! [ -e /content ] && pip install -Uqq fastai # 在Colab上升级fastai学习者,指标,回调
from __future__ import annotations
from fastai.data.all import *
from fastai.optimizer import *
from fastai.callback.core import *
import pickle,threading
from collections.abc import MutableSequencefrom nbdev.showdoc import *_all_ = ['CancelBackwardException', 'CancelStepException','CancelFitException','CancelEpochException',
'CancelTrainException','CancelValidException','CancelBatchException']处理训练循环的基本类
您可能想直接跳转到Learner的定义。
工具函数
#用于测试
from torch.utils.data import TensorDataset, DataLoader as TorchDLdef synth_dbunch(a=2, b=3, bs=16, n_train=10, n_valid=2, cuda=False, tfmdDL=True):
"A simple dataset where `x` is random and `y = a*x + b` plus some noise."
def get_data(n):
x = torch.randn(int(bs*n))
return TensorDataset(x, a*x + b + 0.1*torch.randn(int(bs*n)))
train_ds = get_data(n_train)
valid_ds = get_data(n_valid)
device = default_device() if cuda else None
if tfmdDL:
train_dl = TfmdDL(train_ds, bs=bs, shuffle=True, num_workers=0, drop_last=True)
valid_dl = TfmdDL(valid_ds, bs=bs, num_workers=0)
else:
train_dl = TorchDL(train_ds, batch_size=bs, shuffle=True, num_workers=0, drop_last=True)
valid_dl = TorchDL(valid_ds, batch_size=bs, num_workers=0)
device = None
return DataLoaders(train_dl, valid_dl, device=device)
class RegModel(Module):
"A r"
def __init__(self): self.a,self.b = nn.Parameter(torch.randn(1)),nn.Parameter(torch.randn(1))
def forward(self, x): return x*self.a + self.bdefaults.lr = 1e-3def replacing_yield(o, attr, val):
"Context manager to temporarily replace an attribute"
old = getattr(o,attr)
try: yield setattr(o,attr,val)
finally: setattr(o,attr,old)class _A:
def __init__(self, a): self.a = a
@contextmanager
def a_changed(self, v): return replacing_yield(self, 'a', v)
a = _A(42)
with a.a_changed(32):
test_eq(a.a, 32)
test_eq(a.a, 42)def mk_metric(m):
"Convert `m` to an `AvgMetric`, unless it's already a `Metric`"
if isinstance(m,type): m = m()
return m if isinstance(m, Metric) else AvgMetric(m)请参见下面的Metric类以获取更多信息。
def save_model(file, model, opt, with_opt=True, pickle_protocol=2, **torch_save_kwargs):
"Save `model` to `file` along with `opt` (if available, and if `with_opt`)"
if rank_distrib(): return # don't save if child proc
if opt is None: with_opt=False
state = get_model(model).state_dict()
if with_opt: state = {'model': state, 'opt':opt.state_dict()}
torch.save(state, file, pickle_protocol=pickle_protocol, **torch_save_kwargs)file 可以是一个 Path 对象、一个字符串或一个已打开的文件对象。pickle_protocol 和 torch_save_kwargs 将传递给 torch.save。
def load_model(file, model, opt, with_opt=True, device=None, strict=True, **torch_load_kwargs):
"Load `model` from `file` along with `opt` (if available, and if `with_opt`)"
if isinstance(device, int): device = torch.device('cuda', device)
elif device is None: device = 'cpu'
state = torch.load(file, map_location=device, **torch_load_kwargs)
hasopt = set(state)=={'model', 'opt'}
model_state = state['model'] if hasopt else state
get_model(model).load_state_dict(model_state, strict=strict)
if hasopt and with_opt:
try: opt.load_state_dict(state['opt'])
except:
if with_opt: warn("Could not load the optimizer state.")
elif with_opt: warn("Saved file doesn't contain an optimizer state.")file 可以是 Path 对象、字符串或已打开的文件对象。如果传入 device,模型将加载到该设备上,否则将加载到 CPU 上。
如果 strict 为 True,文件必须准确包含 model 中每个参数键的权重;如果 strict 为 False,则只加载保存在模型中的键到 model。
您可以通过 torch_load_kwargs 传递其他参数给 torch.load。
def _try_concat(o):
try: return torch.cat(o)
except: return sum([L(o_[i,:] for i in range_of(o_)) for o_ in o], L())_before_epoch = [event.before_fit, event.before_epoch]
_after_epoch = [event.after_epoch, event.after_fit]class _ConstantFunc():
"Returns a function that returns `o`"
def __init__(self, o): self.o = o
def __call__(self, *args, **kwargs): return self.oclass SkipToEpoch(Callback):
"Skip training up to `epoch`"
order = 70
def __init__(self, epoch:int):
self._skip_to = epoch
def before_epoch(self):
if self.epoch < self._skip_to:
raise CancelEpochException学习者 -
_loop = ['Start Fit', 'before_fit', 'Start Epoch Loop', 'before_epoch', 'Start Train', 'before_train',
'Start Batch Loop', 'before_batch', 'after_pred', 'after_loss', 'before_backward', 'before_step',
'after_step', 'after_cancel_batch', 'after_batch','End Batch Loop','End Train',
'after_cancel_train', 'after_train', 'Start Valid', 'before_validate','Start Batch Loop',
'**CBs same as train batch**', 'End Batch Loop', 'End Valid', 'after_cancel_validate',
'after_validate', 'End Epoch Loop', 'after_cancel_epoch', 'after_epoch', 'End Fit',
'after_cancel_fit', 'after_fit']class Learner(GetAttr):
_default='model'
def __init__(self,
dls:DataLoaders, # 包含fastai或PyTorch `DataLoader`的`DataLoaders`
model:callable, # 用于训练或推理的PyTorch模型
loss_func:callable|None=None, # 损失函数。默认为 `dls` 损失
opt_func:Optimizer|OptimWrapper=Adam, # 训练优化函数
lr:float|slice=defaults.lr, # 默认学习率
splitter:callable=trainable_params, # 将模型参数分组。默认为一组参数
cbs:Callback|MutableSequence|None=None, # 添加到 `Learner` 的 `Callback`
metrics:callable|MutableSequence|None=None, # 在验证集上计算的`指标`
path:str|Path|None=None, # 用于保存、加载和导出模型的父目录。默认为 `dls` 的 `path`。
model_dir:str|Path='models', # 保存和加载模型的子目录
wd:float|int|None=None, # 默认权重衰减
wd_bn_bias:bool=False, # 对归一化参数和偏置参数应用权重衰减
train_bn:bool=True, # 冻结归一化层
moms:tuple=(0.95,0.85,0.95), # 调度器的默认动量
default_cbs:bool=True # 包含默认的 `Callback`
):
path = Path(path) if path is not None else getattr(dls, 'path', Path('.'))
if loss_func is None:
loss_func = getattr(dls.train_ds, 'loss_func', None)
assert loss_func is not None, "Could not infer loss function from the data, please pass a loss function."
