! [ -e /content ] && pip install -Uqq fastai # 在Colab上升级fastai混合精度训练
from __future__ import annotations
from fastai.basics import *
from fastai.callback.progress import *
from torch.cuda.amp import GradScaler,autocast
from torch.cuda.amp.grad_scaler import OptStatefrom fastai.test_utils import *
from nbdev.showdoc import *回调和工具函数以支持混合精度训练
一点理论知识
关于混合精度训练的一个非常好且清晰的介绍是 NVIDIA 的这个视频。
什么是半精度?
在神经网络中,所有的计算通常都是用单精度进行的,这意味着所有表示输入、激活、权重等的数组中的浮点数都是32位浮点数(在本文其余部分称为FP32)。为了减少内存使用量(并避免那些恼人的cuda错误),一个思路是尝试使用半精度进行相同的操作,这意味着使用16位浮点数(在本文其余部分称为FP16)。根据定义,它们在RAM中占用一半的空间,并且理论上可以让你将模型的大小翻倍并将批量大小翻倍。
另一个非常好的特点是NVIDIA开发了其最新的GPU(Volta系列)以充分利用半精度张量。基本上,如果你将半精度张量提供给这些GPU,它们会将其堆叠,以便每个核心可以同时进行更多的操作,并且理论上能提供8倍的速度提升(可悲的是,这只是理论上的)。
因此,在半精度下训练对你的内存使用更有利,如果你有一块Volta GPU,它的速度会快得多(即使没有的话,因为计算更简单,速度仍然会快一点)。我们该如何做到这一点?在pytorch中非常简单,我们只需在模型的输入和所有参数上添加.half()。问题是,最终你通常不会看到相同的准确性(因此有时会发生)因为半精度是……好吧……不那么精确 ;)。
半精度的问题:
为了理解半精度的问题,让我们简要看看什么是FP16(更多信息请参见这里)。
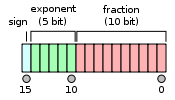
符号位给出我们 +1 或 -1,然后我们有 5 位来编码一个范围在 -14 到 15 之间的指数,剩下的 10 位则用于表示小数部分。与 FP32 相比,我们可能的值范围较小(大约是 2e-14 到 2e15,而 FP32 是 2e-126 到 2e127),但也有较小的 偏移量。
例如,在 1 和 2 之间,FP16 格式只表示数字 1、1+2e-10、1+2*2e-10……这意味着在半精度下 1 + 0.0001 = 1。这将导致一些问题,尤其是会发生的三种问题会干扰你的训练。
权重更新不精确:在你的优化器中,你基本上对网络中的每个权重执行 w = w - lr * w.grad。使用半精度执行此操作的问题在于,w.grad 经常比 w 低几个数量级,并且学习率也较小。因此,w=1 且 lr*w.grad 为 0.0001(或更小)的情况非常常见,但在这些情况下更新不会产生任何效果。
你的梯度可能会下溢。在 FP16 中,你的梯度可能会因为过低而被轻易替换为 0。
你的激活值或损失可能会溢出。这是与梯度相反的问题:在 FP16 精度下,更容易出现 nan(或无穷大),并且你的训练可能更容易发散。
解决方案:混合精度训练
为了解决这三个问题,我们并不完全在FP16精度下进行训练。正如混合训练的名称所暗示的,部分操作将在FP16进行,其余操作将在FP32进行。这样主要是为了处理上述第一个问题。对于接下来的两个问题,还有其他技巧。
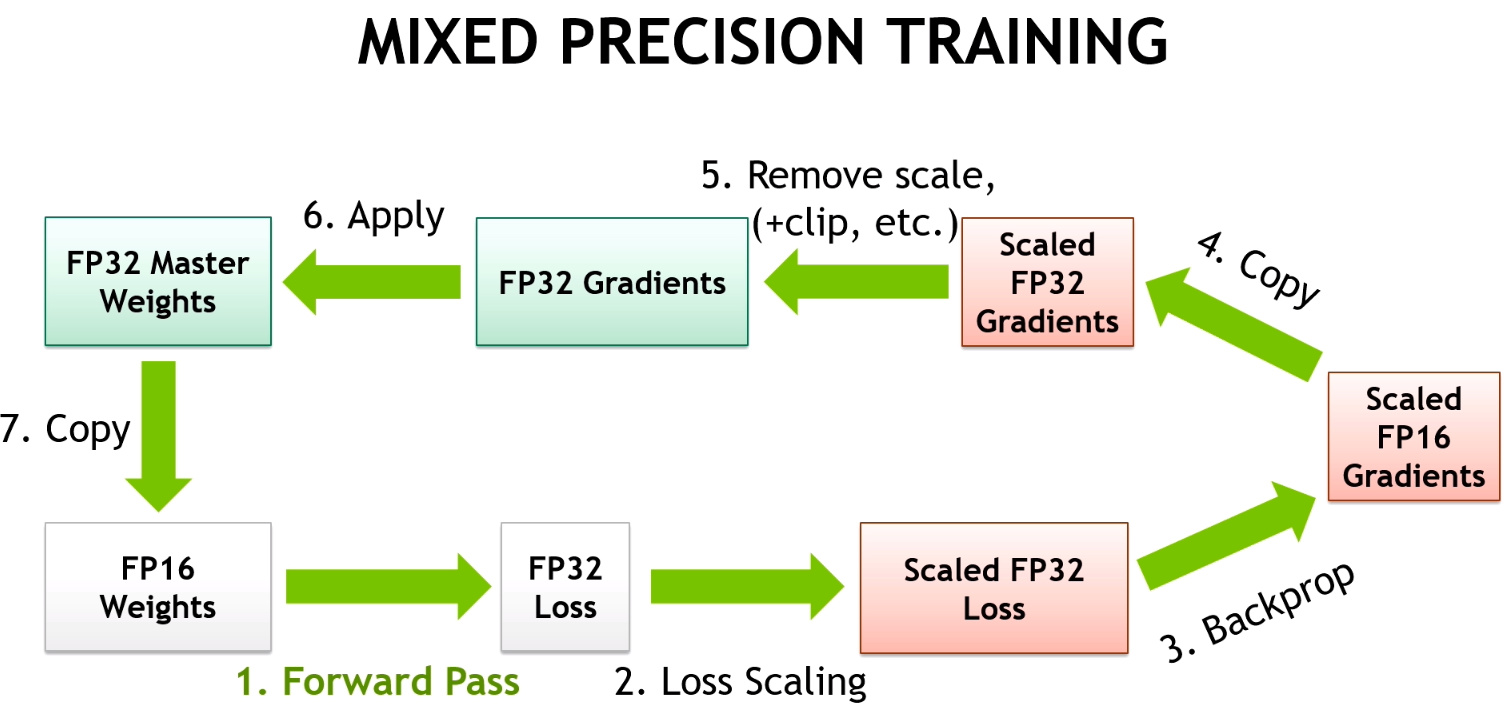
主要思想是我们希望在半精度下进行前向传递和梯度计算(以提高速度),但在单精度下进行更新(以获得更高的精确度)。如果权重w和梯度grad都是半浮点数是可以的,但当我们执行操作w = w - lr * grad时,我们需要在FP32下计算。这样我们的1 + 0.0001将会是1.0001。
这就是为什么我们保留一个FP32的权重副本(称为主模型)。然后,我们的训练循环将如下所示:
- 使用FP16模型计算输出,然后计算损失
- 在半精度下反向传播梯度
- 将梯度复制为FP32精度
