0.23.0 版本的新特性(2018年5月15日)#
这是从 0.22.0 版本以来的一个重大发布,包括许多 API 变更、弃用、新功能、增强功能和性能改进,以及大量错误修复。我们建议所有用户升级到此版本。
亮点包括:
警告
自2019年1月1日起,pandas 功能版本将仅支持 Python 3。更多信息请参见 Dropping Python 2.7。
新功能#
使用 orient='table' 进行 JSON 读/写 往返操作#
一个 DataFrame 现在可以通过 JSON 写入并随后读回,同时通过使用 orient='table' 参数保留元数据(见 GH 18912 和 GH 9146)。以前,所有可用的 orient 值都不能保证保留 dtypes 和索引名称等元数据。
In [1]: df = pd.DataFrame({'foo': [1, 2, 3, 4],
...: 'bar': ['a', 'b', 'c', 'd'],
...: 'baz': pd.date_range('2018-01-01', freq='d', periods=4),
...: 'qux': pd.Categorical(['a', 'b', 'c', 'c'])},
...: index=pd.Index(range(4), name='idx'))
In [2]: df
Out[2]:
foo bar baz qux
idx
0 1 a 2018-01-01 a
1 2 b 2018-01-02 b
2 3 c 2018-01-03 c
3 4 d 2018-01-04 c
[4 rows x 4 columns]
In [3]: df.dtypes
Out[3]:
foo int64
bar object
baz datetime64[ns]
qux category
Length: 4, dtype: object
In [4]: df.to_json('test.json', orient='table')
In [5]: new_df = pd.read_json('test.json', orient='table')
In [6]: new_df
Out[6]:
foo bar baz qux
idx
0 1 a 2018-01-01 a
1 2 b 2018-01-02 b
2 3 c 2018-01-03 c
3 4 d 2018-01-04 c
[4 rows x 4 columns]
In [7]: new_df.dtypes
Out[7]:
foo int64
bar object
baz datetime64[ns]
qux category
Length: 4, dtype: object
请注意,字符串 index 在往返格式中不被支持,因为它在 write_json 中默认用于指示缺失的索引名称。
In [1]: df.index.name = 'index'
In [2]: df.to_json('test.json', orient='table')
In [3]: new_df = pd.read_json('test.json', orient='table')
In [4]: new_df
Out[4]:
A
foo 1
bar 2
baz 3
[3 rows x 1 columns]
In [5]: new_df.dtypes
Out[5]:
A int64
Length: 1, dtype: object
方法 .assign() 接受依赖参数#
DataFrame.assign() 现在接受依赖的关键字参数,适用于 Python 版本 3.6 及以上(另见 PEP 468)。后面的关键字参数现在可以引用前面的参数,如果该参数是可调用的。请参阅 这里的文档 (GH 14207)
In [6]: df = pd.DataFrame({'A': [1, 2, 3]})
In [7]: df
Out[7]:
A
0 1
1 2
2 3
[3 rows x 1 columns]
In [8]: df.assign(B=df.A, C=lambda x: x['A'] + x['B'])
Out[8]:
A B C
0 1 1 2
1 2 2 4
2 3 3 6
[3 rows x 3 columns]
警告
当你使用 .assign() 更新现有列时,这可能会微妙地改变你的代码的行为。以前,引用其他正在更新的变量的可调用对象会得到“旧”的值
之前的行为:
In [2]: df = pd.DataFrame({"A": [1, 2, 3]})
In [3]: df.assign(A=lambda df: df.A + 1, C=lambda df: df.A * -1)
Out[3]:
A C
0 2 -1
1 3 -2
2 4 -3
新行为:
In [9]: df.assign(A=df.A + 1, C=lambda df: df.A * -1)
Out[9]:
A C
0 2 -2
1 3 -3
2 4 -4
[3 rows x 2 columns]
在列和索引级别的组合上进行合并#
传递给 DataFrame.merge() 的 on、left_on 和 right_on 参数现在可以引用列名或索引级别名。这使得可以在不重置索引的情况下,将 DataFrame 实例按索引级别和列的组合进行合并。请参阅 按列和级别合并 文档部分。(GH 14355)
In [10]: left_index = pd.Index(['K0', 'K0', 'K1', 'K2'], name='key1')
In [11]: left = pd.DataFrame({'A': ['A0', 'A1', 'A2', 'A3'],
....: 'B': ['B0', 'B1', 'B2', 'B3'],
....: 'key2': ['K0', 'K1', 'K0', 'K1']},
....: index=left_index)
....:
In [12]: right_index = pd.Index(['K0', 'K1', 'K2', 'K2'], name='key1')
In [13]: right = pd.DataFrame({'C': ['C0', 'C1', 'C2', 'C3'],
....: 'D': ['D0', 'D1', 'D2', 'D3'],
....: 'key2': ['K0', 'K0', 'K0', 'K1']},
....: index=right_index)
....:
In [14]: left.merge(right, on=['key1', 'key2'])
Out[14]:
A B key2 C D
key1
K0 A0 B0 K0 C0 D0
K1 A2 B2 K0 C1 D1
K2 A3 B3 K1 C3 D3
[3 rows x 5 columns]
按列和索引级别的组合排序#
传递给 DataFrame.sort_values() 作为 by 参数的字符串现在可以引用列名或索引级别名。这使得可以通过索引级别和列的组合对 DataFrame 实例进行排序,而无需重置索引。请参阅 按索引和值排序 文档部分。(GH 14353)
# Build MultiIndex
In [15]: idx = pd.MultiIndex.from_tuples([('a', 1), ('a', 2), ('a', 2),
....: ('b', 2), ('b', 1), ('b', 1)])
....:
In [16]: idx.names = ['first', 'second']
# Build DataFrame
In [17]: df_multi = pd.DataFrame({'A': np.arange(6, 0, -1)},
....: index=idx)
....:
In [18]: df_multi
Out[18]:
A
first second
a 1 6
2 5
2 4
b 2 3
1 2
1 1
[6 rows x 1 columns]
# Sort by 'second' (index) and 'A' (column)
In [19]: df_multi.sort_values(by=['second', 'A'])
Out[19]:
A
first second
b 1 1
1 2
a 1 6
b 2 3
a 2 4
2 5
[6 rows x 1 columns]
使用自定义类型扩展 pandas(实验性)#
pandas 现在支持存储不一定是 1-D NumPy 数组的类数组对象作为 DataFrame 中的列或 Series 中的值。这允许第三方库实现对 NumPy 类型的扩展,类似于 pandas 实现分类、带时区的日期时间、周期和区间的方式。
作为一个演示,我们将使用 cyberpandas,它提供了一个 IPArray 类型用于存储 IP 地址。
In [1]: from cyberpandas import IPArray
In [2]: values = IPArray([
...: 0,
...: 3232235777,
...: 42540766452641154071740215577757643572
...: ])
...:
...:
IPArray 不是一个普通的 1-D NumPy 数组,但由于它是 pandas ExtensionArray,它可以被正确地存储在 pandas 的容器中。
In [3]: ser = pd.Series(values)
In [4]: ser
Out[4]:
0 0.0.0.0
1 192.168.1.1
2 2001:db8:85a3::8a2e:370:7334
dtype: ip
注意 dtype 是 ip。底层数组的缺失值语义被尊重:
In [5]: ser.isna()
Out[5]:
0 True
1 False
2 False
dtype: bool
新的 observed 关键字用于在 GroupBy 中排除未观察到的类别#
按分类分组时,输出中包含未观察到的类别。当按多个分类列分组时,这意味着你会得到所有类别的外积,包括没有观察到的组合,这可能导致大量分组。我们添加了一个关键字 observed 来控制此行为,默认情况下为 observed=False 以保持向后兼容性。(GH 14942, GH 8138, GH 15217, GH 17594, GH 8669, GH 20583, GH 20902)
In [20]: cat1 = pd.Categorical(["a", "a", "b", "b"],
....: categories=["a", "b", "z"], ordered=True)
....:
In [21]: cat2 = pd.Categorical(["c", "d", "c", "d"],
....: categories=["c", "d", "y"], ordered=True)
....:
In [22]: df = pd.DataFrame({"A": cat1, "B": cat2, "values": [1, 2, 3, 4]})
In [23]: df['C'] = ['foo', 'bar'] * 2
In [24]: df
Out[24]:
A B values C
0 a c 1 foo
1 a d 2 bar
2 b c 3 foo
3 b d 4 bar
[4 rows x 4 columns]
要显示所有值,以前的行为:
In [25]: df.groupby(['A', 'B', 'C'], observed=False).count()
Out[25]:
values
A B C
a c bar 0
foo 1
d bar 1
foo 0
y bar 0
... ...
