! [ -e /content ] && pip install -Uqq fastai # 在Colab上升级fastai超参数调度
from __future__ import annotations
from fastai.basics import *
from fastai.callback.tracker import SaveModelCallback_all_ = ['SuggestionMethod']from nbdev.showdoc import *回调和辅助函数,用于调度任何超参数
from fastai.test_utils import *退火
class _Annealer:
def __init__(self, f, start, end): store_attr('f,start,end')
def __call__(self, pos): return self.f(self.start, self.end, pos)def annealer(f):
"Decorator to make `f` return itself partially applied."
@functools.wraps(f)
def _inner(start, end): return _Annealer(f, start, end)
return _inner这是我们将用于所有调度函数的装饰器,因为它将一个接受 (start, end, pos) 的函数转换为一个接受 (start, end) 的函数,并返回一个依赖于 pos 的函数。
#待办事项 杰里米,把这个腌黄瓜做好
#@退火器
#def 线性调度(起点, 终点, 位置): 返回 起点 + 位置*(终点-起点)
#@退火器
#def SchedCos(start, end, pos): return start + (1 + math.cos(math.pi*(1-pos))) * (end-start) / 2
#@退火器
#def 调度无 (开始, 结束, 位置): 返回 开始
#@退火器
#def SchedExp(start, end, pos): return start * (end/start) ** pos
#
#SchedLin.__doc__ = "Linear schedule function from `start` to `end`"
#SchedCos.__doc__ = "Cosine schedule function from `start` to `end`"
#SchedNo .__doc__ = "Constant schedule function with `start` value"
#SchedExp.__doc__ = "Exponential schedule function from `start` to `end`"def sched_lin(start, end, pos): return start + pos*(end-start)
def sched_cos(start, end, pos): return start + (1 + math.cos(math.pi*(1-pos))) * (end-start) / 2
def sched_no (start, end, pos): return start
def sched_exp(start, end, pos): return start * (end/start) ** pos
def SchedLin(start, end): return _Annealer(sched_lin, start, end)
def SchedCos(start, end): return _Annealer(sched_cos, start, end)
def SchedNo (start, end): return _Annealer(sched_no, start, end)
def SchedExp(start, end): return _Annealer(sched_exp, start, end)
SchedLin.__doc__ = "Linear schedule function from `start` to `end`"
SchedCos.__doc__ = "Cosine schedule function from `start` to `end`"
SchedNo .__doc__ = "Constant schedule function with `start` value"
SchedExp.__doc__ = "Exponential schedule function from `start` to `end`"tst = pickle.dumps(SchedCos(0, 5))annealings = "NO LINEAR COS EXP".split()
p = torch.linspace(0.,1,100)
fns = [SchedNo, SchedLin, SchedCos, SchedExp]def SchedPoly(start, end, power):
"Polynomial schedule (of `power`) function from `start` to `end`"
def _inner(pos): return start + (end - start) * pos ** power
return _innerfor fn, t in zip(fns, annealings):
plt.plot(p, [fn(2, 1e-2)(o) for o in p], label=t)
f = SchedPoly(2,1e-2,0.5)
plt.plot(p, [f(o) for o in p], label="POLY(0.5)")
plt.legend();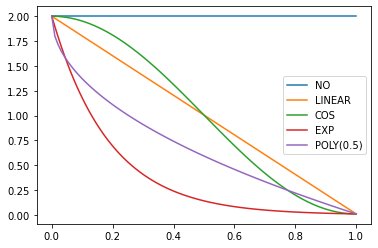
show_doc(SchedLin)sched = SchedLin(0, 2)
test_eq(L(map(sched, [0., 0.25, 0.5, 0.75, 1.])), [0., 0.5, 1., 1.5, 2.])show_doc(SchedCos)sched = SchedCos(0, 2)
test_close(L(map(sched, [0., 0.25, 0.5, 0.75, 1.])), [0., 0.29289, 1., 1.70711, 2.])show_doc(SchedNo)sched = SchedNo(0, 2)
test_close(L(map(sched, [0., 0.25, 0.5, 0.75, 1.])), [0., 0., 0., 0., 0.])show_doc(SchedExp)sched = SchedExp(1, 2)
test_close(L(map(sched, [0., 0.25, 0.5, 0.75, 1.])), [1., 1.18921, 1.41421, 1.68179, 2.])show_doc(SchedPoly)
SchedPoly[source]
SchedPoly(start,end,power)
Polynomial schedule (of power) function from start to end
sched = SchedPoly(0, 2, 2)
test_close(L(map(sched, [0., 0.25, 0.5, 0.75, 1.])), [0., 0.125, 0.5, 1.125, 2.])p = torch.linspace(0.,1,100)
pows = [0.5,1.,2.]