self.dls,self.model = dls,model
store_attr(but='dls,model,cbs')
self.training,self.create_mbar,self.logger,self.opt,self.cbs = False,True,print,None,L()
if default_cbs: self.add_cbs(L(defaults.callbacks))
self.add_cbs(cbs)
self.lock = threading.Lock()
self("after_create")
@property
def metrics(self): return self._metrics
@metrics.setter
def metrics(self,v): self._metrics = L(v).map(mk_metric)
def _grab_cbs(self, cb_cls): return L(cb for cb in self.cbs if isinstance(cb, cb_cls))
def add_cbs(self, cbs):
L(cbs).map(self.add_cb)
return self
def remove_cbs(self, cbs):
L(cbs).map(self.remove_cb)
return self
def add_cb(self, cb):
if isinstance(cb, type): cb = cb()
cb.learn = self
setattr(self, cb.name, cb)
self.cbs.append(cb)
return self
def remove_cb(self, cb):
if isinstance(cb, type): self.remove_cbs(self._grab_cbs(cb))
else:
cb.learn = None
if hasattr(self, cb.name): delattr(self, cb.name)
if cb in self.cbs: self.cbs.remove(cb)
return self
@contextmanager
def added_cbs(self, cbs):
self.add_cbs(cbs)
try: yield
finally: self.remove_cbs(cbs)
@contextmanager
def removed_cbs(self, cbs):
self.remove_cbs(cbs)
try: yield self
finally: self.add_cbs(cbs)
def ordered_cbs(self, event): return [cb for cb in self.cbs.sorted('order') if hasattr(cb, event)]
def __call__(self, event_name): L(event_name).map(self._call_one)
def _call_one(self, event_name):
if not hasattr(event, event_name): raise Exception(f'missing {event_name}')
for cb in self.cbs.sorted('order'): cb(event_name)
def _bn_bias_state(self, with_bias): return norm_bias_params(self.model, with_bias).map(self.opt.state)
def create_opt(self):
if isinstance(self.opt_func, partial):
if 'lr' in self.opt_func.keywords:
self.lr = self.opt_func.keywords['lr']
if isinstance(self.opt_func, OptimWrapper):
self.opt = self.opt_func
self.opt.clear_state()
else:
self.opt = self.opt_func(self.splitter(self.model), lr=self.lr)
if not self.wd_bn_bias:
for p in self._bn_bias_state(True ): p['do_wd'] = False
if self.train_bn:
for p in self._bn_bias_state(False): p['force_train'] = True
def _split(self, b):
i = getattr(self.dls, 'n_inp', 1 if len(b)==1 else len(b)-1)
self.xb,self.yb = b[:i],b[i:]
def _with_events(self, f, event_type, ex, final=noop):
try: self(f'before_{event_type}'); f()
except ex: self(f'after_cancel_{event_type}')
self(f'after_{event_type}'); final()
def all_batches(self):
self.n_iter = len(self.dl)
for o in enumerate(self.dl): self.one_batch(*o)
def _backward(self): self.loss_grad.backward()
def _step(self): self.opt.step()
def _do_grad_opt(self):
self._with_events(self._backward, 'backward', CancelBackwardException)
self._with_events(self._step, 'step', CancelStepException)
self.opt.zero_grad()
def _do_one_batch(self):
self.pred = self.model(*self.xb)
self('after_pred')
if len(self.yb):
self.loss_grad = self.loss_func(self.pred, *self.yb)
self.loss = self.loss_grad.clone()
self('after_loss')
if not self.training or not len(self.yb): return
self._do_grad_opt()
def _set_device(self, b):
model_device = next(self.model.parameters()).device
dls_device = getattr(self.dls, 'device', default_device())
if model_device == dls_device: return to_device(b, dls_device)
else: return to_device(b, model_device)
def one_batch(self, i, b):
self.iter = i
b = self._set_device(b)
self._split(b)
self._with_events(self._do_one_batch, 'batch', CancelBatchException)
def _do_epoch_train(self):
self.dl = self.dls.train
self._with_events(self.all_batches, 'train', CancelTrainException)
def _do_epoch_validate(self, ds_idx=1, dl=None):
if dl is None: dl = self.dls[ds_idx]
self.dl = dl
with torch.no_grad(): self._with_events(self.all_batches, 'validate', CancelValidException)
def _do_epoch(self):
self._do_epoch_train()
self._do_epoch_validate()
def _do_fit(self):
for epoch in range(self.n_epoch):
self.epoch=epoch
self._with_events(self._do_epoch, 'epoch', CancelEpochException)
def fit(self, n_epoch, lr=None, wd=None, cbs=None, reset_opt=False, start_epoch=0):
if start_epoch != 0:
cbs = L(cbs) + SkipToEpoch(start_epoch)
with self.added_cbs(cbs):
if reset_opt or not self.opt: self.create_opt()
if wd is None: wd = self.wd
if wd is not None: self.opt.set_hypers(wd=wd)
self.opt.set_hypers(lr=self.lr if lr is None else lr)
self.n_epoch = n_epoch
self._with_events(self._do_fit, 'fit', CancelFitException, self._end_cleanup)
def _end_cleanup(self): self.dl,self.xb,self.yb,self.pred,self.loss = None,(None,),(None,),None,None
def __enter__(self): self(_before_epoch); return self
def __exit__(self, exc_type, exc_value, tb): self(_after_epoch)
def validation_context(self, cbs=None, inner=False):
cms = [self.no_logging(),self.no_mbar(), self.lock]
if cbs: cms.append(self.added_cbs(cbs))
if not inner: cms.append(self)
return ContextManagers(cms)
def validate(self, ds_idx=1, dl=None, cbs=None):
if dl is None: dl = self.dls[ds_idx]
with self.validation_context(cbs=cbs): self._do_epoch_validate(ds_idx, dl)
return getattr(self, 'final_record', None)
@delegates(GatherPredsCallback.__init__)
def get_preds(self,
ds_idx:int=1, # 如果 `dl` 为 None,用于预测的 `DataLoader`。0:训练集。1:验证集。
dl=None, # 用于预测的`DataLoader`,如果未指定,则默认为`ds_idx=1`
with_input:bool=False, # 返回带有预测的输入
with_decoded:bool=False, # 返回解码后的预测结果
with_loss:bool=False, # 每项损失的回报与预测
act=None, # Apply activation to predictions, defaults to `self.loss_func`'s activation
inner:bool=False, # If False, create progress bar, show logger, use temporary `cbs`
reorder:bool=True, # Reorder predictions on dataset indicies, if applicable
cbs:Callback|MutableSequence|None=None, # Temporary `Callback`s to apply during prediction
**kwargs
)-> tuple:
if dl is None: dl = self.dls[ds_idx].new(shuffle=False, drop_last=False)
else:
try: len(dl)
except TypeError as e:
raise TypeError(f"`dl` is {type(dl)} and doesn't have len(dl)")
if isinstance(dl, DataLoader):
if dl.drop_last: dl = dl.new(shuffle=False, drop_last=False)
if reorder and hasattr(dl, 'get_idxs'):
idxs = dl.get_idxs()
dl = dl.new(get_idxs = _ConstantFunc(idxs))
cb = GatherPredsCallback(with_input=with_input, with_loss=with_loss, **kwargs)
ctx_mgrs = self.validation_context(cbs=L(cbs)+[cb], inner=inner)
if with_loss: ctx_mgrs.append(self.loss_not_reduced())
with ContextManagers(ctx_mgrs):
self._do_epoch_validate(dl=dl)
if act is None: act = getcallable(self.loss_func, 'activation')
res = cb.all_tensors()
pred_i = 1 if with_input else 0
if res[pred_i] is not None:
res[pred_i] = act(res[pred_i])
if with_decoded: res.insert(pred_i+2, getcallable(self.loss_func, 'decodes')(res[pred_i]))
if reorder and hasattr(dl, 'get_idxs'): res = nested_reorder(res, tensor(idxs).argsort())
return tuple(res)
self._end_cleanup()
def predict(self, item, rm_type_tfms=None, with_input=False):
dl = self.dls.test_dl([item], rm_type_tfms=rm_type_tfms, num_workers=0)
inp,preds,_,dec_preds = self.get_preds(dl=dl, with_input=True, with_decoded=True)
i = getattr(self.dls, 'n_inp', -1)
inp = (inp,) if i==1 else tuplify(inp)
dec = self.dls.decode_batch(inp + tuplify(dec_preds))[0]
dec_inp,dec_targ = map(detuplify, [dec[:i],dec[i:]])
res = dec_targ,dec_preds[0],preds[0]
if with_input: res = (dec_inp,) + res
return res
def show_results(self, ds_idx=1, dl=None, max_n=9, shuffle=True, **kwargs):
if dl is None: dl = self.dls[ds_idx].new(shuffle=shuffle)
b = dl.one_batch()
_,_,preds = self.get_preds(dl=[b], with_decoded=True)
dl.show_results(b, preds, max_n=max_n, **kwargs)
def show_training_loop(self):
indent = 0
for s in _loop:
if s.startswith('Start'): print(f'{" "*indent}{s}'); indent += 2
elif s.startswith('End'): indent -= 2; print(f'{" "*indent}{s}')
else: print(f'{" "*indent} - {s:15}:', self.ordered_cbs(s))
@contextmanager
def no_logging(self): return replacing_yield(self, 'logger', noop)
@contextmanager
def no_mbar(self): return replacing_yield(self, 'create_mbar', False)
@contextmanager
def loss_not_reduced(self):
if hasattr(self.loss_func, 'reduction'): return replacing_yield(self.loss_func, 'reduction', 'none')
else: return replacing_yield(self, 'loss_func', partial(self.loss_func, reduction='none'))
def to_detach(self,b,cpu=True,gather=True):
return self.dl.to_detach(b,cpu,gather) if hasattr(getattr(self,'dl',None),'to_detach') else to_detach(b,cpu,gather)
def __getstate__(self): return {k:v for k,v in self.__dict__.items() if k!='lock'}
def __setstate__(self, state):
self.__dict__.update(state)
self.lock = threading.Lock()
Learner.x,Learner.y = add_props(lambda i,x: detuplify((x.xb,x.yb)[i]))add_docs(Learner, "Group together a `model`, some `dls` and a `loss_func` to handle training",
add_cbs="Add `cbs` to the list of `Callback` and register `self` as their learner",
add_cb="Add `cb` to the list of `Callback` and register `self` as their learner",
remove_cbs="Remove `cbs` from the list of `Callback` and deregister `self` as their learner",
remove_cb="Add `cb` from the list of `Callback` and deregister `self` as their learner",
added_cbs="Context manage that temporarily adds `cbs`",
removed_cbs="Context manage that temporarily removes `cbs`",
ordered_cbs="List of `Callback`s, in order, for an `event` in the training loop",
create_opt="Create an optimizer with default hyper-parameters",
one_batch="Train or evaluate `self.model` on batch `(xb,yb)`",
all_batches="Train or evaluate `self.model` on all the batches of `self.dl`",
fit="Fit `self.model` for `n_epoch` using `cbs`. Optionally `reset_opt`.",
validate="Validate on `dl` with potential new `cbs`.",
get_preds="Get the predictions and targets on the `ds_idx`-th dbunchset or `dl`, optionally `with_input` and `with_loss`",
predict="Prediction on `item`, fully decoded, loss function decoded and probabilities",
validation_context="A `ContextManagers` suitable for validation, with optional `cbs`",
show_results="Show some predictions on `ds_idx`-th dataset or `dl`",
show_training_loop="Show each step in the training loop",
no_logging="Context manager to temporarily remove `logger`",
no_mbar="Context manager to temporarily prevent the master progress bar from being created",
loss_not_reduced="A context manager to evaluate `loss_func` with reduction set to none.",
to_detach="Calls `to_detach` if `self.dl` provides a `.to_detach` function otherwise calls global `to_detach`",
__call__="Call `event_name` for all `Callback`s in `self.cbs`"
)show_doc(Learner)Learner
Learner (dls:DataLoaders, model:callable, loss_func:callable|None=None, opt_func:Optimizer|OptimWrapper=<function Adam>, lr:float|slice=0.001, splitter:callable=<function trainable_params>, cbs:Callback|MutableSequence|None=None, metrics:callable|MutableSequence|None=None, path:str|Path|None=None, model_dir:str|Path='models', wd:float|int|None=None, wd_bn_bias:bool=False, train_bn:bool=True, moms:tuple=(0.95, 0.85, 0.95), default_cbs:bool=True)
Group together a model, some dls and a loss_func to handle training
| Type | Default | Details | |
|---|---|---|---|
| dls | DataLoaders | DataLoaders containing fastai or PyTorch DataLoaders |
|
| model | callable | PyTorch model for training or inference | |
| loss_func | callable | None | None | Loss function. Defaults to dls loss |
| opt_func | Optimizer | OptimWrapper | Adam | Optimization function for training |
| lr | float | slice | 0.001 | Default learning rate |
| splitter | callable | trainable_params | Split model into parameter groups. Defaults to one parameter group |
| cbs | Callback | MutableSequence | None | None | Callbacks to add to Learner |
| metrics | callable | MutableSequence | None | None | Metrics to calculate on validation set |
| path | str | Path | None | None | Parent directory to save, load, and export models. Defaults to dls path |
| model_dir | str | Path | models | Subdirectory to save and load models |
| wd | float | int | None | None | Default weight decay |
| wd_bn_bias | bool | False | Apply weight decay to normalization and bias parameters |
| train_bn | bool | True | Train frozen normalization layers |
| moms | tuple | (0.95, 0.85, 0.95) | Default momentum for schedulers |
| default_cbs | bool | True | Include default Callbacks |
opt_func 将在调用 Learner.fit 时用于创建优化器,默认学习率为 lr。 splitter 是一个函数,它接受 self.model 并返回参数组的列表(如果没有不同的参数组,则只返回一个参数组)。默认值是 trainable_params,返回模型的所有可训练参数。
cbs 是一个或多个要传递给 Learner 的 Callback。 Callback 用于训练循环的每个调整。每个 Callback 被注册为 Learner 的一个属性(使用驼峰式命名)。在创建时,defaults.callbacks 中的所有回调(TrainEvalCallback,Recorder 和 ProgressCallback)都会与 Learner 关联。
metrics 是一个可选的指标列表,可以是函数或 Metric(见下文)。
path 和 model_dir 用于保存和/或加载模型。通常,path 将从 dls 推断,但您可以覆盖它或将 Path 对象传递给 model_dir。确保您可以在 path/model_dir 中进行写入!