- 在主模型(FP32精度)上进行更新
- 将主模型复制到FP16模型中
请注意,我们在第5步中会损失精度,权重中的1.0001将回到1。但如果下一个更新再次对应于添加0.0001,由于优化步骤是在主模型上进行的,1.0001将变为1.0002,最终如果这样进行到1.0005,FP16模型将能够区分出差异。
这解决了第一个问题。对于第二个问题,我们使用一种叫做梯度缩放的方法:为了避免梯度由于FP16精度而被归零,我们将损失乘以一个缩放因子(例如scale=512)。这样我们可以在接下来的图中将梯度向右推,避免它们变为零。
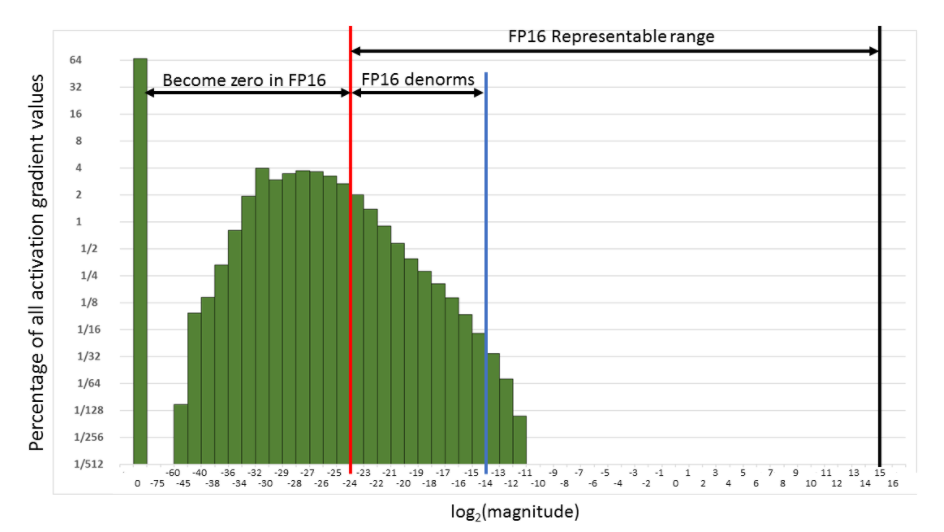
当然,我们不希望这512倍缩放的梯度参与权重更新,因此在转换为FP32之后,我们可以在没有风险变为0的情况下将其除以这个缩放因子。这将循环更改为:
- 使用FP16模型计算输出,然后计算损失。
- 将损失乘以缩放因子,然后在半精度下反向传播梯度。
- 将梯度复制为FP32精度,然后将其除以缩放因子。
- 在主模型(FP32精度)上进行更新。
- 将主模型复制到FP16模型中。
对于最后一个问题,NVIDIA提供的技巧是将batchnorm层保留在单精度(它们的权重不多,所以不是一个大的内存挑战),并在单精度下计算损失(这意味着在将模型的最后输出传递给损失之前,将其转换为单精度)。
动态损失缩放
先前的混合精度训练实现中唯一令人烦恼的事情是,它引入了一个新的超参数需要调整,即损失缩放的值。幸运的是,我们有解决办法。我们希望损失缩放尽可能高,以便我们的梯度能够使用整个表示范围,因此我们首先尝试一个非常高的值。在很大可能性下,这将导致我们的梯度或损失溢出,我们将尝试半个那个值,然后再试,直到找到一个不会导致梯度溢出的最大损失缩放值。
这个值将完美地适应我们的模型,并且可以在训练过程中动态调整,如果它仍然太高,只需在每次溢出时将其减半。然而,经过一段时间后,训练将收敛,梯度将开始变小,因此我们还需要一个机制,在安全的情况下增大这个动态损失缩放。Apex库中使用的策略是,每当我们在没有溢出的情况下完成给定数量的迭代时,将损失缩放乘以2。
BFloat16 混合精度
BFloat16 (BF16) 是由 Google Brain 开发的 16 位浮点数格式。BF16 与 FP32 具有相同的指数,因此将 7 位留给小数。这使得 BF16 具有与 FP32 相同的范围,但精度显著降低。
由于与 FP32 具有相同的范围,BF16 混合精度训练跳过了缩放步骤。所有其他混合精度步骤与 FP16 混合精度保持一致。
BF16 混合精度需要 Ampere 或更新版本的硬件。并不是所有的 PyTorch 操作都受支持。
要在 BF16 混合精度下训练,可以将 amp_mode=AMPMode.BF16 或 amp_mode='bf16' 传递给 MixedPrecision,或使用 Learner.to_bf16 便利方法。
混合精度 -
class AMPMode(Enum):
"Automatic mixed precision modes for ease of completion"
FP16 = 'fp16'
BF16 = 'bf16'@delegates(GradScaler)
class MixedPrecision(Callback):
"Mixed precision training using Pytorch's Automatic Mixed Precision (AMP)"
order = 10
def __init__(self,
amp_mode:str|AMPMode=AMPMode.FP16, # Mixed Precision training mode. Supports fp16 and bf16.
**kwargs
):
amp_mode = AMPMode(amp_mode)
store_attr(names='amp_mode')
self.kwargs = kwargs
def before_fit(self):
if self.amp_mode == AMPMode.BF16:
if torch.cuda.is_available() and not torch.cuda.is_bf16_supported():
