信号处理 (scipy.signal)#
信号处理工具箱目前包含一些滤波函数、有限的一组滤波器设计工具,以及一些用于一维和二维数据的B样条插值算法。虽然B样条算法在技术上可以归类为插值类别,但它们被包含在这里是因为它们仅适用于等间距数据,并且大量使用了滤波理论和传递函数形式来提供快速的B样条变换。要理解本节内容,您需要了解在SciPy中,信号是一个由实数或复数组成的数组。
B样条#
B样条是通过B样条系数和节点点对有限域上的连续函数进行近似。如果节点点等间距分布,间距为 \(\Delta x\),那么B样条对一维函数的近似是有限基展开。
在二维情况下,节点间距为 \(\Delta x\) 和 \(\Delta y\),函数表示为
在这些表达式中, \(\beta^{o}\left(\cdot\right)\) 是阶数为 \(o\) 的空间受限B样条基函数。等间距节点点和等间距数据点的要求,使得可以开发出快速(反滤波)算法来确定系数 \(c_{j}\),从样本值 \(y_{n}\) 中。与一般的样条插值算法不同,这些算法可以快速找到大型图像的样条系数。
通过B样条基函数表示一组样本的优点 其优点在于,连续域运算符(导数、重采样、积分等),假设数据样本来自一个底层连续函数,可以从样条系数中相对容易地计算出来。例如,样条的二阶导数为
利用B样条的性质
可以看出
如果 \(o=3\),则在采样点处:
因此,二阶导数信号可以很容易地从样条拟合中计算出来。如果需要,可以找到平滑样条,使二阶导数对随机误差不太敏感。
细心的读者可能已经注意到,数据样本与节点系数通过卷积运算符相关联,因此简单地与采样的B样条函数进行卷积就可以从样条系数中恢复原始数据。卷积的输出会根据边界处理方式的不同而变化(随着数据集维数的增加,这一点变得越来越重要)。信号处理子包中与B样条相关的算法假设镜像对称边界条件。因此,样条系数是基于此计算的。 假设,并且通过假设数据样本也具有镜像对称性,可以从样条系数中精确恢复数据样本。
目前,该包提供了用于从一维和二维等间距样本中确定二阶和三阶三次样条系数的函数(qspline1d、qspline2d、cspline1d、cspline2d)。对于较大的 \(o\),B样条基函数可以很好地近似为一个均值为零、标准差为 \(\sigma_{o}=\left(o+1\right)/12\) 的高斯函数:
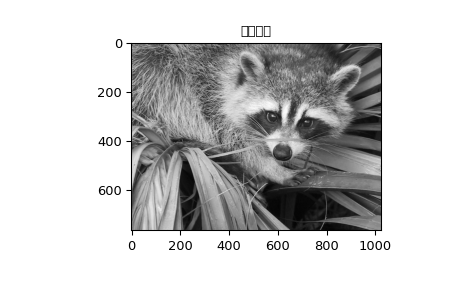
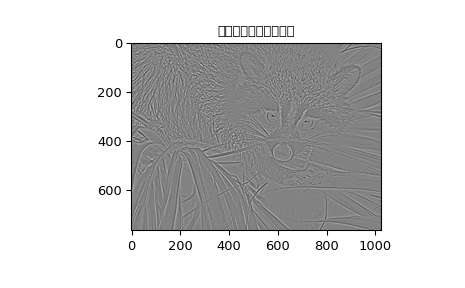
还提供了一个函数来计算任意 \(x\) 和 \(o\) 的高斯函数(gauss_spline)。以下代码和图示使用样条滤波来计算浣熊脸部图像的边缘图像(平滑样条的二阶导数),该图像是通过命令 scipy.datasets.face 返回的数组。命令 sepfir2d 用于将具有镜像对称边界条件的可分离二维FIR滤波器应用于样条系数。该函数非常适合从样条系数重建样本,并且比 convolve2d 更快,后者用于卷积任意二维滤波器,并允许选择镜像对称边界条件。
>>> import numpy as np
>>> from scipy import signal, datasets
>>> import matplotlib.pyplot as plt
>>> image = datasets.face(gray=True).astype(np.float32)
>>> derfilt = np.array([1.0, -2, 1.0], dtype=np.float32)
>>> ck = signal.cspline2d(image, 8.0)
>>> deriv = (signal.sepfir2d(ck, derfilt, [1]) +
... signal.sepfir2d(ck, [1], derfilt))
或者,我们可以这样做:
laplacian = np.array([[0,1,0], [1,-4,1], [0,1,0]], dtype=np.float32)
deriv2 = signal.convolve2d(ck,laplacian,mode='same',boundary='symm')
>>> plt.figure()
>>> plt.imshow(image)
>>> plt.gray()
>>> plt.title('原始图像')
>>> plt.show()
>>> plt.figure()
>>> plt.imshow(deriv)
>>> plt.gray()
>>> plt.title('样条边缘滤波器的输出')
>>> plt.show()
滤波#
滤波是一个通用术语,用于描述任何以某种方式修改输入信号的系统。在SciPy中,信号可以被视为NumPy数组。不同类型的滤波器用于不同类型的操作。滤波操作主要分为两类:线性和非线性。线性滤波器总是可以简化为将展平的NumPy数组与适当的矩阵相乘,从而得到另一个展平的NumPy数组。当然,这通常不是计算滤波器的最佳方法,因为涉及的矩阵和向量可能非常大。例如,使用这种方法对一个 \(512 \times 512\) 的图像进行滤波将需要将一个 \(512^2 \times 512^2\) 的矩阵与一个 \(512^2\) 的向量相乘。仅尝试使用标准NumPy数组存储 \(512^2 \times 512^2\) 矩阵就需要 \(68,719,476,736\) 个元素。以每个元素4字节计算,这将需要 \(256\textrm{GB}\) 的内存。在大多数应用中,该矩阵的大多数元素为零,并且采用了不同的方法来计算滤波器的输出。
卷积/相关#
许多线性滤波器还具有位移不变性。这意味着滤波操作在信号的不同位置是相同的,并且这意味着滤波矩阵可以 由矩阵的某一行(或列)的知识构建而成。在这种情况下,矩阵乘法可以通过傅里叶变换来完成。
设 \(x\left[n\right]\) 定义一个由整数 \(n\) 索引的 1-D 信号。两个 1-D 信号的完整卷积可以表示为
这个方程只有在我们将序列限制为可以存储在计算机中的有限支持序列时才能直接实现,选择 \(n=0\) 作为两个序列的起始点,设 \(K+1\) 为使得 \(x\left[n\right]=0\) 对所有 \(n\geq K+1\) 成立的值,设 \(M+1\) 为使得 \(h\left[n\right]=0\) 对所有 \(n\geq M+1\) 成立的值,那么离散卷积表达式为
为了方便,假设 \(K\geq M.\) 那么,更明确地,该操作的输出为
因此,两个长度分别为 \(K+1\) 和 \(M+1\) 的有限序列的完整离散卷积,结果是一个长度为 \(K+M+1=\left(K+1\right)+\left(M+1\right)-1\) 的有限序列。
一维卷积在 SciPy 中通过函数 convolve 实现。该函数接受信号 \(x\)、\(h\) 以及两个可选标志 ‘mode’ 和 ‘method’ 作为输入,并返回信号 \(y\)。
第一个可选标志 ‘mode’ 允许指定返回输出信号的哪一部分。默认值 ‘full’ 返回整个信号。如果标志的值为 ‘same’,则仅返回中间的 \(K\) 个值,从 \(y\left[\left\lfloor \frac{M-1}{2}\right\rfloor \right]\) 开始,使得输出与第一个输入具有相同的长度。如果标志的值为 ‘valid’,则仅返回中间的 \(K-M+1=\left(K+1\right)-\left(M+1\right)+1\) 个输出值,其中 \(z\) 取决于最小输入的所有值。 \(h\left[0\right]\) 到 \(h\left[M\right]\)。换句话说,只返回从 \(y\left[M\right]\) 到 \(y\left[K\right]\) 的值。
第二个可选标志 ‘method’ 决定了卷积的计算方式,可以通过傅里叶变换方法使用 fftconvolve 或直接方法。默认情况下,它会选择预期更快的计算方法。傅里叶变换方法的时间复杂度为 \(O(N\log N)\),而直接方法的时间复杂度为 \(O(N^2)\)。根据大 O 常数和 \(N\) 的值,这两种方法中的一种可能会更快。默认值 ‘auto’ 会进行粗略计算并选择预期更快的方法,而值 ‘direct’ 和 ‘fft’ 则强制使用其他两种方法进行计算。
下面的代码展示了一个简单的卷积示例,涉及两个序列:
>>> x = np.array([1.0, 2.0, 3.0])
>>> h = np.array([0.0, 1.0, 0.0, 0.0, 0.0])
>>> signal.convolve(x, h)
array([ 0., 1., 2., 3., 0., 0., 0.])
>>> signal.convolve(x, h, 'same')
array([ 2., 3., 0.])
这个相同的函数 convolve 实际上可以接受 N 维数组作为输入,并返回两个数组的 N 维卷积,如下面的代码示例所示。对于这种情况,同样可以使用相同的输入标志。
>>> x = np.array([[1., 1., 0., 0.], [1., 1., 0., 0.], [0., 0., 0., 0.], [0., 0., 0., 0.]])
>>> h = np.array([[1., 0., 0., 0.], [0., 0., 0., 0.], [0., 0., 1., 0.], [0., 0., 0., 0.]])