wd 是训练模型时使用的默认权重衰减;moms 是在 Learner.fit_one_cycle 中使用的默认动量。 wd_bn_bias 控制是否将权重衰减应用于 BatchNorm 层和偏置。
最后,train_bn 控制即使根据 splitter 规定应当被冻结,BatchNorm 层是否仍然被训练。我们的实证实验表明,在迁移学习中,这种行为是这些层的最佳选择。
PyTorch 互操作性
您可以使用常规的 PyTorch 功能来处理 Learner 的大多数参数,尽管使用纯 fastai 对象的体验会更流畅,并且您将能够使用库的全部功能。期望是训练循环即使没有使用 fastai 端到端也能顺利运行。您可能会失去的是解释对象或展示功能。下面的列表解释了如何为所有参数使用普通的 PyTorch 对象,以及您可能会失去的内容。
最重要的是 opt_func。如果您不使用 fastai 优化器,您将需要编写一个函数,将您的 PyTorch 优化器包装在 OptimWrapper 中。有关更多详细信息,请参见 优化器模块。这确保了库的调度程序/冻结 API 可以与您的代码一起工作。
dls是一个DataLoaders对象,您可以从标准的 PyTorch 数据加载器创建。这样做会导致您失去所有展示功能,例如show_batch/show_results。您可以查看 数据块 API 或 中级数据 API 教程 以了解如何使用 fastai 来收集您的数据!model是一个标准的 PyTorch 模型。您可以使用任何您喜欢的模型,只需确保它接受DataLoaders中的输入数量,并返回与目标数量相同的输出。loss_func可以是您喜欢的任何损失函数。如果您想使用Learn.predict或Learn.get_preds,它需要是 fastai 的损失函数之一,否则您将需要实现特殊方法(有关更多详细信息,请参见BaseLoss文档)。
训练循环
现在我们来看一下Learner类实现的主要内容:训练循环。
if not hasattr(defaults, 'callbacks'): defaults.callbacks = [TrainEvalCallback]show_doc(Learner.fit)Learner.fit
Learner.fit (n_epoch, lr=None, wd=None, cbs=None, reset_opt=False, start_epoch=0)
Fit self.model for n_epoch using cbs. Optionally reset_opt.
如果提供了lr和wd,则使用它们,否则使用Learner的lr和wd属性给出的默认值。
所有的示例都使用 synth_learner,这是一个简单的 Learner,用于训练线性回归模型。
def synth_learner(n_train=10, n_valid=2, cuda=False, tfmdDL=True, lr=defaults.lr, **kwargs):
data = synth_dbunch(n_train=n_train,n_valid=n_valid, cuda=cuda, tfmdDL=tfmdDL)
return Learner(data, RegModel(), loss_func=MSELossFlat(), lr=lr, **kwargs)#训练几个epoch应该会使模型变得更好
learn = synth_learner(lr=0.1)
learn(_before_epoch)
learn.model = learn.model.cpu()
xb,yb = learn.dls.one_batch()
init_loss = learn.loss_func(learn.model(xb), yb)
learn.fit(10)
xb,yb = learn.dls.one_batch()
final_loss = learn.loss_func(learn.model(xb), yb)
assert final_loss < init_loss, (final_loss,init_loss)#确保我们可以使用原始的PyTorch进行训练
learn = synth_learner(lr=0.1, tfmdDL=False)
learn(_before_epoch)
learn.model = learn.model.cpu()
xb,yb = next(iter(learn.dls[0]))
init_loss = learn.loss_func(learn.model(xb), yb)
learn.fit(10)
xb,yb = next(iter(learn.dls[0]))
learn.model = learn.model.cpu() # 确保即使在CUDA环境中我们仍然使用CPU
final_loss = learn.loss_func(learn.model(xb), yb)
assert final_loss < init_loss, (final_loss,init_loss)class TestTrainEvalCallback(Callback):
run_after,run_valid = TrainEvalCallback,False
def before_fit(self):
test_eq([self.pct_train,self.train_iter], [0., 0])
self.old_pct_train,self.old_train_iter = self.pct_train,self.train_iter
def before_batch(self): test_eq(next(self.parameters()).device, find_device(self.xb))
def after_batch(self):
assert self.training
test_eq(self.pct_train , self.old_pct_train+1/(self.n_iter*self.n_epoch))
test_eq(self.train_iter, self.old_train_iter+1)
self.old_pct_train,self.old_train_iter = self.pct_train,self.train_iter
def before_train(self):
assert self.training and self.model.training
test_eq(self.pct_train, self.epoch/self.n_epoch)
self.old_pct_train = self.pct_train
def before_validate(self):
assert not self.training and not self.model.training
learn = synth_learner(cbs=TestTrainEvalCallback)
learn.fit(1)
#检查顺序是否正确考虑
learn.cbs = L(reversed(learn.cbs))#|cuda
#检查模型是否在需要时被放置在GPU上
learn = synth_learner(cbs=TestTrainEvalCallback, cuda=True)
learn.fit(1)#|cuda
#确保原始数据加载器被放置在GPU上
learn = synth_learner(cbs=TestTrainEvalCallback, tfmdDL=False)
learn.fit(1)#检查当选项wd_bn_bias=False时,权重衰减(wd)未应用于bn/偏置项
class _TstModel(nn.Module):
def __init__(self):
super().__init__()
self.a,self.b = nn.Parameter(torch.randn(1)),nn.Parameter(torch.randn(1))
self.tst = nn.Sequential(nn.Linear(4,5), nn.BatchNorm1d(3))
self.tst[0].bias.data,self.tst[1].bias.data = torch.randn(5),torch.randn(3)
def forward(self, x): return x * self.a + self.b
class _PutGrad(Callback):
def before_step(self):
for p in self.learn.tst.parameters():
p.grad = torch.ones_like(p.data)
learn = synth_learner(n_train=5, opt_func = partial(SGD, wd=1, decouple_wd=True), cbs=_PutGrad)
learn.model = _TstModel()
init = [p.clone() for p in learn.tst.parameters()]
learn.fit(1, lr=1e-2)
end = list(learn.tst.parameters())
assert not torch.allclose(end[0]-init[0], -0.05 * torch.ones_like(end[0]))
for i in [1,2,3]: test_close(end[i]-init[i], -0.05 * torch.ones_like(end[i]))show_doc(Learner.one_batch)这是一个由 Learner.fit 调用的内部方法。如果传入,则 i 是该迭代在周期中的索引。在训练模式下,它会对该批次进行完整的训练步骤(计算预测、损失、梯度,更新模型参数并清零梯度)。在验证模式下,它在损失计算时停止。训练或验证由 TrainEvalCallback 通过 training 属性内部控制。
没有返回值,但 Learner 的属性 x、y、pred、loss 被设置为适当的值:
b = learn.dls.one_batch()
learn.one_batch(0, b)
test_eq(learn.x, b[0])
test_eq(learn.y, b[1])
out = learn.model(learn.x)
test_eq(learn.pred, out)
test_eq(learn.loss, learn.loss_func(out, b[1]))class VerboseCallback(Callback):
"Callback that prints the name of each event called"
def __call__(self, event_name):
print(event_name)
super().__call__(event_name)class TestOneBatch(VerboseCallback):
def __init__(self, xb, yb, i):
self.save_xb,self.save_yb,self.i = xb,yb,i
self.old_pred,self.old_loss = None,tensor(0.)