raise ValueError("Unsupported GPU for bfloat16 mixed precision training")
dtype = torch.bfloat16
elif self.amp_mode == AMPMode.FP16:
dtype = torch.float16
else:
raise ValueError(f"Unrecognized precision: {self.amp_mode}")
# `GradScaler` is not needed for bfloat16 as fp32 and bf16 have the same range
self.kwargs['enabled'] = dtype == torch.float16
self.autocast,self.learn.scaler,self.scales = autocast(dtype=dtype),GradScaler(**self.kwargs),L()
def before_batch(self): self.autocast.__enter__()
def after_pred(self):
self.learn.pred = to_float(self.pred)
def after_loss(self): self.autocast.__exit__(None, None, None)
def before_backward(self): self.learn.loss_grad = self.scaler.scale(self.loss_grad)
def before_step(self):
"Use `self` as a fake optimizer. `self.skipped` will be set to True `after_step` if gradients overflow."
self.skipped=True
self.scaler.step(self)
if self.skipped: raise CancelStepException()
self.scales.append(self.scaler.get_scale())
def after_step(self): self.learn.scaler.update()
def after_fit(self): self.autocast,self.learn.scaler,self.scales = None,None,None
@property
def param_groups(self):
"Pretend to be an optimizer for `GradScaler`"
return self.opt.param_groups
def step(self, *args, **kwargs):
"Fake optimizer step to detect whether this batch was skipped from `GradScaler`"
self.skipped=Falseshow_doc(MixedPrecision)class FP16TestCallback(Callback):
"Asserts that predictions are `float16` values"
order = 9
def after_pred(self):
assert listify(flatten(self.pred))[0].dtype==torch.float16class BF16TestCallback(Callback):
"Asserts that predictions are `bfloat16` values"
order = 9
def after_pred(self):
assert listify(flatten(self.pred))[0].dtype==torch.bfloat16#|cuda
set_seed(99, True)
learn = synth_learner(cbs=[MixedPrecision,FP16TestCallback], cuda=True)
learn.model = nn.Sequential(nn.Linear(1,1), nn.Linear(1,1)).cuda()
learn.opt_func = partial(SGD, mom=0.)
