! [ -e /content ] && pip install -Uqq fastai # 在Colab上升级fastai训练 Imagenette
深入探索 fastai 在计算机视觉中的分层 API
fastai库具有分层API,如下图所示:
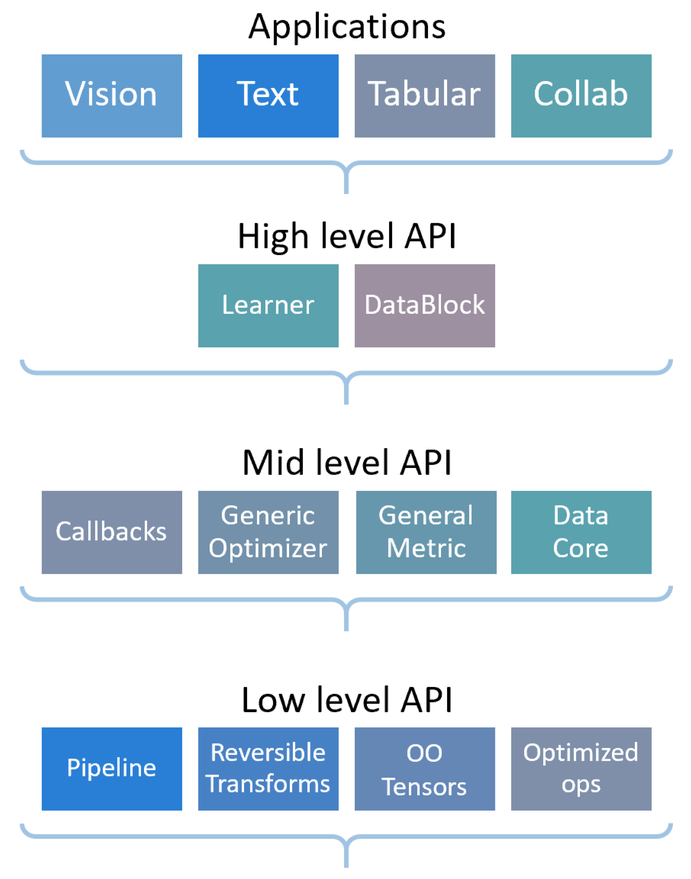
如果您正在按照本教程进行操作,您可能已经熟悉这些应用程序,在这里我们将看到它们是如何由高级和中级API驱动的。
Imagenette是ImageNet的一个子集,包含10个非常不同的类别。它非常适合在尝试完整的ImageNet数据集上的技术之前快速实验。本教程中,我们将展示如何在此数据集上训练模型,使用常见的高级API,然后深入fastai库,向您展示如何使用我们设计的中级API。通过这种方式,您将能够根据需要自定义自己的数据收集或训练。
汇集数据
我们将查看几种将数据放入 DataLoaders 的方法:首先,我们将使用 ImageDataLoaders 工厂方法(应用层),然后使用数据块 API(高级 API),最后展示如何使用中级 API 完成相同的操作。
使用工厂方法加载数据
这是我们在所有初学者教程中展示的最基本的数据组装方式,因此希望你现在对此应该已经熟悉了。
首先,我们导入视觉应用程序中的所有内容:
from fastai.vision.all import *然后我们下载数据集并解压它(如果需要),并获取它的位置:
path = untar_data(URLs.IMAGENETTE_160)
100.01% [99008512/99003388 01:15<00:00]
我们使用 ImageDataLoaders.from_folder 来获取所有内容(因为我们的数据是以 imageNet 风格格式组织的):
dls = ImageDataLoaders.from_folder(path, valid='val',
item_tfms=RandomResizedCrop(128, min_scale=0.35), batch_tfms=Normalize.from_stats(*imagenet_stats))我们可以看看我们的数据:
dls.show_batch()
使用数据块API加载数据
正如我们在之前的教程中看到的,get_image_files函数帮助获取子文件夹中的所有图像:
fnames = get_image_files(path)让我们从一个空的 DataBlock 开始。
dblock = DataBlock()DataBlock 本身只是一个如何组装数据的蓝图。在你传递一个数据源之前,它不会做任何事情。然后你可以选择将该数据源转换为 Datasets 或 DataLoaders,通过使用 DataBlock.datasets 或 DataBlock.dataloaders 方法。由于我们还没有为批次准备好数据,dataloaders 方法会在这里失败,但我们可以看看它是如何在 Datasets 中转换的。这是我们传递数据源的地方,这里是我们所有的文件名:
dsets = dblock.datasets(fnames)
dsets.train[0](Path('/home/jhoward/.fastai/data/imagenette2-160/train/n03425413/n03425413_7416.JPEG'),
Path('/home/jhoward/.fastai/data/imagenette2-160/train/n03425413/n03425413_7416.JPEG'))默认情况下,数据块 API 假设我们有一个输入和一个目标,这就是我们看到文件名重复两次的原因。
我们可以做的第一件事是使用 get_items 函数来实际组装数据块中的项目:
dblock = DataBlock(get_items = get_image_files)区别在于你需要传递包含图像的文件夹作为源,而不是所有文件名:
dsets = dblock.datasets(path)
dsets.train[0](Path('/home/jhoward/.fastai/data/imagenette2-160/val/n03888257/n03888257_42.JPEG'),
Path('/home/jhoward/.fastai/data/imagenette2-160/val/n03888257/n03888257_42.JPEG'))我们的输入已准备好作为图像进行处理(因为可以根据文件名构建图像),但我们的目标尚未准备好。我们需要将文件名转换为类名。为此,fastai 提供了 parent_label:
parent_label(fnames[0])'n03417042'这并不是很容易阅读,因此既然我们实际上可以制作我们想要的函数,让我们将那些晦涩的标签转换为一些我们可以理解的内容:
lbl_dict = dict(
n01440764='tench',
n02102040='English springer',
n02979186='cassette player',
n03000684='chain saw',
n03028079='church',
n03394916='French horn',