z c foo 0
d bar 0
foo 0
y bar 0
foo 0
[18 rows x 1 columns]
仅显示观察到的值:
In [26]: df.groupby(['A', 'B', 'C'], observed=True).count()
Out[26]:
values
A B C
a c foo 1
d bar 1
b c foo 1
d bar 1
[4 rows x 1 columns]
对于旋转操作,此行为已经由 dropna 关键字控制:
In [27]: cat1 = pd.Categorical(["a", "a", "b", "b"],
....: categories=["a", "b", "z"], ordered=True)
....:
In [28]: cat2 = pd.Categorical(["c", "d", "c", "d"],
....: categories=["c", "d", "y"], ordered=True)
....:
In [29]: df = pd.DataFrame({"A": cat1, "B": cat2, "values": [1, 2, 3, 4]})
In [30]: df
Out[30]:
A B values
0 a c 1
1 a d 2
2 b c 3
3 b d 4
[4 rows x 3 columns]
In [1]: pd.pivot_table(df, values='values', index=['A', 'B'], dropna=True)
Out[1]:
values
A B
a c 1.0
d 2.0
b c 3.0
d 4.0
In [2]: pd.pivot_table(df, values='values', index=['A', 'B'], dropna=False)
Out[2]:
values
A B
a c 1.0
d 2.0
y NaN
b c 3.0
d 4.0
y NaN
z c NaN
d NaN
y NaN
Rolling/Expanding.apply() 接受 raw=False 以将 Series 传递给函数#
Series.rolling().apply()、DataFrame.rolling().apply()、Series.expanding().apply() 和 DataFrame.expanding().apply() 增加了一个 raw=None 参数。这与 DataFame.apply() 类似。如果该参数为 True,允许将 np.ndarray 发送到应用的函数中。如果为 False,则将传递 Series。默认值为 None,保留向后兼容性,因此默认情况下将发送 np.ndarray。在未来的版本中,默认值将更改为 False,发送 Series。(GH 5071, GH 20584)
In [31]: s = pd.Series(np.arange(5), np.arange(5) + 1)
In [32]: s
Out[32]:
1 0
2 1
3 2
4 3
5 4
Length: 5, dtype: int64
传递一个 Series:
In [33]: s.rolling(2, min_periods=1).apply(lambda x: x.iloc[-1], raw=False)
Out[33]:
1 0.0
2 1.0
3 2.0
4 3.0
5 4.0
Length: 5, dtype: float64
模拟传递一个 ndarray 的原始行为:
In [34]: s.rolling(2, min_periods=1).apply(lambda x: x[-1], raw=True)
Out[34]:
1 0.0
2 1.0
3 2.0
4 3.0
5 4.0
Length: 5, dtype: float64
DataFrame.interpolate 已经获得了 limit_area 关键字参数#
DataFrame.interpolate() 增加了一个 limit_area 参数,以允许进一步控制哪些 NaN 被替换。使用 limit_area='inside' 仅填充被有效值包围的 NaN,或使用 limit_area='outside' 仅填充现有有效值之外的 NaN,同时保留内部的 NaN。(GH 16284)请参阅 完整文档在这里。
In [35]: ser = pd.Series([np.nan, np.nan, 5, np.nan, np.nan,
....: np.nan, 13, np.nan, np.nan])
....:
In [36]: ser
Out[36]:
0 NaN
1 NaN
2 5.0
3 NaN
4 NaN
5 NaN
6 13.0
7 NaN
8 NaN
Length: 9, dtype: float64
在两个方向上填充一个连续的内部值
In [37]: ser.interpolate(limit_direction='both', limit_area='inside', limit=1)
Out[37]:
0 NaN
1 NaN
2 5.0
3 7.0
4 NaN
5 11.0
6 13.0
7 NaN
8 NaN
Length: 9, dtype: float64
向后填充所有连续的外部值
In [38]: ser.interpolate(limit_direction='backward', limit_area='outside')
Out[38]:
0 5.0
1 5.0
2 5.0
3 NaN
4 NaN
5 NaN
6 13.0
7 NaN
8 NaN
Length: 9, dtype: float64
在两个方向上填充所有连续的外部值
In [39]: ser.interpolate(limit_direction='both', limit_area='outside')
Out[39]:
0 5.0
1 5.0
2 5.0
3 NaN
4 NaN
5 NaN
6 13.0
7 13.0
8 13.0
Length: 9, dtype: float64
函数 get_dummies 现在支持 dtype 参数#
get_dummies() 现在接受一个 dtype 参数,该参数指定新列的数据类型。默认值仍然是 uint8。(GH 18330)
In [40]: df = pd.DataFrame({'a': [1, 2], 'b': [3, 4], 'c': [5, 6]})
In [41]: pd.get_dummies(df, columns=['c']).dtypes
Out[41]:
a int64
b int64
c_5 bool
c_6 bool
Length: 4, dtype: object
In [42]: pd.get_dummies(df, columns=['c'], dtype=bool).dtypes
Out[42]:
a int64
b int64
c_5 bool
c_6 bool
Length: 4, dtype: object
Timedelta 模方法#
mod (%) 和 divmod 操作现在在 Timedelta 对象上定义,当操作带有时间增量类似的或数字参数时。请参阅 这里的文档。(GH 19365)
In [43]: td = pd.Timedelta(hours=37)
In [44]: td % pd.Timedelta(minutes=45)
Out[44]: Timedelta('0 days 00:15:00')
方法 .rank() 在存在 NaN 时处理 inf 值#
在之前的版本中,.rank() 会将 inf 元素的排名分配为 NaN。现在排名计算正确。(GH 6945)
In [45]: s = pd.Series([-np.inf, 0, 1, np.nan, np.inf])
In [46]: s
Out[46]:
0 -inf
1 0.0
2 1.0
3 NaN
4 inf
Length: 5, dtype: float64
之前的行为:
In [11]: s.rank()
Out[11]:
0 1.0
1 2.0
2 3.0
3 NaN
4 NaN
dtype: float64
当前行为:
In [47]: s.rank()
Out[47]:
0 1.0
1 2.0
2 3.0
3 NaN
4 4.0
Length: 5, dtype: float64
此外,之前如果你将 inf 或 -inf 值与 NaN 值一起排序,在使用 ‘top’ 或 ‘bottom’ 参数时,计算不会区分 NaN 和无穷大。
In [48]: s = pd.Series([np.nan, np.nan, -np.inf, -np.inf])
In [49]: s
Out[49]:
0 NaN
1 NaN
2 -inf
3 -inf
Length: 4, dtype: float64
之前的行为:
In [15]: s.rank(na_option='top')
Out[15]:
0 2.5
1 2.5
2 2.5
3 2.5
dtype: float64
当前行为:
In [50]: s.rank(na_option='top')
Out[50]:
0 1.5
1 1.5
2 3.5
3 3.5
Length: 4, dtype: float64
这些错误已被修复:
在
method='dense'和pct=True时,DataFrame.rank()和Series.rank()中的错误,其中百分位排名没有与不同观测值的数量一起使用 (GH 15630)当
ascending='False'时,Series.rank()和DataFrame.rank()中的错误未能为无穷大返回正确的排名,如果存在NaN(GH 19538)在
DataFrameGroupBy.rank()中的错误,当同时存在无穷大和NaN时,排名不正确 (GH 20561)
Series.str.cat 增加了 join 关键字参数#
之前,Series.str.cat() 不像大多数 pandas 那样,在连接之前不会对齐 Series 的索引(见 GH 18657)。该方法现在增加了一个关键字 join 来控制对齐方式,请参见下面的示例和 这里。
在 v.0.23 中,join 将默认为 None(意味着不进行对齐),但在未来版本的 pandas 中,此默认值将更改为 'left'。
In [51]: s = pd.Series(['a', 'b', 'c', 'd'])
In [52]: t = pd.Series(['b', 'd', 'e', 'c'], index=[1, 3, 4, 2])
In [53]: s.str.cat(t)
Out[53]:
0 NaN
1 bb
2 cc
3 dd
Length: 4, dtype: object
In [54]: s.str.cat(t, join='left', na_rep='-')
Out[54]:
0 a-
1 bb
2 cc
3 dd
Length: 4, dtype: object
此外,Series.str.cat() 现在也适用于 CategoricalIndex``(之前会引发 ``ValueError;见 GH 20842)。
DataFrame.astype 执行按列转换为 Categorical#
DataFrame.astype() 现在可以通过提供字符串 'category' 或 CategoricalDtype 来执行按列转换为 Categorical。以前,尝试这样做会引发 NotImplementedError。有关更多详细信息和示例,请参阅文档的 对象创建 部分。(GH 12860, GH 18099)
提供字符串 'category' 执行列方向的转换,只有出现在给定列中的标签被设置为类别:
In [55]: df = pd.DataFrame({'A': list('abca'), 'B': list('bccd')})
In [56]: df = df.astype('category')
In [57]: df['A'].dtype
Out[57]: CategoricalDtype(categories=['a', 'b', 'c'], ordered=False, categories_dtype=object)
In [58]: df['B'].dtype
Out[58]: CategoricalDtype(categories=['b', 'c', 'd'], ordered=False, categories_dtype=object)
提供一个 CategoricalDtype 将使每列中的类别与提供的 dtype 一致:
In [59]: from pandas.api.types import CategoricalDtype
In [60]: df = pd.DataFrame({'A': list('abca'), 'B': list('bccd')})
In [61]: cdt = CategoricalDtype(categories=list('abcd'), ordered=True)
In [62]: df = df.astype(cdt)
In [63]: df['A'].dtype
Out[63]: CategoricalDtype(categories=['a', 'b', 'c', 'd'], ordered=True, categories_dtype=object)
In [64]: df['B'].dtype
Out[64]: CategoricalDtype(categories=['a', 'b', 'c', 'd'], ordered=True, categories_dtype=object)
其他增强功能#
一元
+现在允许用于Series和DataFrame作为数值运算符 (GH 16073)更好地支持使用
xlsxwriter引擎的to_excel()输出。(GH 16149)pandas.tseries.frequencies.to_offset()现在接受前导的 ‘+’ 符号,例如 ‘+1h’。(GH 18171)MultiIndex.unique()现在支持level=参数,以从特定索引级别获取唯一值 (GH 17896)pandas.io.formats.style.Styler现在有方法hide_index()来决定索引是否会在输出中呈现 (GH 14194)pandas.io.formats.style.Styler现在有方法hide_columns()来决定是否在输出中隐藏列 (GH 14194)改进了在传递
unit=时,to_datetime()中引发的ValueError的措辞,当unit=传递了一个不可转换的值时 (GH 14350)Series.fillna()现在接受一个 Series 或一个字典作为分类数据类型的value(GH 17033)pandas.read_clipboard()更新为使用 qtpy,回退到 PyQt5,然后是 PyQt4,增加了对 Python3 和多个 python-qt 绑定的兼容性 (GH 17722)改进了当