learn.splitter = lambda m: [list(m[0].parameters()), list(m[1].parameters())]
learn.fit(3)
assert learn.recorder.values[-1][-1]<learn.recorder.values[0][-1]| epoch | train_loss | valid_loss | time |
|---|---|---|---|
| 0 | 17.554865 | 14.357819 | 00:00 |
| 1 | 17.006779 | 13.436550 | 00:00 |
| 2 | 16.414442 | 12.542552 | 00:00 |
#|cuda
#多输出版本
set_seed(99, True)
learn = synth_learner(cbs=[MixedPrecision,FP16TestCallback], cuda=True)
class MultiOutputModel(Module):
def __init__(self): self.linear1, self.linear2 = nn.Linear(1,1) , nn.Linear(1,1)
def forward(self,x): return self.linear1(x), self.linear2(x)
def multioutputloss(pred, val): return ((val-pred[0]).abs() + 0.5 * (val-pred[1]).abs()).sum()
learn.model = MultiOutputModel()
learn.opt_func = partial(SGD, mom=0.)
learn.splitter = lambda m: [list(m.linear1.parameters()), list(m.linear2.parameters())]
learn.loss_func=multioutputloss
learn.fit(3)
assert learn.recorder.values[-1][-1]<learn.recorder.values[0][-1]| epoch | train_loss | valid_loss | time |
|---|---|---|---|
| 0 | 87.652245 | 72.425194 | 00:00 |
| 1 | 86.457306 | 70.571136 | 00:00 |
| 2 | 85.303947 | 68.533089 | 00:00 |
#|cuda
if torch.cuda.is_bf16_supported():
set_seed(99, True)
learn = synth_learner(cbs=[MixedPrecision(amp_mode=AMPMode.BF16),BF16TestCallback], cuda=True)
learn.model = nn.Sequential(nn.Linear(1,1), nn.Linear(1,1)).cuda()
learn.opt_func = partial(SGD, mom=0.)
learn.splitter = lambda m: [list(m[0].parameters()), list(m[1].parameters())]
learn.fit(3)
assert learn.recorder.values[-1][-1]<learn.recorder.values[0][-1]@patch
@delegates(GradScaler)
def to_fp16(self:Learner, **kwargs):
"Set `Learner` to float16 mixed precision using PyTorch AMP"
return self.add_cb(MixedPrecision(**kwargs))@patch
def to_bf16(self:Learner):
"Set `Learner` to bfloat16 mixed precision using PyTorch AMP"
return self.add_cb(MixedPrecision(amp_mode=AMPMode.BF16))@patch
def to_fp32(self:Learner):
"Set `Learner` to float32 precision"
return self.remove_cb(MixedPrecision)工具函数
在进入主要的 Callback 之前,我们需要一些辅助函数。我们使用来自 APEX 库 的函数。
::: {#cell-32 .cell 0=‘e’ 1=‘x’ 2=‘p’ 3=‘o’ 4=‘r’ 5=‘t’}
from fastai.fp16_utils import convert_network, model_grads_to_master_grads, master_params_to_model_params:::
将模型转换为FP16
我们需要一个函数将模型的所有层转换为FP16精度,除了BatchNorm类的层(因为这些需要以FP32精度进行以保持稳定)。在Apex中,执行此操作的函数是convert_network。我们可以使用它将模型设置为FP16或恢复为FP32。
model = nn.Sequential(nn.Linear(10,30), nn.BatchNorm1d(30), nn.Linear(30,2)).cuda()
model = convert_network(model, torch.float16)
for i,t in enumerate([torch.float16, torch.float32, torch.float16]):
test_eq(model[i].weight.dtype, t)
test_eq(model[i].bias.dtype, t)
model = nn.Sequential(nn.Linear(10,30), BatchNorm(30, ndim=1), nn.Linear(30,2)).cuda()
model = convert_network(model, torch.float16)
for i,t in enumerate([torch.float16, torch.float32, torch.float16]):
test_eq(model[i].weight.dtype, t)
test_eq(model[i].bias.dtype, t)创建参数的主副本
根据我们的模型参数(主要为FP16),我们将需要创建一个FP32的副本(主参数),我们将在优化器中使用这个副本。可选地,我们将所有参数连接起来形成一个扁平的大张量,这可以让这一步执行得更快一些。
我们不能在这里使用FP16工具函数,因为它无法处理多个参数组,而这是我们用来:
- 进行迁移学习并冻结某些层
- 应用辨别学习率
- 不对某些层(如BatchNorm)或偏置项应用权重衰减
from torch.nn.utils import parameters_to_vectordef get_master(
opt:Optimizer, # 从中获取模型参数的优化器
flat_master:bool=False, # 将fp32参数展平成向量以提升性能
) -> list: # fp16参数列表,以及fp32参数列表
"Creates fp16 model params given an initialized `Optimizer`, also returning fp32 model params. "