def before_batch(self):
self.old_a,self.old_b = self.a.data.clone(),self.b.data.clone()
test_eq(self.iter, self.i)
test_eq(self.save_xb, *self.xb)
test_eq(self.save_yb, *self.yb)
if hasattr(self.learn, 'pred'): test_eq(self.pred, self.old_pred)
def after_pred(self):
self.old_pred = self.pred
test_eq(self.pred, self.a.data * self.x + self.b.data)
test_eq(self.loss, self.old_loss)
def after_loss(self):
self.old_loss = self.loss
test_eq(self.loss, self.loss_func(self.old_pred, self.save_yb))
for p in self.parameters():
if not hasattr(p, 'grad') or p.grad is not None: test_eq(p.grad, tensor([0.]))
def before_step(self):
self.grad_a = (2 * self.x * (self.pred.data - self.y)).mean()
self.grad_b = 2 * (self.pred.data - self.y).mean()
test_close(self.a.grad.data, self.grad_a)
test_close(self.b.grad.data, self.grad_b)
test_eq(self.a.data, self.old_a)
test_eq(self.b.data, self.old_b)
def after_step(self):
test_close(self.a.data, self.old_a - self.lr * self.grad_a)
test_close(self.b.data, self.old_b - self.lr * self.grad_b)
self.old_a,self.old_b = self.a.data.clone(),self.b.data.clone()
test_close(self.a.grad.data, self.grad_a)
test_close(self.b.grad.data, self.grad_b)
def after_batch(self):
for p in self.parameters(): test_eq(p.grad, tensor([0.]))# 隐藏
learn = synth_learner()
b = learn.dls.one_batch()
learn = synth_learner(cbs=TestOneBatch(*b, 42), lr=1e-2)
#移除训练/评估
learn.cbs = learn.cbs[1:]
#设置
learn.loss,learn.training = tensor(0.),True
learn.opt = SGD(learn.parameters(), lr=learn.lr)
learn.model.train()
batch_events = ['before_batch', 'after_pred', 'after_loss', 'before_backward', 'after_backward', 'before_step', 'after_step', 'after_batch']
test_stdout(lambda: learn.one_batch(42, b), '\n'.join(batch_events))
test_stdout(lambda: learn.one_batch(42, b), '\n'.join(batch_events)) #检查第二批是否正常工作after_createshow_doc(Learner.all_batches)Learner.all_batches
Learner.all_batches ()
Train or evaluate self.model on all the batches of self.dl
learn = synth_learner(n_train=5, cbs=VerboseCallback())
learn.opt = SGD(learn.parameters(), lr=learn.lr)
with redirect_stdout(io.StringIO()):
learn(_before_epoch)
learn.epoch,learn.dl = 0,learn.dls.train
learn('before_train')
test_stdout(learn.all_batches, '\n'.join(batch_events * 5))
test_eq(learn.train_iter, 5)
valid_events = ['before_batch', 'after_pred', 'after_loss', 'after_batch']
with redirect_stdout(io.StringIO()):
learn.dl = learn.dls.valid
learn('before_validate')
test_stdout(learn.all_batches, '\n'.join(valid_events * 2))
test_eq(learn.train_iter, 5)after_createlearn = synth_learner(n_train=5, cbs=VerboseCallback())
test_stdout(lambda: learn(_before_epoch), 'before_fit\nbefore_epoch')
test_eq(learn.loss, tensor(0.))after_createlearn.opt = SGD(learn.parameters(), lr=learn.lr)
learn.epoch = 0
test_stdout(lambda: learn._do_epoch_train(), '\n'.join(['before_train'] + batch_events * 5 + ['after_train']))test_stdout(learn._do_epoch_validate, '\n'.join(['before_validate'] + valid_events * 2+ ['after_validate']))show_doc(Learner.create_opt)此方法在内部调用以创建优化器,超参数随后通过您传递给 Learner.fit 的内容或您特定的调度程序进行调整(见 callback.schedule)。
learn = synth_learner(n_train=5, cbs=VerboseCallback())
assert learn.opt is None
learn.create_opt()
assert learn.opt is not None
test_eq(learn.opt.hypers[0]['lr'], learn.lr)after_createlearn = synth_learner(n_train=5, cbs=VerboseCallback(), opt_func=partial(OptimWrapper, opt=torch.optim.Adam))
assert learn.opt is None
learn.create_opt()
assert learn.opt is not None
test_eq(learn.opt.hypers[0]['lr'], learn.lr)after_createwrapper_lr = 1
learn = synth_learner(n_train=5, cbs=VerboseCallback(), opt_func=partial(OptimWrapper, opt=torch.optim.Adam, lr=wrapper_lr))
assert learn.opt is None
learn.create_opt()
assert learn.opt is not None
test_eq(learn.opt.hypers[0]['lr'], wrapper_lr)after_create回调处理
我们在这里仅描述与 Callback 相关的基本功能。要了解更多关于 Callback 的信息以及如何编写它们,请查看 callback.core 模块文档。
让我们首先看看 Callback 是如何成为 Learner 的属性的:
#使用回调函数进行测试初始化
class TstCallback(Callback):
def batch_begin(self): self.learn.a = self.a + 1
tst_learn = synth_learner()
test_eq(len(tst_learn.cbs), 1)
assert hasattr(tst_learn, ('train_eval'))
tst_learn = synth_learner(cbs=TstCallback())
test_eq(len(tst_learn.cbs), 2)
assert hasattr(tst_learn, ('tst'))show_doc(Learner.__call__)这是Callback在内部被调用的方式。例如,VerboseCallback只是打印事件名称(这对于调试很有用):
learn = synth_learner(cbs=VerboseCallback())
learn('after_fit')after_create
after_fitshow_doc(Learner.add_cb)Learner.add_cb
Learner.add_cb (cb)
Add cb to the list of Callback and register self as their learner
learn = synth_learner()
learn.add_cb(TestTrainEvalCallback())
test_eq(len(learn.cbs), 2)
assert isinstance(learn.cbs[1], TestTrainEvalCallback)
test_eq(learn.train_eval.learn, learn)show_doc(Learner.add_cbs)Learner.add_cbs
Learner.add_cbs (cbs)
Add cbs to the list of Callback and register self as their learner
learn.add_cbs([TestTrainEvalCallback(), TestTrainEvalCallback()])
test_eq(len(learn.cbs), 4)show_doc(Learner.added_cbs)learn = synth_learner()
test_eq(len(learn.cbs), 1)
with learn.added_cbs(TestTrainEvalCallback()):
test_eq(len(learn.cbs), 2)show_doc(Learner.ordered_cbs)Learner.ordered_cbs
Learner.ordered_cbs (event)
List of Callbacks, in order, for an event in the training loop
通过顺序,我们指的是使用Callback的内部排序(有关其工作原理的更多信息,请参见callback.core)。
learn = synth_learner()
learn.add_cb(TestTrainEvalCallback())
learn.ordered_cbs('before_fit')[TrainEvalCallback, TestTrainEvalCallback]show_doc(Learner.remove_cb)Learner.remove_cb
Learner.remove_cb (cb)
Add cb from the list of Callback and deregister self as their learner
learn = synth_learner()
learn.add_cb(TestTrainEvalCallback())
cb = learn.cbs[1]
learn.remove_cb(learn.cbs[1])
test_eq(len(learn.cbs), 1)
assert cb.learn is None
assert not getattr(learn,'test_train_eval',None)cb 可以简单地是我们想要移除的 Callback 的类(在这种情况下,该回调的所有实例都会被移除)。
learn = synth_learner()
learn.add_cbs([TestTrainEvalCallback(), TestTrainEvalCallback()])
learn.remove_cb(TestTrainEvalCallback)
test_eq(len(learn.cbs), 1)
assert not getattr(learn,'test_train_eval',None)show_doc(Learner.remove_cbs)Learner.remove_cbs
Learner.remove_cbs (cbs)
Remove cbs from the list of Callback and deregister self as their learner
cbs 的元素可以是回调的类型,也可以是 Learner 的实际回调。
learn = synth_learner()
learn.add_cbs([TestTrainEvalCallback() for _ in range(3)])
cb = learn.cbs[1]
learn.remove_cbs(learn.cbs[1:])
test_eq(len(learn.cbs), 1)show_doc(Learner.removed_cbs)cbs 的元素可以是回调的类型或 Learner 的实际回调。
learn = synth_learner()
learn.add_cb(TestTrainEvalCallback())
with learn.removed_cbs(learn.cbs[1]):
test_eq(len(learn.cbs), 1)
test_eq(len(learn.cbs), 2)show_doc(Learner.show_training_loop)在每一步中,回调按顺序显示,这可以帮助调试。
learn = synth_learner()
learn.show_training_loop()Start Fit
- before_fit : [TrainEvalCallback]
Start Epoch Loop
- before_epoch : []
Start Train
- before_train : [TrainEvalCallback]
Start Batch Loop
- before_batch : []
- after_pred : []
- after_loss : []
- before_backward: []
- before_step : []
- after_step : []
- after_cancel_batch: []
- after_batch : [TrainEvalCallback]
End Batch Loop
End Train
- after_cancel_train: []
- after_train : []
Start Valid
- before_validate: [TrainEvalCallback]
Start Batch Loop
- **CBs same as train batch**: []
End Batch Loop
End Valid
- after_cancel_validate: []
- after_validate : []
End Epoch Loop
- after_cancel_epoch: []
- after_epoch : []
End Fit
- after_cancel_fit: []
- after_fit : []def _before_batch_cb(f, self):
xb,yb = f(self, self.xb, self.yb)
self.learn.xb,self.learn.yb = xb,ybdef before_batch_cb(f):
"Shortcut for creating a Callback on the `before_batch` event, which takes and returns `xb,yb`"