n03417042='garbage truck',
n03425413='gas pump',
n03445777='golf ball',
n03888257='parachute'
)def label_func(fname):
return lbl_dict[parent_label(fname)]我们可以告诉我们的数据块使用它来标记我们的目标,通过将其作为 get_y 传递:
dblock = DataBlock(get_items = get_image_files,
get_y = label_func)
dsets = dblock.datasets(path)
dsets.train[0](Path('/home/jhoward/.fastai/data/imagenette2-160/train/n03000684/n03000684_8368.JPEG'),
'chain saw')现在我们的输入和目标已经准备好,我们可以指定类型来告诉数据块API我们的输入是图像而我们的目标是类别。类型在数据块API中由块表示,这里我们使用ImageBlock和CategoryBlock:
dblock = DataBlock(blocks = (ImageBlock, CategoryBlock),
get_items = get_image_files,
get_y = label_func)
dsets = dblock.datasets(path)
dsets.train[0](PILImage mode=RGB size=187x160, TensorCategory(0))我们可以看到,DataBlock 如何自动添加打开图像所需的转换,或者它是如何将名称“磁带播放器”更改为索引 2(使用特殊的张量类型)。为此,它创建了一个从类别到索引的映射,称为“词汇表”,我们可以通过以下方式访问它:
dsets.vocab['English springer', 'French horn', 'cassette player', 'chain saw', 'church', 'garbage truck', 'gas pump', 'golf ball', 'parachute', 'tench']请注意,您可以将任何输入和目标块进行混合匹配,这就是为什么该API被称为数据块API。您还可以拥有多个块(如果您有多个输入和/或目标),您只需将n_inp传递给DataBlock来告诉库有多少个输入(其余将是目标)并且将一个函数列表传递给get_x和/或get_y(以说明如何处理每个项目以使其准备好适应其类型)。下面是对象检测的一个示例。
下一步是控制我们的验证集是如何创建的。我们通过将一个splitter传递给DataBlock来实现这一点。例如,下面是我们如何按祖父文件夹进行划分的。
dblock = DataBlock(blocks = (ImageBlock, CategoryBlock),
get_items = get_image_files,
get_y = label_func,
splitter = GrandparentSplitter())
dsets = dblock.datasets(path)
dsets.train[0](PILImage mode=RGB size=213x160, TensorCategory(5))最后一步是指定项目变换和批处理变换(与我们在ImageDataLoaders工厂方法中所做的方式相同):
dblock = DataBlock(blocks = (ImageBlock, CategoryBlock),
get_items = get_image_files,
get_y = label_func,
splitter = GrandparentSplitter(),
item_tfms = RandomResizedCrop(128, min_scale=0.35),
batch_tfms=Normalize.from_stats(*imagenet_stats))通过该调整,我们现在能够将项目批处理在一起,并最终调用 dataloaders 将我们的 DataBlock 转换为 DataLoaders 对象:
dls = dblock.dataloaders(path)
dls.show_batch()
另一种为 get_y 组合多个函数的方法是将它们放在一个 Pipeline 中:
imagenette = DataBlock(blocks = (ImageBlock, CategoryBlock),
get_items = get_image_files,
get_y = Pipeline([parent_label, lbl_dict.__getitem__]),
splitter = GrandparentSplitter(valid_name='val'),
item_tfms = RandomResizedCrop(128, min_scale=0.35),
batch_tfms = Normalize.from_stats(*imagenet_stats))dls = imagenette.dataloaders(path)
dls.show_batch()
要了解更多关于数据块API的信息,请查看data block tutorial!