model_params = [[param for param in pg if getattr(param, 'requires_grad', False) and hasattr(param, 'data')] for pg in opt.param_lists]
if flat_master:
master_params = []
for pg in model_params:
mp = parameters_to_vector([param.data.float() for param in pg])
mp = nn.Parameter(mp, requires_grad=True)
if mp.grad is None: mp.grad = mp.new(*mp.size())
master_params.append([mp])
else:
master_params = [[nn.Parameter(param.data.clone().float().detach(), requires_grad=True) for param in pg] for pg in model_params]
return model_params, master_params#|cuda
learn = synth_learner()
learn.model = convert_network(nn.Sequential(nn.Linear(1,1), nn.Linear(1,1)), torch.float16).cuda()
learn.splitter = lambda m: [list(m[0].parameters()), list(m[1].parameters())]
learn.opt = learn.opt_func(learn.splitter(learn.model), learn.lr)
model_p,master_p = get_master(learn.opt)
test_eq(len(model_p), 2) #2 pqrqm 群组
test_eq(len(master_p), 2)
for pg1,pg2 in zip(model_p,master_p):
test_eq([p.float() for p in pg1], pg2) #相同值但不同类型
for p in pg1: assert p.dtype == torch.float16#|cuda
#扁平化版本
model_pf,master_pf = get_master(learn.opt, flat_master=True)
test_eq(len(model_pf), 2) #2 pqrqm 群组
test_eq(len(master_pf), 2)
for pg1,pg2 in zip(model_pf,master_pf):
test_eq(len(pg2), 1) #一个展平的张量
test_eq([p.float().squeeze() for p in pg1], [p for p in pg2[0]]) #相同值但不同类型
for p in pg1: assert p.dtype == torch.float16将梯度从模型参数复制到主参数
在反向传播后,所有的梯度必须在进行FP32的优化器步骤之前复制到主参数中。Apex工具中的相应函数是model_grads_to_master_grads,但我们需要对其进行调整,以便与参数组一起使用。
::: {#cell-44 .cell 0=‘e’ 1=‘x’ 2=‘p’ 3=‘o’ 4=‘r’ 5=‘t’}
def to_master_grads(
model_pgs:list, # 从fp16模型参数复制梯度
master_pgs:list, # 将fp32模型参数的梯度复制到
flat_master:bool=False, # 无论fp32参数是否之前已被展平
):
"Move fp16 model gradients to fp32 master gradients"
for (model_params,master_params) in zip(model_pgs,master_pgs):
model_grads_to_master_grads(model_params, master_params, flat_master=flat_master):::
#|cuda
xb,yb = learn.dls.one_batch()
pred = learn.model.cuda()(xb.cuda().half())
loss = F.mse_loss(pred, yb.cuda().half())
loss.backward()
to_master_grads(model_p, master_p)
to_master_grads(model_pf, master_pf, flat_master=True)
test_eq([[p.grad.float() for p in pg] for pg in model_p],
[[p.grad for p in pg] for pg in master_p])
test_eq([[p.grad.float().squeeze() for p in pg] for pg in model_pf],
[[p for p in pg[0].grad] for pg in master_pf])
xb.shapetorch.Size([16, 1])将主参数复制到模型参数
在这一步之后,我们需要将主参数复制回模型参数,以便进行下一次更新。Apex 中的相应函数是 master_params_to_model_params。
::: {#cell-48 .cell 0=‘e’ 1=‘x’ 2=‘p’ 3=‘o’ 4=‘r’ 5=‘t’}
def to_model_params(
model_pgs:list, # 将Fp16模型参数复制到
master_pgs:list, # 要复制的fp32主参数
flat_master:bool=False # master_pgs 是否曾经被扁平化
)->None:
"Copy updated fp32 master params to fp16 model params after gradient step. "
for (model_params,master_params) in zip(model_pgs,master_pgs):
master_params_to_model_params(model_params, master_params, flat_master=flat_master):::
#|CUDA
learn.opt.params = master_p
learn.opt.step()
to_model_params(model_p, master_p)
test_close([p.float() for pg in model_p for p in pg], [p for pg in master_p for p in pg], eps=1e-3)#|cuda
learn.opt.params = master_pf
learn.opt.step()
to_model_params(model_pf, master_pf, flat_master=True)
test_close([p.float().squeeze() for pg in model_pf for p in pg], [p for pg in master_pf for p in pg[0]], eps=1e-3)检查溢出
对于动态损失缩放,我们需要知道梯度何时达到无穷大。检查总和比执行 torch.isinf(x).any() 更快。
::: {#cell-53 .cell 0=‘e’ 1=‘x’ 2=‘p’ 3=‘o’ 4=‘r’ 5=‘t’}
def test_overflow(x:torch.Tensor):
"Tests whether fp16 gradients have overflown."