>>> signal.convolve(x, h)
array([[ 1., 1., 0., 0., 0., 0., 0.],
[ 1., 1., 0., 0., 0., 0., 0.],
[ 0., 0., 1., 1., 0., 0., 0.],
[ 0., 0., 1., 1., 0., 0., 0.],
[ 0., 0., 0., 0., 0., 0., 0.],
[ 0., 0., 0., 0., 0., 0., 0.],
[ 0., 0., 0., 0., 0., 0., 0.]])
相关性与卷积非常相似,只是减号变成了加号。因此,
是信号 \(y\) 和 \(x\) 的(互)相关。对于有限长度的信号,当 \(y\left[n\right]=0\) 在范围 \(\left[0,K\right]\) 之外且 \(x\left[n\right]=0\) 在范围 \(\left[0,M\right]\) 之外时,求和可以简化为
再次假设 \(K\geq M\),则有
SciPy 函数 correlate 实现了这一操作。等效的标志可用于此操作,以返回长度为 \(K+M+1\) 的完整序列(’full’)或与最大序列大小相同的序列,从 \(w\left[-K+\left\lfloor \frac{M-1}{2}\right\rfloor \right]\) 开始(’same’),或返回一个序列,其中值取决于所有输入值(’valid’)。
最小序列(’valid’)。此最终选项返回从 \(w\left[M-K\right]\) 到 \(w\left[0\right]\) 的 \(K-M+1\) 个值。
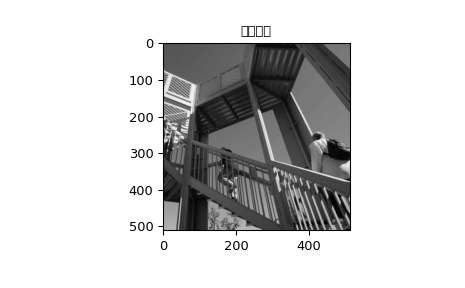
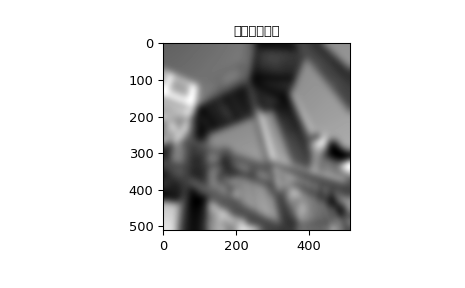
常用于模糊处理。
>>> import numpy as np
>>> from scipy import signal, datasets
>>> import matplotlib.pyplot as plt
>>> image = np.asarray(datasets.ascent(), np.float64)
>>> w = signal.windows.gaussian(51, 10.0)
>>> image_new = signal.sepfir2d(image, w, w)
>>> plt.figure()
>>> plt.imshow(image)
>>> plt.gray()
>>> plt.title('原始图像')
>>> plt.show()
>>> plt.figure()
>>> plt.imshow(image_new)
>>> plt.gray()
>>> plt.title('滤波后的图像')
>>> plt.show()
通常,选择 \(a_{0}=1\) 进行归一化。SciPy 中实现这种通用差分方程滤波器的方式比前面方程所暗示的要稍微复杂一些。它的实现方式使得只需要延迟一个信号。实际的实现方程如下(假设 \(a_{0}=1\) ):
其中 \(K=\max\left(N,M\right)\)。注意,如果 \(K>M\),则 \(b_{K}=0\),如果 \(K>N\),则 \(a_{K}=0\)。通过这种方式,时间 \(n\) 处的输出仅依赖于时间 \(n\) 处的输入和前一时间 \(z_{0}\) 的值。只要在每个时间步计算并存储 \(K\) 个值 \(z_{0}\left[n-1\right]\ldots z_{K-1}\left[n-1\right]\),就可以始终计算出结果。
差分方程滤波器通过 SciPy 中的命令 lfilter 调用。该命令的输入包括向量 \(b\)、向量 \(a\)、信号 \(x\),并返回使用上述方程计算得到的向量 \(y`(长度与 :math:`x\) 相同)。如果 \(x\) 是 N 维的,则沿提供的轴进行滤波计算。
如果需要,可以提供初始条件,给出 \(z_{0}\left[-1\right]\) 到 \(z_{K-1}\left[-1\right]\) 的值,否则将假定它们全为零。如果提供了初始条件,则还会返回中间变量的最终条件。这些条件可以用于例如在相同状态下重新启动计算。
有时,用信号 \(x\left[n\right]\) 和 \(y\left[n\right]\) 来表示初始条件更为方便。换句话说,也许你知道 \(x\left[-M\right]\) 到 \(x\left[-1\right]\) 的值,以及 \(y\left[-N\right]\) 到 \(y\left[-1\right]\) 的值,并且希望确定应该将哪些 \(z_{m}\left[-1\right]\) 值作为初始条件传递给差分方程滤波器。不难证明,对于 \(0\leq m<K,\)
使用这个公式,我们可以找到初始条件向量 \(z_{0}\left[-1\right]\) 到 \(z_{K-1}\left[-1\right]\),给定 \(y`(和 :math:`x\))的初始条件。命令 lfiltic 执行此功能。
作为一个例子,考虑以下系统:
代码计算给定信号 \(x[n]\) 的信号 \(y[n]\);首先对于初始条件 \(y[-1] = 0`(默认情况),然后通过 :func:`lfiltic\) 计算 \(y[-1] = 2\)。
>>> import numpy as np
>>> from scipy import signal
>>> x = np.array([1., 0., 0., 0.])
>>> b = np.array([1.0/2, 1.0/4])
>>> a = np.array([1.0, -1.0/3])
>>> signal.lfilter(b, a, x)
array([0.5, 0.41666667, 0.13888889, 0.0462963])
>>> zi = signal.lfiltic(b, a, y=[2.])
>>> signal.lfilter(b, a, x, zi=zi)
(array([ 1.16666667, 0.63888889, 0.21296296, 0.07098765]), array([0.02366]))
注意,输出信号 \(y[n]\) 的长度与输入信号 \(x[n]\) 的长度相同。
线性系统的分析#
描述线性差分方程的线性系统可以通过系数向量 \(a\) 和 \(b\) 完全描述,如上所述;另一种表示方法是提供一个因子 \(k\),\(N_z\) 个零点 \(z_k\) 以及 \(N_p\) 个极点 \(p_k\),分别通过其传递函数 \(H(z)\) 来描述系统,根据
这种替代表示可以通过 scipy 函数 tf2zpk 获得;其逆函数由 zpk2tf 提供。
对于上述示例,我们有
>>> b = np.array([1.0/2, 1.0/4])
>>> a = np.array([1.0, -1.0/3])
>>> signal.tf2zpk(b, a)
(array([-0.5]), array([ 0.33333333]), 0.5)
即,系统在 \(z=-1/2\) 处有一个零点,在 \(z=1/3\) 处有一个极点。
scipy 函数 freqz 允许计算由系数 \(a_k\) 和 \(b_k\) 描述的系统的频率响应。请参阅 freqz 函数的帮助文档以获取综合示例。
滤波器设计#
时间离散滤波器可以分为有限响应(FIR)滤波器和无限响应(IIR)滤波器。FIR 滤波器可以提供线性相位响应,而 IIR 滤波器则不能。SciPy 提供了设计这两类滤波器的函数。
FIR 滤波器#
函数 firwin 根据窗口方法设计滤波器。根据提供的参数,函数返回不同类型的滤波器(例如,低通、带通…)。
下面的示例分别设计了一个低通滤波器和一个带阻滤波器。
>>> import numpy as np
>>> import scipy.signal as signal
>>> import matplotlib.pyplot as plt
>>> b1 = signal.firwin(40, 0.5)
>>> b2 = signal.firwin(41, [0.3, 0.8])
>>> w1, h1 = signal.freqz(b1)
>>> w2, h2 = signal.freqz(b2)
>>> plt.title('数字滤波器频率响应')
>>> plt.plot(w1, 20*np.log10(np.abs(h1)), 'b')
>>> plt.plot(w2, 20*np.log10(np.abs(h2)), 'r')
>>> plt.ylabel('幅度响应 (dB)')
>>> plt.xlabel('频率 (rad/sample)')
>>> plt.grid()
>>> plt.show()
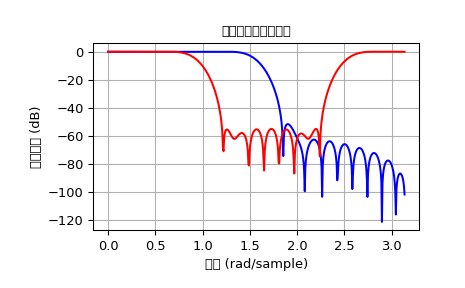