使用中级 API 加载数据
现在让我们看看如何使用中级API加载数据:我们将学习Transform和Datasets。开始的步骤与之前相同:我们下载数据并获取所有文件名:
source = untar_data(URLs.IMAGENETTE_160)
fnames = get_image_files(source)我们对原始项目(这里是文件名)应用的每一项变换称为fastai中的Transform。它基本上是一个具有一些附加功能的函数:
- 根据接收的类型,它可以表现出不同的行为(这称为类型分发)
- 通常会应用于元组的每个元素
这样,当你有一个像resize这样的Transform时,你可以将其应用于一个元组(图像,标签),它将调整图像的大小,但不会调整分类标签的大小(因为没有针对类别的调整大小实现)。对一个元组(图像,掩码)应用完全相同的变换将会调整图像和目标的大小,使用双线性插值法调整图像,使用最近邻法调整掩码。这就是该库在每个计算机视觉应用(分割、点定位或目标检测)中始终应用数据增强变换的方式。
此外,变换可以具有:
- 在整个数据集(或整个训练集)上执行的设置。这就是
Categorize自动构建词汇表的方式。 - 一个解码功能,可以撤消变换所做的操作以供展示(例如,
Categorize将把一个索引转换回一个类别)。
我们在这里不会深入探讨这些低级API的部分,但你可以查看宠物教程或更高级的孪生网络教程以获取更多信息。
要打开一张图片,我们使用 PILImage.create 转换。它将打开该图片并将其转换为 fastai 类型的 PILImage:
PILImage.create(fnames[0])
同时,我们已经看到如何使用 parent_label 和 lbl_dict 来获取我们图像的标签:
lbl_dict[parent_label(fnames[0])]'garbage truck'为了将它们转化为合适的类别,并映射到一个索引,然后再输入到模型中,我们需要添加Categorize变换。如果我们希望直接应用它,就需要提供一个词汇表(以便它知道如何将字符串与整数关联)。我们已经看到可以通过使用Pipeline组合多个变换:
tfm = Pipeline([parent_label, lbl_dict.__getitem__, Categorize(vocab = lbl_dict.values())])
tfm(fnames[0])TensorCategory(5)现在要构建我们的 Datasets 对象,我们需要指定:
- 我们的原始项目
- 将原始项目构建为输入的转换列表
- 将原始项目构建为目标的转换列表
- 训练和验证的划分
我们现在拥有除了划分以外的所有内容,可以通过以下方式构建它:
splits = GrandparentSplitter(valid_name='val')(fnames)我们可以将所有这些信息传递给 Datasets。
dsets = Datasets(fnames, [[PILImage.create], [parent_label, lbl_dict.__getitem__, Categorize]], splits=splits)我们之前最大的区别在于,我们可以直接传递 Categorize 而不需要传递词汇表:它将在设置阶段根据训练数据(它通过 items 和 splits 了解)构建词汇表。让我们来看一下第一个元素:
dsets[0](PILImage mode=RGB size=213x160, TensorCategory(5))我们也可以使用我们的 Datasets 对象来表示它:
dsets.show(dsets[0]);
现在,如果我们想从这个对象构建一个 DataLoaders,我们需要添加几个将在每个项目级别应用的变换。正如我们之前看到的,这些变换将分别应用于输入和目标,使用每种类型的适当实现(实际上可以什么都不做)。
在这里,我们需要:
- 调整我们的图像大小
- 将它们转换为张量
item_tfms = [ToTensor, RandomResizedCrop(128, min_scale=0.35)]此外,我们需要在批次级别应用几个变换,具体包括:
- 将图像中的整型张量转换为浮点型,并将每个像素除以255
- 使用ImageNet的统计数据进行归一化
batch_tfms = [IntToFloatTensor, Normalize.from_stats(*imagenet_stats)]这两个步骤也可以针对每个项目进行,但在整批处理时效率更高。
请注意,我们有比数据块 API 更多的转换:在这里不需要考虑 ToTensor 或 IntToFloatTensor。这是因为数据块在涉及到您将始终需要的那种转换时,配备了默认的项目转换和批次转换。