return Callback(before_batch=partial(_before_batch_cb, f))为了更改传递给模型的数据,您通常需要在 before_batch 事件中进行钩子,如下所示:
class TstCallback(Callback):
def before_batch(self):
self.learn.xb = self.xb + 1000
self.learn.yb = self.yb - 1000由于这非常常见,我们提供了 before_batch_cb 装饰器以便于使用。
@before_batch_cb
def cb(self, xb, yb): return xb+1000,yb-1000# 测试跳过至纪元回调
class TestSkipToEpoch(Callback):
def after_train(self):
assert self.epoch >= 2
learn = synth_learner(cbs=TestSkipToEpoch())
learn.fit(4, start_epoch=2)
learn = synth_learner()
p0_pre = first(learn.model.parameters()).data.clone()
learn.fit(3, start_epoch=3)
p0 = first(learn.model.parameters()).data
test_eq(p0_pre, p0)序列化
@patch
@delegates(save_model)
def save(self:Learner, file, **kwargs):
"Save model and optimizer state (if `with_opt`) to `self.path/self.model_dir/file`"
file = join_path_file(file, self.path/self.model_dir, ext='.pth')
save_model(file, self.model, getattr(self,'opt',None), **kwargs)
return filefile可以是Path、字符串或缓冲区。pickle_protocol参数会传递给torch.save。
@patch
@delegates(load_model)
def load(self:Learner, file, device=None, **kwargs):
"Load model and optimizer state (if `with_opt`) from `self.path/self.model_dir/file` using `device`"
if device is None and hasattr(self.dls, 'device'): device = self.dls.device
if self.opt is None: self.create_opt()
file = join_path_file(file, self.path/self.model_dir, ext='.pth')
distrib_barrier()
load_model(file, self.model, self.opt, device=device, **kwargs)
return selffile 可以是 Path、string 或缓冲区。使用 device 可以在与保存时不同的设备上加载模型/优化器状态。
with tempfile.TemporaryDirectory() as d:
learn = synth_learner(path=d)
learn.fit(1)
#测试保存创建了一个文件
learn.save('tmp')
assert (Path(d)/'models/tmp.pth').exists()
#测试加载确实加载了模型
learn1 = synth_learner(path=d)
learn1 = learn1.load('tmp')
test_eq(learn.a, learn1.a)
test_eq(learn.b, learn1.b)
test_eq(learn.opt.state_dict(), learn1.opt.state_dict())#当模型保存时不带优化器,测试负载有效
with tempfile.TemporaryDirectory() as d:
learn = synth_learner(path=d)
learn.fit(1)
learn.save('tmp', with_opt=False)
learn1 = synth_learner(path=d)
learn1 = learn1.load('tmp', with_opt=False)
test_eq(learn.a, learn1.a)
test_eq(learn.b, learn1.b)
test_ne(learn.opt.state_dict(), learn1.opt.state_dict())@patch
def export(self:Learner, fname='export.pkl', pickle_module=pickle, pickle_protocol=2):
"Export the content of `self` without the items and the optimizer state for inference"
if rank_distrib(): return # 如果子进程未导出
self._end_cleanup()
old_dbunch = self.dls
self.dls = self.dls.new_empty()
state = self.opt.state_dict() if self.opt is not None else None
self.opt = None
with warnings.catch_warnings():
#为了避免PyTorch关于模型未被检查的警告
warnings.simplefilter("ignore")
torch.save(self, self.path/fname, pickle_module=pickle_module, pickle_protocol=pickle_protocol)
self.create_opt()
if state is not None: self.opt.load_state_dict(state)
self.dls = old_dbunchLearner 被保存在 self.path/fname 中,使用 pickle_protocol。请注意,Python 中的序列化保存的是函数的名称,而不是代码本身。因此,您为模型、数据转换、损失函数等编写的任何自定义代码应放在一个模块中,您将在导出之前在训练环境中导入,并在加载之前在部署环境中导入。
def load_learner(fname, cpu=True, pickle_module=pickle):
"Load a `Learner` object in `fname`, by default putting it on the `cpu`"
distrib_barrier()
map_loc = 'cpu' if cpu else default_device()
try: res = torch.load(fname, map_location=map_loc, pickle_module=pickle_module)
except AttributeError as e:
e.args = [f"Custom classes or functions exported with your `Learner` not available in namespace. Re-declare/import before loading:\n\t{e.args[0]}"]
raise
if cpu:
res.dls.cpu()
if hasattr(res, 'channels_last'): res = res.to_contiguous(to_fp32=True)
elif hasattr(res, 'mixed_precision'): res = res.to_fp32()
elif hasattr(res, 'non_native_mixed_precision'): res = res.to_non_native_fp32()
return res
Warning
load_learner 要求您所有的自定义代码与导出您的 Learner 时的位置完全相同(即主脚本或您导入它的模块)。
数据加载器感知的 to_detach -
show_doc(Learner.to_detach)Learner.to_detach
Learner.to_detach (b, cpu=True, gather=True)
Calls to_detach if self.dl provides a .to_detach function otherwise calls global to_detach
fastai 提供了 to_detach,默认情况下会分离张量的梯度,并在以分布式数据并行(DDP)模式运行时从所有完成的进程中收集张量(调用 maybe_gather)。
在 DDP 模式下,所有进程需要具有相同的批大小,而 DistributedDL 负责根据需要填充批次;然而,在收集所有张量时(例如计算指标、推理等),我们需要丢弃填充的项目。DistributedDL 提供了一个方法 to_detach,该方法可以适当地去除填充项。
调用学习者的 to_detach 方法将尝试在学习者最后使用的 DataLoader dl 中查找 to_detach 方法,如果找到,则使用该方法,否则将回退到原生的 to_detach。
learn = synth_learner()
test_eq(learn.to_detach(Tensor([123])),Tensor([123]))
learn.dl = learn.dls[0]
test_eq(learn.to_detach(Tensor([123])),Tensor([123]))
learn.dl.to_detach = lambda b,cpu,gather: b-100
test_eq(learn.to_detach(Tensor([123.])),Tensor([23.]))指标 -
@docs
class Metric():
"Blueprint for defining a metric"
def reset(self): pass
def accumulate(self, learn): pass
@property
def value(self): raise NotImplementedError
@property
def name(self): return class2attr(self, 'Metric')
_docs = dict(
reset="Reset inner state to prepare for new computation",
name="Name of the `Metric`, camel-cased and with Metric removed",
accumulate="Use `learn` to update the state with new results",
value="The value of the metric")show_doc(Metric, title_level=3)指标可以是简单的平均值(如准确率),但有时它们的计算会更复杂,无法在批量上进行平均(如精确度或召回率),这就是我们需要一个特殊类的原因。对于可以作为批量上平均计算的简单函数,我们可以使用 AvgMetric 类,否则您需要实现以下方法。
Note
如果您的 Metric 具有依赖于张量的状态,请务必将其存储在 CPU 上,以避免任何潜在的内存泄漏。
show_doc(Metric.reset)show_doc(Metric.accumulate)show_doc(Metric.value, name='Metric.value')show_doc(Metric.name, name='Metric.name')class AvgMetric(Metric):
"Average the values of `func` taking into account potential different batch sizes"
def __init__(self, func): self.func = func
def reset(self): self.total,self.count = 0.,0
def accumulate(self, learn):
bs = find_bs(learn.yb)
self.total += learn.to_detach(self.func(learn.pred, *learn.yb))*bs
self.count += bs
@property
def value(self): return self.total/self.count if self.count != 0 else None
@property
def name(self): return self.func.func.__name__ if hasattr(self.func, 'func') else self.func.__name__show_doc(AvgMetric, title_level=3)AvgMetric
AvgMetric (func)
Average the values of func taking into account potential different batch sizes
learn = synth_learner()
tst = AvgMetric(lambda x,y: (x-y).abs().mean())
t,u = torch.randn(100),torch.randn(100)
tst.reset()
for i in range(0,100,25):
learn.pred,learn.yb = t[i:i+25],(u[i:i+25],)
tst.accumulate(learn)
test_close(tst.value, (t-u).abs().mean())#不同批次大小
tst.reset()
splits = [0, 30, 50, 60, 100]
for i in range(len(splits )-1):
learn.pred,learn.yb = t[splits[i]:splits[i+1]],(u[splits[i]:splits[i+1]],)
tst.accumulate(learn)
test_close(tst.value, (t-u).abs().mean())class AvgLoss(Metric):
"Average the losses taking into account potential different batch sizes"
def reset(self): self.total,self.count = 0.,0
def accumulate(self, learn):
bs = find_bs(learn.yb)
self.total += learn.to_detach(learn.loss.mean())*bs
self.count += bs
@property
def value(self): return self.total/self.count if self.count != 0 else None
@property
def name(self): return "loss"show_doc(AvgLoss, title_level=3)tst = AvgLoss()
t = torch.randn(100)
tst.reset()
for i in range(0,100,25):
learn.yb,learn.loss = t[i:i+25],t[i:i+25].mean()
tst.accumulate(learn)
test_close(tst.value, t.mean())#不同批次大小
tst.reset()
splits = [0, 30, 50, 60, 100]
for i in range(len(splits )-1):
learn.yb,learn.loss = t[splits[i]:splits[i+1]],t[splits[i]:splits[i+1]].mean()
tst.accumulate(learn)
test_close(tst.value, t.mean())class AvgSmoothLoss(Metric):
"Smooth average of the losses (exponentially weighted with `beta`)"
def __init__(self, beta=0.98): self.beta = beta
def reset(self): self.count,self.val = 0,tensor(0.)