usecols参数无法匹配所有列时在read_csv()中引发的ValueError的措辞。(GH 17301)DataFrame.corrwith()现在在传递一个 Series 时会静默删除非数字列。之前,会引发异常 (GH 18570)。IntervalIndex现在支持时区感知的Interval对象 (GH 18537, GH 18538)Series()/DataFrame()的标签补全也会返回MultiIndex()第一层级的标识符。(GH 16326)read_excel()获得了nrows参数 (GH 16645)DataFrame.append()现在在更多情况下可以保留调用数据框列的类型(例如,如果两者都是CategoricalIndex)(GH 18359)DataFrame.to_json()和Series.to_json()现在接受一个index参数,允许用户从 JSON 输出中排除索引 (GH 17394)IntervalIndex.to_tuples()增加了na_tuple参数,用于控制 NA 是作为 NA 的元组返回,还是 NA 本身 (GH 18756)Categorical.rename_categories,CategoricalIndex.rename_categories和Series.cat.rename_categories现在可以接受一个可调用对象作为它们的参数 (GH 18862)Interval和IntervalIndex获得了一个length属性 (GH 18789)Resampler对象现在有一个功能性的Resampler.pipe方法。以前,对pipe的调用被重定向到mean方法 (GH 17905)。is_scalar()现在对DateOffset对象返回True(GH 18943)。DataFrame.pivot()现在接受values=参数的列表 (GH 17160)。添加了
pandas.api.extensions.register_dataframe_accessor()、pandas.api.extensions.register_series_accessor()和pandas.api.extensions.register_index_accessor(),允许 pandas 下游库在 pandas 对象上注册自定义访问器,如.cat。更多信息请参见 注册自定义访问器 (GH 14781)。IntervalIndex.astype现在支持在传递IntervalDtype时在子类型之间进行转换 (GH 19197)IntervalIndex及其相关的构造方法(from_arrays、from_breaks、from_tuples)增加了一个dtype参数 (GH 19262)添加了
SeriesGroupBy.is_monotonic_increasing()和SeriesGroupBy.is_monotonic_decreasing()(GH 17015)对于子类化的
DataFrames,DataFrame.apply()现在将在将数据传递给应用的函数时保留Series子类(如果已定义)(GH 19822)DataFrame.from_dict()现在接受一个columns参数,当使用orient='index'时可以用来指定列名 (GH 18529)添加了选项
display.html.use_mathjax,以便在Jupyter笔记本中渲染表格时可以禁用 MathJax (GH 19856, GH 19824)DataFrame.replace()现在支持method参数,当to_replace是标量、列表或元组且value是None时,可以使用该参数指定替换方法 (GH 19632)Timestamp.month_name(),DatetimeIndex.month_name(), 和Series.dt.month_name()现在可用 (GH 12805)Timestamp.day_name()和DatetimeIndex.day_name()现在可用,以返回指定区域设置的日期名称 (GH 12806)DataFrame.to_sql()现在如果底层连接支持,会执行多值插入而不是逐行插入。支持多值插入的SQLAlchemy方言包括:mysql、postgresql、sqlite以及任何带有supports_multivalues_insert的方言。(GH 14315, GH 8953)read_html()现在接受一个displayed_only关键字参数来控制是否解析隐藏元素(默认为True) (GH 20027)read_html()现在读取<table>中的所有<tbody>元素,而不仅仅是第一个。(GH 20690)Rolling.quantile()和Expanding.quantile()现在接受interpolation关键字,默认为linear(GH 20497)通过在
DataFrame.to_pickle()、Series.to_pickle()、DataFrame.to_csv()、Series.to_csv()、DataFrame.to_json()、Series.to_json()中使用compression=zip支持 zip 压缩。(GH 17778)WeekOfMonth构造函数现在支持n=0(GH 20517)。DataFrame和Series现在支持矩阵乘法 (@) 运算符 (GH 10259) 适用于 Python>=3.5更新了
DataFrame.to_gbq()和pandas.read_gbq()的签名和文档,以反映来自 pandas-gbq 库版本 0.4.0 的更改。添加了对 pandas-gbq 库的 intersphinx 映射。(GH 20564)在版本117中添加了用于导出Stata dta文件的新写入器
StataWriter117。此格式支持导出长度高达2,000,000个字符的字符串 (GH 16450)to_hdf()和read_hdf()现在接受一个errors关键字参数来控制编码错误处理 (GH 20835)cut()增加了duplicates='raise'|'drop'选项来控制是否在重复边缘时引发 (GH 20947)date_range(),timedelta_range(), 和interval_range()现在如果指定了start,stop, 和periods,但未指定freq,则返回一个线性间隔的索引。(GH 20808, GH 20983, GH 20976)
向后不兼容的 API 变化#
依赖项已增加最低版本#
我们已经更新了依赖项的最低支持版本 (GH 15184)。如果已安装,我们现在要求:
包 |
最低版本 |
必需的 |
问题 |
|---|---|---|---|
python-dateutil |
2.5.0 |
X |
|
openpyxl |
2.4.0 |
||
beautifulsoup4 |
4.2.1 |
||
setuptools |
24.2.0 |
从字典实例化保留了 Python 3.6+ 的字典插入顺序#
直到 Python 3.6,Python 中的字典没有正式定义的顺序。对于 Python 3.6 及更高版本,字典按插入顺序排序,请参见 PEP 468。当使用 Python 3.6 或更高版本从字典创建 Series 或 DataFrame 时,pandas 将使用字典的插入顺序。(GH 19884)
之前的行为(如果在 Python < 3.6 上,则是当前行为):
In [16]: pd.Series({'Income': 2000,
....: 'Expenses': -1500,
....: 'Taxes': -200,
....: 'Net result': 300})
Out[16]:
Expenses -1500
Income 2000
Net result 300
Taxes -200
dtype: int64
注意上面的系列是按索引值的字母顺序排列的。
新行为(适用于 Python >= 3.6):
In [65]: pd.Series({'Income': 2000,
....: 'Expenses': -1500,
....: 'Taxes': -200,
....: 'Net result': 300})
....:
Out[65]:
Income 2000
Expenses -1500
Taxes -200
Net result 300
Length: 4, dtype: int64
请注意,现在 Series 是按插入顺序排序的。这种新行为用于所有相关的 pandas 类型(Series、DataFrame、SparseSeries 和 SparseDataFrame)。
如果你希望在使用 Python >= 3.6 时保留旧的行为,可以使用 .sort_index():
In [66]: pd.Series({'Income': 2000,
....: 'Expenses': -1500,
....: 'Taxes': -200,
....: 'Net result': 300}).sort_index()
....:
Out[66]:
Expenses -1500
Income 2000
Net result 300
Taxes -200
Length: 4, dtype: int64
弃用 Panel#
Panel 在 0.20.x 版本中已被弃用,显示为 DeprecationWarning。现在使用 Panel 将显示 FutureWarning。推荐使用 MultiIndex 在 DataFrame 上表示 3-D 数据,通过 to_frame() 方法或使用 xarray 包。pandas 提供了一个 to_xarray() 方法来自动完成这种转换(GH 13563, GH 18324)。
In [75]: import pandas._testing as tm
In [76]: p = tm.makePanel()
In [77]: p
Out[77]:
<class 'pandas.core.panel.Panel'>
Dimensions: 3 (items) x 3 (major_axis) x 4 (minor_axis)
Items axis: ItemA to ItemC
Major_axis axis: 2000-01-03 00:00:00 to 2000-01-05 00:00:00
Minor_axis axis: A to D
转换为 MultiIndex DataFrame
In [78]: p.to_frame()
Out[78]:
ItemA ItemB ItemC
major minor
2000-01-03 A 0.469112 0.721555 0.404705
B -1.135632 0.271860 -1.039268
C 0.119209 0.276232 -1.344312
D -2.104569 0.113648 -0.109050
2000-01-04 A -0.282863 -0.706771 0.577046
B 1.212112 -0.424972 -0.370647
C -1.044236 -1.087401 0.844885
D -0.494929 -1.478427 1.643563
2000-01-05 A -1.509059 -1.039575 -1.715002
B -0.173215 0.567020 -1.157892
C -0.861849 -0.673690 1.075770
D 1.071804 0.524988 -1.469388
[12 rows x 3 columns]
转换为 xarray DataArray
In [79]: p.to_xarray()
Out[79]:
<xarray.DataArray (items: 3, major_axis: 3, minor_axis: 4)>
array([[[ 0.469112, -1.135632, 0.119209, -2.104569],
[-0.282863, 1.212112, -1.044236, -0.494929],
[-1.509059, -0.173215, -0.861849, 1.071804]],
[[ 0.721555, 0.27186 , 0.276232, 0.113648],
[-0.706771, -0.424972, -1.087401, -1.478427],
[-1.039575, 0.56702 , -0.67369 , 0.524988]],
[[ 0.404705, -1.039268, -1.344312, -0.10905 ],
[ 0.577046, -0.370647, 0.844885, 1.643563],
[-1.715002, -1.157892, 1.07577 , -1.469388]]])
Coordinates:
* items (items) object 'ItemA' 'ItemB' 'ItemC'
* major_axis (major_axis) datetime64[ns] 2000-01-03 2000-01-04 2000-01-05
* minor_axis (minor_axis) object 'A' 'B' 'C' 'D'
pandas.core.common 移除#
以下错误和警告信息已从 pandas.core.common 中移除(GH 13634, GH 19769):
PerformanceWarningUnsupportedFunctionCallUnsortedIndexErrorAbstractMethodError
这些可以从 pandas.errors 导入(自 0.19.0 起)。
对 DataFrame.apply 输出的一致性进行更改#
DataFrame.apply() 在应用返回类似列表的用户定义函数时与 axis=1 不一致。解决了几个错误和不一致的问题。如果应用的函数返回一个 Series,那么 pandas 将返回一个 DataFrame;否则将返回一个 Series,这包括返回类似列表的情况(例如 tuple 或 list)(GH 16353, GH 17437, GH 17970, GH 17348, GH 17892, GH 18573, GH 17602, GH 18775, GH 18901, GH 18919)。
In [67]: df = pd.DataFrame(np.tile(np.arange(3), 6).reshape(6, -1) + 1,
....: columns=['A', 'B', 'C'])
....:
In [68]: df
Out[68]:
A B C
0 1 2 3
1 1 2 3
2 1 2 3
3 1 2 3
4 1 2 3
5 1 2 3
[6 rows x 3 columns]
之前的行为:如果返回的形状恰好与原始列的长度匹配,这将返回一个 DataFrame。如果返回的形状不匹配,则返回一个包含列表的 Series。
In [3]: df.apply(lambda x: [1, 2, 3], axis=1)
Out[3]:
A B C
0 1 2 3
1 1 2 3
2 1 2 3
3 1 2 3
4 1 2 3
5 1 2 3
In [4]: df.apply(lambda x: [1, 2], axis=1)
Out[4]:
0 [1, 2]
1 [1, 2]
2 [1, 2]
3 [1, 2]
4 [1, 2]
5 [1, 2]
dtype: object
新行为:当应用的函数返回类似列表的结果时,现在将 总是 返回一个 Series。
In [69]: df.apply(lambda x: [1, 2, 3], axis=1)
Out[69]:
0 [1, 2, 3]
1 [1, 2, 3]
2 [1, 2, 3]
3 [1, 2, 3]
4 [1, 2, 3]
5 [1, 2, 3]
Length: 6, dtype: object
In [70]: df.apply(lambda x: [1, 2], axis=1)
Out[70]:
0 [1, 2]
1 [1, 2]
2 [1, 2]
3 [1, 2]
4 [1, 2]
5 [1, 2]
Length: 6, dtype: object
要展开列,可以使用 result_type='expand'
In [71]: df.apply(lambda x: [1, 2, 3], axis=1, result_type='expand')
Out[71]:
0 1 2
0 1 2 3
1 1 2 3
2 1 2 3
3 1 2 3
4 1 2 3
5 1 2 3
[6 rows x 3 columns]
要在原始列之间广播结果(对于长度正确的列表类型的旧行为),可以使用 result_type='broadcast'。形状必须与原始列匹配。
In [72]: df.apply(lambda x: [1, 2, 3], axis=1, result_type='broadcast')
Out[72]:
A B C
0 1 2 3
1 1 2 3
2 1 2 3
3 1 2 3
4 1 2 3
5 1 2 3
[6 rows x 3 columns]
返回一个 Series 允许控制确切的返回结构和列名:
In [73]: df.apply(lambda x: pd.Series([1, 2, 3], index=['D', 'E', 'F']), axis=1)
Out[73]:
D E F
0 1 2 3
1 1 2 3
2 1 2 3
3 1 2 3
4 1 2 3
5 1 2 3
[6 rows x 3 columns]
连接将不再排序#
在未来的 pandas 版本中,pandas.concat() 将不再对未对齐的非连接轴进行排序。当前的行为与之前(排序)相同,但当 sort 未指定且非连接轴未对齐时,现在会发出警告 (GH 4588)。
In [74]: df1 = pd.DataFrame({"a": [1, 2], "b": [1, 2]}, columns=['b', 'a'])
In [75]: df2 = pd.DataFrame({"a": [4, 5]})
In [76]: pd.concat([df1, df2])
Out[76]:
b a
0 1.0 1
1 2.0 2
0 NaN 4
1 NaN 5
[4 rows x 2 columns]
要保持之前的行为(排序)并静默警告,请传递 sort=True
In [77]: pd.concat([df1, df2], sort=True)
Out[77]:
a b
0 1 1.0
1 2 2.0
0 4 NaN
1 5 NaN
[4 rows x 2 columns]
要接受未来的行为(不排序),请传递 sort=False
请注意,这一更改也适用于 DataFrame.append() ,它也接收了一个 sort 关键字来控制此行为。
构建变化#
索引除以零正确填充#
对 Index 及其子类的除法操作现在会将正数除以零填充为 np.inf,负数除以零填充为 -np.inf,以及 0 / 0 填充为 np.nan。这与现有的 Series 行为相匹配。(GH 19322, GH 19347)
之前的行为:
In [6]: index = pd.Int64Index([-1, 0, 1])
In [7]: index / 0
Out[7]: Int64Index([0, 0, 0], dtype='int64')
# Previous behavior yielded different results depending on the type of zero in the divisor
In [8]: index / 0.0
Out[8]: Float64Index([-inf, nan, inf], dtype='float64')
In [9]: index = pd.UInt64Index([0, 1])
In [10]: index / np.array([0, 0], dtype=np.uint64)
Out[10]: UInt64Index([0, 0], dtype='uint64')
In [11]: pd.RangeIndex(1, 5) / 0
ZeroDivisionError: integer division or modulo by zero
当前行为:
In [12]: index = pd.Int64Index([-1, 0, 1])
# division by zero gives -infinity where negative,
# +infinity where positive, and NaN for 0 / 0
In [13]: index / 0
# The result of division by zero should not depend on
# whether the zero is int or float
In [14]: index / 0.0
In [15]: index = pd.UInt64Index([0, 1])
In [16]: index / np.array([0, 0], dtype=np.uint64)
In [17]: pd.RangeIndex(1, 5) / 0
从字符串中提取匹配的模式#
默认情况下,使用 str.extract() 从字符串中提取匹配模式时,如果提取单个组,则返回 Series``(如果提取多个组,则返回 ``DataFrame)。从 pandas 0.23.0 开始,str.extract() 总是返回 DataFrame,除非 expand 设置为 False。最后,None 是 expand 参数的可接受值(等同于 False),但现在会引发 ValueError。(GH 11386)
之前的行为:
In [1]: s = pd.Series(['number 10', '12 eggs'])
In [2]: extracted = s.str.extract(r'.*(\d\d).*')
In [3]: extracted
Out [3]:
0 10
1 12
dtype: object
In [4]: type(extracted)
Out [4]:
pandas.core.series.Series
新行为:
In [78]: s = pd.Series(['number 10', '12 eggs'])
In [79]: extracted = s.str.extract(r'.*(\d\d).*')
In [80]: extracted
Out[80]:
0
0 10
1 12
[2 rows x 1 columns]
In [81]: type(extracted)
Out[81]: pandas.DataFrame
要恢复之前的行为,只需将 expand 设置为 False:
In [82]: s = pd.Series(['number 10', '12 eggs'])
In [83]: extracted = s.str.extract(r'.*(\d\d).*', expand=False)
In [84]: extracted
Out[84]:
0 10
1 12
Length: 2, dtype: object
In [85]: type(extracted)
Out[85]: pandas.core.series.Series
CategoricalDtype 的 ordered 参数的默认值#
对于 CategoricalDtype 的 ordered 参数的默认值已从 False 更改为 None,以允许在不影响 ordered 的情况下更新 categories。对于下游对象(如 Categorical)的行为应保持一致(GH 18790)
在之前的版本中,ordered 参数的默认值是 False。这可能会导致用户在尝试更新 categories 时,如果未明确指定 ordered,ordered 参数会无意中从 True 变为 False,因为它会静默默认设置为 False。ordered=None 的新行为是保留 ordered 的现有值。
新行为:
In [2]: from pandas.api.types import CategoricalDtype
In [3]: cat = pd.Categorical(list('abcaba'), ordered=True, categories=list('cba'))
In [4]: cat
Out[4]:
[a, b, c, a, b, a]
Categories (3, object): [c < b < a]
In [5]: cdt = CategoricalDtype(categories=list('cbad'))
In [6]: cat.astype(cdt)
Out[6]:
[a, b, c, a, b, a]
Categories (4, object): [c < b < a < d]
请注意,在上面的例子中,转换后的 Categorical 保留了 ordered=True。如果 ordered 的默认值保持为 False,转换后的 Categorical 将会变成无序的,尽管 ordered=False 从未被明确指定。要更改 ordered 的值,请显式地将其传递给新的数据类型,例如 CategoricalDtype(categories=list('cbad'), ordered=False)。
请注意,上述 ordered 的无意转换在以前的版本中并未出现,这是由于单独的错误阻止了 astype 进行任何类型的类别到类别转换(GH 10696, GH 18593)。这些错误已在本次发布中修复,并促使更改了 ordered 的默认值。
在终端中更好地打印DataFrame#
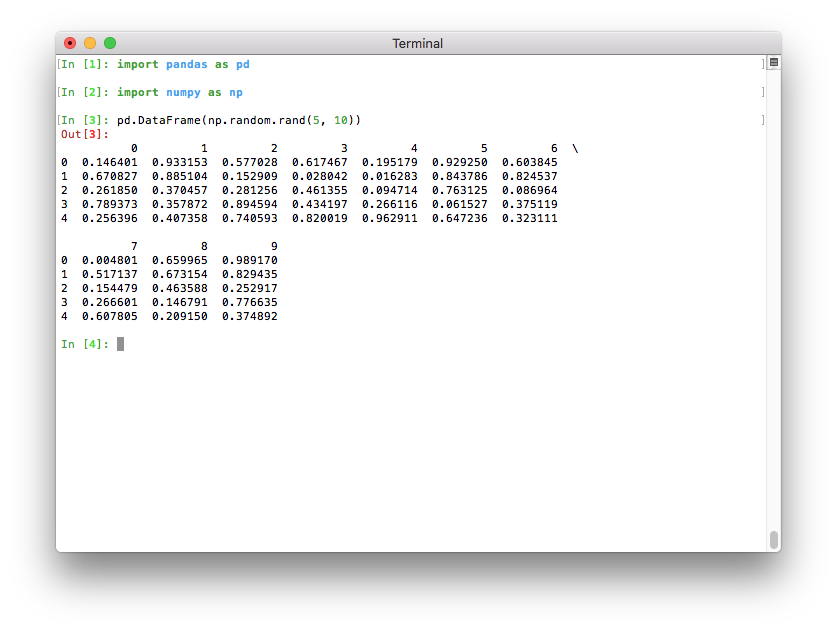
之前,最大列数的默认值是 pd.options.display.max_columns=20。这意味着相对较宽的数据框不会适应终端宽度,pandas 会引入换行来显示这 20 列。这导致输出相对难以阅读:
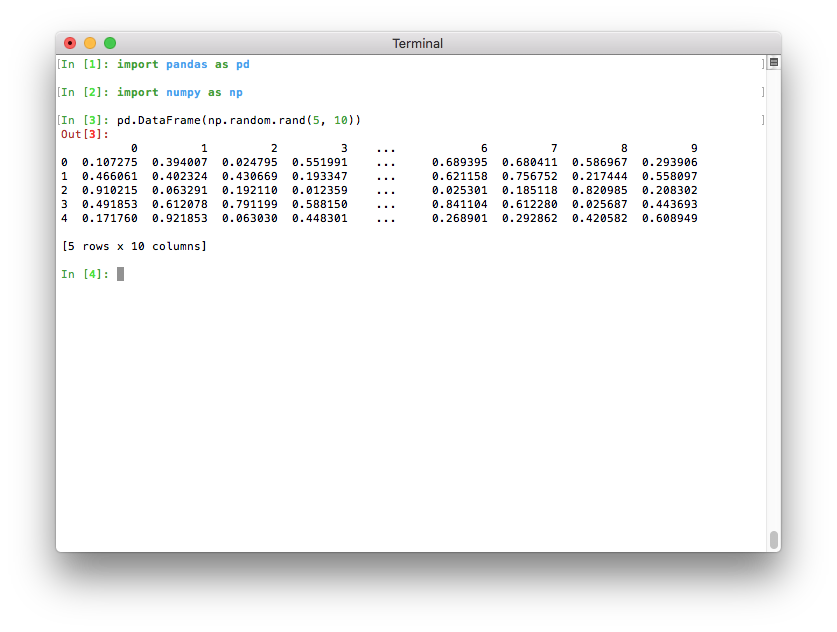
如果 Python 在终端中运行,最大列数现在会自动确定,以便打印的数据框适合当前终端宽度(pd.options.display.max_columns=0)(GH 17023)。如果 Python 作为 Jupyter 内核运行(例如 Jupyter QtConsole 或 Jupyter notebook,以及许多 IDE 中),这个值无法自动推断,因此像以前版本一样设置为 20。在终端中,这会生成一个更美观的输出:
请注意,如果你不喜欢新的默认设置,你可以随时自己设置这个选项。要恢复到旧的设置,你可以运行这一行:
pd.options.display.max_columns = 20
Datetimelike API 变化#
默认的
Timedelta构造函数现在接受一个ISO 8601 持续时间字符串作为参数 (GH 19040)从具有
dtype='datetime64[ns]'的Series中减去NaT会返回一个dtype='timedelta64[ns]'的Series,而不是dtype='datetime64[ns]'(GH 18808)从
TimedeltaIndex中添加或减去NaT将返回TimedeltaIndex而不是DatetimeIndex(GH 19124)DatetimeIndex.shift()和TimedeltaIndex.shift()现在将在索引对象频率为None时引发NullFrequencyError``(这是 ``ValueError的子类,在旧版本中会引发ValueError)(GH 19147)对
dtype='timedelta64[ns]'的Series进行NaN的加减运算将引发TypeError,而不是将NaN视为NaT(GH 19274)NaT与datetime.timedelta的除法现在将返回NaN而不是引发 (GH 17876)具有 dtype
dtype='datetime64[ns]'的Series和PeriodIndex之间的操作将正确引发TypeError(GH 18850)具有时区感知的
dtype='datetime64[ns]'的Series在时区不匹配的情况下进行减法运算将引发TypeError而不是ValueError(GH 18817)CacheableOffset和WeekDay在pandas.tseries.offsets模块中不再可用 (GH 17830)pandas.tseries.frequencies.get_freq_group()和pandas.tseries.frequencies.DAYS已从公共 API 中移除 (GH 18034)Series.truncate()和DataFrame.truncate()如果索引未排序,将引发ValueError而不是无用的KeyError(GH 17935)Series.first和DataFrame.first现在将在索引不是DatetimeIndex时引发TypeError而不是NotImplementedError(GH 20725)。Series.last和DataFrame.last现在将在索引不是DatetimeIndex时引发TypeError而不是NotImplementedError(GH 20725)。限制
DateOffset关键字参数。以前,DateOffset子类允许任意关键字参数,这可能导致意外行为。现在,只接受有效参数。(GH 17176, GH 18226)。pandas.merge()在尝试合并时区感知和时区不可知列时提供更详细的错误消息 (GH 15800)对于
DatetimeIndex和TimedeltaIndex且freq=None,整数类型的数组或Index的加法或减法将引发NullFrequencyError而不是TypeError(GH 19895)DatetimeIndex现在在实例化后设置tz属性时会引发AttributeError(GH 3746)DatetimeIndex带有pytz时区现在将返回一致的pytz时区 (GH 18595)
其他 API 更改#
Series.astype()和Index.astype()使用不兼容的 dtype 现在会引发TypeError而不是ValueError(GH 18231)使用
object类型的 tz-aware datetime 和指定dtype=object构建Series,现在将返回一个object类型的Series,以前这将推断为 datetime 类型 (GH 18231)从空的
dict构建的dtype=category的Series现在将有dtype=object的类别,而不是dtype=float64,与传递空列表的情况一致 (GH 18515)在
MultiIndex中的所有-NaN 层级现在被分配float而不是object数据类型,以促进与Index的一致性 (GH 17929)。MultiIndex的级别名称(当不为 None 时)现在要求是唯一的:尝试创建一个名称重复的MultiIndex将引发ValueError(GH 18872)使用不可哈希的
name/names构建和重命名Index/MultiIndex现在将引发TypeError(GH 20527)Index.map()现在可以接受Series和字典输入对象 (GH 12756, GH 18482, GH 18509)。DataFrame.unstack()现在默认用np.nan填充object列。(GH 12815)IntervalIndex构造函数将在closed参数与输入数据的推断闭合方式冲突时引发 (GH 18421)插入缺失值到索引中将对所有类型的索引起作用,并自动插入正确类型的缺失值(
NaN、NaT等),无论传入的类型是什么 (GH 18295)。当创建带有重复标签的
MultiIndex时,现在会引发ValueError。 (GH 17464)Series.fillna()现在在传递列表、元组或 DataFrame 作为value时会引发TypeError而不是ValueError(GH 18293)pandas.DataFrame.merge()在合并int和float列时不再将float列转换为object(GH 16572)pandas.merge()现在在尝试合并不兼容的数据类型时会引发ValueError(GH 9780)UInt64Index的默认 NA 值已从 0 更改为NaN,这影响了使用 NA 进行掩码的方法,例如UInt64Index.where()(GH 18398)重构了
setup.py以使用find_packages而不是显式列出所有子包 (GH 18535)在
read_excel()中重新排列了关键字参数的顺序,以与read_csv()对齐 (GH 16672)wide_to_long()之前将类似数字的后缀保留为object数据类型。现在如果可能的话,它们会被转换为数字 (GH 17627)在
read_excel()中,comment参数现在作为命名参数公开 (GH 18735)在
read_excel()中重新排列了关键字参数的顺序,以与read_csv()对齐 (GH 16672)选项
html.border和mode.use_inf_as_null在之前的版本中已被弃用,现在这些选项将显示FutureWarning而不是DeprecationWarning(GH 19003)IntervalIndex和IntervalDtype不再支持分类、对象和字符串子类型 (GH 19016)IntervalDtype现在在与'interval'比较时,无论子类型如何,都返回True,并且IntervalDtype.name现在无论子类型如何,都返回'interval'(GH 18980)在
drop(),drop(),drop(),drop()中,当删除轴中重复项中的一个不存在的元素时,现在会引发KeyError而不是ValueError(GH 19186)Series.to_csv()现在接受一个compression参数,其工作方式与DataFrame.to_csv()中的compression参数相同 (GH 18958)对类型不兼容的
IntervalIndex进行集合操作(并集、差集…)现在会引发TypeError而不是ValueError(GH 19329)DateOffset对象呈现更简单,例如<DateOffset: days=1>而不是<DateOffset: kwds={'days': 1}>(GH 19403)Categorical.fillna现在验证其value和method关键字参数。当两者都指定或都不指定时,现在会引发错误,与Series.fillna()的行为相匹配 (GH 19682)pd.to_datetime('today')现在返回一个 datetime,与pd.Timestamp('today')一致;之前pd.to_datetime('today')返回一个.normalized()datetime (GH 19935)Series.str.replace()现在接受一个可选的regex关键字,当设置为False时,使用字符串替换而不是正则表达式替换 (GH 16808)DatetimeIndex.strftime()和PeriodIndex.strftime()现在返回一个Index而不是一个 numpy 数组,以与类似的访问器保持一致 (GH 20127)DataFrame.to_dict()使用orient='index'不再将整数列转换为浮点数,对于仅包含整数和浮点数列的 DataFrame (GH 18580)一个传递给
Series.rolling().aggregate()、DataFrame.rolling().aggregate()或其扩展同类的用户定义函数,现在 总是 会被传递一个Series,而不是一个np.array;.apply()只有raw关键字,参见 这里。这与.aggregate()在 pandas 中的签名一致 (GH 20584)滚动和扩展类型在迭代时会引发
NotImplementedError(GH 11704)。
弃用#
Series.from_array和SparseSeries.from_array已被弃用。请使用正常的构造函数Series(..)和SparseSeries(..)代替 (GH 18213)。DataFrame.as_matrix已被弃用。请使用DataFrame.values代替 (GH 18458)。Series.asobject,DatetimeIndex.asobject,PeriodIndex.asobject和TimeDeltaIndex.asobject已被弃用。请改用.astype(object)(GH 18572)现在按键元组分组会发出
FutureWarning并被弃用。将来,传递给'by'的元组将始终引用实际的元组作为单个键,而不是将元组视为多个键。要保留以前的行为,请使用列表而不是元组 (GH 18314)Series.valid已被弃用。请改用Series.dropna()(GH 18800)。read_excel()已弃用skip_footer参数。请改用skipfooter(GH 18836)ExcelFile.parse()已经弃用sheetname而改为使用sheet_name以与read_excel()保持一致 (GH 20920)。is_copy属性已被弃用,并将在未来版本中移除 (GH 18801)。IntervalIndex.from_intervals已被弃用,取而代之的是IntervalIndex构造函数 (GH 19263)DataFrame.from_items已被弃用。请使用DataFrame.from_dict()代替,或者如果您希望保留键的顺序,请使用DataFrame.from_dict(OrderedDict())(GH 17320, GH 17312)使用包含一些缺失键的列表对
MultiIndex或FloatIndex进行索引现在会显示一个FutureWarning,这与其它类型的索引一致 (GH 17758)。apply()的broadcast参数已被弃用,取而代之的是result_type='broadcast'(GH 18577)apply()的reduce参数已被弃用,取而代之的是result_type='reduce'(GH 18577)order参数在factorize()中已被弃用,并将在未来的版本中移除 (GH 19727)Timestamp.weekday_name,DatetimeIndex.weekday_name, 和Series.dt.weekday_name已被弃用,取而代之的是Timestamp.day_name(),DatetimeIndex.day_name(), 和Series.dt.day_name()(GH 12806)pandas.tseries.plotting.tsplot已被弃用。请使用Series.plot()代替 (GH 18627)Index.summary()已被弃用,并将在未来版本中移除 (GH 18217)NDFrame.get_ftype_counts()已被弃用,并将在未来版本中移除 (GH 18243)在
DataFrame.to_records()中的convert_datetime64参数已被弃用,并将在未来版本中移除。激励此参数的 NumPy 错误已解决。此参数的默认值也已从True改为None(GH 18160)。Series.rolling().apply()、DataFrame.rolling().apply()、Series.expanding().apply()和DataFrame.expanding().apply()已弃用默认传递np.array。需要传递新的raw参数以明确传递的内容 (GH 20584)Series和Index类的data、base、strides、flags和itemsize属性已被弃用,并将在未来版本中移除 (GH 20419)。DatetimeIndex.offset已被弃用。请改用DatetimeIndex.freq(GH 20716)整数 ndarray 和
Timedelta之间的地板除法已被弃用。请改为除以Timedelta.value(GH 19761)设置
PeriodIndex.freq(这并不保证能正确工作)已被弃用。请使用PeriodIndex.asfreq()代替 (GH 20678)Index.get_duplicates()已被弃用,并将在未来版本中移除 (GH 20239)在
Categorical.take中负索引的先前默认行为已被弃用。在未来的版本中,它将从表示缺失值改为表示从右边开始的 positional indices。未来的行为与Series.take()一致 (GH 20664)。在
DataFrame.dropna()中传递多个轴到axis参数已被弃用,并将在未来版本中移除 (GH 20987)
移除先前版本的弃用/更改#
针对过时的用法
Categorical(codes, categories)的警告,例如当Categorical()的前两个参数具有不同的 dtypes 时发出的警告,并推荐使用Categorical.from_codes,现在已经移除 (GH 8074)MultiIndex的levels和labels属性不能再直接设置 (GH 4039)。pd.tseries.util.pivot_annual已被移除(自 v0.19 起弃用)。请改用pivot_table(GH 18370)pd.tseries.util.isleapyear已被移除(自 v0.19 起弃用)。请改用 Datetime-likes 中的.is_leap_year属性 (GH 18370)pd.ordered_merge已被移除(自 v0.19 起弃用)。请改用pd.merge_ordered(GH 18459)SparseList类已被移除 (GH 14007)pandas.io.wb和pandas.io.data存根模块已被移除 (GH 13735)Categorical.from_array已被移除 (GH 13854)freq和how参数已从 DataFrame 和 Series 的rolling/expanding/ewm方法中移除(自 v0.18 起已弃用)。请在调用这些方法之前先进行重采样。(GH 18601 & GH 18668)DatetimeIndex.to_datetime,Timestamp.to_datetime,PeriodIndex.to_datetime, 和Index.to_datetime已被移除 (GH 8254, GH 14096, GH 14113)read_csv()已经删除了skip_footer参数 (GH 13386)read_csv()已经删除了as_recarray参数 (GH 13373)read_csv()已经移除了buffer_lines参数 (GH 13360)read_csv()已删除compact_ints和use_unsigned参数 (GH 13323)Timestamp类已经放弃了offset属性,转而使用freq(GH 13593)Series、Categorical和Index类已经移除了reshape方法 (GH 13012)pandas.tseries.frequencies.get_standard_freq已被移除,取而代之的是pandas.tseries.frequencies.to_offset(freq).rule_code(GH 13874)freqstr关键字已从pandas.tseries.frequencies.to_offset中移除,取而代之的是freq(GH 13874)Panel4D和PanelND类已被移除 (GH 13776)Panel类已经移除了to_long和toLong方法 (GH 19077)选项
display.line_with和display.height分别被display.width和display.max_rows取代 (GH 4391, GH 19107)Categorical类的labels属性已被移除,取而代之的是Categorical.codes(GH 7768)flavor参数已从to_sql()方法中移除 (GH 13611)模块
pandas.tools.hashing和pandas.util.hashing已被移除 (GH 16223)顶级函数
pd.rolling_*,pd.expanding_*和pd.ewm*已被移除(自 v0.18 起弃用)。请改用 DataFrame/Series 方法rolling,expanding和ewm(GH 18723)从
pandas.core.common导入的函数,如is_datetime64_dtype现在已被移除。这些函数位于pandas.api.types中。(GH 13634, GH 19769)在
Series.tz_localize()、DatetimeIndex.tz_localize()和DatetimeIndex中的infer_dst关键字已被移除。infer_dst=True等同于ambiguous='infer',而infer_dst=False等同于ambiguous='raise'(GH 7963)。当
.resample()从急切操作变为懒惰操作时,就像在 v0.18.0 中的.groupby()一样,我们设置了兼容性(带有FutureWarning),以便操作可以继续工作。现在这已经完全移除,因此Resampler将不再转发兼容操作 (GH 20554)从
.replace()中移除长期弃用的axis=None参数 (GH 20271)
性能提升#
在
Series或DataFrame上的索引器不再创建引用循环 (GH 17956)为
to_datetime()添加了一个关键字参数cache,这改进了转换重复日期时间参数的性能 (GH 11665)DateOffset算术性能得到提升 (GH 18218)将
Series的Timedelta对象转换为天数、秒数等… 通过底层方法的矢量化加速 (GH 18092)使用
Series/dict输入改进了.map()的性能 (GH 15081)被重写的
Timedelta属性 days、seconds 和 microseconds 已被移除,转而利用它们内置的 Python 版本 (GH 18242)Series构造将在某些情况下减少对输入数据复制的次数(GH 17449)改进了
Series.dt.date()和DatetimeIndex.date()的性能 (GH 18058)改进了
Series.dt.time()和DatetimeIndex.time()的性能 (GH 18461)改进了
IntervalIndex.symmetric_difference()的性能 (GH 18475)改进了
DatetimeIndex和Series在 Business-Month 和 Business-Quarter 频率下的算术运算性能 (GH 18489)Series()/DataFrame()标签补全限制为 100 个值,以提高性能。(GH 18587)在没有安装 bottleneck 的情况下,改进了
axis=1时DataFrame.median()的性能 (GH 16468)改进了对大索引的
MultiIndex.get_loc()性能,但牺牲了小索引的性能 (GH 18519)在没有任何未使用级别时,改进了
MultiIndex.remove_unused_levels()的性能,但在有未使用级别时性能有所降低 (GH 19289)改进了非唯一索引的
Index.get_loc()性能 (GH 19478)改进了成对
.rolling()和.expanding()与.cov()和.corr()操作的性能 (GH 17917)改进了
GroupBy.rank()的性能 (GH 15779)改进了变量
.rolling()在.min()和.max()上的性能 (GH 19521)改进了
GroupBy.ffill()和GroupBy.bfill()的性能 (GH 11296)改进了
GroupBy.any()和GroupBy.all()的性能 (GH 15435)改进了
GroupBy.pct_change()的性能 (GH 19165)在分类数据类型的情况下,改进了
Series.isin()的性能 (GH 20003)在
Series具有某些索引类型时,改进了getattr(Series, attr)的性能。这在打印具有DatetimeIndex的大型Series时表现为缓慢 (GH 19764)修复了某些对象列在使用
GroupBy.nth()和GroupBy.last()时的性能退化问题 (GH 19283)改进了
Categorical.from_codes()的性能 (GH 18501)
文档更改#
感谢所有参与 pandas 文档冲刺的贡献者,该活动于 3 月 10 日举行。我们有来自全球超过 30 个地点的约 500 名参与者。您应该注意到许多 API 文档字符串 得到了极大的改进。
由于同时进行的贡献太多,无法为每个改进都包含一个发布说明,但这个 GitHub 搜索 应该能让你了解有多少文档字符串得到了改进。
特别感谢 Marc Garcia 组织了这次冲刺。欲了解更多信息,请阅读 NumFOCUS 博客文章 回顾这次冲刺。
错误修复#
分类#
警告
在 pandas 0.21 中引入了一类错误,与 CategoricalDtype 相关,这会影响 merge、concat 和索引等操作的正确性,当比较多个具有相同类别但顺序不同的无序 Categorical 数组时。我们强烈建议在进行这些操作之前升级或手动对齐您的类别。
在比较两个具有相同类别但顺序不同的无序
Categorical数组时,Categorical.equals返回错误结果 (GH 16603)在
pandas.api.types.union_categoricals()中存在一个错误,当处理不同顺序的无序分类时,返回了错误的结果。这影响了带有分类数据的pandas.concat()(GH 19096)。在
pandas.merge()中存在一个错误,当基于一个未排序的Categorical进行连接时,即使类别相同但顺序不同,也会返回错误的结果 (GH 19551)在
target是一个未排序的Categorical且具有与self相同的类别但顺序不同时,CategoricalIndex.get_indexer()返回错误结果的错误 (GH 19551)在具有分类数据类型的
Index.astype()中存在一个错误,其中结果索引没有转换为所有类型索引的CategoricalIndex(GH 18630)在
Series.astype()和Categorical.astype()中的错误,其中现有的分类数据未更新 (GH 10696, GH 18593)在
Series.str.split()中使用expand=True时,对空字符串不正确地引发 IndexError 的错误 (GH 20002)。在
dtype=CategoricalDtype(...)的情况下,Index构造函数中的错误,其中categories和ordered未被维护 (GH 19032)在带有标量和
dtype=CategoricalDtype(...)的Series构造函数中,categories和ordered未被维护的错误 (GH 19565)Categorical.__iter__中的错误未转换为 Python 类型 (GH 19909)在
pandas.factorize()中返回uniques的唯一代码的错误。现在返回一个与输入具有相同 dtype 的Categorical(GH 19721)pandas.factorize()中的一个错误,包括在uniques返回值中为缺失值添加一个项目 (GH 19721)在
Series.take()中使用分类数据时,将indices中的-1解释为缺失值标记,而不是 Series 的最后一个元素 (GH 20664)
Datetimelike#
在
Series.__sub__()中,从一个Series中减去一个非纳秒的np.datetime64对象会给出不正确的结果 (GH 7996)DatetimeIndex和TimedeltaIndex中的错误,零维整数数组的加减运算给出了不正确的结果 (GH 19012)在
DatetimeIndex和TimedeltaIndex中的错误,其中添加或减去DateOffset对象的类数组时,要么引发错误(np.array,pd.Index),要么错误地广播(pd.Series) (GH 18849)在
Series.__add__()中,将 dtypetimedelta64[ns]的 Series 添加到带时区的DatetimeIndex时,错误地丢弃了时区信息 (GH 13905)将
Period对象添加到datetime或Timestamp对象现在会正确地引发TypeError(GH 17983)在
Timestamp中的一个错误,当与Timestamp对象数组进行比较时会导致RecursionError(GH 15183)在
Series的整除操作中存在一个错误,当对一个标量timedelta进行操作时会引发异常 (GH 18846)在
DatetimeIndex中的一个错误,其中 repr 没有显示一天结束时的高精度时间值(例如,23:59:59.999999999)(GH 19030)在
.astype()转换为非纳秒时间增量单位时会持有不正确的数据类型 (GH 19176, GH 19223, GH 12425)在
Series.truncate()中存在一个错误,当使用单调的PeriodIndex时会引发TypeError(GH 17717)在使用
periods和freq时,pct_change()中的错误返回了不同长度的输出 (GH 7292)DatetimeIndex与None或datetime.date对象进行比较时,对于==和!=比较会引发TypeError,而不是分别返回全False和全True(GH 19301)在
Timestamp和to_datetime()中的一个错误,其中表示略微超出范围的时间戳字符串会被错误地向下舍入,而不是引发OutOfBoundsDatetime(GH 19382)在
Timestamp.floor()DatetimeIndex.floor()中的错误,其中未来的和过去的时间戳没有正确舍入 (GH 19206)在
to_datetime()中的一个错误,当传递一个超出范围的日期时间且带有errors='coerce'和utc=True时,会引发OutOfBoundsDatetime而不是解析为NaT(GH 19612)DatetimeIndex和TimedeltaIndex加减法中的一个错误,返回对象的名称并不总是被一致地设置。(GH 19744)DatetimeIndex和TimedeltaIndex加减法中的错误,其中与 numpy 数组的运算引发了TypeError(GH 19847)DatetimeIndex和TimedeltaIndex中的一个错误,设置freq属性未完全支持 (GH 20678)
Timedelta#
Timedelta.__mul__()中的一个错误,其中乘以NaT返回NaT而不是引发TypeError(GH 19819)Series中的一个错误,当dtype='timedelta64[ns]'时,TimedeltaIndex的加法或减法会将结果转换为dtype='int64'(GH 17250)Series中的一个错误,当dtype='timedelta64[ns]'时,TimedeltaIndex的加法或减法可能会返回一个名称不正确的Series(GH 19043)在
Timedelta.__floordiv__()和Timedelta.__rfloordiv__()中,除以许多不兼容的 numpy 对象被错误地允许 (GH 18846)在将一个标量的类时间增量对象与
TimedeltaIndex相除时,执行了互反操作的错误 (GH 19125)在
TimedeltaIndex中的一个错误,其中除以一个Series会返回一个TimedeltaIndex而不是一个Series(GH 19042)在
Timedelta.__add__(),Timedelta.__sub__()中的错误,其中添加或减去一个np.timedelta64对象会返回另一个np.timedelta64而不是Timedelta(GH 19738)在
Timedelta.__floordiv__(),Timedelta.__rfloordiv__()中的错误,在与Tick对象操作时会引发TypeError而不是返回一个数值 (GH 19738)在
Period.asfreq()中的错误,其中接近datetime(1, 1, 1)的周期可能被转换不正确 (GH 19643, GH 19834)Timedelta.total_seconds()中的一个错误导致精度错误,例如Timedelta('30S').total_seconds()==30.000000000000004(GH 19458)在
Timedelta.__rmod__()中的错误,在与numpy.timedelta64操作时返回了一个timedelta64对象而不是Timedelta对象 (GH 19820)TimedeltaIndex乘以TimedeltaIndex现在将在长度不匹配的情况下引发TypeError而不是ValueError(GH 19333)在用
np.timedelta64对象索引TimedeltaIndex时出现的错误,该错误引发了TypeError(GH 20393)
时区#
从包含 tz-naive 和 tz-aware 值的数组创建
Series时出现的错误将导致Series的 dtype 是 tz-aware 而不是 object (GH 16406)时区感知的
DatetimeIndex与NaT比较时错误地引发TypeError的错误 (GH 19276)在
DatetimeIndex.astype()中转换时区感知 dtypes 之间以及从时区感知转换为朴素时存在错误 (GH 18951)在比较
DatetimeIndex时出现的错误,在尝试比较带时区和无时区的类似日期对象时未能引发TypeError(GH 18162)在
Series构造函数中,使用datetime64[ns, tz]dtype 时,本地化一个简单的 datetime 字符串的错误 (GH 174151)Timestamp.replace()现在会优雅地处理夏令时转换 (GH 18319)在 tz-aware
DatetimeIndex中,与TimedeltaIndex或dtype='timedelta64[ns]'的数组进行加法/减法运算时存在错误 (GH 17558)在
DatetimeIndex.insert()中的错误,在时区感知的索引中插入NaT时错误地引发了 (GH 16357)DataFrame构造函数中的错误,其中 tz-aware Datetimeindex 和给定的列名将导致一个空的DataFrame(GH 19157)在