注意,firwin 默认使用归一化频率,其中值 \(1\) 对应于奈奎斯特频率,而函数 freqz 的定义是值 \(\pi\) 对应于奈奎斯特频率。
函数 firwin2 允许通过指定角频率数组和相应的增益来设计几乎任意的频率响应。
下面的示例设计了一个具有任意幅度响应的滤波器。
>>> import numpy as np
>>> import scipy.signal as signal
>>> import matplotlib.pyplot as plt
>>> b = signal.firwin2(150, [0.0, 0.3, 0.6, 1.0], [1.0, 2.0, 0.5, 0.0])
>>> w, h = signal.freqz(b)
>>> plt.title('数字滤波器频率响应')
>>> plt.plot(w, np.abs(h))
>>> plt.title('数字滤波器频率响应')
>>> plt.ylabel('幅度响应')
>>> plt.xlabel('频率 (rad/sample)')
>>> plt.grid()
>>> plt.show()
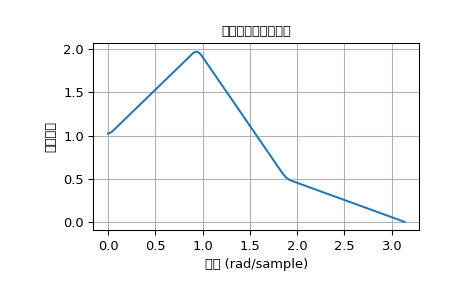
IIR滤波器#
SciPy提供了两个直接设计IIR滤波器的函数 iirdesign 和 iirfilter,其中滤波器类型(例如,椭圆)作为参数传递,并且还有几个特定滤波器类型的设计函数,例如 ellip。
下面的示例设计了一个具有定义的通带和阻带波纹的椭圆低通滤波器。请注意,与上面示例中的FIR滤波器相比,为了达到相同的阻带衰减(约60 dB),滤波器阶数(4阶)要低得多。
>>> import numpy as np
>>> import scipy.signal as signal
>>> import matplotlib.pyplot as plt
>>> b, a = signal.iirfilter(4, Wn=0.2, rp=5, rs=60, btype='lowpass', ftype='ellip')
>>> w, h = signal.freqz(b, a)
>>> plt.title('数字滤波器频率响应')
>>> plt.plot(w, 20*np.log10(np.abs(h)))
>>> plt.title('数字滤波器频率响应')
>>> plt.ylabel('幅度响应 [dB]')
>>> plt.xlabel('频率 (rad/sample)')
>>> plt.grid()
>>> plt.show()
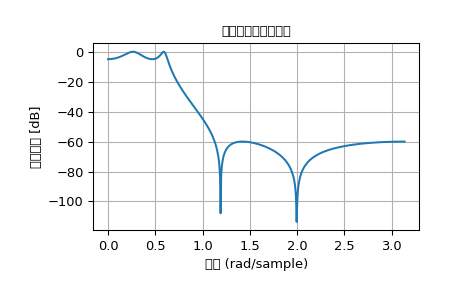
滤波器系数#
滤波器系数可以存储在几种不同的格式中:
‘ba’ 或 ‘tf’ = 传递函数系数
‘zpk’ = 零点、极点和整体增益
‘ss’ = 状态空间系统表示
‘sos’ = 二阶节传递函数系数
函数,如 tf2zpk 和 zpk2ss,可以在它们之间进行转换。
传递函数表示#
ba 或 tf 格式是一个2元组 (b, a),表示传递函数,其中 b 是长度为 M+1 的数组,表示 M 阶分子多项式的系数,a 是长度为 N+1 的数组,表示 N 阶分母多项式的系数,按传递函数变量的正降幂排列。因此,元组 \(b = [b_0, b_1, ..., b_M]\) 和 \(a =[a_0, a_1, ..., a_N]\) 可以表示以下形式的模拟滤波器:
.. math:
H(s) = \frac
{b_0 s^M + b_1 s^{(M-1)} + \cdots + b_M}
{a_0 s^N + a_1 s^{(N-1)} + \cdots + a_N}
= \frac
{\sum_{i=0}^M b_i s^{(M-i)}}
{\sum_{i=0}^N a_i s^{(N-i)}}
或离散时间滤波器的形式:
这种“正幂次”形式在控制工程中更为常见。如果 M 和 N 相等(对于所有由双线性变换生成的滤波器都是如此),那么这恰好等价于DSP中偏好的“负幂次”离散时间形式:
尽管这对常见滤波器是正确的,但请记住,在一般情况下这并不成立。如果 M 和 N 不相等,离散时间传递函数的系数必须首先转换为“正幂次”形式,然后才能找到极点和零点。
这种表示在高阶时会受到数值误差的影响,因此在可能的情况下,其他格式更受青睐。
零点和极点表示#
zpk 格式是一个三元组 (z, p, k),其中 z 是传递函数的复数零点的 M 长度数组 \(z = [z_0, z_1, ..., z_{M-1}]\),p 是传递函数的复数极点的 N 长度数组 \(p = [p_0, p_1, ..., p_{N-1}]\),k 是一个标量增益。这些表示数字传递函数:
或模拟传递函数:
尽管根集以有序的NumPy数组形式存储,但它们的顺序并不重要:([-1, -2], [-3, -4], 1) 与 ([-2, -1], [-4, -3], 1) 是相同的滤波器。
状态空间系统表示#
ss 格式是一个由数组 (A, B, C, D) 组成的4元组,表示一个 N 阶数字/离散时间系统的状态空间,形式如下:
或一个连续/模拟系统,形式如下:
其中 P 个输入,Q 个输出和 N 个状态变量,其中:
x 是状态向量
y 是长度为 Q 的输出向量
u 是长度为 P 的输入向量
A 是状态矩阵,形状为
(N, N)B 是输入矩阵,形状为
(N, P)C 是输出矩阵,形状为
(Q, N)D 是前馈或前馈矩阵,形状为
(Q, P)。(在系统没有直接前馈的情况下,D 中的所有值均为零。)
状态空间是最通用的表示形式,也是唯一允许多输入多输出(MIMO)系统的表示形式。对于给定的传递函数,存在多种状态空间表示。具体来说,“可控规范形式”和“可观测规范形式”具有与 tf 表示相同的系数,因此,它们会遭受相同的数值误差。
二阶节表示#
sos 格式是一个形状为 (n_sections, 6) 的单个二维数组,表示一系列二阶传递函数,当
级联串联,实现数值误差最小的高阶滤波器。每一行对应一个二阶的 tf 表示,前三个列提供分子系数,后三个列提供分母系数:
系数通常是归一化的,使得 \(a_0\) 总是 1。级联顺序通常在浮点计算中不重要;滤波器输出将相同,无论顺序如何。
滤波器变换#
IIR 滤波器设计函数首先生成一个具有归一化截止频率为 1 rad/sec 的原型模拟低通滤波器。然后使用以下替换将其转换为其他频率和带类型:
类型 |
变换 |
|---|---|
\(s \rightarrow \frac{s}{\omega_0}\) |
|
\(s \rightarrow \frac{\omega_0}{s}\) |
|
\(s \rightarrow \frac{s^2 + {\omega_0}^2}{s \cdot \mathrm{BW}}\) |
|
\(s \rightarrow \frac{s \cdot \mathrm{BW}}{s^2 + {\omega_0}^2}\) |
这里,\(\omega_0\) 是新的截止频率或中心频率,\(\mathrm{BW}\) 是带宽。这些变换在对数频率轴上保持对称性。
要将变换后的模拟滤波器转换为数字滤波器,使用 bilinear 变换,它进行以下替换:
其中 T 是采样时间(采样频率的倒数)。
其他滤波器#
信号处理包还提供了许多其他滤波器。
中值滤波器#
中值滤波器通常在噪声明显非高斯分布或希望保留边缘时应用。中值滤波器通过将围绕感兴趣点的矩形区域内的所有数组像素值进行排序来工作。该列表中邻域像素值的样本中值被用作输出数组的值。样本中值是排序列表中邻域值的中间数组值。如果邻域中的元素数量为偶数,则使用中间两个值的平均值作为中值。一个适用于N维数组的一般用途中值滤波器是 medfilt。一个仅适用于二维数组的专用版本是 medfilt2d。
顺序滤波器#
中值滤波器是更一般的滤波器类——顺序滤波器的一个特例。为了计算特定像素的输出,所有顺序滤波器都使用围绕该像素的区域内的数组值。这些数组值被排序,然后其中一个被选为输出值。对于中值滤波器,列表中数组值的样本中值被用作输出。一般顺序滤波器允许用户选择排序值中的哪一个将被用作输出。因此,例如,可以选择列表中的最大值或最小值。顺序滤波器除了输入数组和区域掩码外,还需要一个额外的参数,该参数指定排序列表中邻域数组值中的哪一个应被用作输出。执行顺序滤波的命令是 order_filter。
维纳滤波器#
维纳滤波器是一种简单的去模糊滤波器,用于图像去噪。这不是图像重建问题中通常描述的维纳滤波器,而是一个简单的局部均值滤波器。设 \(x\) 为输入信号,则输出为
其中 \(m_{x}\) 是均值的局部估计值, \(\sigma_{x}^{2}\) 是方差的局部估计值。这些估计值的窗口是一个可选的输入参数(默认值为 \(3\times3\))。 参数 \(\sigma^{2}\) 是一个阈值噪声参数。如果未给出 \(\sigma\),则将其估计为局部方差的平均值。