def accumulate(self, learn):
self.count += 1
self.val = torch.lerp(to_detach(learn.loss.mean()), self.val, self.beta)
@property
def value(self): return self.val/(1-self.beta**self.count)show_doc(AvgSmoothLoss, title_level=3)AvgSmoothLoss
AvgSmoothLoss (beta=0.98)
Smooth average of the losses (exponentially weighted with beta)
tst = AvgSmoothLoss()
t = torch.randn(100)
tst.reset()
val = tensor(0.)
for i in range(4):
learn.loss = t[i*25:(i+1)*25].mean()
tst.accumulate(learn)
val = val*0.98 + t[i*25:(i+1)*25].mean()*(1-0.98)
test_close(val/(1-0.98**(i+1)), tst.value)class ValueMetric(Metric):
"Use to include a pre-calculated metric value (for instance calculated in a `Callback`) and returned by `func`"
def __init__(self, func, metric_name=None): store_attr('func, metric_name')
@property
def value(self): return self.func()
@property
def name(self): return self.metric_name if self.metric_name else self.func.__name__show_doc(ValueMetric, title_level=3)ValueMetric
ValueMetric (func, metric_name=None)
Use to include a pre-calculated metric value (for instance calculated in a Callback) and returned by func
def metric_value_fn(): return 5e-3
vm = ValueMetric(metric_value_fn, 'custom_value_metric')
test_eq(vm.value, 5e-3)
test_eq(vm.name, 'custom_value_metric')
vm = ValueMetric(metric_value_fn)
test_eq(vm.name, 'metric_value_fn')记录器 –
from fastprogress.fastprogress import format_timedef _maybe_item(t):
t = t.value
try: return t.item()
except: return tclass Recorder(Callback):
"Callback that registers statistics (lr, loss and metrics) during training"
_stateattrs=('lrs','iters','losses','values')
remove_on_fetch,order = True,50
def __init__(self, add_time=True, train_metrics=False, valid_metrics=True, beta=0.98):
store_attr('add_time,train_metrics,valid_metrics')
self.loss,self.smooth_loss = AvgLoss(),AvgSmoothLoss(beta=beta)
def before_fit(self):
"Prepare state for training"
self.lrs,self.iters,self.losses,self.values = [],[],[],[]
names = self.metrics.attrgot('name')
if self.train_metrics and self.valid_metrics:
names = L('loss') + names
names = names.map('train_{}') + names.map('valid_{}')
elif self.valid_metrics: names = L('train_loss', 'valid_loss') + names
else: names = L('train_loss') + names
if self.add_time: names.append('time')
self.metric_names = 'epoch'+names
self.smooth_loss.reset()
def after_batch(self):
"Update all metrics and records lr and smooth loss in training"
if len(self.yb) == 0: return
mets = self._train_mets if self.training else self._valid_mets
for met in mets: met.accumulate(self.learn)
if not self.training: return
self.lrs.append(self.opt.hypers[-1]['lr'])
self.losses.append(self.smooth_loss.value)
self.learn.smooth_loss = self.smooth_loss.value
def before_epoch(self):
"Set timer if `self.add_time=True`"
self.cancel_train,self.cancel_valid = False,False
if self.add_time: self.start_epoch = time.time()
self.log = L(getattr(self, 'epoch', 0))
def before_train (self): self._train_mets[1:].map(Self.reset())
def before_validate(self): self._valid_mets.map(Self.reset())
def after_train (self): self.log += self._train_mets.map(_maybe_item)
def after_validate(self): self.log += self._valid_mets.map(_maybe_item)
def after_cancel_train(self): self.cancel_train = True
def after_cancel_validate(self): self.cancel_valid = True
def after_epoch(self):
"Store and log the loss/metric values"
self.learn.final_record = self.log[1:].copy()
self.values.append(self.learn.final_record)
if self.add_time: self.log.append(format_time(time.time() - self.start_epoch))
self.logger(self.log)
self.iters.append(self.smooth_loss.count)
@property
def _train_mets(self):
if getattr(self, 'cancel_train', False): return L()
return L(self.smooth_loss) + (self.metrics if self.train_metrics else L())
@property
def _valid_mets(self):
if getattr(self, 'cancel_valid', False): return L()
return (L(self.loss) + self.metrics if self.valid_metrics else L())
def plot_loss(self, skip_start=5, with_valid=True, log=False, show_epochs=False, ax=None):
if not ax:
ax=plt.gca()
if log:
ax.loglog(list(range(skip_start, len(self.losses))), self.losses[skip_start:], label='train')
else:
ax.plot(list(range(skip_start, len(self.losses))), self.losses[skip_start:], label='train')
if show_epochs:
for x in self.iters:
ax.axvline(x, color='grey', ls=':')
ax.set_ylabel('loss')
ax.set_xlabel('steps')
ax.set_title('learning curve')
if with_valid:
idx = (np.array(self.iters)<skip_start).sum()
valid_col = self.metric_names.index('valid_loss') - 1
ax.plot(self.iters[idx:], L(self.values[idx:]).itemgot(valid_col), label='valid')
ax.legend()
return axadd_docs(Recorder,
before_train = "Reset loss and metrics state",
after_train = "Log loss and metric values on the training set (if `self.training_metrics=True`)",
before_validate = "Reset loss and metrics state",
after_validate = "Log loss and metric values on the validation set",
after_cancel_train = "Ignore training metrics for this epoch",
after_cancel_validate = "Ignore validation metrics for this epoch",
plot_loss = "Plot the losses from `skip_start` and onward. Optionally `log=True` for logarithmic axis, `show_epochs=True` for indicate epochs and a matplotlib axis `ax` to plot on.")
if Recorder not in defaults.callbacks: defaults.callbacks.append(Recorder)默认情况下,指标仅在验证集上计算,尽管可以通过调整 train_metrics 和 valid_metrics 来更改这一点。beta 是用于计算损失的指数加权平均的权重(这给 Learner 带来了 smooth_loss 属性)。
Learner 的 logger 属性决定了这些指标的处理方式。默认情况下,它只是打印这些指标:
#测试打印输出
def tst_metric(out, targ): return F.mse_loss(out, targ)
learn = synth_learner(n_train=5, metrics=tst_metric, default_cbs=False, cbs=[TrainEvalCallback, Recorder])
# pat = r"[tensor\(\d.\d*\), tensor\(\d.\d*\), tensor\(\d.\d*\), 'dd:dd']"
pat = r"\[\d, \d+.\d+, \d+.\d+, \d+.\d+, '\d\d:\d\d'\]"
test_stdout(lambda: learn.fit(1), pat, regex=True)class TestRecorderCallback(Callback):
order=51
def before_fit(self):
self.train_metrics,self.add_time = self.recorder.train_metrics,self.recorder.add_time
self.beta = self.recorder.smooth_loss.beta
for m in self.metrics: assert isinstance(m, Metric)
test_eq(self.recorder.smooth_loss.val, 0.)
