! [ -e /content ] && pip install -Uqq fastai # 在Colab上升级fastai核心视觉
::: {#cell-2 .cell 0=‘默’ 1=‘认’ 2=‘导’ 3=‘出’ 4=’ ’ 5=‘v’ 6=‘i’ 7=‘s’ 8=‘i’ 9=‘o’ 10=‘n’ 11=‘.’ 12=‘c’ 13=‘o’ 14=‘r’ 15=‘e’}
### 默认类级别 3:::
from __future__ import annotations
from fastai.torch_basics import *
from fastai.data.all import *
from PIL import Image
try: BILINEAR,NEAREST = Image.Resampling.BILINEAR,Image.Resampling.NEAREST
except AttributeError: from PIL.Image import BILINEAR,NEAREST_all_ = ['BILINEAR','NEAREST']from fastai.data.external import *from nbdev.showdoc import *_all_ = ['Image','ToTensor']@patch
def __repr__(x:Image.Image):
return "<%s.%s image mode=%s size=%dx%d>" % (x.__class__.__module__, x.__class__.__name__, x.mode, x.size[0], x.size[1])基本图像打开/处理功能
帮助程序
imagenet_stats = ([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
cifar_stats = ([0.491, 0.482, 0.447], [0.247, 0.243, 0.261])
mnist_stats = ([0.131], [0.308])im = Image.open(TEST_IMAGE).resize((30,20))if not hasattr(Image,'_patched'):
_old_sz = Image.Image.size.fget
@patch(as_prop=True)
def size(x:Image.Image): return fastuple(_old_sz(x))
Image._patched = True@patch(as_prop=True)
def n_px(x: Image.Image): return x.size[0] * x.size[1]test_eq(im.n_px, 30*20)@patch(as_prop=True)
def shape(x: Image.Image): return x.size[1],x.size[0]test_eq(im.shape, (20,30))@patch(as_prop=True)
def aspect(x: Image.Image): return x.size[0]/x.size[1]test_eq(im.aspect, 30/20)@patch
def reshape(x: Image.Image, h, w, resample=0):
"`resize` `x` to `(w,h)`"
return x.resize((w,h), resample=resample)show_doc(Image.Image.reshape)Image.reshape
Image.reshape (x:PIL.Image.Image, h, w, resample=0)
resize x to (w,h)
test_eq(im.reshape(12,10).shape, (12,10))@patch
def to_bytes_format(im:Image.Image, format='png'):
"Convert to bytes, default to PNG format"
arr = io.BytesIO()
im.save(arr, format=format)
return arr.getvalue()show_doc(Image.Image.to_bytes_format)Image.to_bytes_format
Image.to_bytes_format (im:PIL.Image.Image, format='png')
Convert to bytes, default to PNG format
@patch
def to_thumb(self:Image.Image, h, w=None):
"Same as `thumbnail`, but uses a copy"
if w is None: w=h
im = self.copy()
im.thumbnail((w,h))
return imshow_doc(Image.Image.to_thumb)Image.to_thumb
Image.to_thumb (h, w=None)
Same as thumbnail, but uses a copy
@patch
def resize_max(x: Image.Image, resample=0, max_px=None, max_h=None, max_w=None):
"`resize` `x` to `max_px`, or `max_h`, or `max_w`"
h,w = x.shape
if max_px and x.n_px>max_px: h,w = fastuple(h,w).mul(math.sqrt(max_px/x.n_px))
if max_h and h>max_h: h,w = (max_h ,max_h*w/h)
if max_w and w>max_w: h,w = (max_w*h/w,max_w )
return x.reshape(round(h), round(w), resample=resample)test_eq(im.resize_max(max_px=20*30).shape, (20,30))
test_eq(im.resize_max(max_px=300).n_px, 294)
test_eq(im.resize_max(max_px=500, max_h=10, max_w=20).shape, (10,15))
test_eq(im.resize_max(max_h=14, max_w=15).shape, (10,15))
test_eq(im.resize_max(max_px=300, max_h=10, max_w=25).shape, (10,15))show_doc(Image.Image.resize_max)Image.resize_max
Image.resize_max (x:PIL.Image.Image, resample=0, max_px=None, max_h=None, max_w=None)
resize x to max_px, or max_h, or max_w
基本类型
本节归纳了计算机视觉中使用的基本类型以及创建这些类型对象的转换。
def to_image(x):
"Convert a tensor or array to a PIL int8 Image"
if isinstance(x,Image.Image): return x
if isinstance(x,Tensor): x = to_np(x.permute((1,2,0)))
if x.dtype==np.float32: x = (x*255).astype(np.uint8)
return Image.fromarray(x, mode=['RGB','CMYK'][x.shape[0]==4])def load_image(fn, mode=None):
"Open and load a `PIL.Image` and convert to `mode`"
im = Image.open(fn)
im.load()
im = im._new(im.im)
return im.convert(mode) if mode else imdef image2tensor(img):
"Transform image to byte tensor in `c*h*w` dim order."