s = float(x.float().sum())
return (s == float('inf') or s == float('-inf') or s != s):::
x = torch.randn(3,4)
assert not test_overflow(x)
x[1,2] = float('inf')
assert test_overflow(x)然后我们可以在以下函数中使用它,该函数用于检查梯度溢出:
::: {#cell-56 .cell 0=‘e’ 1=‘x’ 2=‘p’ 3=‘o’ 4=‘r’ 5=‘t’}
def grad_overflow(pgs:list)->bool:
"Tests all fp16 parameters in pgs for gradient overflow"
for pg in pgs:
for p in pg:
if p.grad is not None and test_overflow(p.grad.data): return True
return False:::
#|cuda
assert not grad_overflow(model_p)
assert not grad_overflow(model_pf)
model_p[1][0].grad.data[0,0] = float('inf')
model_pf[0][1].grad.data[0] = float('inf')
assert grad_overflow(model_p)
assert grad_overflow(model_pf)非原生混合精度 -
def copy_clone(d):
return {k:(v.detach().clone().float() if isinstance(v,Tensor) else v) for k,v in d.items()}def _copy_state(opt, pgs1, pgs2):
opt.param_lists = pgs2
for pg1,pg2 in zip(pgs1, pgs2):
for p1,p2 in zip(pg1, pg2): opt.state[p2] = copy_clone(opt.state.pop(p1, {}))class ModelToHalf(Callback):
"Use with NonNativeMixedPrecision callback (but it needs to run at the very beginning)"
order=-50
def before_fit(self): self.learn.model = convert_network(self.model, dtype=torch.float16)
def after_fit (self): self.learn.model = convert_network(self.model, dtype=torch.float32)@docs
class NonNativeMixedPrecision(Callback):
"Run training in mixed precision"
order=10
def __init__(self,
loss_scale:int=512, # 非动态损失缩放,用于避免梯度下溢。
flat_master:bool=False, # 是否为了性能而将fp32参数展平
dynamic:bool=True, # 是否自动确定损失缩放
max_loss_scale:float=2.**24, # 动态损失缩放的起始值
div_factor:float=2., # 在溢出时除以这个值,在经过scale_wait批次后乘以这个值
scale_wait:int=500, # 等待损失比例增加的批次数量
clip:float=None, # 用于裁剪梯度的值,即 `nn.utils.clip_grad_norm_` 中的 `max_norm`。
):
assert torch.backends.cudnn.enabled, "Mixed precision training requires cudnn."
self.flat_master,self.dynamic,self.max_loss_scale = flat_master,dynamic,max_loss_scale
self.div_factor,self.scale_wait,self.clip = div_factor,scale_wait,clip
self.loss_scale = max_loss_scale if dynamic else loss_scale
def before_fit(self):
assert self.dls.device.type == 'cuda', "Mixed-precision training requires a GPU, remove the call `to_fp16`"
if self.learn.opt is None: self.learn.create_opt()
self.model_pgs,self.master_pgs = get_master(self.opt, self.flat_master)
self.old_pgs = self.opt.param_lists
#将优化器更改为在FP32精度下执行优化步骤。
_copy_state(self.learn.opt, self.model_pgs, self.master_pgs)
if self.dynamic: self.count = 0
def before_batch(self): self.learn.xb = to_half(self.xb)
def after_pred(self): self.learn.pred = to_float(self.pred)
def before_backward(self): self.learn.loss_grad *= self.loss_scale
def before_step(self):
首先,检查是否存在溢出情况。
if self.dynamic and grad_overflow(self.model_pgs):
self.loss_scale /= self.div_factor
self.learn.loss_grad /= self.div_factor #记录正确的损失
self.model.zero_grad()
raise CancelBatchException() #跳过步骤并清零梯度
to_master_grads(self.model_pgs, self.master_pgs, self.flat_master)
for master_params in self.master_pgs:
for param in master_params:
if param.grad is not None: param.grad.div_(self.loss_scale)
if self.clip is not None:
for group in self.master_pgs: nn.utils.clip_grad_norm_(group, self.clip)
# Check if it's been long enough without overflow
if self.dynamic:
self.count += 1
if self.count == self.scale_wait:
self.count = 0
self.loss_scale *= self.div_factor
def after_step(self):
self.model.zero_grad() #Zero the gradients of the model manually (optimizer disconnected)
to_model_params(self.model_pgs, self.master_pgs, self.flat_master)
def after_batch(self):
if self.training: self.learn.loss_grad /= self.loss_scale #Log correct loss
def after_fit(self):
if not hasattr(self,'master_pgs'): return
_copy_state(self.learn.opt, self.master_pgs, self.model_pgs)
self.learn.opt.param_lists = self.old_pgs
delattr(self, "master_pgs")
delattr(self, "model_pgs")
delattr(self, "old_pgs")
_docs = dict(before_fit="Put the model in FP16 and prepare the two copies of the parameters",
before_batch="Put the input in FP16",
after_pred="Put the output back to FP32 so that the loss is computed in FP32",
before_backward="Apply loss scaling to avoid gradient underflow",
before_step="Update and apply dynamic loss scaling, move gradients to fp32, apply gradient clipping",
after_step="Zero fp16 grads and update fp16 params with fp32 params. ",
after_batch="Ensure loss is logged correctly",
after_fit="Put the model back in FP32")class TestBeforeMixedPrecision(Callback):
order=-55
def before_fit(self): test_eq(first(self.model.parameters()).dtype, torch.float32)
def before_batch(self): test_eq(self.x.dtype, torch.float32)
def after_pred(self): test_eq(self.pred.dtype, torch.float16)
def after_loss(self): self.tst_loss = self.learn.loss_grad.detach().clone()
def before_step(self):
self.learn.has_overflown = grad_overflow(self.non_native_mixed_precision.model_pgs)
self.grads = [p.grad.data.clone() for p in self.model.parameters()]
self.old_params = [p.data.clone() for p in self.model.parameters()]
def after_cancel_step(self): assert self.has_overflown
class TestAfterMixedPrecision(Callback):
order=65
def before_fit(self): test_eq(first(self.model.parameters()).dtype, torch.float16)
def after_fit(self): test_eq(first(self.model.parameters()).dtype, torch.float32)
def before_batch(self): test_eq(self.x.dtype, torch.float16)
def after_pred(self): test_eq(self.pred.dtype, torch.float32)
def before_backward(self):
loss_scale = self.non_native_mixed_precision.loss_scale if self.training else 1.
