | NaN | NaN | 96.751160 | 85.873802 | 89.638840 | 103.863487 | 107.628525 |
| 2017-07-01 | NaN | NaN | 97.451607 | 86.572372 | 90.338058 | 104.565147 | 108.330833 |
| 2017-08-01 | NaN | NaN | 103.420616 | 92.540489 | 96.306480 | 110.534752 | 114.300743 |
220 rows × 7 columns
现在让我们可视化我们的预测结果和时间序列的历史数据,以及绘制在以95%置信度进行预测时获得的置信区间。
fig, ax = plt.subplots(1, 1, figsize = (20, 8))
plt.plot(df_plot['y'], 'k--', df_plot['AutoARIMA'], 'b-', linewidth=2 ,label="y")
plt.plot(df_plot['AutoARIMA'], 'b-', color="red", linewidth=2, label="AutoArima")
# 指定图形特征:
ax.fill_between(df_plot.index,
df_plot['AutoARIMA-lo-80'],
df_plot['AutoARIMA-hi-80'],
alpha=.20,
color='lime',
label='AutoARIMA_level_80')
ax.fill_between(df_plot.index,
df_plot['AutoARIMA-lo-95'],
df_plot['AutoARIMA-hi-95'],
alpha=.2,
color='white',
label='AutoARIMA_level_95')
ax.set_title('', fontsize=20)
ax.set_ylabel('Production', fontsize=15)
ax.set_xlabel('Month', fontsize=15)
ax.legend(prop={'size': 15})
ax.grid(True)
plt.show()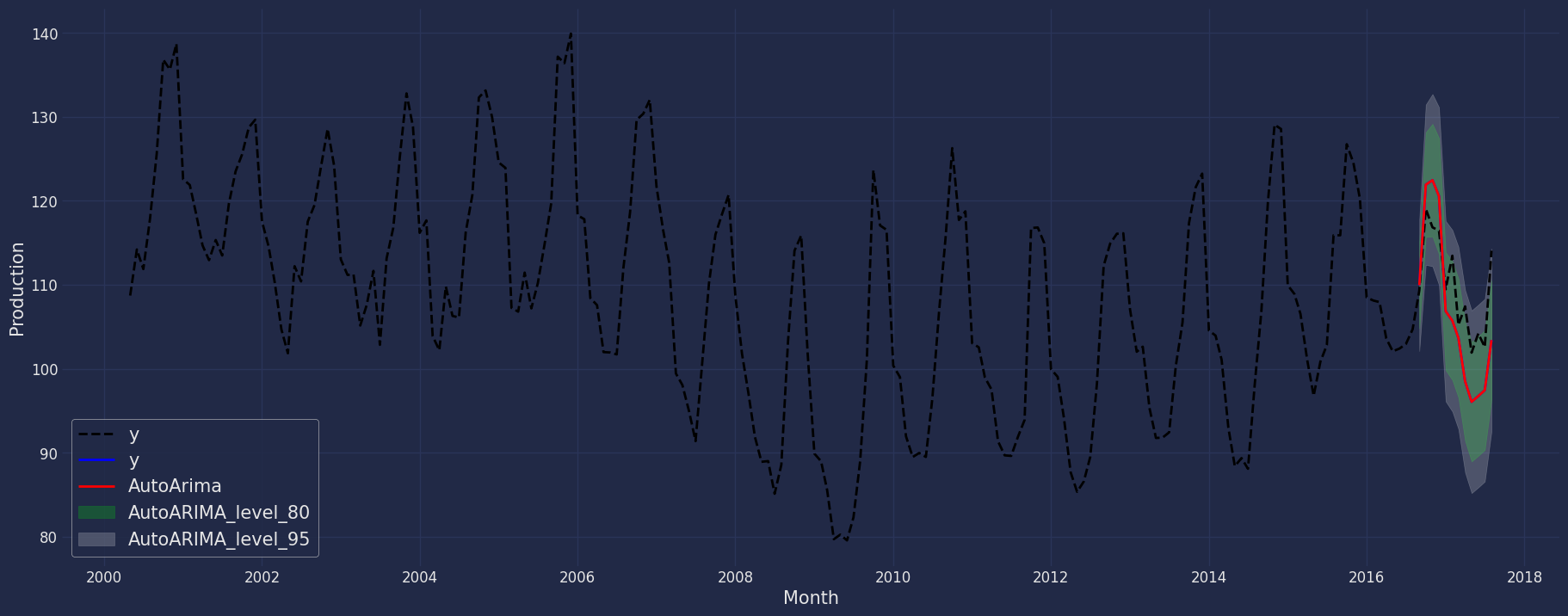
让我们使用Statsforecast中提供的plot函数绘制相同的图,如下所示。
sf.plot(df, forecast_df, level=[95])
交叉验证
在之前的步骤中,我们使用历史数据来预测未来。然而,为了评估其准确性,我们还希望了解模型在过去的表现。为了评估模型在数据上的准确性和稳健性,可以进行交叉验证。
对于时间序列数据,交叉验证是通过在历史数据上定义一个滑动窗口并预测其后面的时间段来进行的。这种交叉验证的形式使我们能够在更广泛的时间实例中更好地估计模型的预测能力,同时保持训练集中的数据连续,这符合我们模型的要求。
下面的图表描述了这种交叉验证策略:

执行时间序列交叉验证
时间序列模型的交叉验证被认为是最佳实践,但大多数实现速度非常慢。statsforecast库将交叉验证实现为一种分布式操作,从而使这个过程变得不那么耗时。如果您有大型数据集,还可以使用Ray、Dask或Spark在分布式集群中进行交叉验证。
在这种情况下,我们希望评估每个模型在过去5个月的表现(n_windows=5),每隔一个月预测一次(step_size=12)。根据您的计算机,这一步应该大约需要1分钟。
StatsForecast类的cross_validation方法接受以下参数。
df:训练数据框h (int):表示正在预测的未来h步。在本例中,表示向前预测12个月。step_size (int):每个窗口之间的步长。换句话说:您希望多长时间运行一次预测过程。n_windows(int):用于交叉验证的窗口数。换句话说:您希望评估过去的多少个预测过程。
crossvalidation_df = sf.cross_validation(df=Y_train_df,
h=12,
step_size=12,