在将这些转换传递给 .dataloaders 方法时,相应的参数名称稍有不同:item_tfms 被传递给 after_item(因为它们在项目形成后应用),而 batch_tfms 被传递给 after_batch(因为它们在批次形成后应用)。
dls = dsets.dataloaders(after_item=item_tfms, after_batch=batch_tfms, bs=64, num_workers=8)我们可以使用传统的 show_batch 方法:
dls.show_batch()
训练
我们将从我们在视觉教程中使用的常规vision_learner函数开始,看看如何在fastai中构建Learner对象。然后,我们将学习如何自定义:
- 损失函数,以及如何编写一个能够与fastai完全兼容的损失函数,
- 优化器函数,以及如何使用PyTorch优化器,
- 训练循环,以及如何编写一个基本的
Callback。
构建一个 Learner
构建用于图像分类的 Learner 的最简单方法,如我们所见,是使用 vision_learner。我们可以通过传递 pretrained=False 来指定我们不想要预训练模型(这里的目标是从头开始训练一个模型):
learn = vision_learner(dls, resnet34, metrics=accuracy, pretrained=False)我们可以像往常一样拟合我们的模型:
::: {#cell-79 .cell 0=‘缓’ 1=‘慢’}
learn.fit_one_cycle(5, 5e-3)| epoch | train_loss | valid_loss | accuracy | time |
|---|---|---|---|---|
| 0 | 2.371458 | 1.981063 | 0.336815 | 00:07 |
| 1 | 2.185702 | 3.057348 | 0.299363 | 00:06 |
| 2 | 1.935795 | 8.318202 | 0.360255 | 00:06 |
| 3 | 1.651643 | 1.327140 | 0.566624 | 00:06 |
| 4 | 1.395742 | 1.297114 | 0.616815 | 00:06 |
:::
这只是一个开始。但是由于我们没有使用预训练模型,为什么不使用不同的架构呢?fastai 提供了一个版本的 resnets 模型,其中包含了现代研究中的所有技巧。虽然在撰写本教程时没有使用这些预训练模型,但我们当然可以在这里使用它。为此,我们只需使用 Learner 类。它至少需要我们的 DataLoaders 和一个 PyTorch 模型。在这里,我们可以使用 xresnet34,并且由于我们有 10 个类别,我们指定 n_out=10:
learn = Learner(dls, xresnet34(n_out=10), metrics=accuracy)我们可以通过学习率查找器找到一个好的学习率:
::: {#cell-83 .cell 0=‘缓’ 1=‘慢’}
learn.lr_find()SuggestedLRs(valley=0.0004786300996784121)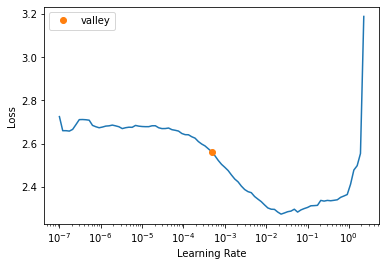
:::
然后拟合我们的模型:
::: {#cell-85 .cell 0=‘缓’ 1=‘慢’}
learn.fit_one_cycle(5, 1e-3)| epoch | train_loss | valid_loss | accuracy | time |
|---|---|---|---|---|
| 0 | 1.622614 | 1.570121 | 0.493758 | 00:06 |
| 1 | 1.171878 | 1.235382 | 0.593376 | 00:06 |
| 2 | 0.934658 | 0.914801 | 0.705987 | 00:06 |
| 3 | 0.762568 | 0.766841 | 0.754904 | 00:06 |
| 4 | 0.649679 | 0.675186 | 0.784204 | 00:06 |
:::
哇,这是一个巨大的改进!正如我们在所有应用程序教程中看到的,我们可以然后查看一些结果:
learn.show_results()
现在让我们看看如何自定义训练的每个部分。
更改损失函数
您传递给 Learner 的损失函数预期接受输出和目标,然后返回损失。它可以是任何常规的 PyTorch 函数,训练循环将正常运作。可能会导致问题的是,当您使用 fastai 的函数如 Learner.get_preds、Learner.predict 或 Learner.show_results 时。