res = tensor(img)
if res.dim()==2: res = res.unsqueeze(-1)
return res.permute(2,0,1)class PILBase(Image.Image, metaclass=BypassNewMeta):
"Base class for a Pillow `Image` that can show itself and convert to a Tensor"
_bypass_type=Image.Image
_show_args = {'cmap':'viridis'}
_open_args = {'mode': 'RGB'}
@classmethod
def create(cls, fn:Path|str|Tensor|ndarray|bytes|Image.Image, **kwargs):
"Return an Image from `fn`"
if isinstance(fn,TensorImage): fn = fn.permute(1,2,0).type(torch.uint8)
if isinstance(fn,TensorMask): fn = fn.type(torch.uint8)
if isinstance(fn,Tensor): fn = fn.numpy()
if isinstance(fn,ndarray): return cls(Image.fromarray(fn))
if isinstance(fn,bytes): fn = io.BytesIO(fn)
if isinstance(fn,Image.Image): return cls(fn)
return cls(load_image(fn, **merge(cls._open_args, kwargs)))
def show(self, ctx=None, **kwargs):
"Show image using `merge(self._show_args, kwargs)`"
return show_image(self, ctx=ctx, **merge(self._show_args, kwargs))
def __repr__(self): return f'{self.__class__.__name__} mode={self.mode} size={"x".join([str(d) for d in self.size])}'show_doc(PILBase.create)传递给 PILBase 或其继承类的 create 的图像,作为 PyTorch Tensor、NumPy ndarray 或 Pillow Image,必须已经是正确的 Pillow 图像格式。例如,对于 PILImage 或 PILImageBW,必须分别为 uint8、RGB 或 BW。
show_doc(PILBase.show)class PILImage(PILBase):
"A RGB Pillow `Image` that can show itself and converts to `TensorImage`"
passclass PILImageBW(PILImage):
"A BW Pillow `Image` that can show itself and converts to `TensorImageBW`"
_show_args,_open_args = {'cmap':'Greys'},{'mode': 'L'}im = PILImage.create(TEST_IMAGE)
test_eq(type(im), PILImage)
test_eq(im.mode, 'RGB')
test_eq(str(im), 'PILImage mode=RGB size=1200x803')im2 = PILImage.create(im)
test_eq(type(im2), PILImage)
test_eq(im2.mode, 'RGB')
test_eq(str(im2), 'PILImage mode=RGB size=1200x803')im.resize((64,64))
ax = im.show(figsize=(1,1))
test_fig_exists(ax)timg = TensorImage(image2tensor(im))
tpil = PILImage.create(timg)tpil.resize((64,64))
test_eq(np.array(im), np.array(tpil))class PILMask(PILBase):
"A Pillow `Image` Mask that can show itself and converts to `TensorMask`"
_open_args,_show_args = {'mode':'L'},{'alpha':0.5, 'cmap':'tab20'}im = PILMask.create(TEST_IMAGE)
test_eq(type(im), PILMask)
test_eq(im.mode, 'L')
test_eq(str(im), 'PILMask mode=L size=1200x803')OpenMask = Transform(PILMask.create)
OpenMask.loss_func = CrossEntropyLossFlat(axis=1)
PILMask.create = OpenMask图片
mnist = untar_data(URLs.MNIST_TINY)
fns = get_image_files(mnist)
mnist_fn = TEST_IMAGE_BWtimg = Transform(PILImageBW.create)
mnist_img = timg(mnist_fn)
test_eq(mnist_img.size, (28,28))
assert isinstance(mnist_img, PILImageBW)
mnist_img
分割掩膜
class AddMaskCodes(Transform):
"Add the code metadata to a `TensorMask`"
def __init__(self, codes=None):
self.codes = codes
if codes is not None: self.vocab,self.c = codes,len(codes)
def decodes(self, o:TensorMask):
if self.codes is not None: o.codes=self.codes
return ocamvid = untar_data(URLs.CAMVID_TINY)
fns = get_image_files(camvid/'images')
cam_fn = fns[0]
mask_fn = camvid/'labels'/f'{cam_fn.stem}_P{cam_fn.suffix}'cam_img = PILImage.create(cam_fn)
test_eq(cam_img.size, (128,96))
tmask = Transform(PILMask.create)
mask = tmask(mask_fn)
test_eq(type(mask), PILMask)
test_eq(mask.size, (128,96))_,axs = plt.subplots(1,3, figsize=(12,3))
cam_img.show(ctx=axs[0], title='image')
mask.show(alpha=1, ctx=axs[1], vmin=1, vmax=30, title='mask')
cam_img.show(ctx=axs[2], title='superimposed')
mask.show(ctx=axs[2], vmin=1, vmax=30);
要点
class TensorPoint(TensorBase):
"Basic type for points in an image"
_show_args = dict(s=10, marker='.', c='r')
@classmethod
def create(cls, t, img_size=None)->None:
"Convert an array or a list of points `t` to a `Tensor`"
return cls(tensor(t).view(-1, 2).float(), img_size=img_size)
def show(self, ctx=None, **kwargs):
if 'figsize' in kwargs: del kwargs['figsize']
x = self.view(-1,2)
ctx.scatter(x[:, 0], x[:, 1], **{**self._show_args, **kwargs})
return ctxTensorPointCreate = Transform(TensorPoint.create)
TensorPointCreate.loss_func = MSELossFlat()
TensorPoint.create = TensorPointCreate点应该以形状为 (n,2) 的数组/张量或包含两个元素的列表的形式出现。除非您更改 PointScaler 中的默认设置(稍后会提到),坐标应在 0 到宽度/高度之间,第一个是列索引(从 0 到宽度),第二个是行索引(从 0 到高度)。
Note
这与 numpy 或 PyTorch 中数组的通常索引约定不同,但这是 matplotlib 或 PyTorch 内部函数(如 F.grid_sample)对点的预期方式。
pnt_img = TensorImage(mnist_img.resize((28,35)))
pnts = np.array([[0,0], [0,35], [28,0], [28,35], [9, 17]])
tfm = Transform(TensorPoint.create)
tpnts = tfm(pnts)
test_eq(tpnts.shape, [5,2])
test_eq(tpnts.dtype, torch.float32)ctx = pnt_img.show(figsize=(1,1), cmap='Greys')
tpnts.show(ctx=ctx);
边界框
def get_annotations(fname, prefix=None):
"Open a COCO style json in `fname` and returns the lists of filenames (with maybe `prefix`) and labelled bboxes."
annot_dict = json.load(open(fname))
id2images, id2bboxes, id2cats = {}, collections.defaultdict(list), collections.defaultdict(list)
classes = {o['id']:o['name'] for o in annot_dict['categories']}
for o in annot_dict['annotations']:
bb = o['bbox']
id2bboxes[o['image_id']].append([bb[0],bb[1], bb[0]+bb[2], bb[1]+bb[3]])
id2cats[o['image_id']].append(classes[o['category_id']])
id2images = {o['id']:ifnone(prefix, '') + o['file_name'] for o in annot_dict['images'] if o['id'] in id2bboxes}
ids = list(id2images.keys())
return [id2images[k] for k in ids], [(id2bboxes[k], id2cats[k]) for k in ids]在coco_tiny数据集上测试get_annotations,对比图像文件名和边界框标签。
coco = untar_data(URLs.COCO_TINY)
test_images, test_lbl_bbox = get_annotations(coco/'train.json')
annotations = json.load(open(coco/'train.json'))
categories, images, annots = map(lambda x:L(x),annotations.values())
test_eq(test_images, images.attrgot('file_name'))
def bbox_lbls(file_name):
img = images.filter(lambda img:img['file_name']==file_name)[0]
bbs = annots.filter(lambda a:a['image_id'] == img['id'])
i2o = {k['id']:k['name'] for k in categories}
lbls = [i2o[cat] for cat in bbs.attrgot('category_id')]
bboxes = [[bb[0],bb[1], bb[0]+bb[2], bb[1]+bb[3]] for bb in bbs.attrgot('bbox')]
return [bboxes, lbls]
for idx in random.sample(range(len(images)),5):
test_eq(test_lbl_bbox[idx], bbox_lbls(test_images[idx]))from matplotlib import patches, patheffectsdef _draw_outline(o, lw):
o.set_path_effects([patheffects.Stroke(linewidth=lw, foreground='black'), patheffects.Normal()])
def _draw_rect(ax, b, color='white', text=None, text_size=14, hw=True, rev=False):
lx,ly,w,h = b
if rev: lx,ly,w,h = ly,lx,h,w
if not hw: w,h = w-lx,h-ly
patch = ax.add_patch(patches.Rectangle((lx,ly), w, h, fill=False, edgecolor=color, lw=2))
_draw_outline(patch, 4)
if text is not None:
patch = ax.text(lx,ly, text, verticalalignment='top', color=color, fontsize=text_size, weight='bold')
_draw_outline(patch,1)class TensorBBox(TensorPoint):
"Basic type for a tensor of bounding boxes in an image"
@classmethod
def create(cls, x, img_size=None)->None: return cls(tensor(x).view(-1, 4).float(), img_size=img_size)
def show(self, ctx=None, **kwargs):
x = self.view(-1,4)
for b in x: _draw_rect(ctx, b, hw=False, **kwargs)
return ctx边界框应该作为一个元组传递,格式为形状为 (n,4) 的数组/张量,或者作为包含四个元素的列表的列表及相应标签的列表。除非你在 PointScaler 中更改默认值(见后文),否则每个边界框的坐标应从 0 到宽度/高度,遵循以下约定:x1, y1, x2, y2,其中 (x1,y1) 是左上角,(x2,y2) 是右下角。
Note
我们使用与点相同的约定,x 从 0 到宽度,y 从 0 到高度。
class LabeledBBox(L):
"Basic type for a list of bounding boxes in an image"
def show(self, ctx=None, **kwargs):
for b,l in zip(self.bbox, self.lbl):
if l != '#na#': ctx = retain_type(b, self.bbox).show(ctx=ctx, text=l)
return ctx
bbox,lbl = add_props(lambda i,self: self[i])coco = untar_data(URLs.COCO_TINY)
images, lbl_bbox = get_annotations(coco/'train.json')
idx=2
coco_fn,bbox = coco/'train'/images[idx],lbl_bbox[idx]
coco_img = timg(coco_fn)tbbox = LabeledBBox(TensorBBox(bbox[0]), bbox[1])
ctx = coco_img.show(figsize=(3,3), cmap='Greys')
tbbox.show(ctx=ctx);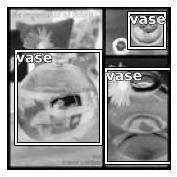
基本变换
除非特别提到,以下所有转换都可以作为单项转换(在您传递给TfmdDS或Datasource的tfms列表中的一个)或元组转换(在您传递给TfmdDS或Datasource的tuple_tfms中)使用。最安全且在所有应用中都能正常工作的方式是始终将它们作为tuple_tfms使用。例如,如果您将点或边界框作为目标,并使用Resize作为单项转换,当您到达PointScaler(它是一个元组转换)时,您将没有图像的正确大小,从而无法正确缩放您的点。
PILImage ._tensor_cls = TensorImage
PILImageBW._tensor_cls = TensorImageBW
PILMask ._tensor_cls = TensorMask@ToTensor
def encodes(self, o:PILBase): return o._tensor_cls(image2tensor(o))
@ToTensor
def encodes(self, o:PILMask): return o._tensor_cls(image2tensor(o)[0])在此变换之前,必须先运行所有在PIL图像上进行的数据增强变换。
tfm = ToTensor()
print(tfm)
print(type(mnist_img))
print(type(tfm(mnist_img)))ToTensor:
encodes: (PILMask,object) -> encodes
(PILBase,object) -> encodes
(PILMask,object) -> encodes
(PILBase,object) -> encodes
decodes:
<class '__main__.PILImageBW'>
<class 'fastai.torch_core.TensorImageBW'>tfm = ToTensor()
test_eq(tfm(mnist_img).shape, (1,28,28))
test_eq(type(tfm(mnist_img)), TensorImageBW)
test_eq(tfm(mask).shape, (96,128))
test_eq(type(tfm(mask)), TensorMask)让我们确认我们可以通过PILImage.create进行管道处理。
pipe_img = Pipeline([PILImageBW.create, ToTensor()])
img = pipe_img(mnist_fn)
test_eq(type(img), TensorImageBW)
pipe_img.show(img, figsize=(1,1));
def _cam_lbl(x): return mask_fn
cam_tds = Datasets([cam_fn], [[PILImage.create, ToTensor()], [_cam_lbl, PILMask.create, ToTensor()]])
show_at(cam_tds, 0);
为了进行数据增强,特别是 grid_sample 方法,点需要用坐标从 -1 到 1 表示(-1 为顶部或左侧,1 为底部或右侧),除非您传递 do_scale=False。我们还需要确保它们遵循我们的点的 x,y 坐标约定,因此如果您的数据是 y,x 格式,请传递 y_first=True 来添加翻转。
Warning
该变换需要在元组级别运行,在任何改变图像大小的变换之前。
def _scale_pnts(y, sz, do_scale=True, y_first=False):
if y_first: y = y.flip(1)
res = y * 2/tensor(sz).float() - 1 if do_scale else y
return TensorPoint(res, img_size=sz)
def _unscale_pnts(y, sz): return TensorPoint((y+1) * tensor(sz).float()/2, img_size=sz)class PointScaler(Transform):
"Scale a tensor representing points"
order = 1
def __init__(self, do_scale=True, y_first=False): self.do_scale,self.y_first = do_scale,y_first
def _grab_sz(self, x):
self.sz = [x.shape[-1], x.shape[-2]] if isinstance(x, Tensor) else x.size
return x
def _get_sz(self, x): return getattr(x, 'img_size') if self.sz is None else self.sz
def setups(self, dl):
res = first(dl.do_item(None), risinstance(TensorPoint))
if res is not None: self.c = res.numel()
def encodes(self, x:PILBase|TensorImageBase): return self._grab_sz(x)
def decodes(self, x:PILBase|TensorImageBase): return self._grab_sz(x)
def encodes(self, x:TensorPoint): return _scale_pnts(x, self._get_sz(x), self.do_scale, self.y_first)
def decodes(self, x:TensorPoint): return _unscale_pnts(x.view(-1, 2), self._get_sz(x))为了进行数据增强,特别是grid_sample方法,点需要用坐标表示,范围从-1到1(-1表示顶部或左侧,1表示底部或右侧),除非你传递do_scale=False。我们还需要确保它们遵循我们的点是x,y坐标的约定,因此如果你的数据是y,x格式,请传递y_first=True以添加翻转。
Note
该变换会自动抓取它看到的图像的大小,并将其嵌入到一个TensorPoint对象中。为了使其生效,这些图像需要在最终元组中任何点之前。如果没有这样的图像,创建TensorPoint时需要通过传递sz=...来嵌入相应图像的大小。
def _pnt_lbl(x): return TensorPoint.create(pnts)
def _pnt_open(fn): return PILImage(PILImage.create(fn).resize((28,35)))
pnt_tds = Datasets([mnist_fn], [_pnt_open, [_pnt_lbl]])
pnt_tdl = TfmdDL(pnt_tds, bs=1, after_item=[PointScaler(), ToTensor()])test_eq(pnt_tdl.after_item.c, 10)#检查PointScaler是否抓取了尺寸并将其添加到y中
tfm = PointScaler()
tfm.as_item=False
x,y = tfm(pnt_tds[0])
test_eq(tfm.sz, x.size)
test_eq(y.img_size, x.size)x,y = pnt_tdl.one_batch()
#正确缩放和翻转
#注意:我们之前在(9,17)处添加了一个点;下面的公式将其缩放到(-1,1)坐标系中
test_close(y[0], tensor([[-1., -1.], [-1., 1.], [1., -1.], [1., 1.], [9/14-1, 17/17.5-1]]))
a,b = pnt_tdl.decode_batch((x,y))[0]
test_eq(b, tensor(pnts).float())
#检查类型
test_eq(type(x), TensorImage)
test_eq(type(y), TensorPoint)
test_eq(type(a), TensorImage)
test_eq(type(b), TensorPoint)
test_eq(b.img_size, (28,35)) #自动选择输入的大小pnt_tdl.show_batch(figsize=(2,2), cmap='Greys');
class BBoxLabeler(Transform):
def setups(self, dl): self.vocab = dl.vocab