#为了测试记录器记录的内容,我们使用了一个自定义的日志记录函数。
self.learn.logger = self.test_log
self.old_smooth,self.count = tensor(0.),0
def after_batch(self):
if self.training:
self.count += 1
test_eq(len(self.recorder.lrs), self.count)
test_eq(self.recorder.lrs[-1], self.opt.hypers[-1]['lr'])
test_eq(len(self.recorder.losses), self.count)
smooth = (1 - self.beta**(self.count-1)) * self.old_smooth * self.beta + self.loss * (1-self.beta)
smooth /= 1 - self.beta**self.count
test_close(self.recorder.losses[-1], smooth, eps=1e-4)
test_close(self.smooth_loss, smooth, eps=1e-4)
self.old_smooth = self.smooth_loss
self.bs += find_bs(self.yb)
if not self.training: test_eq(self.recorder.loss.count, self.bs)
if self.train_metrics or not self.training:
for m in self.metrics: test_eq(m.count, self.bs)
self.losses.append(self.loss.detach().cpu())
def before_epoch(self):
if self.add_time: self.start_epoch = time.time()
self.log = [self.epoch]
def before_train(self):
self.bs = 0
self.losses = []
for m in self.recorder._train_mets: test_eq(m.count, self.bs)
def after_train(self):
mean = tensor(self.losses).mean()
self.log += [self.smooth_loss, mean] if self.train_metrics else [self.smooth_loss]
test_close(self.log, self.recorder.log)
self.losses = []
def before_validate(self):
self.bs = 0
self.losses = []
for m in [self.recorder.loss] + self.metrics: test_eq(m.count, self.bs)
def test_log(self, log):
res = tensor(self.losses).mean()
self.log += [res, res]
if self.add_time: self.log.append(format_time(time.time() - self.start_epoch))
test_close(log[:-1], self.log[:-1])
test_eq(log[-1], self.log[-1])def _get_learn():
return synth_learner(n_train=5, metrics = tst_metric, default_cbs=False, cbs=[TrainEvalCallback, Recorder, TestRecorderCallback])
learn = _get_learn()
learn.fit(1)
test_eq(learn.recorder.metric_names, ['epoch', 'train_loss', 'valid_loss', 'tst_metric', 'time'])
learn = _get_learn()
learn.recorder.train_metrics=True
learn.fit(1)
test_eq(learn.recorder.metric_names,
['epoch', 'train_loss', 'train_tst_metric', 'valid_loss', 'valid_tst_metric', 'time'])
learn = _get_learn()
learn.recorder.add_time=False
learn.fit(1)
test_eq(learn.recorder.metric_names, ['epoch', 'train_loss', 'valid_loss', 'tst_metric'])#测试numpy指标
def tst_metric_np(out, targ): return F.mse_loss(out, targ).numpy()
learn = synth_learner(n_train=5, metrics=tst_metric_np)
learn.fit(1)[0, 6.6412787437438965, 9.520381927490234, 9.520381927490234, '00:00']内部结构
show_doc(Recorder.before_fit)show_doc(Recorder.before_epoch)show_doc(Recorder.before_validate)show_doc(Recorder.after_batch)Recorder.after_batch
Recorder.after_batch ()
Update all metrics and records lr and smooth loss in training
show_doc(Recorder.after_epoch)绘图工具
show_doc(Recorder.plot_loss)Recorder.plot_loss
Recorder.plot_loss (skip_start=5, with_valid=True)
Plot the losses from skip_start and onward
learn.recorder.plot_loss(skip_start=1)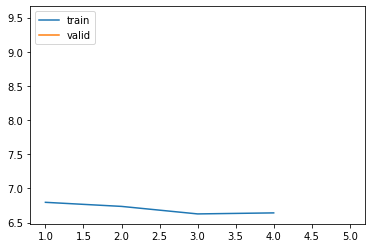
转换为张量 -
def _cast_tensor(x):
if isinstance(x, tuple): return tuple(_cast_tensor(x_) for x_ in x)
else: return cast(x, Tensor) if isinstance(x,torch.Tensor) else xclass CastToTensor(Callback):
"Cast Subclassed Tensors to `Tensor`"
order=9 # 就在混合精度之前
def before_batch(self):
self.learn.xb,self.learn.yb = _cast_tensor(self.learn.xb),_cast_tensor(self.learn.yb)针对PyTorch中的一个bug的解决方法,该bug导致子类张量(例如TensorBase)在传递到模型时训练速度比Tensor慢约20%。默认情况下已添加到Learner中。
CastToTensor的顺序在MixedPrecision之前,因此使用fastai的张量子类的回调仍然可以使用它们。
如果输入不是子类张量或张量元组,您可能需要通过自定义回调或者在Learner执行前向传播之前在数据加载器中将Learner.xb和Learner.yb中的输入转换为Tensor。
如果CastToTensor的解决方法干扰到自定义代码,可以将其移除:
learn = Learner(...)
learn.remove_cb(CastToTensor)如果移除CastToTensor,您应验证输入是否为Tensor类型,或通过自定义回调或数据加载器实现转换为Tensor。
if CastToTensor not in defaults.callbacks: defaults.callbacks.append(CastToTensor)推断函数
show_doc(Learner.validate)Learner.validate
Learner.validate (ds_idx=1, dl=None, cbs=None)
Validate on dl with potential new cbs.
#测试结果
learn = synth_learner(n_train=5, metrics=tst_metric)
res = learn.validate()
test_eq(res[0], res[1])
x,y = learn.dls.valid_ds.tensors
test_close(res[0], F.mse_loss(learn.model(x), y), 1e-3)#测试其他深度学习模型
res = learn.validate(dl=learn.dls.train)
test_eq(res[0], res[1])
x,y = learn.dls.train_ds.tensors
test_close(res[0], F.mse_loss(learn.model(x), y), 1e-3)show_doc(Learner.get_preds)Learner.get_preds
Learner.get_preds (ds_idx:int=1, dl:Union[fastai.data.core.TfmdDL,NoneType]=None, with_input:bool=False, with_decoded:bool=False, with_loss:bool=False, act:Any=None, inner:bool=False, reorder:bool=True, cbs:Union[list,NoneType]=None, save_preds:pathlib.Path=None, save_targs:pathlib.Path=None, with_preds:bool=True, with_targs:bool=True, concat_dim:int=0, pickle_protocol:int=2)
Get the predictions and targets on the ds_idx-th dbunchset or dl, optionally with_input and with_loss
| Type | Default | Details | |
|---|---|---|---|
| ds_idx | int | 1 | This takes the dataset index of DataLoader with default value as 1 for valid and 0 can be used for train |
| dl | TfmdDL | None | None | DataLoaders containing data for each dataset needed for model |
| with_input | bool | False | Whether to return inputs |
| with_decoded | bool | False | Whether to decode based on loss function passed |
| with_loss | bool | False | Whether to return losses |
| act | Any | None | Option to pass Activation function to predict function |
| inner | bool | False | Tells that it’s used internally used anywhere like in another training loop |
| reorder | bool | True | To order the tensors appropriately |
| cbs | list | None | None | Option to pass Callbacks to predict function |
| save_preds | Path | None | Path to save predictions |
| save_targs | Path | None | Path to save targets |
| with_preds | bool | True | Whether to return predictions |
| with_targs | bool | True | Whether to return targets |
| concat_dim | int | 0 | Dimension to concatenate returned tensors |
| pickle_protocol | int | 2 | Pickle protocol used to save predictions and targets |
| Returns | tuple |
with_decoded 还将使用损失函数的 <code>decodes</code> 函数(如果存在的话)返回解码后的预测。例如,fastai 的 CrossEntropyFlat 在其解码中使用 argmax 或预测。
根据 Learner 的 loss_func 属性,将自动选择一个激活函数,以使预测结果有意义。例如,如果损失是交叉熵的情况,将应用 softmax;或者如果损失是带逻辑的二元交叉熵,将应用 sigmoid。如果你想确保应用特定的激活函数,可以通过 act 进行传递。
当你的预测结果过大而无法完全放入内存时,应使用 save_preds 和 save_targs。提供一个指向文件夹的 Path 对象,该文件夹用于保存预测和目标。
concat_dim 是批次维度,所有张量将在此维度上连接。
inner 是一个内部属性,用于告诉 get_preds 它是在另一个训练循环内部被调用,以避免递归错误。
Note
如果您想在自定义损失函数中使用选项 with_loss=True,请确保您已经实现了支持 ‘none’ 的 reduction 属性。
#测试结果
learn = synth_learner(n_train=5, metrics=tst_metric)
preds,targs = learn.get_preds()
x,y = learn.dls.valid_ds.tensors
test_eq(targs, y)
test_close(preds, learn.model(x))
preds,targs = learn.get_preds(act = torch.sigmoid)
test_eq(targs, y)
test_close(preds, torch.sigmoid(learn.model(x)))#测试get_preds在数据集不能被批量大小整除的情况下是否正常工作
learn = synth_learner(n_train=2.5, metrics=tst_metric)
preds,targs = learn.get_preds(ds_idx=0)
#同时确保当数据加载器(dl)的drop_last参数为True时,此版本仍能正常工作
preds,targs = learn.get_preds(dl=learn.dls.train)#测试其他数据集
x = torch.randn(16*5)
y = 2*x + 3 + 0.1*torch.randn(16*5)
dl = TfmdDL(TensorDataset(x, y), bs=16)
preds,targs = learn.get_preds(dl=dl)
test_eq(targs, y)
test_close(preds, learn.model(x))
#测试与损失
preds,targs,losses = learn.get_preds(dl=dl, with_loss=True)
test_eq(targs, y)
test_close(preds, learn.model(x))
test_close(losses, F.mse_loss(preds, targs, reduction='none'))
#使用输入进行测试
inps,preds,targs = learn.get_preds(dl=dl, with_input=True)
test_eq(inps,x)
test_eq(targs, y)
test_close(preds, learn.model(x))#无目标测试
learn = synth_learner(n_train=5)
x = torch.randn(16*5)
dl = TfmdDL(TensorDataset(x), bs=16)
preds,targs = learn.get_preds(dl=dl)
assert targs is None#测试目标为元组的情况
def _fake_loss(x,y,z,reduction=None): return F.mse_loss(x,y)
learn = synth_learner(n_train=5)
x = torch.randn(16*5)
y = 2*x + 3 + 0.1*torch.randn(16*5)
learn.dls.n_inp=1
learn.loss_func = _fake_loss
dl = TfmdDL(TensorDataset(x, y, y), bs=16)
preds,targs = learn.get_preds(dl=dl)
test_eq(targs, [y,y])#测试输入为元组的情况
class _TupleModel(Module):
def __init__(self, model): self.model=model
def forward(self, x1, x2): return self.model(x1)
learn = synth_learner(n_train=5)
#学习.dls.n_inp=2
x = torch.randn(16*5)
y = 2*x + 3 + 0.1*torch.randn(16*5)
learn.model = _TupleModel(learn.model)
learn.dls = DataLoaders(TfmdDL(TensorDataset(x, x, y), bs=16),TfmdDL(TensorDataset(x, x, y), bs=16))
inps,preds,targs = learn.get_preds(ds_idx=0, with_input=True)
test_eq(inps, [x,x])
t = learn.get_preds(ds_idx=0, with_input=True)#测试自动激活功能已选择
learn = synth_learner(n_train=5)
learn.loss_func = BCEWithLogitsLossFlat()
x = torch.randn(16*5)
y = 2*x + 3 + 0.1*torch.randn(16*5)
dl = TfmdDL(TensorDataset(x, y), bs=16)
preds,targs = learn.get_preds(dl=dl)
test_close(preds, torch.sigmoid(learn.model(x)))#测试重新排序已完成
learn = synth_learner(n_train=5)
x = torch.randn(16*5)
y = 2*x + 3 + 0.1*torch.randn(16*5)
dl = TfmdDL(TensorDataset(x, y), bs=16, shuffle=True)
preds,targs = learn.get_preds(dl=dl)
test_eq(targs, y)inps,preds,targs = learn.get_preds(ds_idx=0, with_input=True)
tst = learn.get_preds(ds_idx=0, with_input=True, with_decoded=True)show_doc(Learner.predict)Learner.predict
Learner.predict (item, rm_type_tfms=None, with_input=False)
Prediction on item, fully decoded, loss function decoded and probabilities
它返回一个包含三个元素的元组,顺序为: - 模型的预测,可能经过损失函数的激活(如果有的话) - 使用它的潜在decodes方法解码的预测 - 使用构建Datasets/DataLoaders所使用的转换完全解码的预测
rm_type_tfms 是一个已弃用的参数,不应再使用,并将在未来的版本中被移除。 with_input 将把解码后的输入添加到结果中。
class _FakeLossFunc(Module):
reduction = 'none'
def forward(self, x, y): return F.mse_loss(x,y)
def activation(self, x): return x+1
def decodes(self, x): return 2*x
class _Add1(Transform):
def encodes(self, x): return x+1
def decodes(self, x): return x-1
learn = synth_learner(n_train=5)
dl = TfmdDL(Datasets(torch.arange(50), tfms = [L(), [_Add1()]]))
learn.dls = DataLoaders(dl, dl)
learn.loss_func = _FakeLossFunc()
inp = tensor([2.])