如果您希望 Learner.get_preds 在参数 with_loss=True(这在您运行 ClassificationInterpretation.plot_top_losses 时也会使用)时正常工作,您的损失函数需要具有一个 reduction 属性(或参数),您可以将其设置为 “none”(这是所有 PyTorch 损失函数或类的标准)。使用 “none” 的减少方式,损失函数不会返回一个单一的数字(例如均值或和),而是返回与目标相同大小的东西。
至于 Learner.predict 或 Learner.show_results,它们在内部依赖于您的损失函数应该具有的两个方法:
- 如果您有一个结合了激活和损失函数的损失(例如
nn.CrossEntropyLoss),则需要一个activation函数。 - 一个
decodes函数,用于将您的预测转换为与目标相同的格式:例如在nn.CrossEntropyLoss的情况下,decodes函数应该使用 argmax。
作为示例,让我们来看一下如何实现一个进行标签平滑的自定义损失函数(这在 fastai 中已经作为 LabelSmoothingCrossEntropy 提供)。
class LabelSmoothingCE(Module):
def __init__(self, eps=0.1, reduction='mean'): self.eps,self.reduction = eps,reduction
def forward(self, output, target):
c = output.size()[-1]
log_preds = F.log_softmax(output, dim=-1)
if self.reduction=='sum': loss = -log_preds.sum()
else:
loss = -log_preds.sum(dim=-1) #我们在返回行中除以该大小,因此是求和而不是求平均值
if self.reduction=='mean': loss = loss.mean()
return loss*self.eps/c + (1-self.eps) * F.nll_loss(log_preds, target.long(), reduction=self.reduction)
def activation(self, out): return F.softmax(out, dim=-1)
def decodes(self, out): return out.argmax(dim=-1)我们不会对仅仅实现损失的forward传递进行评论。重要的是要注意reduction属性在最终结果计算中的作用。
由于这个损失函数将激活(softmax)与实际损失结合在一起,我们实现了activation,它对输出执行softmax。这使得Learner.get_preds或Learner.predict返回实际预测,而不是最终激活值。
最后,decodes通过对预测取argmax,将模型的输出转换为与目标相同的格式(每个批次大小中的每个样本一个整数)。我们可以将这个损失函数传递给Learner:
learn = Learner(dls, xresnet34(n_out=10), loss_func=LabelSmoothingCE(), metrics=accuracy)::: {#cell-94 .cell 0=‘缓’ 1=‘慢’}
learn.fit_one_cycle(5, 1e-3)| epoch | train_loss | valid_loss | accuracy | time |
|---|---|---|---|---|
| 0 | 1.734130 | 1.663665 | 0.521529 | 00:18 |
| 1 | 1.419407 | 1.358000 | 0.652994 | 00:19 |
| 2 | 1.239973 | 1.292138 | 0.675669 | 00:19 |
| 3 | 1.114046 | 1.093192 | 0.756688 | 00:19 |
| 4 | 1.019760 | 1.061080 | 0.772229 | 00:19 |
:::
它的训练效果不如以前,因为标签平滑是一种正则化技术,因此需要更多的迭代周期才能真正生效并获得更好的结果。
在训练我们的模型后,我们确实可以使用 predict 和 show_results 来获得正确的结果:
learn.predict(fnames[0])('garbage truck',
tensor(5),
tensor([1.5314e-03, 9.6116e-04, 2.7214e-03, 2.6757e-03, 6.4039e-04, 9.8842e-01,