for e in pows:
f = SchedPoly(2, 0, e)
plt.plot(p, [f(o) for o in p], label=f'power {e}')
plt.legend();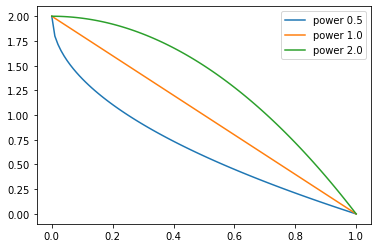
def combine_scheds(pcts, scheds):
"Combine `scheds` according to `pcts` in one function"
assert sum(pcts) == 1.
pcts = tensor([0] + L(pcts))
assert torch.all(pcts >= 0)
pcts = torch.cumsum(pcts, 0)
pct_lim = len(pcts) - 2
def _inner(pos):
idx = min((pos >= pcts).nonzero().max(), pct_lim)
actual_pos = (pos-pcts[idx]) / (pcts[idx+1]-pcts[idx])
return scheds[idx](actual_pos.item())
return _innerpcts 必须是一个正数列表,且所有元素之和为1,且长度与 scheds 相同。生成的函数将使用 scheds[0] 从 0 到 pcts[0],然后使用 scheds[1] 从 pcts[0] 到 pcts[0]+pcts[1],依此类推。
p = torch.linspace(0.,1,100)
f = combine_scheds([0.3,0.7], [SchedCos(0.3,0.6), SchedCos(0.6,0.2)])
plt.plot(p, [f(o) for o in p]);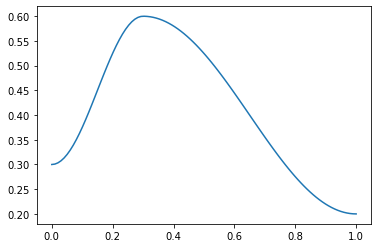
p = torch.linspace(0.,1,100)
f = combine_scheds([0.3,0.2,0.5], [SchedLin(0.,1.), SchedNo(1.,1.), SchedCos(1., 0.)])
plt.plot(p, [f(o) for o in p]);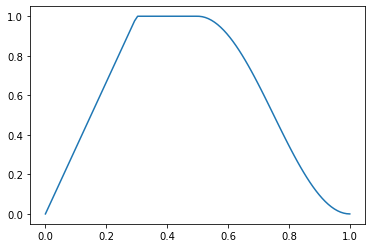
test_close([f(0.), f(0.15), f(0.3), f(0.4), f(0.5), f(0.7), f(1.)],
[0., 0.5, 1., 1., 1., 0.65451, 0.])def combined_cos(pct, start, middle, end):
"Return a scheduler with cosine annealing from `start`→`middle` & `middle`→`end`"
return combine_scheds([pct,1-pct], [SchedCos(start, middle), SchedCos(middle, end)])这是一个用于 1cycle 策略 的有用辅助函数。pct 用于 开始 到 中间 部分,1-pct 用于 中间 到 结束。处理浮点数或浮点数集合。例如:
f = combined_cos(0.25,0.5,1.,0.)
plt.plot(p, [f(o) for o in p]);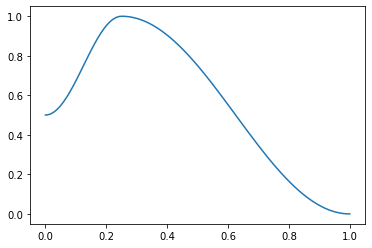
test_close([f(0.), f(0.1), f(0.25), f(0.5), f(1.)], [0.5, 0.67275, 1., 0.75, 0.])
f = combined_cos(0.25, np.array([0.25,0.5]), np.array([0.5,1.]), np.array([0.,0.]))
for a,b in zip([f(0.), f(0.1), f(0.25), f(0.5), f(1.)],
[[0.25,0.5], [0.33638,0.67275], [0.5,1.], [0.375,0.75], [0.,0.]]):
test_close(a,b)参数调度器 -
@docs
class ParamScheduler(Callback):
"Schedule hyper-parameters according to `scheds`"
order,run_valid = 60,False
def __init__(self, scheds): self.scheds = scheds
def before_fit(self): self.hps = {p:[] for p in self.scheds.keys()}
def before_batch(self): self._update_val(self.pct_train)
def _update_val(self, pct):
for n,f in self.scheds.items(): self.opt.set_hyper(n, f(pct))
def after_batch(self):
for p in self.scheds.keys(): self.hps[p].append(self.opt.hypers[-1][p])
def after_fit(self):
if hasattr(self.learn, 'recorder') and hasattr(self, 'hps'): self.recorder.hps = self.hps
_docs = {"before_fit": "Initialize container for hyper-parameters",
"before_batch": "Set the proper hyper-parameters in the optimizer",
"after_batch": "Record hyper-parameters of this batch",
"after_fit": "Save the hyper-parameters in the recorder if there is one"}scheds是一个字典,其中每个超参数都有一个键,值可以是调度器或调度器列表(在第二种情况下,列表的长度必须与优化器参数组的数量相同)。
learn = synth_learner()
sched = {'lr': SchedLin(1e-3, 1e-2)}
learn.fit(1, cbs=ParamScheduler(sched))
n = len(learn.dls.train)
test_close(learn.recorder.hps['lr'], [1e-3 + (1e-2-1e-3) * i/n for i in range(n)])| epoch | train_loss | valid_loss | time |
|---|---|---|---|
| 0 | 11.929138 | 4.039281 | 00:00 |
#测试判别学习率
def _splitter(m): return [[m.a], [m.b]]
learn = synth_learner(splitter=_splitter)
sched = {'lr': combined_cos(0.5, np.array([1e-4,1e-3]), np.array([1e-3,1e-2]), np.array([1e-5,1e-4]))}
learn.fit(1, cbs=ParamScheduler(sched))| epoch | train_loss | valid_loss | time |
|---|---|---|---|