希尔伯特滤波器#
希尔伯特变换从实信号构建复值解析信号。例如,如果 \(x=\cos\omega n\),那么 \(y=\textrm{hilbert}\left(x\right)\) 将返回(除边缘附近外) \(y=\exp\left(j\omega n\right)\)。在频域中, 希尔伯特变换执行
其中 \(H\) 对于正频率为 \(2\),对于负频率为 \(0\),对于零频率为 \(1\)。
模拟滤波器设计#
函数 iirdesign、iirfilter 以及特定滤波器类型的设计函数(例如 ellip)都有一个标志 analog,允许设计模拟滤波器。
下面的示例设计了一个模拟(IIR)滤波器,通过 tf2zpk 获取极点和零点,并在复 s 平面上绘制它们。在幅度响应中可以清楚地看到在 \(\omega \approx 150\) 和 \(\omega \approx 300\) 处的零点。
- alt:
“此代码显示了两个图。第一个图是IIR滤波器的响应,以X-Y图表示,Y轴为幅度响应,X轴为频率。所显示的低通滤波器的通带从0到100 Hz,响应为0 dB,阻带从约175 Hz到1 KHz,下降约40 dB。滤波器在175 Hz和300 Hz附近有两个明显的间断点。第二个图是X-Y图,显示了复平面中的传递函数。Y轴为实数值,X轴为复数值。滤波器在[300+0j, 175+0j, -175+0j, -300+0j]附近有四个零点,用蓝色X标记表示。滤波器在[50-30j, -50-30j, 100-8j, -100-8j]附近也有四个极点,用红色点表示。”
>>> import numpy as np >>> import scipy.signal as signal >>> import matplotlib.pyplot as plt
>>> b, a = signal.iirdesign(wp=100, ws=200, gpass=2.0, gstop=40., analog=True) >>> w, h = signal.freqs(b, a)
>>> plt.title('模拟滤波器频率响应') >>> plt.plot(w, 20*np.log10(np.abs(h))) >>> plt.ylabel('幅度响应 [dB]') >>> plt.xlabel('频率') >>> plt.grid() >>> plt.show()
>>> z, p, k = signal.tf2zpk(b, a)
>>> plt.plot(np.real(z), np.imag(z), 'ob', markerfacecolor='none') >>> plt.plot(np.real(p), np.imag(p), 'xr') >>> plt.legend(['零点', '极点'], loc=2)
>>> plt.title('极点/零点图') >>> plt.xlabel('实部') >>> plt.ylabel('虚部') >>> plt.grid() >>> plt.show()
谱分析#
谱分析指的是研究信号的傅里叶变换 [1]。根据上下文,傅里叶变换的各种谱表示有不同的名称,如频谱、谱密度或周期图等。[2] 本节通过一个固定持续时间的连续时间正弦波信号的例子来说明最常见的表示方法。然后讨论在采样版本的正弦波上使用离散傅里叶变换 [3]。
本节分别用单独的小节讨论了频谱的相位、估计功率谱密度(不进行平均 (periodogram) 和进行平均 (welch))以及非等间隔信号 (lombscargle)。
需要注意的是,傅里叶级数的概念与此密切相关,但在一个关键点上有所不同:傅里叶级数的频谱由离散频率的谐波组成,而本节中的频谱在频率上是连续的。
连续时间正弦信号#
考虑一个幅度为 \(a\)、频率为 \(f_x\) 和持续时间为 \(\tau\) 的正弦信号,即
由于 \(\rect(t)\) 函数在 \(|t|<1/2\) 时为1,在 \(|t|>1/2\) 时为0,它将 \(x(t)\) 限制在区间 \([0, \tau]\) 内。通过将正弦函数用复指数表示,可以看出它具有频率为 \(\pm f_x\) 的两个周期分量。我们假设 \(x(t)\) 是一个电压信号,因此它具有单位 \(\text{V}\)。
在信号处理中,利用绝对平方 \(|x(t)|^2\) 的积分来定义信号的能量和功率,即
功率 \(P_x\) 可以解释为单位时间间隔内的能量 \(E_x\)。从单位上看,对 \(t\) 积分相当于乘以秒。因此,\(E_x\) 的单位为 \(\text{V}^2\text{s}\),而 \(P_x\) 的单位为 \(\text{V}^2\)。
对 \(x(t)\) 应用傅里叶变换,即
结果得到两个以 \(\pm f_x\) 为中心的 \(\sinc(f) := \sin(\pi f) /(\pi f)\) 函数。幅度(绝对值) \(|X(f)|\) 在 \(\pm f_x\) 处有两个最大值,值为 \(|a|\tau/2\)。从下图可以看出,\(X(f)\) 并不集中在 \(\pm f_x\) 的主瓣周围,而是包含高度与 \(1/(\tau f)\) 成比例减小的旁瓣。这种所谓的“频谱泄漏” [4] 是由于将正弦信号限制在有限区间内造成的。注意,信号持续时间 \(\tau\) 越短,泄漏越大。为了与信号持续时间无关,所谓的“幅度谱” \(X(f)/\tau\) 可以用来代替频谱 \(X(f)\)。它在 \(f\) 处的值对应于复指数 \(\exp(\jj2\pi f t)\) 的幅度。
由于帕塞瓦尔定理,能量可以通过其傅里叶变换 \(X(f)\) 计算为
同样地,例如,可以通过直接计算证明,方程 (4) 中 \(X(f)\) 的能量是 \(|a|^2\tau/2\)。因此,信号在频率带 \([f_a, f_b]\) 内的功率可以通过以下公式确定:
因此,函数 \(|X(f)|^2\) 可以定义为所谓的“能量谱密度”,而 \(S_{xx}(f) := |X(f)|^2 / \tau\) 可以定义为 \(x(t)\) 的“功率谱密度”(PSD)。除了PSD,所谓的“幅度谱密度” \(X(f) / \sqrt{\tau}\) 也被使用,它仍然包含相位信息。其绝对平方是PSD,因此它与信号的均方根(RMS)值 \(\sqrt{P_x}\) 的概念密切相关。
总之,本小节介绍了五种表示频谱的方法:
功率谱密度 (PSD)
幅度谱密度
定义:
\(X(f)\)
\(X(f) / \tau\)
\(|X(f)|^2\)
\(|X(f)|^2 / \tau\)
\(X(f) / \sqrt{\tau}\)
在 \(\pm f_x\) 处的幅度:
\(\frac{1}{2}|a|\tau\)
\(\frac{1}{2}|a|\)
\(\frac{1}{4}|a|^2\tau^2\)
\(\frac{1}{4}|a|^2\tau\)
\(\frac{1}{2}|a|\sqrt{\tau}\)
单位:
\(\text{V} / \text{Hz}\)
\(\text{V}\)
\(\text{V}^2\text{s} / \text{Hz}\)
\(\text{V}^2 / \text{Hz}\)
\(\text{V} / \sqrt{\text{Hz}}\)
请注意,上表中列出的单位并不明确,例如,\(\text{V}^2\text{s} / \text{Hz} = \text{V}^2\text{s}^2 = \text{V}^2/ \text{Hz}^2\)。当使用幅度谱的绝对值 \(|X(f) / \tau|\) 时,它被称为幅度谱。此外,请注意,表示法的命名方案并不一致,并且在文献中有所不同。
对于实值信号,通常使用所谓的“单边”频谱表示。它仅使用非负频率(由于 \(X(-f)= \conj{X}(f)\) 如果 \(x(t)\in\IR\))。有时,负频率的值会加到它们的正频率对应值上。然后,幅度谱允许读取 \(x(t)\) 在 \(f_z\) 处的完整(不是一半)幅度正弦,而 PSD 中区间面积表示其完整(不是一半)功率。请注意,对于幅度谱密度,正数值不会加倍,而是乘以 \(\sqrt{2}\),因为它是 PSD 的平方根。此外,没有一种规范的方法来命名加倍的频谱。
下图显示了四个具有不同幅度 \(a\) 和持续时间 \(\tau\) 的正弦信号 \(x(t)\) 的 Eq. (1) 的三种不同频谱表示。为了减少混乱,频谱以 \(f_z\) 为中心。 并且它们被绘制在彼此相邻的位置:
import matplotlib.pyplot as plt
import numpy as np
aa = [1, 1, 2, 2] # amplitudes
taus = [1, 2, 1, 2] # durations
fg0, axx = plt.subplots(3, 1, sharex='all', tight_layout=True, figsize=(6., 4.))