test_eq(self.loss_grad, self.test_before_mixed_precision.tst_loss * loss_scale)
def before_step(self):
tbmp = self.test_before_mixed_precision
test_eq(self.loss_grad, tbmp.loss_grad)
#测试梯度已复制并缩放回原值
test_close(sum([[p.grad.data for p in pg] for pg in self.non_native_mixed_precision.master_pgs], []),
[g.float()/self.non_native_mixed_precision.loss_scale for g in tbmp.grads])
def after_batch(self):
if self.has_overflown: return
tbmp,mp =self.test_before_mixed_precision,self.non_native_mixed_precision
#测试主参数已复制到模型
test_close(sum([[p.data for p in pg] for pg in mp.master_pgs], []),
[p.data.float() for p in self.model.parameters()], eps=1e-3)
#测试更新已正确完成
for p,g,op in zip(self.model.parameters(), tbmp.grads, tbmp.old_params):
test_close(p.data.float(), op.float() - self.lr*g.float()/self.non_native_mixed_precision.loss_scale, eps=1e-3)#|CUDA
learn = synth_learner(cbs=[ModelToHalf(), NonNativeMixedPrecision()], cuda=True)
learn.model = nn.Sequential(nn.Linear(1,1), nn.Linear(1,1)).cuda()
learn.opt_func = partial(SGD, mom=0.)
learn.splitter = lambda m: [list(m[0].parameters()), list(m[1].parameters())]
learn.fit(3, cbs=[TestAfterMixedPrecision(), TestBeforeMixedPrecision()])
#检查损失缩放是否已更改
assert 1 < learn.non_native_mixed_precision.loss_scale < 2**24
#检查模型是否已训练
for v1,v2 in zip(learn.recorder.values[0], learn.recorder.values[-1]): assert v2<v1| epoch | train_loss | valid_loss | time |
|---|---|---|---|
| 0 | 7.187932 | 5.855845 | 00:00 |
| 1 | 7.148743 | 5.697717 | 00:00 |
| 2 | 7.048915 | 5.524172 | 00:00 |
#|cuda
learn = synth_learner(cbs=[ModelToHalf(), NonNativeMixedPrecision(dynamic=False)], cuda=True)
learn.model = nn.Sequential(nn.Linear(1,1), nn.Linear(1,1)).cuda()
learn.opt_func = partial(SGD, mom=0.)
learn.splitter = lambda m: [list(m[0].parameters()), list(m[1].parameters())]
learn.fit(3, cbs=[TestAfterMixedPrecision(), TestBeforeMixedPrecision()])
#检查损失缩放未发生变化
test_eq(learn.non_native_mixed_precision.loss_scale,512)
#检查模型是否已训练
for v1,v2 in zip(learn.recorder.values[0], learn.recorder.values[-1]): assert v2<v1| epoch | train_loss | valid_loss | time |
|---|---|---|---|
| 0 | 11.927933 | 12.063744 | 00:00 |
| 1 | 11.539829 | 11.545557 | 00:00 |
| 2 | 11.266481 | 11.075830 | 00:00 |
@patch
@delegates(NonNativeMixedPrecision.__init__)
def to_non_native_fp16(self:Learner, **kwargs): return self.add_cbs([ModelToHalf(), NonNativeMixedPrecision(**kwargs)])::: {#cell-67 .cell 0=‘c’ 1=‘u’ 2=‘d’ 3=‘a’}
learn = synth_learner(cuda=True)
learn.model = nn.Sequential(nn.Linear(1,1), nn.Linear(1,1)).cuda()
learn.opt_func = partial(SGD, mom=0.)