| 0 | 21.979218 | 21.261951 | 00:00 |
show_doc(ParamScheduler.before_fit)
ParamScheduler.before_fit[source]
ParamScheduler.before_fit()
Initialize container for hyper-parameters
show_doc(ParamScheduler.before_batch)
ParamScheduler.before_batch[source]
ParamScheduler.before_batch()
Set the proper hyper-parameters in the optimizer
show_doc(ParamScheduler.after_batch)
ParamScheduler.after_batch[source]
ParamScheduler.after_batch()
Record hyper-parameters of this batch
show_doc(ParamScheduler.after_fit)
ParamScheduler.after_fit[source]
ParamScheduler.after_fit()
Save the hyper-parameters in the recorder if there is one
@patch
def fit_one_cycle(self:Learner, n_epoch, lr_max=None, div=25., div_final=1e5, pct_start=0.25, wd=None,
moms=None, cbs=None, reset_opt=False, start_epoch=0):
"Fit `self.model` for `n_epoch` using the 1cycle policy."
if self.opt is None: self.create_opt()
self.opt.set_hyper('lr', self.lr if lr_max is None else lr_max)
lr_max = np.array([h['lr'] for h in self.opt.hypers])
scheds = {'lr': combined_cos(pct_start, lr_max/div, lr_max, lr_max/div_final),
'mom': combined_cos(pct_start, *(self.moms if moms is None else moms))}
self.fit(n_epoch, cbs=ParamScheduler(scheds)+L(cbs), reset_opt=reset_opt, wd=wd, start_epoch=start_epoch)1cycle策略是由Leslie N. Smith等人提出的,详细内容见Super-Convergence: Very Fast Training of Neural Networks Using Large Learning Rates。该策略通过余弦退火调度学习率,从lr_max/div减小到lr_max,然后再减小到lr_max/div_final(如果想使用不同的学习率,可以向lr_max传递一个数组),同时根据moms中的值使用余弦退火调度动量。第一阶段占用训练的pct_start。您可以选择性地传递额外的cbs和reset_opt。
#集成测试:训练几个周期应使模型性能提升
learn = synth_learner(lr=1e-2)
xb,yb = learn.dls.one_batch()
init_loss = learn.loss_func(learn.model(xb), yb)
learn.fit_one_cycle(2)
xb,yb = learn.dls.one_batch()
final_loss = learn.loss_func(learn.model(xb), yb)
assert final_loss < init_loss| epoch | train_loss | valid_loss | time |
|---|---|---|---|
| 0 | 19.444899 | 6.755066 | 00:00 |
| 1 | 9.919473 | 1.044571 | 00:00 |
#调度器测试
lrs,moms = learn.recorder.hps['lr'],learn.recorder.hps['mom']
test_close(lrs, [combined_cos(0.25,1e-2/25,1e-2,1e-7)(i/20) for i in range(20)])
test_close(moms, [combined_cos(0.25,0.95,0.85,0.95)(i/20) for i in range(20)])@patch
def plot_sched(self:Recorder, keys=None, figsize=None):
keys = self.hps.keys() if keys is None else L(keys)
rows,cols = (len(keys)+1)//2, min(2, len(keys))
figsize = figsize or (6*cols,4*rows)
_, axs = plt.subplots(rows, cols, figsize=figsize)
axs = axs.flatten() if len(keys) > 1 else L(axs)
for p,ax in zip(keys, axs):
ax.plot(self.hps[p])
ax.set_ylabel(p)#测试判别学习率
def _splitter(m): return [[m.a], [m.b]]
learn = synth_learner(splitter=_splitter)
learn.fit_one_cycle(1, lr_max=slice(1e-3,1e-2))
#n = len(learn.dls.train)
#est_close(learn.recorder.hps['lr'], [1e-3 + (1e-2-1e-3) * i/n for i in range(n)])| epoch | train_loss | valid_loss | time |
|---|---|---|---|
| 0 | 17.738113 | 21.716423 | 00:00 |
learn = synth_learner()
learn.fit_one_cycle(2)| epoch | train_loss | valid_loss | time |
|---|---|---|---|
| 0 | 5.406837 | 5.305011 | 00:00 |
| 1 | 5.058437 | 4.899223 | 00:00 |
learn.recorder.plot_sched()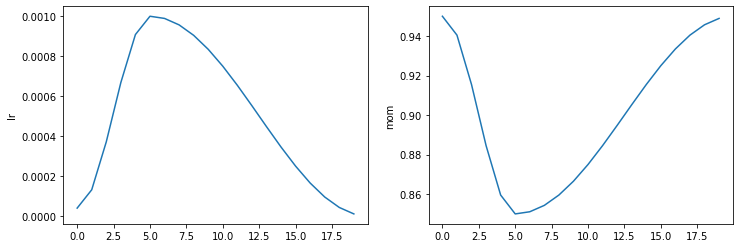
@patch
def fit_flat_cos(self:Learner, n_epoch, lr=None, div_final=1e5, pct_start=0.75, wd=None,
cbs=None, reset_opt=False, start_epoch=0):
"Fit `self.model` for `n_epoch` at flat `lr` before a cosine annealing."