out = learn.model(inp).detach()+1 #应用模型与激活
dec = 2*out #从损失函数中解码
full_dec = dec-1 #从_Add1解码
test_eq(learn.predict(inp), [full_dec,dec,out])
test_eq(learn.predict(inp, with_input=True), [inp,full_dec,dec,out])show_doc(Learner.show_results)Learner.show_results
Learner.show_results (ds_idx=1, dl=None, max_n=9, shuffle=True, **kwargs)
Show some predictions on ds_idx-th dataset or dl
将显示max_n个样本(除非ds_idx或dl的批大小小于max_n,在这种情况下将显示尽可能多的样本),并且将对数据进行shuffle,除非您将false传递给该标志。kwargs是依赖于应用程序的。
我们无法在我们的合成Learner上显示示例,但请查看所有初学者教程,这些教程将向您展示该方法在各种应用中的工作原理。
本节中的最后几个函数用于内部推理,但对您来说应该用处不大。
show_doc(Learner.no_logging)learn = synth_learner(n_train=5, metrics=tst_metric)
with learn.no_logging():
test_stdout(lambda: learn.fit(1), '')
test_eq(learn.logger, print)show_doc(Learner.loss_not_reduced)这要求你的损失函数要么具有reduction属性,要么具有reduction参数(就像所有的fastai和PyTorch损失函数)。
test_eq(learn.loss_func.reduction, 'mean')
with learn.loss_not_reduced():
test_eq(learn.loss_func.reduction, 'none')
x,y = learn.dls.one_batch()
p = learn.model(x)
losses = learn.loss_func(p, y)
test_eq(losses.shape, y.shape)
test_eq(losses, F.mse_loss(p,y, reduction='none'))
test_eq(learn.loss_func.reduction, 'mean')迁移学习
@patch
def freeze_to(self:Learner, n):
if self.opt is None: self.create_opt()
self.opt.freeze_to(n)
self.opt.clear_state()
@patch
def freeze(self:Learner): self.freeze_to(-1)
@patch
def unfreeze(self:Learner): self.freeze_to(0)
add_docs(Learner,
freeze_to="Freeze parameter groups up to `n`",
freeze="Freeze up to last parameter group",
unfreeze="Unfreeze the entire model")class _TstModel(nn.Module):
def __init__(self):
super().__init__()
self.a,self.b = nn.Parameter(torch.randn(1)),nn.Parameter(torch.randn(1))
self.tst = nn.Sequential(nn.Linear(4,5), nn.BatchNorm1d(3))
self.tst[0].bias.data,self.tst[1].bias.data = torch.randn(5),torch.randn(3)
def forward(self, x): return x * self.a + self.b
class _PutGrad(Callback):
def before_step(self):
for p in self.learn.tst.parameters():
if p.requires_grad: p.grad = torch.ones_like(p.data)
def _splitter(m): return [list(m.tst[0].parameters()), list(m.tst[1].parameters()), [m.a,m.b]]
learn = synth_learner(n_train=5, opt_func = partial(SGD), cbs=_PutGrad, splitter=_splitter, lr=1e-2)
learn.model = _TstModel()
learn.freeze()
init = [p.clone() for p in learn.tst.parameters()]
learn.fit(1, wd=0.)
end = list(learn.tst.parameters())
#线性模型未经过训练
for i in [0,1]: test_close(end[i],init[i])
#bn 默认情况下,即使冻结,也会进行训练,因为 `train_bn=True`
for i in [2,3]: test_close(end[i]-init[i], -0.05 * torch.ones_like(end[i]))[0, 10.729637145996094, 8.939041137695312, '00:00']learn = synth_learner(n_train=5, opt_func = partial(SGD), cbs=_PutGrad, splitter=_splitter, train_bn=False, lr=1e-2)
learn.model = _TstModel()
learn.freeze()
init = [p.clone() for p in learn.tst.parameters()]
learn.fit(1, wd=0.)
end = list(learn.tst.parameters())
#linear 和 bn 未经过训练
for i in range(4): test_close(end[i],init[i])
learn.freeze_to(-2)
init = [p.clone() for p in learn.tst.parameters()]
learn.fit(1, wd=0.)
end = list(learn.tst.parameters())
#线性模型未经过训练
for i in [0,1]: test_close(end[i],init[i])
#bn 已经过训练
for i in [2,3]: test_close(end[i]-init[i], -0.05 * torch.ones_like(end[i]))
learn.unfreeze()
init = [p.clone() for p in learn.tst.parameters()]
learn.fit(1, wd=0.)
end = list(learn.tst.parameters())
#线性模型和BN模型已训练完成
for i in range(4): test_close(end[i]-init[i], -0.05 * torch.ones_like(end[i]), 1e-3)[0, 13.20148754119873, 13.554343223571777, '00:00']
[0, 11.017315864562988, 11.248431205749512, '00:00']
[0, 9.187033653259277, 9.335357666015625, '00:00']TTA
@patch
def tta(self:Learner, ds_idx=1, dl=None, n=4, item_tfms=None, batch_tfms=None, beta=0.25, use_max=False):
"Return predictions on the `ds_idx` dataset or `dl` using Test Time Augmentation"
if dl is None: dl = self.dls[ds_idx].new(shuffled=False, drop_last=False)
if item_tfms is not None or batch_tfms is not None: dl = dl.new(after_item=item_tfms, after_batch=batch_tfms)
try:
self(_before_epoch)
with dl.dataset.set_split_idx(0), self.no_mbar():
if hasattr(self,'progress'): self.progress.mbar = master_bar(list(range(n)))
aug_preds = []
for i in self.progress.mbar if hasattr(self,'progress') else range(n):
self.epoch = i #为了跟踪mbar的进度,因为进度回调将使用self.epoch
aug_preds.append(self.get_preds(dl=dl, inner=True)[0][None])
aug_preds = torch.cat(aug_preds)
aug_preds = aug_preds.max(0)[0] if use_max else aug_preds.mean(0)
self.epoch = n
with dl.dataset.set_split_idx(1): preds,targs = self.get_preds(dl=dl, inner=True)
finally: self(event.after_fit)
if use_max: return torch.stack([preds, aug_preds], 0).max(0)[0],targs
preds = (aug_preds,preds) if beta is None else torch.lerp(aug_preds, preds, beta)
return preds,targs在实际操作中,我们使用训练集的变换进行 n 次预测并对其结果进行平均。最终的预测结果为 (1-beta) 乘以这个平均值加上 beta 乘以使用数据集变换得到的预测结果。将 beta 设置为 None 可以得到预测结果和 tta 结果的元组。您还可以通过将 use_max=True 来使用所有预测中的最大值,而不是平均值。
如果您想使用新的变换,可以通过 item_tfms 和 batch_tfms 传递它们。
learn = synth_learner()
dl = TfmdDL(Datasets(torch.arange(50), [noop,noop]))
learn.dls = DataLoaders(dl, dl)
preds,targs = learn.tta()
assert len(preds),len(targs)导出 -
隐藏
from nbdev import nbdev_export
nbdev_export()