axx[0].set(title=r"Spectrum $|X(f)|$", ylabel="V/Hz")
axx[1].set(title=r"Magnitude Spectrum $|X(f)/\tau|$ ", ylabel=r"V")
axx[2].set(title=r"Amplitude Spectral Density $|X(f)/\sqrt{\tau}|$",
ylabel=r"$\operatorname{V} / \sqrt{\operatorname{Hz}}$",
xlabel="Frequency $f$ in Hertz",)
x_labels, x_ticks = [], []
f = np.linspace(-2.5, 2.5, 400)
for c_, (a_, tau_) in enumerate(zip(aa, taus), start=1):
aZ_, f_ = abs(a_ * tau_ * np.sinc(tau_ * f) / 2), f + c_ * 5
axx[0].plot(f_, aZ_)
axx[1].plot(f_, aZ_ / tau_)
axx[2].plot(f_, aZ_ / np.sqrt(tau_))
x_labels.append(rf"$a={a_:g}$, $\tau={tau_:g}$")
x_ticks.append(c_ * 5)
axx[2].set_xticks(x_ticks)
axx[2].set_xticklabels(x_labels)
plt.show()
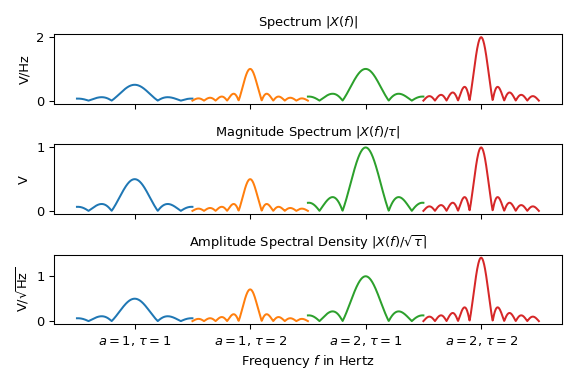
请注意,根据表示方式的不同,峰值的高度会有所变化。只有幅度谱的解释是直接的:第二个图中在 \(f_z\) 处的峰值表示正弦信号幅度 \(|a|\) 的一半。对于所有其他表示方式,需要考虑持续时间 \(\tau\) 以提取有关信号幅度的信息。
采样正弦信号#
在实践中,采样信号被广泛使用。即,信号由 \(n\) 个样本 \(x_k := x(kT)\) 表示,其中 \(k=0, \ldots, n-1\),\(T\) 是采样间隔,\(\tau:=nT\) 是信号的持续时间,\(f_S := 1/T\) 是采样频率。请注意,连续信号需要限制在 \([-f_S/2, f_S/2]\) 以避免混叠,其中 \(f_S/2\) 称为奈奎斯特频率。 [5] 通过用求和代替积分来计算信号的能量和功率,即
得到与连续时间情况下的公式 (2) 相同的结果。离散傅里叶变换(DFT)及其逆变换(使用 scipy.fft 模块中的高效 FFT 计算实现)由以下公式给出
DFT 可以解释为连续傅里叶变换的未缩放采样版本,如公式 (3) 所示,即
以下图显示了两个单位幅度正弦信号的幅度谱 和20 Hz和20.5 Hz的频率。信号由 \(n=100\) 个样本组成,采样间隔为 \(T=10\) 毫秒,导致持续时间为 \(\tau=1\) 秒,采样频率为 \(f_S=100\) Hz。
import matplotlib.pyplot as plt
import numpy as np
from scipy.fft import rfft, rfftfreq
n, T = 100, 0.01 # number of samples and sampling interval
fcc = (20, 20.5) # frequencies of sines
t = np.arange(n) * T
xx = (np.sin(2 * np.pi * fx_ * t) for fx_ in fcc) # sine signals
f = rfftfreq(n, T) # frequency bins range from 0 Hz to Nyquist freq.
XX = (rfft(x_) / n for x_ in xx) # one-sided magnitude spectrum
fg1, ax1 = plt.subplots(1, 1, tight_layout=True, figsize=(6., 3.))
ax1.set(title=r"Magnitude Spectrum (no window) of $x(t) = \sin(2\pi f_x t)$ ",
xlabel=rf"Frequency $f$ in Hertz (bin width $\Delta f = {f[1]}\,$Hz)",
ylabel=r"Magnitude $|X(f)|/\tau$", xlim=(f[0], f[-1]))
for X_, fc_, m_ in zip(XX, fcc, ('x-', '.-')):
ax1.plot(f, abs(X_), m_, label=rf"$f_x={fc_}\,$Hz")
ax1.grid(True)
ax1.legend()
plt.show()
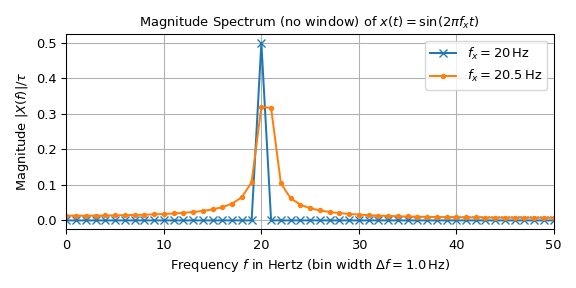
20 Hz信号的解释似乎很简单:除了在20 Hz处,所有值均为零。在20 Hz处,其值为0.5,这对应于输入信号振幅的一半,符合公式 (1)。另一方面,20.5 Hz信号的峰值沿频率轴分散。公式 (3) 表明,这种差异是由于20 Hz是1 Hz的箱宽的倍数,而20.5 Hz不是。以下图示通过将连续谱叠加在采样谱上来说明这一点:
import matplotlib.pyplot as plt
import numpy as np
from scipy.fft import rfft, rfftfreq
n, T = 100, 0.01 # number of samples and sampling interval
tau = n*T
t = np.arange(n) * T
fcc = (20, 20.5) # frequencies of sines
xx = (np.sin(2 * np.pi * fc_ * t) for fc_ in fcc) # sine signals
f = rfftfreq(n, T) # frequency bins range from 0 Hz to Nyquist freq.
XX = (rfft(x_) / n for x_ in xx) # one-sided FFT normalized to magnitude
i0, i1 = 15, 25
f_cont = np.linspace(f[i0], f[i1], 501)
fg1, axx = plt.subplots(1, 2, sharey='all', tight_layout=True,
figsize=(6., 3.))
for c_, (ax_, X_, fx_) in enumerate(zip(axx, XX, fcc)):
Xc_ = (np.sinc(tau * (f_cont - fx_)) +
np.sinc(tau * (f_cont + fx_))) / 2
ax_.plot(f_cont, abs(Xc_), f'-C{c_}', alpha=.5, label=rf"$f_x={fx_}\,$Hz")
m_line, _, _, = ax_.stem(f[i0:i1+1], abs(X_[i0:i1+1]), markerfmt=f'dC{c_}',
linefmt=f'-C{c_}', basefmt=' ')
plt.setp(m_line, markersize=5)
ax_.legend(loc='upper left', frameon=False)
ax_.set(xlabel="Frequency $f$ in Hertz", xlim=(f[i0], f[i1]),
ylim=(0, 0.59))
axx[0].set(ylabel=r'Magnitude $|X(f)/\tau|$')
fg1.suptitle("Continuous and Sampled Magnitude Spectrum ", x=0.55, y=0.93)
fg1.tight_layout()
plt.show()
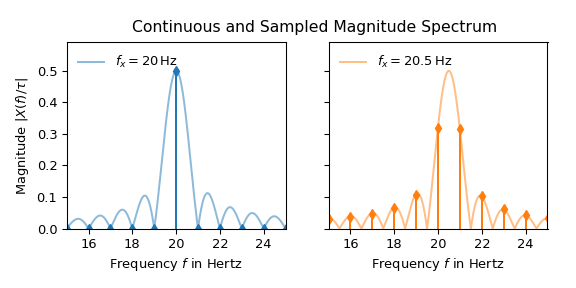
频率的微小变化导致幅度谱显著不同的外观显然是许多实际应用中不希望的行为。以下两种常见技术可用于改善频谱:
所谓的“零填充”通过在信号末尾附加零来减小 \(\Delta f\)。要过采样频率 q 倍,请将参数 n=q*n_x 传递给 fft / rfft 函数,其中 n_x 是输入信号的长度。
第二种技术称为加窗,即,将输入信号与合适的函数相乘,以通常抑制次级旁瓣为代价加宽主瓣。加窗DFT可以表示为
其中 \(w_k\), \(k=0,\ldots,n-1\) 是采样的窗函数。为了计算前一小节中给出的频谱表示的采样版本, 以下归一化常数
需要被利用。第一个常数确保频谱中的峰值与该频率处信号的幅度一致。例如,幅度谱可以表示为 \(|X^w_l / c^\text{amp}|\)。第二个常数保证如公式 (5) 所定义的频率区间的功率是一致的。由于不允许使用复数值窗,因此需要绝对值。
以下图表展示了应用 hann 窗和三次过采样到 \(x(t)\) 的结果:
import matplotlib.pyplot as plt
import numpy as np
from scipy.fft import rfft, rfftfreq
from scipy.signal.windows import hann
n, T = 100, 0.01 # number of samples and sampling interval
tau = n*T
q = 3 # over-sampling factor
t = np.arange(n) * T
fcc = (20, 20.5) # frequencies of sines
xx = [np.sin(2 * np.pi * fc_ * t) for fc_ in fcc] # sine signals
w = hann(n)
c_w = abs(sum(w)) # normalize constant for window
f_X = rfftfreq(n, T) # frequency bins range from 0 Hz to Nyquist freq.
XX = (rfft(x_ * w) / c_w for x_ in xx) # one-sided amplitude spectrum
# Oversampled spectrum:
f_Y = rfftfreq(n*q, T) # frequency bins range from 0 Hz to Nyquist freq.