if self.opt is None: self.create_opt()
self.opt.set_hyper('lr', self.lr if lr is None else lr)
lr = np.array([h['lr'] for h in self.opt.hypers])
scheds = {'lr': combined_cos(pct_start, lr, lr, lr/div_final)}
self.fit(n_epoch, cbs=ParamScheduler(scheds)+L(cbs), reset_opt=reset_opt, wd=wd, start_epoch=0)learn = synth_learner()
learn.fit_flat_cos(2)| epoch | train_loss | valid_loss | time |
|---|---|---|---|
| 0 | 10.588930 | 7.106113 | 00:00 |
| 1 | 8.943380 | 5.016665 | 00:00 |
learn.recorder.plot_sched()
@patch
def fit_sgdr(self:Learner, n_cycles, cycle_len, lr_max=None, cycle_mult=2, cbs=None, reset_opt=False, wd=None,
start_epoch=0):
"Fit `self.model` for `n_cycles` of `cycle_len` using SGDR."
if self.opt is None: self.create_opt()
self.opt.set_hyper('lr', self.lr if lr_max is None else lr_max)
lr_max = np.array([h['lr'] for h in self.opt.hypers])
n_epoch = cycle_len * (cycle_mult**n_cycles-1)//(cycle_mult-1)
pcts = [cycle_len * cycle_mult**i / n_epoch for i in range(n_cycles)]
scheds = [SchedCos(lr_max, 0) for _ in range(n_cycles)]
scheds = {'lr': combine_scheds(pcts, scheds)}
self.fit(n_epoch, cbs=ParamScheduler(scheds)+L(cbs), reset_opt=reset_opt, wd=wd, start_epoch=start_epoch)这个调度由 Ilya Loshchilov 等人在 SGDR: 带热重启的随机梯度下降 中提出。它由 n_cycles 组成,这些周期是从 lr_max(默认为 Learner 的学习率)到 0 的余弦退火,第 i 个周期的长度为 cycle_len * cycle_mult**i(第一个周期长度为 cycle_len,然后我们在每个 epoch 中将长度乘以 cycle_mult)。您可以选择性地传递其他 cbs 和 reset_opt。
::: {#cell-60 .cell 0=‘缓’ 1=‘慢’}
learn = synth_learner()
with learn.no_logging(): learn.fit_sgdr(3, 1)
test_eq(learn.n_epoch, 7)
iters = [k * len(learn.dls.train) for k in [0,1,3,7]]
for i in range(3):
n = iters[i+1]-iters[i]
#周期的开始可能与前一周期的0因舍入误差而混淆,因此我们在+1处进行测试
test_close(learn.recorder.lrs[iters[i]+1:iters[i+1]], [SchedCos(learn.lr, 0)(k/n) for k in range(1,n)])
learn.recorder.plot_sched()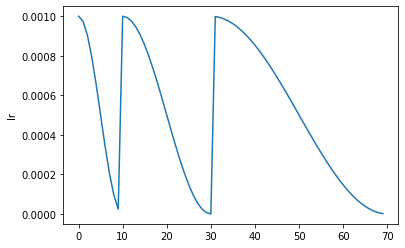
:::
@patch
@delegates(Learner.fit_one_cycle)
def fine_tune(self:Learner, epochs, base_lr=2e-3, freeze_epochs=1, lr_mult=100,
pct_start=0.3, div=5.0, **kwargs):
"Fine tune with `Learner.freeze` for `freeze_epochs`, then with `Learner.unfreeze` for `epochs`, using discriminative LR."