n_windows=5)crossvaldation_df 对象是一个新的数据框,其中包括以下列:
unique_id:索引。如果您不喜欢使用索引,只需运行 crossvalidation_df.resetindex()ds:日期戳或时间索引cutoff:n_windows 的最后一个日期戳或时间索引。y:真实值"model":包含模型名称和拟合值的列。
crossvalidation_df.head()| ds | cutoff | y | AutoARIMA | |
|---|---|---|---|---|
| unique_id | ||||
| 1 | 2011-09-01 | 2011-08-01 | 93.906197 | 104.758850 |
| 1 | 2011-10-01 | 2011-08-01 | 116.763397 | 118.705879 |
| 1 | 2011-11-01 | 2011-08-01 | 116.825798 | 116.834129 |
| 1 | 2011-12-01 | 2011-08-01 | 114.956299 | 117.070084 |
| 1 | 2012-01-01 | 2011-08-01 | 99.966202 | 103.552246 |
模型评估
我们现在可以使用适当的准确性指标来计算预测的准确性。这里我们将使用均方根误差(RMSE)。为此,我们首先需要 install datasetsforecast,这是一个由 Nixtla 开发的 Python 库,其中包含计算 RMSE 的函数。
%%capture
!pip install datasetsforecastfrom datasetsforecast.losses import rmse计算RMSE的函数需要两个参数:
- 实际值。
- 预测值,此处为AutoArima。
rmse = rmse(crossvalidation_df['y'], crossvalidation_df["AutoARIMA"])
print("RMSE using cross-validation: ", rmse)RMSE using cross-validation: 5.5258384正如您所注意到的,我们已经使用交叉验证结果来评估我们的模型。
现在我们将使用预测结果来评估我们的模型,我们将使用不同类型的指标 MAE、MAPE、MASE、RMSE、SMAPE 来评估准确性。
from datasetsforecast.losses import mae, mape, mase, rmse, smapedef evaluate_performace(y_hist, y_true, model):
evaluation = {}
evaluation[model] = {}
for metric in [mase, mae, mape, rmse, smape]:
metric_name = metric.__name__
if metric_name == 'mase':
evaluation[model][metric_name] = metric(y_true['y'].values,
y_true[model].values,
y_hist['y'].values, seasonality=12)
else:
evaluation[model][metric_name] = metric(y_true['y'].values, y_true[model].values)
return pd.DataFrame(evaluation).Tevaluate_performace(Y_train_df, Y_hat_df, model='AutoARIMA')| mae | mape | mase | rmse | smape | |
|---|---|---|---|---|---|
| AutoARIMA | 5.26042 | 4.794312 | 1.015379 | 6.021264 | 4.915602 |
感谢
我们要感谢 Naren Castellon 编写本教程。
参考文献
Give us a ⭐ on Github