8.1883e-04, 7.5840e-04, 1.0780e-03, 3.9759e-04]))learn.show_results()
更改优化器
fastai使用其自己的Optimizer类,结合各种回调功能,以重构常见功能并提供超参数的独特命名,这些超参数在不同的优化器中扮演相同的角色(例如SGD中的动量,与RMSProp中的alpha以及Adam中的beta0相同),这使得调度这些参数变得更加容易(例如在Learner.fit_one_cycle中)。
它实现了所有由PyTorch支持的优化器(以及更多),因此你不需要使用来自PyTorch的优化器。请查看optimizer模块以查看所有原生可用的优化器。
然而,在某些情况下,你可能需要使用不在fastai中的优化器(例如,如果它是仅在PyTorch中实现的新的优化器)。在学习如何将代码移植到我们内部的Optimizer之前(查看optimizer模块以了解如何进行),你可以使用OptimWrapper类来包装你的PyTorch优化器并使用它进行训练:
pytorch_adamw = partial(OptimWrapper, opt=torch.optim.AdamW)我们编写了一个优化器函数,它期待 param_groups,这是一个参数列表的列表。然后我们将这些参数传递给我们想要使用的 PyTorch 优化器。
我们可以使用这个函数,并将其传递给 Learner 的 opt_func 参数:
learn = Learner(dls, xresnet18(), lr=1e-2, metrics=accuracy,
loss_func=LabelSmoothingCrossEntropy(),
opt_func=partial(pytorch_adamw, weight_decay=0.01, eps=1e-3))我们可以使用常规的学习率查找器:
::: {#cell-104 .cell 0=‘缓’ 1=‘慢’}
learn.lr_find()SuggestedLRs(lr_min=0.07585775852203369, lr_steep=0.00363078061491251)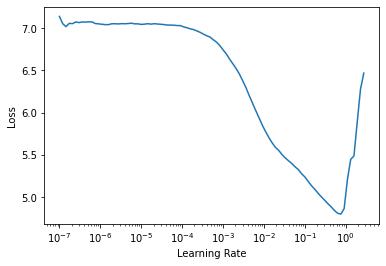
:::
或者 fit_one_cycle(感谢封装,fastai 将会正确安排 AdamW 的 beta0)。
::: {#cell-106 .cell 0=‘缓’ 1=‘慢’}
learn.fit_one_cycle(5, 5e-3)| epoch | train_loss | valid_loss | accuracy | time |
|---|---|---|---|---|
| 0 | 2.661560 | 3.077346 | 0.332994 | 00:14 |
| 1 | 2.172226 | 2.087496 | 0.622675 | 00:14 |
| 2 | 1.913195 | 1.859730 | 0.695541 | 00:14 |
| 3 | 1.736957 | 1.692221 | 0.773758 | 00:14 |
| 4 | 1.631078 | 1.646656 | 0.788280 | 00:14 |
:::
使用 Callback 更改训练循环
fastai中的基础训练循环与PyTorch相同:
for xb,yb in dl:
pred = model(xb)
loss = loss_func(pred, yb)
loss.backward()
opt.step()
opt.zero_grad()其中model、loss_func和opt都是我们Learner的属性。为了便于您在训练循环中添加新行为,而无需自己重写它(以及您可能想要的所有fastai组件,例如混合精度、1cycle调度、分布式训练等),您可以通过编写回调来定制训练循环中的操作。
Callback将在即将到来的教程中全面讲解,但基本内容是:
Callback可以读取Learner的每一个部分,从而了解训练循环中发生的所有事情Callback可以更改Learner的任何部分,从而允许其改变训练循环的行为Callback甚至可以引发特定的异常,以便允许中断点(跳过一步、一个验证阶段、一个周期或甚至完全取消训练)
在这里,我们将编写一个简单的Callback,将混合应用于我们的训练(我们将编写的版本是针对我们的问题,其他情况下使用fastai的MixUp)。
Mixup的核心思想是通过混合两个不同的输入并对它们进行线性组合来改变输入:
input = x1 * t + x2 * (1-t)其中t是介于0和1之间的随机数。然后,如果目标是独热编码的,我们将目标更改为:
target = y1 * t + y2 * (1-t)在实际操作中,目标并不是在PyTorch中进行独热编码,但这相当于通过以下方式更改处理 y1 和 y2 的损失部分:
loss = loss_func(pred, y1) * t + loss_func(pred, y2) * (1-t)因为所使用的损失函数在y上是线性的。
我们只需要使用损失的 reduction='none' 版本来进行这种线性组合,然后再取平均。
以下是我们如何在 Callback 中编写mixup:
from torch.distributions.beta import Betaclass Mixup(Callback):
run_valid = False
def __init__(self, alpha=0.4): self.distrib = Beta(tensor(alpha), tensor(alpha))
def before_batch(self):
self.t = self.distrib.sample((self.y.size(0),)).squeeze().to(self.x.device)
shuffle = torch.randperm(self.y.size(0)).to(self.x.device)
x1,self.y1 = self.x[shuffle],self.y[shuffle]
self.learn.xb = (x1 * (1-self.t[:,None,None,None]) + self.x * self.t[:,None,None,None],)
def after_loss(self):
with NoneReduce(self.loss_func) as lf:
loss = lf(self.pred,self.y1) * (1-self.t) + lf(self.pred,self.y) * self.t
self.learn.loss = loss.mean()我们可以看到我们写了两个事件:
before_batch在绘制一个批次后,模型在输入上运行之前执行。我们首先按照贝塔分布(如论文中建议的那样)绘制我们的随机数t,并获取批次的一个混合版本(而不是绘制批次的第二个版本,我们将一个批次与其混合版本结合)。然后我们将self.learn.xb设置为新的输入,这将被输入到模型中。after_loss在损失计算完成后和反向传播之前执行。我们用正确的值替换self.learn.loss。NoneReduce是一个上下文管理器,暂时将损失的 reduction 属性设置为 ‘none’。
此外,我们还告知 Callback 在验证阶段不应运行,设置 run_valid=False。
要将 Callback 传递给 Learner,我们使用 cbs=:
learn = Learner(dls, xresnet18(), lr=1e-2, metrics=accuracy,
loss_func=LabelSmoothingCrossEntropy(), cbs=Mixup(),
opt_func=partial(pytorch_adamw, weight_decay=0.01, eps=1e-3))然后我们可以将这个新的回调与学习率查找器结合起来:
::: {#cell-116 .cell 0=‘缓’ 1=‘慢’}
learn.lr_find()SuggestedLRs(lr_min=0.06309573650360108, lr_steep=0.004365158267319202)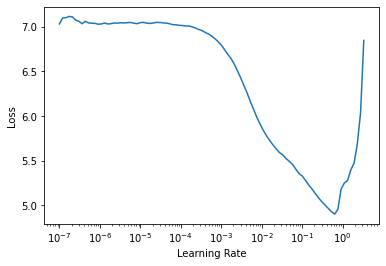
:::
并将其与 fit_one_cycle 结合起来:
::: {#cell-118 .cell 0=‘缓’ 1=‘慢’}
learn.fit_one_cycle(5, 5e-3)| epoch | train_loss | valid_loss | accuracy | time |
|---|---|---|---|---|
| 0 | 3.094243 | 3.560097 | 0.175796 | 00:15 |
| 1 | 2.766956 | 2.633007 | 0.400000 | 00:15 |
| 2 | 2.604495 | 2.454862 | 0.549809 | 00:15 |
| 3 | 2.513580 | 2.335537 | 0.598726 | 00:15 |
| 4 | 2.438728 | 2.277912 | 0.631338 | 00:15 |
:::
像标签平滑一样,这是一个提供更多正则化的回调,因此在看到任何好处之前,你需要运行更多的周期。此外,我们的简单实现没有包括fastai实现中的所有技巧,因此请确保查看官方的 callback.mixup!
结束 -