self.freeze()
self.fit_one_cycle(freeze_epochs, slice(base_lr), pct_start=0.99, **kwargs)
base_lr /= 2
self.unfreeze()
self.fit_one_cycle(epochs, slice(base_lr/lr_mult, base_lr), pct_start=pct_start, div=div, **kwargs)learn.fine_tune(1)| epoch | train_loss | valid_loss | time |
|---|---|---|---|
| 0 | 2.428970 | 1.740237 | 00:00 |
| epoch | train_loss | valid_loss | time |
|---|---|---|---|
| 0 | 2.019952 | 1.616970 | 00:00 |
从检查点恢复训练
class InterruptCallback(Callback):
def __init__(self, epoch):
self._interupt_before = epoch
def before_epoch(self):
if self.epoch == self._interupt_before:
raise CancelFitException要启用从检查点恢复,请确保保存模型和优化器的状态。这可以通过设置 SaveModelCallback 的 (with_opt=True) 来完成。如果训练中断,请使用与之前相同的参数定义 learn,从检查点加载模型,并将 start_epoch 传递给 fit 调用。训练将从 start_epoch 继续,并正确安排 lr。
::: {#cell-66 .cell 0=‘缓’ 1=‘慢’}
with tempfile.TemporaryDirectory() as d:
learn1 = synth_learner(path=d, cbs=SaveModelCallback(with_opt=True, fname="ckpt"))
learn1.fit_one_cycle(5, cbs=InterruptCallback(2))
learn2 = synth_learner(path=d)
learn2 = learn2.load("ckpt")
learn2.fit_one_cycle(5, start_epoch=2)
fig, axs = plt.subplots(1,2, sharey=True)
axs[0].plot(learn1.recorder.lrs)
axs[1].plot(learn2.recorder.lrs)| epoch | train_loss | valid_loss | time |
|---|---|---|---|
| 0 | 18.930223 | 14.100439 | 00:00 |
| 1 | 17.092665 | 10.603369 | 00:00 |
Better model found at epoch 0 with valid_loss value: 14.100439071655273.
Better model found at epoch 1 with valid_loss value: 10.603368759155273.| epoch | train_loss | valid_loss | time |
|---|---|---|---|
| 0 | 00:00 | ||
| 1 | 00:00 | ||
| 2 | 11.456764 | 10.057186 | 00:00 |
| 3 | 10.287196 | 8.694046 | 00:00 |
| 4 | 9.585465 | 8.422710 | 00:00 |
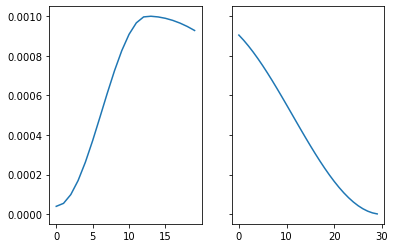
:::
LRFind -
@docs
class LRFinder(ParamScheduler):
"Training with exponentially growing learning rate"
def __init__(self, start_lr=1e-7, end_lr=10, num_it=100, stop_div=True):
if num_it < 6: num_it = 6
self.scheds = {'lr': [SchedExp(s, e) for (s,e) in zip(start_lr,end_lr)
] if is_listy(start_lr) else SchedExp(start_lr, end_lr)}
self.num_it,self.stop_div = num_it,stop_div
def before_fit(self):
super().before_fit()
path = self.path/self.model_dir
path.mkdir(parents=True, exist_ok=True)
self.tmp_d = tempfile.TemporaryDirectory(dir=path)
self.tmp_p = Path(self.tmp_d.name).stem
self.learn.save(f'{self.tmp_p}/_tmp')
self.best_loss = float('inf')
def before_batch(self): self._update_val(self.train_iter/self.num_it)
def after_batch(self):
super().after_batch()
if self.smooth_loss < self.best_loss: self.best_loss = self.smooth_loss
if self.smooth_loss > 4*self.best_loss and self.stop_div: raise CancelFitException()
if self.train_iter >= self.num_it: raise CancelFitException()
def before_validate(self): raise CancelValidException()
def after_fit(self):
self.learn.opt.zero_grad() # 在分离优化器以供未来拟合之前需要完成的事项
tmp_f = self.path/self.model_dir/self.tmp_p/'_tmp.pth'
if tmp_f.exists():
self.learn.load(f'{self.tmp_p}/_tmp', with_opt=True)
self.tmp_d.cleanup()
_docs = {"before_fit": "Initialize container for hyper-parameters and save the model",
"before_batch": "Set the proper hyper-parameters in the optimizer",
"after_batch": "Record hyper-parameters of this batch and potentially stop training",
"after_fit": "Save the hyper-parameters in the recorder if there is one and load the original model",
"before_validate": "Skip the validation part of training"}::: {#cell-69 .cell 0=‘c’ 1=‘u’ 2=‘d’ 3=‘a’}
from fastai.vision.all import *:::
::: {#cell-70 .cell 0=‘c’ 1=‘u’ 2=‘d’ 3=‘a’}
set_seed(99, True)
path = untar_data(URLs.PETS)/'images'
image_files = get_image_files(path)
if sys.platform == "win32" and IN_NOTEBOOK:
image_files = random.choices(image_files, k=int(len(image_files)/8))
print("Randomly select 1/8 files in NOTEBOOK on Windows to save time")