YY = (rfft(x_ * w, n=q*n) / c_w for x_ in xx) # one-sided magnitude spectrum
i0, i1 = 15, 25
j0, j1 = i0*q, i1*q
fg1, axx = plt.subplots(1, 2, sharey='all', tight_layout=True,
figsize=(6., 3.))
for c_, (ax_, X_, Y_, fx_) in enumerate(zip(axx, XX, YY, fcc)):
ax_.plot(f_Y[j0:j1 + 1], abs(Y_[j0:j1 + 1]), f'.-C{c_}',
label=rf"$f_x={fx_}\,$Hz")
m_ln, s_ln, _, = ax_.stem(f_X[i0:i1 + 1], abs(X_[i0:i1 + 1]), basefmt=' ',
markerfmt=f'dC{c_}', linefmt=f'-C{c_}')
plt.setp(m_ln, markersize=5)
plt.setp(s_ln, alpha=0.5)
ax_.legend(loc='upper left', frameon=False)
ax_.set(xlabel="Frequency $f$ in Hertz", xlim=(f_X[15], f_X[25]),
ylim=(0, 0.59))
axx[0].set(ylabel=r'Magnitude $|X(f)/\tau|$')
fg1.suptitle(r"Magnitude Spectrum (Hann window, $%d\times$oversampled)" % q,
x=0.55, y=0.93)
plt.show()
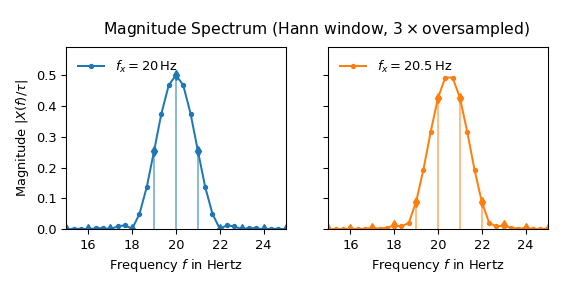
现在两个主瓣看起来几乎相同,旁瓣也得到了很好的抑制。20.5 Hz 频谱的最大值也非常接近预期的一半高度。
频谱能量和频谱功率可以类似地根据公式 (4) 计算,得到相同的结果,即
这种表述不应与矩形窗(或无窗)的特殊情况混淆,即 \(w_k = 1\),\(X^w_l=X_l\),\(c^\text{den}=\sqrt{n}\),这将导致
加窗的频率离散功率谱密度
在频率范围 \([0, f_S)\) 上定义,可以解释为每频率间隔 \(\Delta f\) 的功率。在频率带 \([l_a\Delta f, l_b\Delta f)\) 上积分,如公式 (5) 所示,变为求和
加窗频率离散能量谱密度 \(\tau S^w_{xx}\) 可以类似地定义。
上述讨论表明,可以定义连续时间情况下谱表示的采样版本。下表总结了这些:
谱 |
幅度谱 |
能量谱密度 |
功率谱密度 (PSD) |
幅度谱密度 |
|
|---|---|---|---|---|---|
定义: |
\(\tau X^w_l / c^\text{amp}\) |
\(X^w_l / c^\text{amp}\) |
\(\tau T |X^w_l / c^\text{den}|^2\) |
\(T |X^w_l / c^\text{den}|^2\) |
\(\sqrt{T} X^w_l / c^\text{den}\) |
单位: |
\(\text{V} / \text{Hz}\) |
\(\text{V}\) |
\(\text{V}^2\text{s} / \text{Hz}\) |
\(\text{V}^2 / \text{Hz}\) |
\(\text{V} / \sqrt{\text{Hz}}\) |
请注意,对于密度,\(\pm f_x\) 处的幅度值与连续时间情况不同,因为确定谱能量/功率时从积分变为求和。
尽管汉宁窗是最常见的用于谱分析的窗函数,
其他窗口函数也存在。下图展示了 windows 子模块中各种窗口函数的幅度谱。它可以被解释为单频输入信号的旁瓣形状。请注意,仅显示了右侧一半,并且 \(y\) 轴以分贝为单位,即它是按对数比例缩放的。
import matplotlib.pyplot as plt
import numpy as np
from scipy.fft import rfft, rfftfreq
from scipy.signal import get_window
n, n_zp = 128, 16384 # number of samples without and with zero-padding
t = np.arange(n)
f = rfftfreq(n_zp, 1 / n)
ww = ['boxcar', 'hann', 'hamming', 'tukey', 'blackman', 'flattop']
fg0, axx = plt.subplots(len(ww), 1, sharex='all', sharey='all', figsize=(6., 4.))
for c_, (w_name_, ax_) in enumerate(zip(ww, axx)):
w_ = get_window(w_name_, n, fftbins=False)
W_ = rfft(w_ / abs(sum(w_)), n=n_zp)
W_dB = 20*np.log10(np.maximum(abs(W_), 1e-250))
ax_.plot(f, W_dB, f'C{c_}-', label=w_name_)
ax_.text(0.1, -50, w_name_, color=f'C{c_}', verticalalignment='bottom',
horizontalalignment='left', bbox={'color': 'white', 'pad': 0})
ax_.set_yticks([-20, -60])
ax_.grid(axis='x')
axx[0].set_title("Spectral Leakage of various Windows")
fg0.supylabel(r"Normalized Magnitude $20\,\log_{10}|W(f)/c^\operatorname{amp}|$ in dB",
x=0.04, y=0.5, fontsize='medium')
axx[-1].set(xlabel=r"Normalized frequency $f/\Delta f$ in bins",
xlim=(0, 9), ylim=(-75, 3))
fg0.tight_layout(h_pad=0.4)
plt.show()
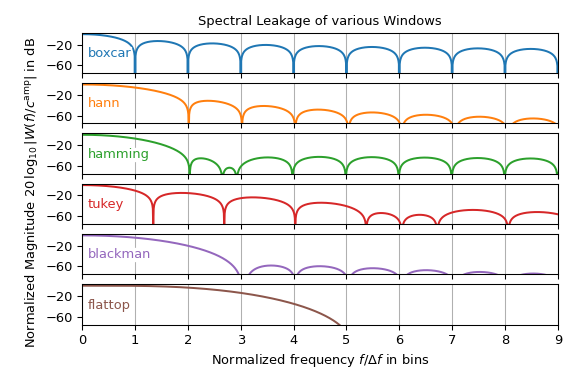
此图显示,窗口函数的选择通常是主瓣宽度和旁瓣高度之间的权衡。请注意,boxcar 窗口对应于 \(\rect\) 函数,即没有加窗。此外,图中所示的许多窗口在滤波器设计中比在频谱分析中更常用。
(来自 angle 的输出) 因此没有任何不连续性。这是通过使用 numpy.unwrap 函数实现的。如果已知滤波器的传递函数,可以使用 freqz 直接确定滤波器的频谱响应。
带平均的频谱#
periodogram 函数计算功率谱密度 (scaling='density') 或平方幅度谱 (scaling='spectrum')。要获得平滑的周期图,可以使用 welch 函数。它通过将输入信号分成重叠的段,然后计算每个段的加窗DFT来实现平滑。结果是这些DFT的平均值。
下面的示例展示了由一个幅度为 \(\sqrt{2}\,\text{V}\) 的 \(1.27\,\text{kHz}\) 正弦信号和具有均值为 \(10^{-3}\,\text{V}^2/\text{Hz}\) 的频谱功率密度的加性高斯噪声组成的信号的平方幅度谱和功率谱密度。
import matplotlib.pyplot as plt
import numpy as np
import scipy.signal as signal
rng = np.random.default_rng(73625) # seeding for reproducibility
fs, n = 10e3, 10_000
f_x, noise_power = 1270, 1e-3 * fs / 2
t = np.arange(n) / fs
x = (np.sqrt(2) * np.sin(2 * np.pi * f_x * t) +
rng.normal(scale=np.sqrt(noise_power), size=t.shape))
fg, axx = plt.subplots(1, 2, sharex='all', tight_layout=True, figsize=(7, 3.5))
axx[0].set(title="Squared Magnitude Spectrum", ylabel="Square of Magnitude in V²")
axx[1].set(title="Power Spectral Density", ylabel="Power Spectral Density in V²/Hz")
for ax_, s_ in zip(axx, ('spectrum', 'density')):
f_p, P_p = signal.periodogram(x, fs, 'hann', scaling=s_)
f_w, P_w = signal.welch(x, fs, scaling=s_)
ax_.semilogy(f_p/1e3, P_p, label=f"Periodogram ({len(f_p)} bins)")
ax_.semilogy(f_w/1e3, P_w, label=f"Welch's Method ({len(f_w)} bins)")
ax_.set(xlabel="Frequency in kHz", xlim=(0, 2), ylim=(1e-7, 1.3))
ax_.grid(True)
ax_.legend(loc='lower center')
plt.show()
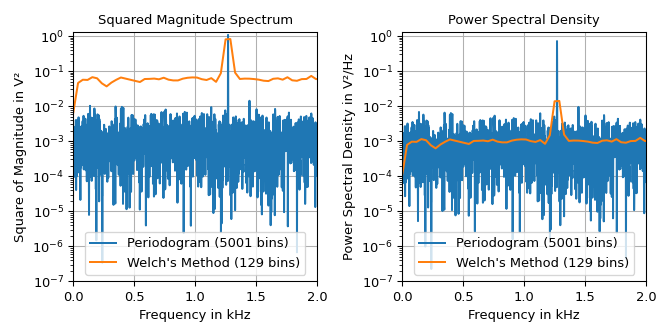
图中显示,welch 函数在牺牲频率分辨率的情况下产生了更平滑的噪声底。由于平滑,正弦波的波瓣宽度更宽,高度不如周期图中的高。左图可用于读取波瓣的高度,即正弦波平方幅度的 \(1\,\text{V}^2\) 的一半。右图可用于确定噪声底为 \(10^{-3}\,\text{V}^2/\text{Hz}\)。请注意,由于频率分辨率有限,平均平方幅度谱的波瓣高度并不完全为1。
可以通过零填充(例如,传递 nfft=4*len(x) 给 welch)或通过增加段长度来减少段数(设置参数 nperseg)来增加频率箱的数量。
Lomb-Scargle 周期图(lombscargle)#
最小二乘谱分析(LSSA)[#Lomb1976]_ [7] 是一种基于正弦波对数据样本进行最小二乘拟合来估计频谱的方法,类似于傅里叶分析。傅里叶分析是科学中最常用的频谱方法,通常会增强长周期噪声在长间隙记录中的影响;而 LSSA 可以缓解这些问题。
Lomb-Scargle 方法对不均匀采样的数据进行频谱分析,并且已知是一种发现和测试弱周期信号显著性的强大方法。
对于一个包含 \(N_{t}\) 个测量值 \(X_{j}\equiv X(t_{j})\) 的时间序列,采样时间为 \(t_{j}\),其中 \((j = 1, \ldots, N_{t})\),假设已经过缩放和移位,使其均值为零,方差为单位,频率 \(f\) 处的归一化 Lomb-Scargle 周期图为