Timestamp.tz_localize()中的一个错误,当本地化接近最小或最大有效值的时间戳时可能会溢出,并返回一个具有不正确纳秒值的时间戳 (GH 12677)在迭代
DatetimeIndex时出现错误,该索引已使用固定时区偏移进行本地化,并将纳秒精度四舍五入到微秒 (GH 19603)在
DataFrame.diff()中出现的错误,当使用 tz-aware 值时会引发IndexError(GH 18578)在
Dataframe.count()中存在的错误,如果在具有时区感知值的单个列上调用了Dataframe.dropna(),则会引发ValueError。 (GH 13407)
偏移量#
在
WeekOfMonth和Week中的加法和减法没有正确进位的问题 (GH 18510, GH 18672, GH 18864)WeekOfMonth和LastWeekOfMonth中的一个错误,其中构造函数的默认关键字参数引发了ValueError(GH 19142)在
FY5253Quarter和LastWeekOfMonth中的错误,其中回滚和前滚行为与加法和减法行为不一致 (GH 18854)在
FY5253中的错误,其中datetime的加减操作在年末日期上不正确地递增,但没有归一化到午夜 (GH 18854)在
FY5253中的一个错误,其中日期偏移量可能在算术运算中不正确地引发AssertionError(GH 14774)
Numeric#
在
Series构造函数中,使用 int 或 float 列表并指定dtype=str、dtype='str'或dtype='U'时,未能将数据元素转换为字符串 (GH 16605)在
Index的乘法和除法方法中的错误,当与Series操作时会返回一个Index对象而不是Series对象 (GH 19042)在
DataFrame构造函数中的一个错误,其中包含非常大的正数或非常大的负数的数据会导致OverflowError(GH 18584)在
dtype='uint64'的Index构造函数中存在一个错误,其中类似整数的浮点数未被强制转换为UInt64Index(GH 18400)DataFrame的灵活算术中的错误(例如df.add(other, fill_value=foo))在fill_value不是None的情况下,在框架或other的长度为零的极端情况下未能引发NotImplementedError(GH 19522)数值类型的
Index对象与 timedelta 类型的标量进行乘法和除法运算时,返回TimedeltaIndex而不是引发TypeError(GH 19333)当
fill_method不是None时,Series.pct_change()和DataFrame.pct_change()返回NaN而不是 0 的错误 (GH 19873)
字符串#
在值中带有字典且索引不在键中的
Series.str.get()存在错误,引发KeyError(GH 20671)
索引#
在传递包含元组和非元组列表时
Index.drop()中的错误 (GH 18304)在
DataFrame.drop()、Panel.drop()、Series.drop()、Index.drop()中的一个错误,当从一个包含重复项的轴中删除一个不存在的元素时,不会引发KeyError(GH 19186)在索引一个引发
ValueError而不是IndexError的类似日期时间的Index中的错误 (GH 18386)。Index.to_series()现在接受index和namekwargs (GH 18699)DatetimeIndex.to_series()现在接受index和namekwargs (GH 18699)在
Series中索引非标量值时,如果Index不是唯一的,将返回扁平化的值 (GH 17610)使用仅包含缺失键的迭代器进行索引时出现错误,但没有引发错误 (GH 20748)
在索引具有整数数据类型且不包含所需键时,修正了
.ix在列表和标量键之间的一致性问题 (GH 20753)当没有匹配项时,
str.extractall中的错误会返回空的Index而不是适当的MultiIndex(GH 19034)在
IntervalIndex中的一个错误,其中空数据和纯 NA 数据根据构造方法的不同而构造不一致 (GH 18421)在
IntervalIndex.symmetric_difference()中的一个错误,当与非IntervalIndex进行对称差集时没有引发 (GH 18475)在
IntervalIndex中的错误,其中返回空IntervalIndex的集合操作具有错误的 dtype (GH 19101)在
DataFrame.drop_duplicates()中的一个错误,当传递不存在于DataFrame上的列时,不会引发KeyError(GH 19726)Index子类构造函数中忽略意外关键字参数的错误 (GH 19348)当对一个
Index与其自身进行Index.difference()操作时出现的错误 (GH 20040)在值的中间存在全NaN行的情况下,
DataFrame.first_valid_index()和DataFrame.last_valid_index()中的错误 (GH 20499)。在
IntervalIndex中的一个错误,其中一些索引操作不支持重叠或非单调的uint64数据 (GH 20636)在
Series.is_unique中存在一个错误,如果 Series 包含定义了__ne__的对象,会在 stderr 中显示多余的输出 (GH 20661)在
.loc赋值中,使用单元素类列表错误地赋值为列表 (GH 19474)在具有单调递减
DatetimeIndex的Series/DataFrame上进行部分字符串索引时存在错误 (GH 19362)在具有重复
Index的DataFrame上执行就地操作时的错误 (GH 17105)当与包含单个区间的
IntervalIndex一起使用时,IntervalIndex.get_loc()和IntervalIndex.get_indexer()中的错误 (GH 17284, GH 20921)loc中的错误与uint64索引器 (GH 20722)
MultiIndex#
在
MultiIndex.__contains__()中的一个错误,其中非元组键即使已被删除也会返回True(GH 19027)MultiIndex.set_labels()中的一个错误,如果level参数不是 0 或类似 [0, 1, … ] 的列表,会导致新标签的转换(并可能截断) (GH 19057)MultiIndex.get_level_values()中的一个错误,该错误会在包含缺失值的整数级别上返回一个无效的索引 (GH 17924)在空的
MultiIndex上调用MultiIndex.unique()时出现的错误 (GH 20568)在
MultiIndex.unique()中的错误,该错误不会保留级别名称 (GH 20570)在
MultiIndex.remove_unused_levels()中的错误,会导致填充 nan 值 (GH 18417)在
MultiIndex.from_tuples()中的错误,在 Python3 中无法处理压缩的元组 (GH 18434)在
MultiIndex.get_loc()中的一个错误,该错误会导致无法在浮点数和整数之间自动转换值 (GH 18818, GH 15994)在
MultiIndex.get_loc()中的错误,会将布尔值转换为整数标签 (GH 19086)在
MultiIndex.get_loc()中的错误,该错误无法定位包含NaN的键 (GH 18485)在大型
MultiIndex中MultiIndex.get_loc()的错误,当级别具有不同的 dtypes 时会失败 (GH 18520)在索引中存在一个错误,其中仅包含 numpy 数组的嵌套索引器处理不正确 (GH 19686)
IO#
read_html()现在在解析失败后会重新定位可查找的IO对象,然后尝试使用新的解析器进行解析。如果解析器出错且对象不可查找,则会引发一个信息性错误,建议使用不同的解析器 (GH 17975)DataFrame.to_html()现在有一个选项可以为主要的<table>标签添加一个 id (GH 8496)在传入一个不存在的文件时,
read_msgpack()存在一个错误,这在 Python 2 中出现 (GH 15296)在
read_csv()中的一个错误,其中包含重复列的MultiIndex没有被适当地处理 (GH 18062)在
keep_default_na=False且使用字典na_values时,read_csv()中未正确处理缺失值的错误 (GH 19227)在32位、大端架构上,
read_csv()中的错误导致堆损坏 (GH 20785)在
read_sas()中的一个错误,当一个文件有0个变量时,错误地给出了一个AttributeError。现在它给出了一个EmptyDataError(GH 18184)在
DataFrame.to_latex()中的一个错误,其中作为隐形占位符的双大括号被转义了 (GH 18667)DataFrame.to_latex()中的一个错误,其中MultiIndex中的NaN会导致IndexError或不正确的输出 (GH 14249)在
DataFrame.to_latex()中的一个错误,其中非字符串索引级别名称会导致AttributeError(GH 19981)在
DataFrame.to_latex()中的一个错误,当索引名称和index_names=False选项结合使用时,会导致输出不正确 (GH 18326)DataFrame.to_latex()中的一个错误,其中MultiIndex的名称是一个空字符串会导致输出不正确 (GH 18669)DataFrame.to_latex()中的一个错误,其中缺少空格字符导致错误的转义,在某些情况下产生无效的 latex (GH 20859)在
read_json()中存在一个错误,其中大数值导致OverflowError(GH 18842)在
DataFrame.to_parquet()中的一个错误,如果在写入目的地是 S3 时会引发异常 (GH 19134)Interval现在在DataFrame.to_excel()中支持所有 Excel 文件类型 (GH 19242)Timedelta现在在DataFrame.to_excel()中支持所有 Excel 文件类型 (GH 19242, GH 9155, GH 19900)在非常旧的文件上调用时,
pandas.io.stata.StataReader.value_labels()中的错误引发了一个AttributeError。现在返回一个空字典 (GH 19417)在解封装包含
TimedeltaIndex或Float64Index对象时,read_pickle()中的错误,这些对象是用 0.20 版本之前的 pandas 创建的 (GH 19939)在
pandas.io.json.json_normalize()中的一个错误,如果任何子记录的值是 NoneType,子记录不会被正确规范化 (GH 20030)在
read_csv()中的usecols参数存在错误,当传递字符串时不会正确引发错误。(GH 20529)在读取包含软链接的文件时,
HDFStore.keys()中的错误导致异常 (GH 20523)在
HDFStore.select_column()中的一个错误,其中一个不是有效存储的键引发了AttributeError而不是KeyError(GH 17912)
绘图#
尝试绘图但未安装 matplotlib 时的更好错误消息 (GH 19810)。
DataFrame.plot()现在在x或y参数格式不正确时会引发ValueError(GH 18671)当
x和y参数作为位置给出时,DataFrame.plot()中的错误导致线图、条形图和面积图的引用列不正确 (GH 20056)使用
datetime.time()和带小数秒的刻度标签格式化时出现的错误 (GH 18478)。Series.plot.kde()在文档字符串中公开了参数ind和bw_method(GH 18461)。参数ind现在也可以是一个整数(样本点的数量)。DataFrame.plot()现在支持y参数的多个列 (GH 19699)
GroupBy/重采样/滚动#
当按单列分组并对类如
list或tuple进行聚合时出现的错误 (GH 18079)修复了
DataFrame.groupby()中的回归问题,当使用不在索引中的元组键调用时不会发出错误 (GH 18798)DataFrame.resample()中的一个错误,该错误静默忽略了对label、closed和convention的不支持(或拼写错误)选项 (GH 19303)在
DataFrame.groupby()中的一个错误,其中元组被解释为键的列表而不是键 (GH 17979, GH 18249)在
DataFrame.groupby()中的一个错误,其中通过first/last/min/max进行聚合会导致时间戳失去精度 (GH 19526)在
DataFrame.transform()中的一个错误,其中特定的聚合函数被错误地转换以匹配分组数据的 dtype(GH 19200)在
DataFrame.groupby()中传递on=关键字参数,并随后使用.apply()时出现的错误 (GH 17813)在
DataFrame.resample().aggregate中的错误,在聚合一个不存在的列时没有引发KeyError(GH 16766, GH 19566)当传递
skipna时,DataFrameGroupBy.cumsum()和DataFrameGroupBy.cumprod()中的错误 (GH 19806)在
DataFrame.resample()中丢失时区信息的错误 (GH 13238)DataFrame.groupby()中的一个错误,在使用np.all和np.any进行转换时会引发ValueError(GH 20653)DataFrame.resample()中的一个错误,其中ffill、bfill、pad、backfill、fillna、interpolate和asfreq忽略了loffset。(GH 20744)当应用一个包含混合数据类型的函数且用户提供的函数在分组列上失败时,
DataFrame.groupby()中存在一个错误 (GH 20949)在
DataFrameGroupBy.rolling().apply()中的错误,其中对关联的DataFrameGroupBy对象执行的操作可能会影响分组项在结果中的包含情况 (GH 14013)
Sparse#
Reshaping#
在
DataFrame.merge()中的一个错误,当通过名称引用CategoricalIndex时,by关键字参数会导致KeyError(GH 20777)在 Python 3 下尝试对混合类型层级进行排序时,
DataFrame.stack()中的错误 (GH 18310)在
DataFrame.unstack()中的错误,如果columns是一个包含未使用级别的MultiIndex,则会将整数转换为浮点数 (GH 17845)在
DataFrame.unstack()中的错误,如果在unstack级别上index是一个带有未使用标签的MultiIndex,则会引发错误 (GH 18562)禁用了构建
Series时 len(index) > len(data) = 1 的情况,这之前会广播数据项,现在会引发ValueError(GH 18819)在从包含标量值的
dict构建DataFrame时,如果传递的索引中不包含相应的键,则抑制错误 (GH 18600)固定(从
object改为float64)了使用轴、无数据和dtype=int初始化的DataFrame的 dtype (GH 19646)在包含
NaT的Series中Series.rank()的错误会就地修改Series(GH 18521)在
DataFrame.pivot_table()中的错误,当aggfunc参数是字符串类型时会失败。现在该行为与其他方法如agg和apply一致 (GH 18713)在
DataFrame.merge()中的一个错误,其中使用Index对象作为向量进行合并时引发了异常 (GH 19038)在
DataFrame.stack()、DataFrame.unstack()、Series.unstack()中存在一个错误,这些方法没有返回子类 (GH 15563)时区比较中的错误,表现为在
.concat()中将索引转换为 UTC (GH 18523)在连接稀疏和密集系列时,
concat()中的错误只返回一个SparseDataFrame。应该是DataFrame。(GH 18914, GH 18686, 和 GH 16874)改进了当没有共同合并键时
DataFrame.merge()的错误信息 (GH 19427)在
DataFrame.join()中的一个错误,当与多个 DataFrame 一起调用并且某些 DataFrame 具有非唯一索引时,会执行outer而不是left连接 (GH 19624)Series.rename()现在接受axis作为关键字参数 (GH 18589)比较
Series和Index会返回一个名称错误的Series,忽略Index的名称属性 (GH 19582)在
qcut()中存在一个错误,当包含NaT的 datetime 和 timedelta 数据引发了一个ValueError(GH 19768)在
DataFrame.iterrows()中的错误,该错误会将不符合 ISO8601 的字符串推断为日期时间 (GH 19671)Series构造函数中的一个错误,当使用Categorical时,给定不同长度的索引时不会引发ValueError(GH 19342)在
DataFrame.astype()中的一个错误,当转换为分类或数据类型字典时,列元数据丢失 (GH 19920)在
get_dummies()和select_dtypes()中的错误,重复的列名导致不正确的行为 (GH 20848)
其他#
在使用
numexpr支持的查询中尝试将 Python 关键字用作标识符时,改进了错误消息 (GH 18221)在访问
pandas.get_option()时出现的错误,在某些情况下查找不存在的选项键时会引发KeyError而不是OptionError(GH 19789)testing.assert_series_equal()和testing.assert_frame_equal()中对于包含不同Unicode数据的Series或DataFrame的Bug (GH 20503)
贡献者#
总共有328人为这次发布贡献了补丁。名字旁边有“+”的人第一次贡献了补丁。
Aaron Critchley
AbdealiJK +
Adam Hooper +
Albert Villanova del Moral
Alejandro Giacometti +
Alejandro Hohmann +
Alex Rychyk
Alexander Buchkovsky
Alexander Lenail +
Alexander Michael Schade
Aly Sivji +
Andreas Költringer +
Andrew
Andrew Bui +
András Novoszáth +
Andy Craze +
Andy R. Terrel
Anh Le +
Anil Kumar Pallekonda +
Antoine Pitrou +
Antonio Linde +
Antonio Molina +
Antonio Quinonez +
Armin Varshokar +
Artem Bogachev +
Avi Sen +
Azeez Oluwafemi +
Ben Auffarth +
Bernhard Thiel +
Bhavesh Poddar +
BielStela +
Blair +
Bob Haffner
Brett Naul +
Brock Mendel
Bryce Guinta +
Carlos Eduardo Moreira dos Santos +
Carlos García Márquez +
Carol Willing
Cheuk Ting Ho +
Chitrank Dixit +
Chris
Chris Burr +
Chris Catalfo +
Chris Mazzullo
Christian Chwala +
Cihan Ceyhan +
Clemens Brunner
Colin +
Cornelius Riemenschneider
Crystal Gong +
DaanVanHauwermeiren
Dan Dixey +
Daniel Frank +
Daniel Garrido +
Daniel Sakuma +
DataOmbudsman +
Dave Hirschfeld
Dave Lewis +
David Adrián Cañones Castellano +
David Arcos +
David C Hall +
David Fischer
David Hoese +
David Lutz +
David Polo +
David Stansby
Dennis Kamau +
Dillon Niederhut
Dimitri +
Dr. Irv
Dror Atariah
Eric Chea +
Eric Kisslinger
Eric O. LEBIGOT (EOL) +
FAN-GOD +
Fabian Retkowski +
Fer Sar +
Gabriel de Maeztu +
Gianpaolo Macario +
Giftlin Rajaiah
Gilberto Olimpio +
Gina +
Gjelt +
Graham Inggs +
Grant Roch
Grant Smith +
Grzegorz Konefał +
Guilherme Beltramini
HagaiHargil +
Hamish Pitkeathly +
Hammad Mashkoor +
Hannah Ferchland +
Hans
Haochen Wu +
Hissashi Rocha +
Iain Barr +
Ibrahim Sharaf ElDen +
Ignasi Fosch +
Igor Conrado Alves de Lima +
Igor Shelvinskyi +
Imanflow +
Ingolf Becker
Israel Saeta Pérez
Iva Koevska +
Jakub Nowacki +
Jan F-F +
Jan Koch +
Jan Werkmann
Janelle Zoutkamp +
Jason Bandlow +
Jaume Bonet +
Jay Alammar +
Jeff Reback
JennaVergeynst
Jimmy Woo +
Jing Qiang Goh +
Joachim Wagner +
Joan Martin Miralles +
Joel Nothman
Joeun Park +
John Cant +
Johnny Metz +
Jon Mease
Jonas Schulze +
Jongwony +
Jordi Contestí +
Joris Van den Bossche
José F. R. Fonseca +
Jovixe +
Julio Martinez +
Jörg Döpfert
KOBAYASHI Ittoku +
Kate Surta +
Kenneth +
Kevin Kuhl
Kevin Sheppard
Krzysztof Chomski
Ksenia +
Ksenia Bobrova +
Kunal Gosar +
Kurtis Kerstein +
Kyle Barron +
Laksh Arora +
Laurens Geffert +
Leif Walsh
Liam Marshall +
Liam3851 +
Licht Takeuchi
Liudmila +
Ludovico Russo +
Mabel Villalba +
Manan Pal Singh +
Manraj Singh
Marc +
Marc Garcia
Marco Hemken +
Maria del Mar Bibiloni +
Mario Corchero +
Mark Woodbridge +
Martin Journois +
Mason Gallo +
Matias Heikkilä +
Matt Braymer-Hayes
Matt Kirk +
Matt Maybeno +
Matthew Kirk +
Matthew Rocklin +
Matthew Roeschke
Matthias Bussonnier +
Max Mikhaylov +
Maxim Veksler +
Maximilian Roos
Maximiliano Greco +
Michael Penkov
Michael Röttger +
Michael Selik +
Michael Waskom
Mie~~~
Mike Kutzma +
Ming Li +
Mitar +
Mitch Negus +
Montana Low +
Moritz Münst +
Mortada Mehyar
Myles Braithwaite +
Nate Yoder
Nicholas Ursa +
Nick Chmura
Nikos Karagiannakis +
Nipun Sadvilkar +
Nis Martensen +
Noah +
Noémi Éltető +
Olivier Bilodeau +
Ondrej Kokes +
Onno Eberhard +
Paul Ganssle +
Paul Mannino +
Paul Reidy
Paulo Roberto de Oliveira Castro +
Pepe Flores +
Peter Hoffmann
Phil Ngo +
Pietro Battiston
Pranav Suri +
Priyanka Ojha +
Pulkit Maloo +
README Bot +
Ray Bell +
Riccardo Magliocchetti +
Ridhwan Luthra +
Robert Meyer
Robin
Robin Kiplang’at +
Rohan Pandit +
Rok Mihevc +
Rouz Azari
Ryszard T. Kaleta +
Sam Cohan
Sam Foo
Samir Musali +
Samuel Sinayoko +
Sangwoong Yoon
SarahJessica +
Sharad Vijalapuram +
Shubham Chaudhary +
SiYoungOh +
Sietse Brouwer
Simone Basso +
Stefania Delprete +
Stefano Cianciulli +
Stephen Childs +
StephenVoland +
Stijn Van Hoey +
Sven
Talitha Pumar +
Tarbo Fukazawa +
Ted Petrou +
Thomas A Caswell
Tim Hoffmann +
Tim Swast
Tom Augspurger
Tommy +
Tulio Casagrande +
Tushar Gupta +
Tushar Mittal +
Upkar Lidder +
Victor Villas +
Vince W +
Vinícius Figueiredo +
Vipin Kumar +
WBare
Wenhuan +
Wes Turner
William Ayd
Wilson Lin +
Xbar
Yaroslav Halchenko
Yee Mey
Yeongseon Choe +
Yian +
Yimeng Zhang
ZhuBaohe +
Zihao Zhao +
adatasetaday +
akielbowicz +
akosel +
alinde1 +
amuta +
bolkedebruin
cbertinato
cgohlke
charlie0389 +
chris-b1
csfarkas +
dajcs +
deflatSOCO +
derestle-htwg
discort
dmanikowski-reef +
donK23 +
elrubio +
fivemok +
fjdiod
fjetter +
froessler +
gabrielclow
gfyoung
ghasemnaddaf
h-vetinari +
himanshu awasthi +
ignamv +
jayfoad +
jazzmuesli +
jbrockmendel
jen w +
jjames34 +
joaoavf +
joders +
jschendel
juan huguet +
l736x +
luzpaz +
mdeboc +
miguelmorin +
miker985
miquelcamprodon +
orereta +
ottiP +
peterpanmj +
rafarui +
raph-m +
readyready15728 +
rmihael +
samghelms +
scriptomation +
sfoo +
stefansimik +
stonebig
tmnhat2001 +
tomneep +
topper-123
tv3141 +
verakai +
xpvpc +
zhanghui +