# pickle can't serializer lamda function.
def _label_func(x):
return x[0].isupper()
dls = ImageDataLoaders.from_name_func(
path, image_files, valid_pct=0.2,
label_func=_label_func, item_tfms=Resize(224))
learn = vision_learner(dls, resnet18)
learn.fit(1)
learn.opt.state_dict()['state'][1]['grad_avg']| epoch | train_loss | valid_loss | time |
|---|---|---|---|
| 0 | 0.086690 | 0.016682 | 00:33 |
tensor([-5.8191e-04, -2.2443e-03, 0.0000e+00, -1.2517e-03, 0.0000e+00,
-1.4744e-03, -3.6433e-04, 0.0000e+00, 9.3745e-03, 0.0000e+00,
5.1993e-03, -1.5093e-02, -4.0410e-03, 0.0000e+00, 7.1963e-03,
-6.6033e-03, -3.3354e-03, -2.9191e-03, -1.5054e-03, -1.3179e-03,
8.7333e-03, -1.1155e-02, -9.6656e-04, 1.6653e-02, 9.5839e-04,
8.4995e-03, -2.8187e-02, 3.1579e-03, -9.3051e-04, -2.3887e-03,
-7.3557e-04, -1.4501e-02, -6.2110e-03, 1.9949e-03, -7.0233e-03,
1.2792e-02, 0.0000e+00, 1.0687e-03, 0.0000e+00, -4.2413e-04,
2.9628e-03, 7.2686e-03, -9.7241e-03, -4.9941e-04, 1.7408e-02,
-9.2441e-03, -9.7731e-03, -9.9393e-03, 0.0000e+00, -2.1448e-03,
2.7660e-03, -3.1110e-03, 5.9454e-05, -1.4412e-03, -6.1454e-04,
-1.6537e-03, 1.7001e-02, 1.4041e-02, -6.2878e-03, 2.0800e-02,
-1.2900e-02, -1.2626e-02, -2.6591e-03, 3.9685e-03], device='cuda:0'):::
::: {#cell-71 .cell 0=‘缓’ 1=‘慢’}
with tempfile.TemporaryDirectory() as d:
learn = synth_learner(path=Path(d))
init_a,init_b = learn.model.a,learn.model.b
with learn.no_logging(): learn.fit(20, cbs=LRFinder(num_it=100))
assert len(learn.recorder.lrs) <= 100
test_eq(len(learn.recorder.lrs), len(learn.recorder.losses))
#检查是否发散
if len(learn.recorder.lrs) < 100: assert learn.recorder.losses[-1] > 4 * min(learn.recorder.losses)
#测试计划
test_eq(learn.recorder.lrs, [SchedExp(1e-7, 10)(i/100) for i in range_of(learn.recorder.lrs)])
#无验证数据
test_eq([len(v) for v in learn.recorder.values], [1 for _ in range_of(learn.recorder.values)])
#模型已正确加载
test_eq(learn.model.a, init_a)
test_eq(learn.model.b, init_b)
test_eq(learn.opt.state_dict()['state'], [{}, {}]):::
show_doc(LRFinder.before_fit)
LRFinder.before_fit[source]
LRFinder.before_fit()
Initialize container for hyper-parameters and save the model
show_doc(LRFinder.before_batch)
LRFinder.before_batch[source]
LRFinder.before_batch()
Set the proper hyper-parameters in the optimizer
show_doc(LRFinder.after_batch)
LRFinder.after_batch[source]
LRFinder.after_batch()
Record hyper-parameters of this batch and potentially stop training
show_doc(LRFinder.before_validate)建议方法
有几种方法可以自动建议学习率,正如我们将看到的,这些方法可以进一步传递给 lr_find。当前支持四种方法,然而,如果要编写自己的方法,它应该看起来像一个可以接受 LRFinder 返回的 lrs、losses 以及 num_it 的函数。 你的函数应该返回一个可以绘制的 x,y 坐标,如下所示:
def myfunc(lrs:list, losses:list, num_it:int) -> tuple(float, tuple(float,int)):
...
return suggestion, (suggestion,loss_idx)如果需要传递更多参数,你应该将你的 func 作为部分函数传入,并自行指定,例如:
def myfunc(lrs:list, losses:list, num_it:int, pct_reduction:float) -> tuple(float, tuple(float,int)):
...