这里,\(\omega \equiv 2\pi f\) 是角频率。频率相关的时移 \(\tau\) 由下式给出
lombscargle 函数使用 Townsend [8] 提出的略有修改的算法计算周期图,该算法允许周期图仅通过每个频率的输入数组进行一次传递来计算。
该方程被重构为:
以及
其中,
而求和为
这需要 \(N_{f}(2N_{t}+3)\) 次三角函数计算,比直接实现的速度提高了约 \(\sim 2\) 倍。
时间 \(t\) 然后通过频率 \(f\) 进行调制(即频率偏移)。 对于处理采样信号 \(x[k] := x(kT)\),\(k\in\IZ\),其中采样间隔 \(T`(即采样频率 `fs\) 的倒数), 需要使用离散版本,即仅在离散网格点上计算 STFT \(S[q, p] := S(q \Delta f, p\Delta t)\),\(q,p\in\IZ\)。它可以表示为
其中 p 表示时间索引 \(S\),时间间隔为 \(\Delta t := h T\),\(h\in\IN`(参见 `delta_t\)), 可以表示为 \(h\) 个样本的 hop 大小。\(q\) 表示频率索引 \(S\),步长为 \(\Delta f := 1 / (N T)\) (参见 delta_f),使其与 FFT 兼容。\(w[m] := w(mT)\),\(m\in\IZ\) 是采样的窗口函数。
为了更符合 |ShortTimeFFT| 的实现,将公式 (7) 重新表述为两步过程是有意义的:
通过窗口 \(w[m]\) 提取第 \(p\) 个切片,该窗口由 \(M\) 个样本组成(参见 m_num), 中心位于 \(t[p] := p \Delta t = h T`(参见 `delta_t\)),即
(8)#\[x_p[m] = x\!\big[m - \lfloor M/2\rfloor + h p\big]\, \conj{w[m]}\ , \quad m = 0, \ldots M-1\ ,\]其中整数 \(\lfloor M/2\rfloor\) 表示
M//2,即窗口的中点(m_num_mid)。为方便起见, 假设 \(x[k]:=0\) 对于 \(k\not\in\{0, 1, \ldots, N-1\}\)。在子节 滑动窗口 中, 详细讨论了切片的索引。然后对 \(x_p[m]\) 执行离散傅里叶变换(即 FFT)。
(9)#\[X_p[q] = \sum_{m=0}^{M-1} x_p[m]\, \e^{-\jj2\pi q m / M}\ , \quad q = 0, \ldots, M-1\ , S[q, p] = \sum_{m=0}^{M-1} x_p[m] \exp\!\big\{% -2\jj\pi (q + \phi_m)\, m / M\big\}\ .\]注意,可以指定线性相位 \(\phi_m`(参见 `phase_shift\)),这相当于将输入信号移动 \(\phi_m\) 个样本。默认值为 \(\phi_m = \lfloor M/2\rfloor`(根据定义对应于 ``phase_shift = 0`\)),这会抑制未移位信号的线性相位分量。 此外,可以通过用零填充 \(w[m]\) 来对 FFT 进行过采样。这可以通过指定 mfft 大于窗口长度 m_num 来实现——这将 \(M\) 设置为 mfft`(这意味着对于 :math:`mnotin{0, 1, ldots, M-1},\(w[m]:=0\) 也成立)。
逆短时傅里叶变换(istft)通过反转这两个步骤来实现:
执行逆离散傅里叶变换,即
\[x_p[m] = \frac{1}{M}\sum_{q=0}^M S[q, p]\, \exp\!\big\{ 2\jj\pi (q + \phi_m)\, m / M\big\}\ .\]将加权后的移位切片求和以重建原始信号,即
\[x[k] = \sum_p x_p\!\big[\mu_p(k)\big]\, w_d\!\big[\mu_p(k)\big]\ ,\quad \mu_p(k) = k + \lfloor M/2\rfloor - h p\]对于 \(k \in [0, \ldots, n-1]\)。\(w_d[m]\) 是 \(w[m]\) 的所谓对偶窗口,并且也由 \(M\) 个样本组成。
请注意,并非所有窗口和跳跃大小都存在逆 STFT。对于给定的窗口 \(w[m]\),跳跃大小 \(h\) 必须足够小,以确保 \(x[k]\) 的每个样本至少被一个窗口切片中的非零值触及。这有时被称为“非零重叠条件”(参见 check_NOLA)。更多细节在子节 逆STFT与对偶窗 中给出。
滑动窗口#
本小节通过一个示例讨论了在|ShortTimeFFT|中滑动窗口的索引方式:考虑一个长度为6的窗口,hop`间隔为2,采样间隔`T`为1,例如``ShortTimeFFT(np.ones(6), 2, fs=1)`。下图示意性地描绘了前四个窗口位置,也称为时间切片:

x轴表示时间 \(t\),对应于底部蓝色方框指示的样本索引`k`。y轴表示时间切片索引 \(p\)。信号 \(x[k]\) 从索引 \(k=0\) 开始,并以浅蓝色背景标记。根据定义,第零切片(\(p=0\))以 \(t=0\) 为中心。每个切片的中心(m_num_mid),此处为样本 6//2=3,由文本“mid”标记。默认情况下,stft 计算与信号有部分重叠的所有切片。因此,第一个切片在 p_min = -1,最低样本索引为 k_min = -5。第一个不受切片影响的样本索引是 \(p_{lb} = 2\),第一个不受边界效应影响的样本索引是 \(k_{lb} = 5\)。属性 lower_border_end 返回元组 \((k_{lb}, p_{lb})\)。
信号末端的行为在下图中描绘,信号包含 \(n=50\) 个样本,如蓝色背景所示:

这里最后一个切片的索引为 \(p=26\)。因此,遵循Python 结束索引超出范围的约定,p_max = 27 表示第一个不触及信号的切片。对应的样本索引是 k_max = 55。第一个向右突出的切片是 \(p_{ub} = 24\),其第一个样本在 \(k_{ub}=45\)。函数 upper_border_begin 返回元组 \((k_{ub}, p_{ub})\)。
逆STFT与对偶窗#
术语“对偶窗”源自框架理论 [10],其中框架是一种序列展开,可以在给定的希尔伯特空间中表示任何函数。在那里,如果对于给定希尔伯特空间 \(\mathcal{H}\) 中的所有函数 \(f\),展开式 \(\{g_k\}\) 和 \(\{h_k\}\) 是对偶框架,则
成立,其中 \(\langle ., .\rangle\) 表示 \(\mathcal{H}\) 的标量积。所有框架都有对偶框架 [10]。
仅在离散网格点 \(S(q \Delta f, p\Delta t)\) 处计算的STFT在文献中被称为“Gabor框架” [9] [10]。由于窗 \(w[m]\) 的支持限制在有限区间内,|ShortTimeFFT| 属于所谓的“无痛非正交展开”类别 [9]。在这种情况下,对偶窗总是具有相同的支持,并且可以通过对角矩阵的逆运算来计算。以下将概述一个仅需要一些矩阵操作理解的粗略推导:
由于公式 (7) 中给出的STFT是 \(x[k]\) 中的线性映射,因此可以用向量-矩阵表示法表示。这使我们能够通过线性最小二乘法的正式解来表示逆变换。
(如在 lstsq 中), 这导致了一个优美且简单的结果。
我们首先重新表述方程 (8) 的窗口化过程
其中,矩阵 \(\vb{W}_{\!p}\) 是一个 \(M\times N\) 的矩阵,只在 \((ph)\)-th 次对角线上有非零元素,即
其中 \(\delta_{k,l}\) 是克罗内克δ函数。方程 (9) 可以表示为
这使得第 \(p\) 个切片的STFT可以写成
注意 \(\vb{F}\) 是酉矩阵,即其逆等于其共轭转置,意味着 \(\conjT{\vb{F}}\vb{F} = \vb{I}\)。
为了得到STFT的单一向量-矩阵方程,将切片堆叠成一个向量,即
其中 \(P\) 是结果STFT的列数。为了反转这个过程 方程 摩尔-彭罗斯逆 \(\vb{G}^\dagger\) 可以被利用
如果存在
是可逆的。那么 \(\vb{x} = \vb{G}^\dagger\vb{G}\,\vb{x} = \inv{\conjT{\vb{G}}\vb{G}}\,\conjT{\vb{G}}\vb{G}\,\vb{x}\) 显然成立。 \(\vb{D}\) 总是一个对角矩阵,且对角线元素非负。 这一点在进一步简化 \(\vb{D}\) 时变得清晰
由于 \(\vb{F}\) 是酉矩阵。此外
表明 \(\vb{D}_p\) 是一个对角矩阵,且对角线元素非负。 因此,求和 \(\vb{D}_p\) 保持了这一性质。这允许进一步简化方程 (13),即
利用公式 (11)、(14)、 (15),\(\vb{U}_p=\vb{W}_{\!p}\vb{D}^{-1}\) 可以表示为
这表明 \(\vb{U}_p\) 与公式 (11) 中的 \(\vb{W}_p\) 具有相同的结构,即仅在 \((ph)\)-th 次对角线上有非零项。逆中的求和项可以解释为将 \(|w[\mu]|^2\) 滑动到 \(w[m]`(带有内置的反转),因此只有与 :math:`w[m]\) 重叠的成分才有影响。因此,所有远离边界的 \(U_p[m, k]\) 都是相同的窗口。为了避免边界效应,\(x[k]\) 用零填充,扩大 \(\vb{U}\) 以便所有接触 \(x[k]\) 的切片都包含相同的对偶窗口
由于 \(w[m] = 0\) 对于 \(m \not\in\{0, \ldots, M-1\}\) 成立,因此只需要对满足 \(|\eta| < M/h\) 的索引 \(\eta\) 求和。对偶窗口的名称可以通过将公式 (12) 插入公式 (16) 来证明,即
表明 \(\vb{U}_p\) 和 \(\vb{W}_{\!p}\) 是可互换的。 因此,\(w_d[m]\) 也是一个有效的窗口,其对偶窗口为 \(w[m]\)。 注意,\(w_d[m]\) 不是唯一的对偶窗口,因为 \(\vb{s}\) 通常比 \(\vb{x}\) 有更多的条目。可以证明,\(w_d[m]\) 具有最小的能量(或 \(L_2\) 范数)[#Groechenig2001]_,这也是它被称为“规范对偶窗口”的原因。
与旧版实现的比较#
函数 |old_stft|、|old_istft| 以及 |old_spectrogram| 早于 |ShortTimeFFT| 实现。本节讨论旧版“遗留”实现与新版 |ShortTimeFFT| 实现之间的主要区别。重写的主要动机是认识到如果不打破兼容性,就无法以合理的方式集成 对偶窗口。这为重新思考代码结构和参数化提供了机会,从而使一些隐含行为更加显式。
以下示例比较了具有负斜率的复值啁啾信号的两个STFT:
>>> import matplotlib.pyplot as plt
>>> import numpy as np
>>> from scipy.fft import fftshift
>>> from scipy.signal import stft, istft, spectrogram, ShortTimeFFT
...