def decode (self, x, **kwargs):
self.bbox,self.lbls = None,None
return self._call('decodes', x, **kwargs)
def decodes(self, x:TensorMultiCategory):
self.lbls = [self.vocab[a] for a in x]
return x if self.bbox is None else LabeledBBox(self.bbox, self.lbls)
def decodes(self, x:TensorBBox):
self.bbox = x
return self.bbox if self.lbls is None else LabeledBBox(self.bbox, self.lbls)#LabeledBBox 可以在 tl 中与 MultiCategorize 一起发送(取决于 tls 的顺序),但它已经解码。
@MultiCategorize
def decodes(self, x:LabeledBBox): return x@PointScaler
def encodes(self, x:TensorBBox):
pnts = self.encodes(cast(x.view(-1,2), TensorPoint))
return cast(pnts.view(-1, 4), TensorBBox)
@PointScaler
def decodes(self, x:TensorBBox):
pnts = self.decodes(cast(x.view(-1,2), TensorPoint))
return cast(pnts.view(-1, 4), TensorBBox)def _coco_bb(x): return TensorBBox.create(bbox[0])
def _coco_lbl(x): return bbox[1]
coco_tds = Datasets([coco_fn], [PILImage.create, [_coco_bb], [_coco_lbl, MultiCategorize(add_na=True)]], n_inp=1)
coco_tdl = TfmdDL(coco_tds, bs=1, after_item=[BBoxLabeler(), PointScaler(), ToTensor()])#检查PointScaler是否抓取了尺寸并将其添加到y中
tfm = PointScaler()
tfm.as_item=False
x,y,z = tfm(coco_tds[0])
test_eq(tfm.sz, x.size)
test_eq(y.img_size, x.size)Categorize(add_na=True)Categorize -- {'vocab': None, 'sort': True, 'add_na': True}:
encodes: (object,object) -> encodes
decodes: (object,object) -> decodescoco_tds.tfms(#3) [Pipeline: PILBase.create,Pipeline: _coco_bb,Pipeline: _coco_lbl -> MultiCategorize -- {'vocab': None, 'sort': True, 'add_na': True}]x,y,z(PILImage mode=RGB size=128x128,
TensorBBox([[-0.9011, -0.4606, 0.1416, 0.6764],
[ 0.2000, -0.2405, 1.0000, 0.9102],
[ 0.4909, -0.9325, 0.9284, -0.5011]]),
TensorMultiCategory([1, 1, 1]))x,y,z = coco_tdl.one_batch()
test_close(y[0], -1+tensor(bbox[0])/64)
test_eq(z[0], tensor([1,1,1]))
a,b,c = coco_tdl.decode_batch((x,y,z))[0]
test_close(b, tensor(bbox[0]).float())
test_eq(c.bbox, b)
test_eq(c.lbl, bbox[1])
#检查类型
test_eq(type(x), TensorImage)
test_eq(type(y), TensorBBox)
test_eq(type(z), TensorMultiCategory)
test_eq(type(a), TensorImage)
test_eq(type(b), TensorBBox)
test_eq(type(c), LabeledBBox)
test_eq(y.img_size, (128,128))coco_tdl.show_batch();
#测试其他方向也有效
coco_tds = Datasets([coco_fn], [PILImage.create, [_coco_lbl, MultiCategorize(add_na=True)], [_coco_bb]])
coco_tdl = TfmdDL(coco_tds, bs=1, after_item=[BBoxLabeler(), PointScaler(), ToTensor()])
x,y,z = coco_tdl.one_batch()
test_close(z[0], -1+tensor(bbox[0])/64)
test_eq(y[0], tensor([1,1,1]))
a,b,c = coco_tdl.decode_batch((x,y,z))[0]
test_eq(b, bbox[1])
test_close(c.bbox, tensor(bbox[0]).float())
test_eq(c.lbl, b)
#检查类型
test_eq(type(x), TensorImage)
test_eq(type(y), TensorMultiCategory)
test_eq(type(z), TensorBBox)
test_eq(type(a), TensorImage)
test_eq(type(b), MultiCategory)
test_eq(type(c), LabeledBBox)
test_eq(z.img_size, (128,128))导出 -
from nbdev import nbdev_export
nbdev_export()