return suggestion, (suggestion,loss_idx)f = partial(myfunc, pct_reduction=.2)learn = synth_learner()
with learn.no_logging(): learn.fit(20, cbs=LRFinder(num_it=100))
lrs,losses = tensor(learn.recorder.lrs[100//10:-5]),tensor(learn.recorder.losses[100//10:-5])def valley(lrs:list, losses:list, num_it:int):
"Suggests a learning rate from the longest valley and returns its index"
n = len(losses)
max_start, max_end = 0,0
# 寻找最长的山谷
lds = [1]*n
for i in range(1,n):
for j in range(0,i):
if (losses[i] < losses[j]) and (lds[i] < lds[j] + 1):
lds[i] = lds[j] + 1
if lds[max_end] < lds[i]:
max_end = i
max_start = max_end - lds[max_end]
sections = (max_end - max_start) / 3
idx = max_start + int(sections) + int(sections/2)
return float(lrs[idx]), (float(lrs[idx]), losses[idx])valley 算法是由 ESRI 开发的,主要是在学习率图中取最长谷底大约 2/3 处分的最陡坡度,且也是 Learner.lr_find 的默认选项。
valley(lrs, losses, 100)(0.007585775572806597, (0.007585775572806597, tensor(10.4701)))def slide(lrs:list, losses:list, num_it:int, lr_diff:int=15, thresh:float=.005, adjust_value:float=1.):
"Suggests a learning rate following an interval slide rule and returns its index"
losses = to_np(losses)
loss_grad = np.gradient(losses)
r_idx = -1
l_idx = r_idx - lr_diff
local_min_lr = lrs[l_idx]
while (l_idx >= -len(losses)) and (abs(loss_grad[r_idx] - loss_grad[l_idx]) > thresh):
local_min_lr = lrs[l_idx]
r_idx -= 1
l_idx -= 1
suggestion = float(local_min_lr) * adjust_value
idx = np.interp(np.log10(suggestion), np.log10(lrs), losses)
return suggestion, (suggestion, idx)slide规则是由Novetta的Andrew Chang开发的一种算法,详细信息请参见此处。
slide(lrs, losses, 100)(6.309573450380412e-07, (6.309573450380412e-07, 12.832133293151855))def minimum(lrs:list, losses:list, num_it:int):
"Suggests a learning rate one-tenth the minumum before divergance and returns its index"
lr_min = lrs[losses.argmin()].item()
loss_idx = losses[min(range(len(lrs)), key=lambda i: abs(lrs[i]-lr_min))]
return lr_min/10, (lr_min, loss_idx)minimum(lrs, losses, 100)(0.10964782238006592, (1.0964782238006592, tensor(7.5869)))def steep(lrs:list, losses:list, num_it:int) -> (float, tuple):
"Suggests a learning rate when the slope is the steepest and returns its index"
grads = (losses[1:]-losses[:-1]) / (lrs[1:].log()-lrs[:-1].log())
lr_steep = lrs[grads.argmin()].item()
loss_idx = losses[min(range(len(lrs)), key=lambda i: abs(lrs[i]-lr_steep))]
return lr_steep, (lr_steep, loss_idx)steep(lrs, losses, 100)(1.9054607491852948e-06, (1.9054607491852948e-06, tensor(12.8940)))@patch
def plot_lr_find(self:Recorder, skip_end=5, return_fig=True, suggestions=None, nms=None, **kwargs):
"Plot the result of an LR Finder test (won't work if you didn't do `learn.lr_find()` before)"
lrs = self.lrs if skip_end==0 else self.lrs [:-skip_end]
losses = self.losses if skip_end==0 else self.losses[:-skip_end]
fig, ax = plt.subplots(1,1)
ax.plot(lrs, losses)
ax.set_ylabel("Loss")
ax.set_xlabel("Learning Rate")
ax.set_xscale('log')
if suggestions:
colors = plt.rcParams['axes.prop_cycle'].by_key()['color'][1:]
for (val, idx), nm, color in zip(suggestions, nms, colors):
ax.plot(val, idx, 'o', label=nm, c=color)
ax.legend(loc='best')mk_class("SuggestionMethod", **{o.__name__.capitalize():o for o in [valley,slide,minimum,steep]},
doc="All possible suggestion methods as convience attributes to get tab-completion and typo-proofing")@patch
def lr_find(self:Learner, start_lr=1e-7, end_lr=10, num_it=100, stop_div=True, show_plot=True, suggest_funcs=(SuggestionMethod.Valley)):
"Launch a mock training to find a good learning rate and return suggestions based on `suggest_funcs` as a named tuple"
n_epoch = num_it//len(self.dls.train) + 1
cb=LRFinder(start_lr=start_lr, end_lr=end_lr, num_it=num_it, stop_div=stop_div)
with self.no_logging(): self.fit(n_epoch, cbs=cb)
if suggest_funcs is not None:
lrs, losses = tensor(self.recorder.lrs[num_it//10:-5]), tensor(self.recorder.losses[num_it//10:-5])
nan_idxs = torch.nonzero(torch.isnan(losses.view(-1)))
if len(nan_idxs) > 0:
drop_idx = min(nan_idxs)
lrs = lrs[:drop_idx]
losses = losses[:drop_idx]
_suggestions, nms = [], []
for func in tuplify(suggest_funcs):
nms.append(func.__name__ if not isinstance(func, partial) else func.func.__name__) # 处理部分内容
_suggestions.append(func(lrs, losses, num_it))
SuggestedLRs = collections.namedtuple('SuggestedLRs', nms)
lrs, pnts = [], []
for lr, pnt in _suggestions:
lrs.append(lr)
pnts.append(pnt)
if show_plot: self.recorder.plot_lr_find(suggestions=pnts, nms=nms)
return SuggestedLRs(*lrs)
elif show_plot: self.recorder.plot_lr_find()最初由Leslie N. Smith在Cyclical Learning Rates for Training Neural Networks中提出,学习率查找器(LR Finder)通过在start_lr和end_lr之间以指数方式增长的学习率训练模型,训练持续num_it次,若出现发散情况则停止(除非stop_div=False),然后以对数刻度绘制损失与学习率的关系图。
各种学习率建议算法可以传入该函数,默认使用valley范式。
::: {#cell-93 .cell 0=‘缓’ 1=‘慢’}
with tempfile.TemporaryDirectory() as d:
learn = synth_learner(path=Path(d))
weights_pre_lr_find = L(learn.model.parameters())
lr_min, lr_steep, lr_valley, lr_slide = learn.lr_find(suggest_funcs=(minimum, steep, valley, slide))
weights_post_lr_find = L(learn.model.parameters())
test_eq(weights_pre_lr_find, weights_post_lr_find)
print(f"Minimum/10:\t{lr_min:.2e}\nSteepest point:\t{lr_steep:.2e}\nLongest valley:\t{lr_valley:.2e}\nSlide interval:\t{lr_slide:.2e}")Minimum/10: 1.58e-01
Steepest point: 9.12e-03
Longest valley: 1.58e-02
Slide interval: 8.32e-02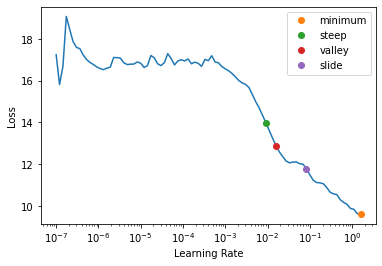
:::
导出 -
from nbdev import nbdev_export
nbdev_export()Converted 00_torch_core.ipynb.
Converted 01_layers.ipynb.
Converted 01a_losses.ipynb.
Converted 02_data.load.ipynb.
Converted 03_data.core.ipynb.
Converted 04_data.external.ipynb.
Converted 05_data.transforms.ipynb.
Converted 06_data.block.ipynb.
Converted 07_vision.core.ipynb.
Converted 08_vision.data.ipynb.
Converted 09_vision.augment.ipynb.
Converted 09b_vision.utils.ipynb.
Converted 09c_vision.widgets.ipynb.
Converted 10_tutorial.pets.ipynb.
Converted 10b_tutorial.albumentations.ipynb.
Converted 11_vision.models.xresnet.ipynb.
Converted 12_optimizer.ipynb.
Converted 13_callback.core.ipynb.
Converted 13a_learner.ipynb.
Converted 13b_metrics.ipynb.
Converted 14_callback.schedule.ipynb.
Converted 14a_callback.data.ipynb.
Converted 15_callback.hook.ipynb.
Converted 15a_vision.models.unet.ipynb.
Converted 16_callback.progress.ipynb.
Converted 17_callback.tracker.ipynb.
Converted 18_callback.fp16.ipynb.
Converted 18a_callback.training.ipynb.
Converted 18b_callback.preds.ipynb.
Converted 19_callback.mixup.ipynb.
Converted 20_interpret.ipynb.
Converted 20a_distributed.ipynb.
Converted 20b_tutorial.distributed.ipynb.
Converted 21_vision.learner.ipynb.
Converted 22_tutorial.imagenette.ipynb.
Converted 23_tutorial.vision.ipynb.
Converted 24_tutorial.image_sequence.ipynb.
Converted 24_tutorial.siamese.ipynb.
Converted 24_vision.gan.ipynb.
Converted 30_text.core.ipynb.
Converted 31_text.data.ipynb.
Converted 32_text.models.awdlstm.ipynb.
Converted 33_text.models.core.ipynb.
Converted 34_callback.rnn.ipynb.
Converted 35_tutorial.wikitext.ipynb.
Converted 37_text.learner.ipynb.
Converted 38_tutorial.text.ipynb.
Converted 39_tutorial.transformers.ipynb.
Converted 40_tabular.core.ipynb.
Converted 41_tabular.data.ipynb.
Converted 42_tabular.model.ipynb.
Converted 43_tabular.learner.ipynb.
Converted 44_tutorial.tabular.ipynb.
Converted 45_collab.ipynb.
Converted 46_tutorial.collab.ipynb.
Converted 50_tutorial.datablock.ipynb.
Converted 60_medical.imaging.ipynb.
Converted 61_tutorial.medical_imaging.ipynb.
Converted 65_medical.text.ipynb.
Converted 70_callback.wandb.ipynb.
Converted 70a_callback.tensorboard.ipynb.
Converted 70b_callback.neptune.ipynb.
Converted 70c_callback.captum.ipynb.
Converted 70d_callback.comet.ipynb.
Converted 74_huggingface.ipynb.
Converted 97_test_utils.ipynb.
Converted 99_pytorch_doc.ipynb.
Converted dev-setup.ipynb.
Converted app_examples.ipynb.
Converted camvid.ipynb.
Converted distributed_app_examples.ipynb.
Converted migrating_catalyst.ipynb.
Converted migrating_ignite.ipynb.
Converted migrating_lightning.ipynb.
Converted migrating_pytorch.ipynb.
Converted migrating_pytorch_verbose.ipynb.
Converted ulmfit.ipynb.
Converted index.ipynb.
Converted quick_start.ipynb.
Converted tutorial.ipynb.