! [ -e /content ] && pip install -Uqq fastai # 在Colab上升级fastai自定义新任务 - siamese
如何使用中级API进行数据收集、模型创建和训练
在本教程中,我们将学习如何使用fastai库的中间层处理一种新类型的任务。我们将使用的示例是一个Siamese网络,它接收两张图像并确定它们是否属于同一类别。我们具体将看到:
- 如何快速从标准PyTorch
Datasets获取DataLoaders - 如何在
Transform中进行适配,以获取一些fastai的展示特性 - 如何为自定义任务添加一些新的
show_batch/show_results行为 - 如何编写自定义的
DataBlock - 如何从预训练模型创建自己的模型
- 如何向
Learner传递自定义的splitter以利用迁移学习
准备数据
为了使我们的数据准备好进行模型训练,我们需要在fastai中创建一个DataLoaders对象。它只是一个训练DataLoader和验证DataLoader的包装,因此如果您已经有了自己的PyTorch数据加载器,您可以直接创建这样的对象。
在这里,我们还没有任何准备好的数据。通常,在使用PyTorch时,第一步是创建一个Dataset,然后将其封装在一个DataLoader中。我们将首先完成这一步,然后看看如何将这个Dataset转换为一个Transform,这将使我们能够利用fastai的功能来显示一个批次或在GPU上使用数据增强。最后,我们将看看如何自定义数据块API并创建我们自己的新TransformBlock。
完全使用PyTorch
首先,我们将仅使用 PyTorch 和 PIL 来创建一个 Dataset,并看看如何将其融入 fastai 中。我们将使用的 fastai 辅助函数只有 untar_data(用于下载和解压数据集)和 get_image_files(用于递归查找文件夹中的所有图像)。在这里,我们将使用 Oxford-IIIT Pet Dataset。
from fastai.data.external import untar_data,URLs
from fastai.data.transforms import get_image_filesuntar_data 返回一个 pathlib.Path 对象,表示解压缩数据集的位置,在这种情况下,所有图像都在一个 images 子文件夹中:
path = untar_data(URLs.PETS)
files = get_image_files(path/"images")
files[0]Path('/home/jhoward/.fastai/data/oxford-iiit-pet/images/great_pyrenees_173.jpg')我们可以使用PIL打开第一张图片,并查看一下它:
import PILimg = PIL.Image.open(files[0])
img
让我们将所有标准预处理(调整大小、转换为张量、除以255和通道重排)封装在一个助手函数中:
import torch
import numpy as npdef open_image(fname, size=224):
img = PIL.Image.open(fname).convert('RGB')
img = img.resize((size, size))
t = torch.Tensor(np.array(img))
return t.permute(2,0,1).float()/255.0open_image(files[0]).shapetorch.Size([3, 224, 224])我们可以看到图像的标签是在文件名中,位于倒数第二个 _ 和一些数字之前。然后我们可以使用正则表达式来创建标签函数:
import redef label_func(fname):
return re.match(r'^(.*)_\d+.jpg$', fname.name).groups()[0]
label_func(files[0])'great_pyrenees'现在让我们收集所有独特的标签:
labels = list(set(files.map(label_func)))
len(labels)37我们有37种不同的宠物品种。为了创建我们的暹罗数据集,我们需要为输入创建图像的元组,如果图像属于同一类,目标将是True,否则为False。建立一种从类到该类文件名列表的映射将会很有用,这样可以快速随机选择任何类的图像。
lbl2files = {l: [f for f in files if label_func(f) == l] for l in labels}现在我们准备创建我们的数据集。对于训练集,我们将遍历所有训练文件名以获取第一张图像,然后随机选择:
- 择取一个同类别的文件名作为第二张图像(概率为0.5)
- 择取一个不同类别的文件名作为第二张图像(概率为0.5)
每次访问一个项目时,我们都会进行这种随机抽样,以便获得尽可能多的样本。然而,对于验证集,我们将一次性固定这个随机抽样(否则我们将在每个时代验证不同的数据集)。
import randomclass SiameseDataset(torch.utils.data.Dataset):
def __init__(self, files, is_valid=False):
self.files,self.is_valid = files,is_valid
if is_valid: self.files2 = [self._draw(f) for f in files]
def __getitem__(self, i):
file1 = self.files[i]
(file2,same) = self.files2[i] if self.is_valid else self._draw(file1)
img1,img2 = open_image(file1),open_image(file2)
return (img1, img2, torch.Tensor([same]).squeeze())
def __len__(self): return len(self.files)
def _draw(self, f):
same = random.random() < 0.5
cls = label_func(f)
if not same: cls = random.choice([l for l in labels if l != cls])
return random.choice(lbl2files[cls]),same我们只需要将我们的文件名分为训练集和验证集以便使用。
idxs = np.random.permutation(range(len(files)))
cut = int(0.8 * len(files))
train_files = files[idxs[:cut]]
valid_files = files[idxs[cut:]]我们可以利用它来创建数据集。
train_ds = SiameseDataset(train_files)
valid_ds = SiameseDataset(valid_files, is_valid=True)以上所有内容对于您的自定义问题来说都会有所不同,关键是只要您有一些 Dataset,就可以使用以下工厂方法创建一个 fastai 的 DataLoaders:
from fastai.data.core import DataLoadersdls = DataLoaders.from_dsets(train_ds, valid_ds)您可以在 Learner 中使用这个 DataLoaders 对象并开始训练。大多数不依赖于显示内容的方法(例如 DataLoaders.show_batch 和 Learner.show_results 等)应该可以正常工作。例如,您可以通过以下方式获取并检查一个批次:
b = dls.one_batch()如果您想使用GPU,可以直接写:
dls = dls.cuda()现在,有点令人烦恼的是,如果我们想要对图像进行标准化或应用数据增强,我们必须重写fastai中已经存在的所有内容。通过对我们编写的代码进行最小的修改,我们仍然可以访问所有这些内容,并使所有的显示方法像锦上添花一样工作。让我们看看怎么做。
使用中级API
当你拥有一个自定义数据集时,你可以通过将 __getitem__ 函数更改为 encodes 来轻松地将其转换为 fastai 的 Transform。一般来说,fastai 中的 Transform 在你对某个项应用时调用 encodes 方法(有点像 PyTorch 模块在对某些内容应用时调用 forward),因此这将把你的 Python 数据集转换为一个将整数转换为你的数据的函数。
如果你返回一个元组(或元组的子类),并使用 fastai 的语义类型,那么你就可以在你的数据上应用任何其他 fastai 的转换,并且它将被正确分派。让我们看看这是如何工作的:
from fastai.vision.all import *class SiameseTransform(Transform):
def __init__(self, files, is_valid=False):
self.files,self.is_valid = files,is_valid
if is_valid: self.files2 = [self._draw(f) for f in files]
def encodes(self, i):
file1 = self.files[i]
(file2,same) = self.files2[i] if self.is_valid else self._draw(file1)
img1,img2 = open_image(file1),open_image(file2)
return (TensorImage(img1), TensorImage(img2), torch.Tensor([same]).squeeze())
def _draw(self, f):
same = random.random() < 0.5
cls = label_func(f)
if not same: cls = random.choice([l for l in labels if l != cls])
return random.choice(lbl2files[cls]),same所以有三件事发生了变化:
__len__被移除了,我们不需要它__getitem__变成了encodes- 我们为我们的图像返回
TensorImage
我们如何用这个构建一个数据集呢?我们将使用 TfmdLists。它只是一个对象,可以懒惰地对列表应用一系列 Transform。在这里,由于我们的转换接受整数,我们将为这个列表传递简单的范围。
train_tl= TfmdLists(range(len(train_files)), SiameseTransform(train_files))
valid_tl= TfmdLists(range(len(valid_files)), SiameseTransform(valid_files, is_valid=True))然后,当我们创建一个 DataLoader 时,可以添加我们喜欢的任何变换。fastai 用其自己的版本替换了 PyTorch 的 DataLoader,这个版本具有更多的钩子(但与 PyTorch 完全兼容)。我们希望应用于单个项的变换应传递给 after_item,希望应用于一批数据的变换应传递给 after_batch。
dls = DataLoaders.from_dsets(train_tl, valid_tl,
after_batch=[Normalize.from_stats(*imagenet_stats), *aug_transforms()])
dls = dls.cuda()通过稍作更改,我们可以使用fastai的归一化和数据增强。如果我们准备做一些额外的编码,我们甚至可以使显示行为正常工作。
使显示工作
fastai中的显示方法都依赖于某些类型能够自我显示。此外,一些需要为显示目的而反转的转换(比如将类别转换为索引或归一化)具有一个decodes方法,用于撤销它们的编码所做的操作。一般来说,fastai会调用这些decodes方法,直到找到一个知道如何自我显示的类型,然后在该类型上调用show方法。
因此,为了使这一切正常工作,让我们首先创建一个具有show方法的新类型!
class SiameseImage(fastuple):
def show(self, ctx=None, **kwargs):
if len(self) > 2:
img1,img2,similarity = self
else:
img1,img2 = self
similarity = 'Undetermined'
if not isinstance(img1, Tensor):
if img2.size != img1.size: img2 = img2.resize(img1.size)
t1,t2 = tensor(img1),tensor(img2)
t1,t2 = t1.permute(2,0,1),t2.permute(2,0,1)
else: t1,t2 = img1,img2
line = t1.new_zeros(t1.shape[0], t1.shape[1], 10)
return show_image(torch.cat([t1,line,t2], dim=2), title=similarity, ctx=ctx, **kwargs)在测试的第一部分有一段代码可以忽略,它主要是为了使显示方法既适用于PIL图像,也适用于张量。主要的内容发生在最后两行:我们创建了一条10像素的黑线,并将带有黑线的两个图像拼接在一起,显示这个张量。通常,ctx代表我们将要展示内容的对象。在这种情况下,它可以是某个特定的matplotlib轴。
让我们看一个例子:
img = PILImage.create(files[0])
img1 = PILImage.create(files[1])
s = SiameseImage(img, img1, False)
s.show();
注意,我们使用的是fastai类型PILImage而不是PIL.Image。这样可以访问fastai的变换。例如,我们可以直接在我们的SiamesImage上使用Resize和ToTensor。由于它是一个元组的子类,这些变换被分派并应用于合适的部分(即PILImage,而不是布尔值)。
tst = Resize(224)(s)
tst = ToTensor()(tst)
tst.show();
现在让我们稍微重写一下之前的变换。我们可以直接处理文件,而不是仅仅处理整数。此外,在fastai中,拆分通常通过帮助函数处理,这些函数返回两个整数列表(训练集中的那些和验证集中的那些),因此我们需要稍微调整一下之前的代码,以便一次性绘制验证图像。我们还需要在映射字典中添加从类到该类文件名列表的映射,分别针对训练和验证拆分,以便在训练集和验证集之间实现完全的分离,即“train”文件应仅从训练拆分中绘制样本;“valid”文件应从验证拆分中绘制。
class SiameseTransform(Transform):
def __init__(self, files, splits):
self.splbl2files = [{l: [f for f in files[splits[i]] if label_func(f) == l] for l in labels}
for i in range(2)]
self.valid = {f: self._draw(f,1) for f in files[splits[1]]}
def encodes(self, f):
f2,same = self.valid.get(f, self._draw(f,0))
img1,img2 = PILImage.create(f),PILImage.create(f2)
return SiameseImage(img1, img2, same)
def _draw(self, f, split=0):
same = random.random() < 0.5
cls = label_func(f)
if not same: cls = random.choice(L(l for l in labels if l != cls))
return random.choice(self.splbl2files[split][cls]),same然后我们使用 RandomSplitter 创建我们的划分:
splits = RandomSplitter()(files)
tfm = SiameseTransform(files, splits)我们测试 tfm.valid 不包含来自训练集的项目:
valids = [v[0] for k,v in tfm.valid.items()]
assert not [v for v in valids if v in files[splits[0]]]我们可以将这些分割传递给 TfmdLists,它将为我们创建验证集和训练集。
tls = TfmdLists(files, tfm, splits=splits)我们现在可以使用像 show_at 这样的 方法:
show_at(tls.valid, 0)
我们可以像之前一样创建一个 DataLoaders,通过为 after_item 和 after_batch 添加我们的自定义变换。
dls = tls.dataloaders(after_item=[Resize(224), ToTensor],
after_batch=[IntToFloatTensor, Normalize.from_stats(*imagenet_stats)])如果我们现在尝试,show_batch 将无法正常工作:默认行为依赖于一些使用数据块构建的数据,而我们使用了一个大的变换来处理所有内容。因此,数据的输入类型和输出类型不是各自独立的,而是整个数据只有一个大类型。如果我们查看一个批次,可以看到 fastai 库已经通过每个变换和批处理操作将该类型传播给我们:
b = dls.one_batch()
type(b)__main__.SiameseImage当我们调用show_batch时,fastai库将会意识到这个批次作为一个整体具有一个show方法,因此它必须知道如何展示自己。它将那个批次直接发送到类型分发函数show_batch。这个函数的签名如下:
show_batch(x, y, samples, ctxs=None, **kwargs)其中kwargs是特定于应用的(在这里我们将有nrows,ncols和figsize等参数)。在我们的情况下,这个批次将作为整体发送到x和y,而samples将为None(这些参数用于当批次没有一个能够展示自己的类型时,见下一个部分)。
要编写自定义的show_batch,我们只需对x使用类型注解,如下所示:
@typedispatch
def show_batch(x:SiameseImage, y, samples, ctxs=None, max_n=6, nrows=None, ncols=2, figsize=None, **kwargs):
if figsize is None: figsize = (ncols*6, max_n//ncols * 3)
if ctxs is None: ctxs = get_grid(min(x[0].shape[0], max_n), nrows=None, ncols=ncols, figsize=figsize)
for i,ctx in enumerate(ctxs): SiameseImage(x[0][i], x[1][i], ['Not similar','Similar'][x[2][i].item()]).show(ctx=ctx)在下一节中,我们将看到当我们有一个没有显示方法的批次时行为是不同的(大多数情况下就是这种情况,只有批次的输入和目标具有这些显示方法)。在这种情况下,参数 y 和 samples 是有用的。在这里,一切都在 x 中,因为批次知道如何整体显示自己,所以它作为一个整体被发送。
在这里,我们创建一个 matplotlib 轴的列表,使用实用函数 get_grid,然后将其传递给所有的 SiameseImage.show。让我们看看实际情况是怎样的:
b = dls.one_batch()dls._types{__main__.SiameseImage: [fastai.torch_core.TensorImage,
fastai.torch_core.TensorImage,
torch.Tensor]}dls.show_batch()
在训练部分,我们将看到创建一个自定义 show_results 是多么简单。现在,让我们看看我们如何可以编写自己的数据块。
编写自定义数据块
Siamese问题只是我们输入为一对图像,目标为一个类别的特定案例。如果“图像对”这一类型在其他问题中再次出现,但是目标不同,那么创建一个自定义块可能会有用,以便能够利用数据块API的强大功能。
注意: 如果你的问题只有一个特定的设置,并且你不需要针对不同目标的模块化方面,那么我们之前做的完全没问题,你不需要再寻找其他方法。
现在,让我们创建一个表示我们两张图像对的类型:
class ImageTuple(fastuple):
@classmethod
def create(cls, fns): return cls(tuple(PILImage.create(f) for f in fns))
def show(self, ctx=None, **kwargs):
t1,t2 = self
if not isinstance(t1, Tensor) or not isinstance(t2, Tensor) or t1.shape != t2.shape: return ctx
line = t1.new_zeros(t1.shape[0], t1.shape[1], 10)
return show_image(torch.cat([t1,line,t2], dim=2), ctx=ctx, **kwargs)由于它是 fastuple 的子类,Transform 将应用于元组的每个部分。例如,ToTensor 将把这个 ImageTuple 转换为 TensorImage 的元组:
img = ImageTuple.create((files[0], files[1]))
tst = ToTensor()(img)
type(tst[0]),type(tst[1])(fastai.torch_core.TensorImage, fastai.torch_core.TensorImage)在show方法中,这次我们没有处理非张量元素(我们可以复制并粘贴之前的代码)。显示假设我们有一个调整大小的转换,并且在我们的处理管道中将图像转换为张量:
img1 = Resize(224)(img)
tst = ToTensor()(img1)
tst.show();
我们现在可以定义一个与 ImageTuple 相关的块,这将在数据块 API 中使用。块基本上是一组默认转换,在这里我们指定如何创建 ImageTuple 和图像预处理所需的 IntToFloatTensor 转换:
def ImageTupleBlock(): return TransformBlock(type_tfms=ImageTuple.create, batch_tfms=IntToFloatTensor)为了使用数据块API收集我们的数据,我们将使用以下函数:
splits_files = [files[splits[i]] for i in range(2)]
splits_sets = mapped(set, splits_files)def get_split(f):
for i,s in enumerate(splits_sets):
if f in s: return i
raise ValueError(f'File {f} is not presented in any split.')splbl2files = [{l: [f for f in s if label_func(f) == l] for l in labels} for s in splits_sets]def splitter(items):
def get_split_files(i): return [j for j,(f1,f2,same) in enumerate(items) if get_split(f1)==i]
return get_split_files(0),get_split_files(1)def draw_other(f):
same = random.random() < 0.5
cls = label_func(f)
split = get_split(f)
if not same: cls = random.choice(L(l for l in labels if l != cls))
return random.choice(splbl2files[split][cls]),samedef get_tuples(files): return [[f, *draw_other(f)] for f in files]我们准备好定义我们的区块了:
def get_x(t): return t[:2]
def get_y(t): return t[2]siamese = DataBlock(
blocks=(ImageTupleBlock, CategoryBlock),
get_items=get_tuples,
get_x=get_x, get_y=get_y,
splitter=splitter,
item_tfms=Resize(224),
batch_tfms=[Normalize.from_stats(*imagenet_stats)]
)dls = siamese.dataloaders(files)我们可以通过 explode_types 方法检查一批中元素的类型。在这里我们有一个元组,其中包含一个包含两个 TensorImage 和一个 TensorCategory 的 ImageTuple。该变换即使在将样本合并在一起后也能正确保持所有内容的类型!
b = dls.one_batch()
explode_types(b){tuple: [{__main__.ImageTuple: [fastai.torch_core.TensorImage,
fastai.torch_core.TensorImage]},
fastai.torch_core.TensorCategory]}show_batch 方法在这里可以直接使用,但为了自定义组织方式,我们可以定义一个调度的 show_batch 函数。这里整个批次只是一个元组,因此没有显示方法。fastai 库将会调度元组的第一部分 (x) 和第二部分 (y),实际样本存储在 samples 变量中。
在这里我们只对 x 进行调度(这意味着此方法将用于 ImageTuple 类型的 x 和任何 y),但是我们可以根据目标实现自定义行为。
@typedispatch
def show_batch(x:ImageTuple, y, samples, ctxs=None, max_n=6, nrows=None, ncols=2, figsize=None, **kwargs):
if figsize is None: figsize = (ncols*6, max_n//ncols * 3)
if ctxs is None: ctxs = get_grid(min(len(samples), max_n), nrows=nrows, ncols=ncols, figsize=figsize)
ctxs = show_batch[object](x, y, samples, ctxs=ctxs, max_n=max_n, **kwargs)
return ctxs作为附注,x和y 实际上并没有被使用(所有需要展示的内容都在 samples 列表中)。它们仅仅是为了类型调度而传递,因为它们携带了我们输入和目标的类型。
我们现在可以看看:
dls.show_batch()
训练模型
模型
我们现在已经到了可以在这些数据上训练模型的阶段。我们将使用一种非常简单的方法:取一个预训练模型的主体,让两张图像通过它。然后以常规方式构建一个头,只需两倍的特征数量。模型本身可以这样表示:
class SiameseModel(Module):
def __init__(self, encoder, head):
self.encoder,self.head = encoder,head
def forward(self, x1, x2):
ftrs = torch.cat([self.encoder(x1), self.encoder(x2)], dim=1)
return self.head(ftrs)对于我们的编码器,我们使用fastai函数create_body。它接受一个架构和一个切割点的索引。默认情况下,它将使用我们选择的模型的预训练版本。如果我们想查看fastai通常在何处切割模型,可以查看model_meta字典:
model_meta[resnet34]{'cut': -2,
'split': <function fastai.vision.learner._resnet_split(m)>,
'stats': ([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])}所以我们需要从-2开始剪切:
encoder = create_body(resnet34, cut=-2)让我们看一下这个编码器的最后一块:
encoder[-1]Sequential(
(0): BasicBlock(
(conv1): Conv2d(256, 512, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(downsample): Sequential(
(0): Conv2d(256, 512, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): BasicBlock(
(conv1): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(2): BasicBlock(
(conv1): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)最后得到512个特征,所以对于我们的自定义头,我们需要将其乘以4(即2*2):2是因为我们有两个图像连接在一起,另2是因为fastai的concat-pool技巧(我们将特征的平均池和最大池连接在一起)。create_head函数将给我们在fastai的迁移学习模型中通常使用的头部。
我们还需要定义我们头部的输出数量 n_out,在我们的例子中是 2:一个用于预测两张图像来自同一类别,另一个用于预测相反的情况。
head = create_head(512*2, 2, ps=0.5)
model = SiameseModel(encoder, head)让我们来看看生成的头部:
headSequential(
(0): AdaptiveConcatPool2d(
(ap): AdaptiveAvgPool2d(output_size=1)
(mp): AdaptiveMaxPool2d(output_size=1)
)
(1): Flatten(full=False)
(2): BatchNorm1d(2048, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(3): Dropout(p=0.25, inplace=False)
(4): Linear(in_features=2048, out_features=512, bias=False)
(5): ReLU(inplace=True)
(6): BatchNorm1d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(7): Dropout(p=0.5, inplace=False)
(8): Linear(in_features=512, out_features=2, bias=False)
)训练模型
我们几乎准备好训练我们的模型了。最后缺少的是一个自定义分割器:为了有效地使用迁移学习,我们希望首先冻结预训练模型,并只训练头部。分割器是一个接受模型并返回参数列表的函数。params 函数用于返回模型的所有参数,因此我们可以像这样创建一个简单的分割器:
def siamese_splitter(model):
return [params(model.encoder), params(model.head)]然后我们使用fastai中的传统CrossEntropyLossFlat损失函数(与nn.CrossEntropyLoss相同,但进行了展平)。唯一需要注意的是,如果使用中级API构建的数据,我们的目标是一个布尔值的张量,因此我们需要将其转换为整数,否则PyTorch会抛出错误。
def loss_func(out, targ):
return CrossEntropyLossFlat()(out, targ.long())我们来获取通过中级 API 构建的数据:
class SiameseTransform(Transform):
def __init__(self, files, splits):
self.splbl2files = [{l: [f for f in files[splits[i]] if label_func(f) == l] for l in labels}
for i in range(2)]
self.valid = {f: self._draw(f,1) for f in files[splits[1]]}
def encodes(self, f):
f2,same = self.valid.get(f, self._draw(f,0))
img1,img2 = PILImage.create(f),PILImage.create(f2)
return SiameseImage(img1, img2, int(same))
def _draw(self, f, split=0):
same = random.random() < 0.5
cls = label_func(f)
if not same: cls = random.choice(L(l for l in labels if l != cls))
return random.choice(self.splbl2files[split][cls]),samesplits = RandomSplitter()(files)
tfm = SiameseTransform(files, splits)
tls = TfmdLists(files, tfm, splits=splits)
dls = tls.dataloaders(after_item=[Resize(224), ToTensor],
after_batch=[IntToFloatTensor, Normalize.from_stats(*imagenet_stats)])再次测试 tfm.valid 是否不包含训练集中的项目:
valids = [v[0] for k,v in tfm.valid.items()]
assert not [v for v in valids if v in files[splits[0]]]我们接下来可以创建我们的 Learner:
learn = Learner(dls, model, loss_func=CrossEntropyLossFlat(), splitter=siamese_splitter, metrics=accuracy)由于我们没有使用一个直接为我们创建 Learner 的便捷函数,因此我们需要手动 freeze 它:
learn.freeze()然后我们可以使用学习率查找器:
learn.lr_find()SuggestedLRs(lr_min=0.0019054606556892395, lr_steep=1.737800812406931e-05)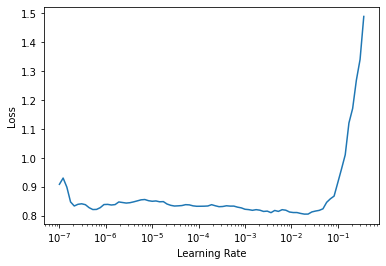
训练一下头脑:
learn.fit_one_cycle(4, 3e-3)| epoch | train_loss | valid_loss | accuracy | time |
|---|---|---|---|---|
| 0 | 0.543907 | 0.378830 | 0.836942 | 00:30 |
| 1 | 0.389485 | 0.263416 | 0.889716 | 00:35 |
| 2 | 0.289101 | 0.199503 | 0.920162 | 00:27 |
| 3 | 0.244186 | 0.176951 | 0.932341 | 00:40 |
解冻并继续训练完整模型:
learn.unfreeze()learn.fit_one_cycle(4, slice(1e-6,1e-4))| epoch | train_loss | valid_loss | accuracy | time |
|---|---|---|---|---|
| 0 | 0.235934 | 0.175252 | 0.933694 | 00:53 |
| 1 | 0.218259 | 0.164884 | 0.933018 | 00:36 |
| 2 | 0.228709 | 0.164789 | 0.933694 | 00:58 |
| 3 | 0.203605 | 0.160317 | 0.935724 | 00:58 |
使 show_results 函数正常工作
@typedispatch
def show_results(x:SiameseImage, y, samples, outs, ctxs=None, max_n=6, nrows=None, ncols=2, figsize=None, **kwargs):
if figsize is None: figsize = (ncols*6, max_n//ncols * 3)
if ctxs is None: ctxs = get_grid(min(x[0].shape[0], max_n), nrows=None, ncols=ncols, figsize=figsize)
for i,ctx in enumerate(ctxs):
title = f'Actual: {["Not similar","Similar"][x[2][i].item()]} \n Prediction: {["Not similar","Similar"][y[2][i].item()]}'
SiameseImage(x[0][i], x[1][i], title).show(ctx=ctx)learn.show_results()
在Learner中补丁siampredict方法,以自动显示图像和预测
@patch
def siampredict(self:Learner, item, rm_type_tfms=None, with_input=False):
res = self.predict(item, rm_type_tfms=None, with_input=False)
if res[0] == tensor(0):
SiameseImage(item[0], item[1], 'Prediction: Not similar').show()
else:
SiameseImage(item[0], item[1], 'Prediction: Similar').show()
return resimgtest = PILImage.create(files[0])
imgval = PILImage.create(files[100])
siamtest = SiameseImage(imgval, imgtest)
siamtest.show();
res = learn.siampredict(siamtest)