learn.splitter = lambda m: [list(m[0].parameters()), list(m[1].parameters())]
learn.to_non_native_fp16()
learn.fit(3, cbs=[TestAfterMixedPrecision(), TestBeforeMixedPrecision()])
#检查模型是否已训练
for v1,v2 in zip(learn.recorder.values[0], learn.recorder.values[-1]): assert v2<v1| epoch | train_loss | valid_loss | time |
|---|---|---|---|
| 0 | 8.358611 | 10.943352 | 00:00 |
| 1 | 8.330508 | 10.722443 | 00:00 |
| 2 | 8.221409 | 10.485508 | 00:00 |
:::
#|cuda
learn = synth_learner(cuda=True)
learn.model = nn.Sequential(nn.Linear(1,1), nn.Linear(1,1)).cuda()
learn.opt_func = partial(SGD, mom=0.9)
learn.splitter = lambda m: [list(m[0].parameters()), list(m[1].parameters())]
learn.to_non_native_fp16()
learn.freeze()
learn.create_opt()
init_ps = [p for pg in learn.opt.param_groups for p in pg]
learn.fit(3)
final_ps = [p for pg in learn.opt.param_groups for p in pg]
for p1,p2 in zip(init_ps, final_ps): test_is(p1, p2)
#第一个参数组没有状态,因为未经过训练
test_eq([learn.opt.state[p] for p in learn.opt.param_lists[0]], [{}, {'do_wd': False}])
#第二个参数组具有状态
for p in learn.opt.param_lists[1]: assert 'grad_avg' in learn.opt.state[p]| epoch | train_loss | valid_loss | time |
|---|---|---|---|
| 0 | 11.646567 | 10.883919 | 00:00 |
| 1 | 11.489956 | 9.904404 | 00:00 |
| 2 | 10.746455 | 7.914827 | 00:00 |
@patch
def to_non_native_fp32(self: Learner): return self.remove_cbs([ModelToHalf, NonNativeMixedPrecision])::: {#cell-70 .cell 0=‘c’ 1=‘u’ 2=‘d’ 3=‘a’}
learn = learn.to_non_native_fp32():::
导出 -
from nbdev import *
nbdev_export()Converted 00_torch_core.ipynb.
Converted 01_layers.ipynb.
Converted 01a_losses.ipynb.
Converted 02_data.load.ipynb.
Converted 03_data.core.ipynb.
Converted 04_data.external.ipynb.
Converted 05_data.transforms.ipynb.
Converted 06_data.block.ipynb.
Converted 07_vision.core.ipynb.
Converted 08_vision.data.ipynb.
Converted 09_vision.augment.ipynb.
Converted 09b_vision.utils.ipynb.
Converted 09c_vision.widgets.ipynb.
Converted 10_tutorial.pets.ipynb.
Converted 10b_tutorial.albumentations.ipynb.
Converted 11_vision.models.xresnet.ipynb.
Converted 12_optimizer.ipynb.
Converted 13_callback.core.ipynb.
Converted 13a_learner.ipynb.
Converted 13b_metrics.ipynb.
Converted 14_callback.schedule.ipynb.
Converted 14a_callback.data.ipynb.
Converted 15_callback.hook.ipynb.
Converted 15a_vision.models.unet.ipynb.
Converted 16_callback.progress.ipynb.
Converted 17_callback.tracker.ipynb.
Converted 18_callback.fp16.ipynb.
Converted 18a_callback.training.ipynb.
Converted 18b_callback.preds.ipynb.
Converted 19_callback.mixup.ipynb.
Converted 20_interpret.ipynb.
Converted 20a_distributed.ipynb.
Converted 21_vision.learner.ipynb.
Converted 22_tutorial.imagenette.ipynb.
Converted 23_tutorial.vision.ipynb.
Converted 24_tutorial.image_sequence.ipynb.
Converted 24_tutorial.siamese.ipynb.
Converted 24_vision.gan.ipynb.
Converted 30_text.core.ipynb.
Converted 31_text.data.ipynb.
Converted 32_text.models.awdlstm.ipynb.
Converted 33_text.models.core.ipynb.
Converted 34_callback.rnn.ipynb.
Converted 35_tutorial.wikitext.ipynb.
Converted 37_text.learner.ipynb.
Converted 38_tutorial.text.ipynb.
Converted 39_tutorial.transformers.ipynb.
Converted 40_tabular.core.ipynb.
Converted 41_tabular.data.ipynb.
Converted 42_tabular.model.ipynb.
Converted 43_tabular.learner.ipynb.
Converted 44_tutorial.tabular.ipynb.
Converted 45_collab.ipynb.
Converted 46_tutorial.collab.ipynb.
Converted 50_tutorial.datablock.ipynb.
Converted 60_medical.imaging.ipynb.
Converted 61_tutorial.medical_imaging.ipynb.
Converted 65_medical.text.ipynb.
Converted 70_callback.wandb.ipynb.
Converted 71_callback.tensorboard.ipynb.
Converted 72_callback.neptune.ipynb.
Converted 73_callback.captum.ipynb.
Converted 74_callback.azureml.ipynb.
Converted 97_test_utils.ipynb.
Converted 99_pytorch_doc.ipynb.
Converted dev-setup.ipynb.
Converted app_examples.ipynb.
Converted camvid.ipynb.
Converted migrating_catalyst.ipynb.
Converted migrating_ignite.ipynb.
Converted migrating_lightning.ipynb.
Converted migrating_pytorch.ipynb.
Converted migrating_pytorch_verbose.ipynb.
Converted ulmfit.ipynb.
Converted index.ipynb.
Converted index_original.ipynb.
Converted quick_start.ipynb.
Converted tutorial.ipynb.