>>> fs, N = 200, 1001 # 200 Hz采样率,5秒信号
>>> t_z = np.arange(N) / fs # 信号的时间索引
>>> z = np.exp(2j*np.pi*70 * (t_z - 0.2*t_z**2)) # 复值啁啾信号
...
>>> nperseg, noverlap = 50, 40
>>> win = ('gaussian', 1e-2 * fs) # 标准差为0.01秒的高斯窗口
...
>>> # 旧版STFT:
>>> f0_u, t0, Sz0_u = stft(z, fs, win, nperseg, noverlap,
… return_onesided=False, scaling=’spectrum’) >>> f0, Sz0 = fftshift(f0_u), fftshift(Sz0_u, axes=0) … >>> # 新的STFT: >>> SFT = ShortTimeFFT.from_window(win, fs, nperseg, noverlap, fft_mode=’centered’, … scale_to=’magnitude’, phase_shift=None) >>> Sz1 = SFT.stft(z) … >>> # 绘制结果: >>> fig1, axx = plt.subplots(2, 1, sharex=’all’, sharey=’all’, … figsize=(6., 5.)) # 稍微放大图形 >>> t_lo, t_hi, f_lo, f_hi = SFT.extent(N, center_bins=True) >>> axx[0].set_title(r”传统stft()生成 $%dtimes%d$ 点” % Sz0.T.shape) >>> axx[0].set_xlim(t_lo, t_hi) >>> axx[0].set_ylim(f_lo, f_hi) >>> axx[1].set_title(r”ShortTimeFFT生成 $%dtimes%d$ 点” % Sz1.T.shape) >>> axx[1].set_xlabel(rf”时间 $t$ 以秒为单位 ($Delta t= {SFT.delta_t:g},$s)”) … >>> # 计算绘图范围,因为imshow默认不进行插值: >>> dt2 = (nperseg-noverlap) / fs / 2 # 等于SFT.delta_t / 2 >>> df2 = fs / nperseg / 2 # 等于SFT.delta_f / 2 >>> extent0 = (-dt2, t0[-1] + dt2, f0[0] - df2, f0[-1] - df2) >>> extent1 = SFT.extent(N, center_bins=True) … >>> kw = dict(origin=’lower’, aspect=’auto’, cmap=’viridis’) >>> im1a = axx[0].imshow(abs(Sz0), extent=extent0, **kw) >>> im1b = axx[1].imshow(abs(Sz1), extent=extent1, **kw) >>> fig1.colorbar(im1b, ax=axx, label=”幅度 $|S_z(t, f)|$”) >>> _ = fig1.supylabel(r”频率 $f$ 以赫兹为单位 ($Delta f = %g,$Hz)” % … SFT.delta_f, x=0.08, y=0.5, fontsize=’medium’) >>> plt.show()
|ShortTimeFFT| 比传统版本多生成3个时间切片是主要的区别。正如在 滑动窗口 部分所述,新版本中包含了所有触及信号的切片。 这具有以下优点:STFT可以像在 |ShortTimeFFT| 代码示例中展示的那样进行切片和重新组装。此外,使用所有相邻切片使得在某些窗口为零的情况下,ISTFT更加稳健。
请注意,具有相同时间戳的切片会产生相同的结果(在数值精度范围内),即:
>>> np.allclose(Sz0, Sz1[:, 2:-1])
True
通常,这些额外的切片包含非零值。由于在我们的示例中重叠较大,它们非常小。例如:
>>> abs(Sz1[:, 1]).min(), abs(Sz1[:, 1]).max()
(6.925060911593139e-07, 8.00271269218721e-07)
ISTFT可以用于重建原始信号:
>>> t0_r, z0_r = istft(Sz0_u, fs, win, nperseg, noverlap,
... input_onesided=False, scaling='spectrum')
>>> z1_r = SFT.istft(Sz1, k1=N)
...
>>> len(z0_r), len(z)
(1010, 1001)
>>> np.allclose(z0_r[:N], z)
True
>>> np.allclose(z1_r, z)
True
请注意,旧版实现返回的信号比原始信号更长。另一方面,新的 istft 允许显式指定重建信号的开始索引 k0 和结束索引 k1。旧版实现中的长度差异是由于信号长度不是切片的倍数造成的。
在此示例中,新版与旧版之间的进一步差异包括:
参数
fft_mode='centered'确保在绘图中,双边FFT的零频率垂直居中。使用旧版实现时,需要使用fftshift。fft_mode='twosided'产生与旧版相同的行为。参数
phase_shift=None确保两个版本的相位相同。|ShortTimeFFT| 的默认值0会产生带有额外线性相位项的STFT切片。
验证了本小节中所有计算值的正确性。
频谱图定义为STFT的绝对平方 [9]。|ShortTimeFFT| 提供的 spectrogram 遵循这一定义,即:
>>> np.allclose(SFT.spectrogram(z), abs(Sz1)**2)
True
另一方面,旧版 |old_spectrogram| 提供了另一种STFT实现,其关键区别在于对信号边界的不同处理方式。以下示例展示了如何使用 |ShortTimeFFT| 获得与旧版 |old_spectrogram| 生成的相同的SFT:
>>> # 旧版频谱图(对复信号去趋势无效):
>>> f2_u, t2, Sz2_u = spectrogram(z, fs, win, nperseg, noverlap,
... detrend=None, return_onesided=False,
... scaling='spectrum', mode='complex')
>>> f2, Sz2 = fftshift(f2_u), fftshift(Sz2_u, axes=0)
...
>>> # 新版STFT:
... SFT = ShortTimeFFT.from_window(win, fs, nperseg, noverlap,
... fft_mode='centered',
... scale_to='magnitude', phase_shift=None)
>>> Sz3 = SFT.stft(z, p0=0, p1=(N-noverlap)//SFT.hop, k_offset=nperseg//2)
>>> t3 = SFT.t(N, p0=0, p1=(N-noverlap)//SFT.hop, k_offset=nperseg//2)
...
>>> np.allclose(t2, t3)
True
>>> np.allclose(f2, SFT.f)
True
>>> np.allclose(Sz2, Sz3)
True
与其他STFT的区别在于,时间切片不是从0开始,而是从 nperseg//2 开始,即:
>>> t2
array([0.125, 0.175, 0.225, 0.275, 0.325, 0.375, 0.425, 0.475, 0.525,
...
4.625, 4.675, 4.725, 4.775, 4.825, 4.875])
此外,仅返回不向右突出的切片,将最后一个切片中心定位在4.875秒处,这使得它比默认的 stft 参数化更短。
通过使用 mode 参数,旧版 |old_spectrogram| 还可以返回
‘angle’, ‘phase’, ‘psd’ 或 ‘magnitude’。旧版 |old_spectrogram| 的 scaling 行为并不直观,因为它取决于参数 mode、scaling 和 return_onesided。在 |ShortTimeFFT| 中,并非所有组合都有直接对应关系,因为它仅提供 ‘magnitude’、’psd’ 或完全不进行窗口缩放。下表展示了这些对应关系:
当对复数值输入信号使用``onesided``输出时,旧的|old_spectrogram|会切换到``two-sided``模式。|ShortTimeFFT|会引发一个:exc:TypeError,因为所使用的`~scipy.fft.rfft`函数仅接受实值输入。请参阅上面的:ref:`tutorial_SpectralAnalysis`部分,以讨论由各种参数化引起的各种频谱表示。
参考文献
一些进一步阅读和相关软件: