skimage.measure#
用指定的容差近似多边形链。 |
|
通过将函数 func 应用于局部块来对图像进行下采样。 |
|
计算一个指标,该指标表示图像中的模糊强度(0 表示无模糊,1 表示最大模糊)。 |
|
返回图像的(加权)质心。 |
|
计算二值图像中的欧拉特性。 |
|
在给定级别值的情况下,在二维数组中找到等值轮廓。 |
|
测试指定网格上的点是否在多边形内部。 |
|
计算输入图像的惯性张量。 |
|
计算图像惯性张量的特征值。 |
|
一个通道的分段二进制掩码与第二个通道的分段二进制掩码重叠的部分。 |
|
标记整数数组的连通区域。 |
|
Manders 的两个通道间的共定位系数。 |
|
Manders' 重叠系数 |
|
Marching cubes 算法用于在三维体数据中寻找表面。 |
|
计算表面积,给定顶点和三角形面。 |
|
计算所有原始图像矩,直到某个特定阶数。 |
|
计算所有中心图像矩,直到某个特定阶数。 |
|
计算所有原始图像矩,直到某个特定阶数。 |
|
计算所有中心图像矩,直到某个特定阶数。 |
|
计算图像的 Hu 矩集(仅限 2D)。 |
|
计算所有归一化的中心图像矩,直到某个特定阶数。 |
|
计算通道中像素强度之间的皮尔逊相关系数。 |
|
计算二值图像中所有对象的总周长。 |
|
计算二值图像中所有对象的总Crofton周长。 |
|
测试点是否位于多边形内部。 |
|
返回沿扫描线测量的图像的强度分布。 |
|
使用 RANSAC(随机样本一致性)算法将模型拟合到数据。 |
|
测量标记图像区域的属性。 |
|
计算图像属性并将它们作为与pandas兼容的表格返回。 |
|
计算图像的香农熵。 |
|
使用B样条细分多边形曲线。 |
|
二维圆的总体最小二乘估计器。 |
|
二维椭圆的总最小二乘估计器。 |
|
N 维直线的总最小二乘估计器。 |
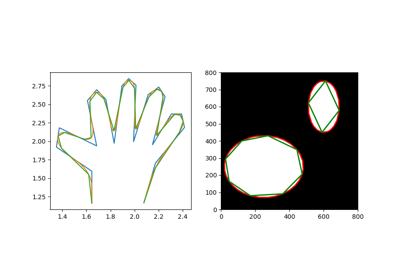
- skimage.measure.approximate_polygon(coords, tolerance)[源代码][源代码]#
用指定的容差近似多边形链。
它基于Douglas-Peucker算法。
请注意,近似的多边形总是在原始多边形的凸包内。
- 参数:
- 坐标(K, 2) 数组
坐标数组。
- 容差浮动
多边形原始点到近似多边形链的最大距离。如果容差为0,则返回原始坐标数组。
- 返回:
- 坐标(L, 2) 数组
近似多边形链,其中 L <= K。
参考文献
- skimage.measure.block_reduce(image, block_size=2, func=<function sum>, cval=0, func_kwargs=None)[源代码][源代码]#
通过将函数 func 应用于局部块来对图像进行下采样。
例如,此功能对于最大池化和平均池化非常有用。
- 参数:
- 图像(M[, …]) ndarray
N 维输入图像。
- block_size类数组 或 整数
包含沿每个轴的下采样整数因子的数组。默认的 block_size 是 2。
- 函数可调用
用于计算每个局部块返回值的函数对象。此函数必须实现一个
axis参数。主要函数包括numpy.sum、numpy.min、numpy.max、numpy.mean和numpy.median。另请参阅 func_kwargs 。- cval浮动
如果图像不能被块大小整除,则使用常量填充值。
- func_kwargsdict
传递给 func 的关键字参数。特别适用于传递
np.mean的 dtype 参数。接受输入的字典,例如:func_kwargs={'dtype': np.float16})。
- 返回:
- 图像ndarray
下采样图像,其维度与输入图像相同。
示例
>>> from skimage.measure import block_reduce >>> image = np.arange(3*3*4).reshape(3, 3, 4) >>> image array([[[ 0, 1, 2, 3], [ 4, 5, 6, 7], [ 8, 9, 10, 11]], [[12, 13, 14, 15], [16, 17, 18, 19], [20, 21, 22, 23]], [[24, 25, 26, 27], [28, 29, 30, 31], [32, 33, 34, 35]]]) >>> block_reduce(image, block_size=(3, 3, 1), func=np.mean) array([[[16., 17., 18., 19.]]]) >>> image_max1 = block_reduce(image, block_size=(1, 3, 4), func=np.max) >>> image_max1 array([[[11]], [[23]], [[35]]]) >>> image_max2 = block_reduce(image, block_size=(3, 1, 4), func=np.max) >>> image_max2 array([[[27], [31], [35]]])
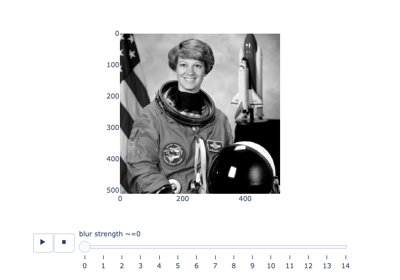
- skimage.measure.blur_effect(image, h_size=11, channel_axis=None, reduce_func=<function max>)[源代码][源代码]#
计算一个指标,该指标表示图像中的模糊强度(0 表示无模糊,1 表示最大模糊)。
- 参数:
- 图像ndarray
RGB 或灰度 nD 图像。输入图像在计算模糊度量之前被转换为灰度图像。
- h_sizeint, 可选
重新模糊滤镜的大小。
- channel_axisint 或 None, 可选
如果为 None,则假定图像是灰度图像(单通道)。否则,此参数指示数组中哪个轴对应于颜色通道。
- reduce_func可调用,可选
用于计算沿所有轴的模糊度量聚合的函数。如果设置为 None,则返回整个列表,其中第 i 个元素是沿第 i 个轴的模糊度量。
- 返回:
- 模糊浮点数 (0 到 1) 或浮点数列表
模糊度量:默认情况下,沿所有轴的模糊度量的最大值。
注释
h_size 必须保持相同的值,以便在图像之间比较结果。大多数情况下,默认大小(11)已经足够。这意味着该指标可以清晰地区分高达平均11x11滤镜的模糊;如果模糊度更高,该指标仍然能给出良好的结果,但其值趋向于渐近线。
参考文献
[1]Frederique Crete, Thierry Dolmiere, Patricia Ladret, 和 Marina Nicolas “模糊效果:使用新的无参考感知模糊度量进行感知和估计” Proc. SPIE 6492, 人类视觉与电子成像XII, 64920I (2007) https://hal.archives-ouvertes.fr/hal-00232709 DOI:10.1117/12.702790
- skimage.measure.centroid(image, *, spacing=None)[源代码][源代码]#
返回图像的(加权)质心。
- 参数:
- 图像数组
输入图像。
- spacing: 浮点数的元组, 形状 (ndim,)
图像沿每个轴的像素间距。
- 返回:
- center : 浮点数元组,长度为
image.ndim浮点数元组, 长度 image中(非零)像素的质心。
- center : 浮点数元组,长度为
示例
>>> image = np.zeros((20, 20), dtype=np.float64) >>> image[13:17, 13:17] = 0.5 >>> image[10:12, 10:12] = 1 >>> centroid(image) array([13.16666667, 13.16666667])
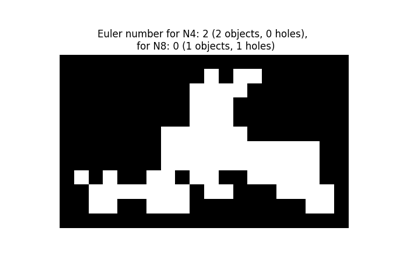
- skimage.measure.euler_number(image, connectivity=None)[源代码][源代码]#
计算二值图像中的欧拉特性。
对于二维物体,欧拉数是物体数量减去孔洞数量。对于三维物体,欧拉数是通过物体数量加上孔洞数量,再减去隧道或环的数量得到的。
- 参数:
- 图像: (M, N[, P]) ndarray
输入图像。如果图像不是二进制的,所有大于零的值都被视为对象。
- 连接性int, 可选
考虑将像素/体素视为邻居的最大正交跳数。接受的值范围从 1 到 input.ndim。如果为
None,则使用input.ndim的完全连通性。对于 2D 图像,定义了 4 或 8 个邻域(分别为连通性 1 和 2)。对于 3D 图像,定义了 6 或 26 个邻域(分别为连通性 1 和 3)。连通性 2 未定义。
- 返回:
- 欧拉数整数
图像中所有对象集合的欧拉特征数。
注释
欧拉特性是一个整数,描述了输入图像中所有对象集合的拓扑结构。如果对象是4连通的,那么背景是8连通的,反之亦然。
欧拉特性的计算基于离散空间中的积分几何公式。在实践中,构建一个邻域配置,并对每个配置应用一个LUT。使用的系数是Ohser等人提出的。
计算几种连通性的欧拉特性可能会有用。不同连通性的结果之间存在较大的相对差异,表明图像分辨率(相对于物体和孔洞的大小)过低。
参考文献
[1]S. Rivollier. Analyse d’image geometrique et morphometrique par diagrammes de forme et voisinages adaptatifs generaux. PhD thesis, 2010. Ecole Nationale Superieure des Mines de Saint-Etienne. https://tel.archives-ouvertes.fr/tel-00560838
[2]Ohser J., Nagel W., Schladitz K. (2002) 离散集合的欧拉数——关于均匀格中邻接选择的问题。在:Mecke K., Stoyan D. (编) 凝聚态的形态学。物理学讲义,第600卷。Springer, 柏林, 海德堡。
示例
>>> import numpy as np >>> SAMPLE = np.zeros((100,100,100)); >>> SAMPLE[40:60, 40:60, 40:60]=1 >>> euler_number(SAMPLE) 1... >>> SAMPLE[45:55,45:55,45:55] = 0; >>> euler_number(SAMPLE) 2... >>> SAMPLE = np.array([[0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 1, 1, 0, 0, 0, 0, 0], ... [0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0], ... [0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0], ... [0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0], ... [0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0], ... [0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0], ... [0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0], ... [1, 0, 1, 0, 0, 1, 1, 0, 1, 1, 0, 0, 1, 1, 1, 1, 1, 0], ... [0, 1, 1, 1, 1, 1, 1, 1, 0, 1, 1, 0, 0, 0, 1, 1, 1, 1], ... [0, 1, 1, 0, 0, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1]]) >>> euler_number(SAMPLE) # doctest: 0 >>> euler_number(SAMPLE, connectivity=1) # doctest: 2
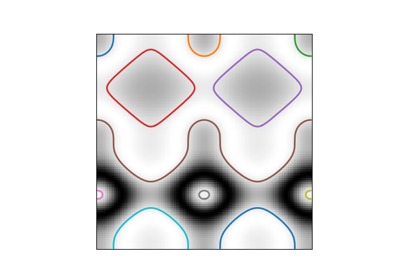
- skimage.measure.find_contours(image, level=None, fully_connected='low', positive_orientation='low', *, mask=None)[源代码][源代码]#
在给定级别值的情况下,在二维数组中找到等值轮廓。
使用“行进方块”方法计算输入2D数组在特定水平值下的等值轮廓。数组值通过线性插值以提供更好的输出轮廓精度。
- 参数:
- 图像(M, N) 双精度 ndarray
要在其中找到轮廓的输入图像。
- 级别float, 可选
在数组中查找等高线的值。默认情况下,级别设置为 (max(image) + min(image)) / 2
在 0.18 版本发生变更: 此参数现在是可选的。
- 全连接str, {‘low’, ‘high’}
指示是否将给定级别值以下的数组元素视为完全连接的(因此值以上的元素将仅面连接),反之亦然。(详情请参见下面的注释。)
- 正向方向str, {‘low’, ‘high’}
指示输出轮廓是否将围绕低值或高值元素的岛屿生成正向多边形。如果为 ‘low’,则轮廓将围绕低于等值线的元素逆时针旋转。换句话说,这意味着低值元素始终位于轮廓的左侧。(详情见下文。)
- 掩码(M, N) 布尔型 ndarray 或 None
一个布尔掩码,在我们想要绘制轮廓的地方为True。注意,NaN值总是被排除在考虑的区域之外(
mask在array为NaN的地方被设置为False)。
- 返回:
- 轮廓列表的 (K, 2) ndarrays
每个轮廓是一个
(行, 列)坐标的 ndarray,沿轮廓排列。
注释
行进方块算法是行进立方体算法的一个特例 [1] 。这里有一个简单的解释:
https://users.polytech.unice.fr/~lingrand/MarchingCubes/algo.html
在行进方块算法中,存在一个单一的模糊情况:当给定的
2 x 2元素方块有两对高值和低值元素,每对对角相邻时。(高值和低值是相对于所寻求的等高线值而言。)在这种情况下,高值元素可以通过一个细小的地峡’连接在一起’,从而分隔低值元素,反之亦然。当元素对角连接时,它们被认为是’完全连接’(也称为’面+顶点连接’或’8连接’)。只有高值或低值元素可以完全连接,另一组将被视为’面连接’或’4连接’。默认情况下,低值元素被认为是完全连接的;这可以通过’fully_connected’参数进行更改。输出的轮廓不保证是封闭的:与数组边缘或被屏蔽区域(无论是在掩码为 False 的地方,还是在数组为 NaN 的地方)相交的轮廓将保持开放。所有其他轮廓将是封闭的。(可以通过检查起点是否与终点相同来测试轮廓的封闭性。)
等高线是有方向的。默认情况下,数组值低于等高线值的部分位于等高线的左侧,而值高于等高线值的部分位于右侧。这意味着等高线将以逆时针方向(即’正方向’)围绕低值像素的岛屿旋转。此行为可以通过’positive_orientation’参数进行更改。
输出列表中轮廓的顺序由轮廓中最小的 ``x,y``(按字典顺序)坐标的位置决定。这是输入数组遍历方式的副作用,但可以依赖。
警告
数组坐标/值假定为指向数组元素的 中心 。以一个简单的输入为例:
[0, 1]。在这个数组中,0.5的插值位置位于0元素(在``x=0``处)和1元素(在``x=1``处)之间,因此会落在``x=0.5``处。这意味着要找到合理的轮廓,最好在预期的“亮”和“暗”值之间的中间位置找到轮廓。特别是,给定一个二值化数组,*不要*选择在数组的低值或高值处寻找轮廓。这通常会产生退化的轮廓,尤其是在宽度仅为一个数组元素的结构周围。相反,选择一个中间值,如上所述。
参考文献
[1]Lorensen, William 和 Harvey E. Cline. 移动立方体:一种高分辨率3D表面构造算法。计算机图形学(SIGGRAPH 87会议论文集)21(4) 1987年7月,第163-170页。 DOI:10.1145/37401.37422
示例
>>> a = np.zeros((3, 3)) >>> a[0, 0] = 1 >>> a array([[1., 0., 0.], [0., 0., 0.], [0., 0., 0.]]) >>> find_contours(a, 0.5) [array([[0. , 0.5], [0.5, 0. ]])]
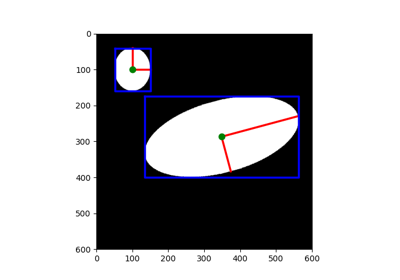
- skimage.measure.grid_points_in_poly(shape, verts, binarize=True)[源代码][源代码]#
测试指定网格上的点是否在多边形内部。
对于网格上的每个
(r, c)坐标,例如(0, 0)、(0, 1)等,测试该点是否位于多边形内部。你可以通过 binarize 标志控制输出类型。有关更多详细信息,请参阅其文档。
- 参数:
- 形状元组 (M, N)
网格的形状。
- verts(V, 2) 数组
指定多边形的 V 个顶点,按顺时针或逆时针排序。第一个点可以(但不需要)重复。
- binarize: bool
如果 True,函数的输出是一个布尔掩码。否则,它是一个带标签的数组。标签为:O - 外部,1 - 内部,2 - 顶点,3 - 边。
- 返回:
- 掩码(M, N) ndarray
如果 binarize 为 True,输出是一个布尔掩码。True 表示相应的像素位于多边形内部。如果 binarize 为 False,输出是一个标记数组,像素的标记值在 0 到 3 之间。各值的含义是:0 - 外部,1 - 内部,2 - 顶点,3 - 边。
- skimage.measure.inertia_tensor(image, mu=None, *, spacing=None)[源代码][源代码]#
计算输入图像的惯性张量。
- 参数:
- 图像数组
输入图像。
- mu数组,可选
image的预计算中心矩。惯性张量的计算需要图像的中心矩。如果应用程序同时需要中心矩和惯性张量(例如,skimage.measure.regionprops),那么预先计算它们并将它们传递给惯性张量调用会更有效。- spacing: 浮点数的元组, 形状 (ndim,)
图像沿每个轴的像素间距。
- 返回:
- T : 数组, 形状
(image.ndim, image.ndim)数组, 形状 输入图像的惯性张量。\(T_{i, j}\) 包含了沿轴 \(i\) 和 \(j\) 的图像强度协方差。
- T : 数组, 形状
参考文献
[2]Bernd Jähne. 时空图像处理:理论与科学应用。(第8章:张量方法)Springer, 1993.
- skimage.measure.inertia_tensor_eigvals(image, mu=None, T=None, *, spacing=None)[源代码][源代码]#
计算图像惯性张量的特征值。
惯性张量测量图像沿图像轴的强度协方差。(参见
inertia_tensor。)因此,张量特征值的相对大小是图像中(明亮)物体伸长度的度量。- 参数:
- 图像数组
输入图像。
- mu数组,可选
image的预计算中心矩。- T : 数组, 形状
(image.ndim, image.ndim)数组, 形状 预先计算的惯性张量。如果给出了
T,则忽略mu和image。- spacing: 浮点数的元组, 形状 (ndim,)
图像沿每个轴的像素间距。
- 返回:
- eigvals : 浮点数列表, 长度
image.ndim浮点数列表, 长度 image的惯性张量的特征值,按降序排列。
- eigvals : 浮点数列表, 长度
注释
计算特征值需要输入图像的惯性张量。如果提供了中心矩 (
mu),或者可以直接提供惯性张量 (T),这将大大加快计算速度。
- skimage.measure.intersection_coeff(image0_mask, image1_mask, mask=None)[源代码][源代码]#
一个通道的分段二进制掩码与第二个通道的分段二进制掩码重叠的部分。
- 参数:
- image0_mask(M, N) 的 dtype bool 的 ndarray
通道 A 的图像掩码。
- image1_mask(M, N) 的 dtype bool 的 ndarray
通道 B 的图像掩码。必须与 image0_mask 具有相同的尺寸。
- 掩码(M, N) 布尔类型的 ndarray,可选
只有 image0_mask 和 image1_mask 像素在这个感兴趣区域掩码内被包含在计算中。必须与 image0_mask 具有相同的维度。
- 返回:
- 交集系数, float
image0_mask 与 image1_mask 重叠的部分的比例。
- skimage.measure.label(label_image, background=None, return_num=False, connectivity=None)[源代码][源代码]#
标记整数数组的连通区域。
两个像素在它们是邻居并且具有相同值时是连通的。在二维空间中,它们可以是1-连通或2-连通的。值指的是考虑一个像素/体素为邻居的最大正交跳数:
1-connectivity 2-connectivity diagonal connection close-up [ ] [ ] [ ] [ ] [ ] | \ | / | <- hop 2 [ ]--[x]--[ ] [ ]--[x]--[ ] [x]--[ ] | / | \ hop 1 [ ] [ ] [ ] [ ]
- 参数:
- label_imagedtype 为 int 的 ndarray
图像到标签。
- 背景int, 可选
将所有具有此值的像素视为背景像素,并将其标记为 0。默认情况下,值为 0 的像素被视为背景像素。
- return_numbool, 可选
是否返回分配的标签数量。
- 连接性int, 可选
考虑将一个像素/体素视为邻居的最大正交跳数。接受的值范围从 1 到 input.ndim。如果为
None,则使用input.ndim的完全连通性。
- 返回:
- 标签dtype 为 int 的 ndarray
标记数组,其中所有相连的区域都被赋予相同的整数值。
- numint, 可选
标签的数量,等于最大标签索引,仅当 return_num 为 True 时返回。
参考文献
[1]Christophe Fiorio 和 Jens Gustedt,“两种用于图像处理的线性时间并查策略”,《理论计算机科学》154卷(1996年),第165-181页。
[2]Kensheng Wu, Ekow Otoo 和 Arie Shoshani, “优化连通分量标记算法”, 论文 LBNL-56864, 2005, 劳伦斯伯克利国家实验室 (加利福尼亚大学), http://repositories.cdlib.org/lbnl/LBNL-56864
示例
>>> import numpy as np >>> x = np.eye(3).astype(int) >>> print(x) [[1 0 0] [0 1 0] [0 0 1]] >>> print(label(x, connectivity=1)) [[1 0 0] [0 2 0] [0 0 3]] >>> print(label(x, connectivity=2)) [[1 0 0] [0 1 0] [0 0 1]] >>> print(label(x, background=-1)) [[1 2 2] [2 1 2] [2 2 1]] >>> x = np.array([[1, 0, 0], ... [1, 1, 5], ... [0, 0, 0]]) >>> print(label(x)) [[1 0 0] [1 1 2] [0 0 0]]

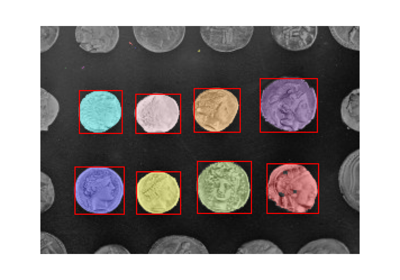


- skimage.measure.manders_coloc_coeff(image0, image1_mask, mask=None)[源代码][源代码]#
Manders 的两个通道间的共定位系数。
- 参数:
- image0(M, N) ndarray
通道A的图像。所有像素值应为非负值。
- image1_mask(M, N) 的 dtype bool 的 ndarray
在通道 B 中带有感兴趣区域的二进制掩码。必须与 image0 具有相同的尺寸。
- 掩码(M, N) 布尔类型的 ndarray,可选
只有 image0 在感兴趣区域掩码内的像素值被包含在计算中。必须与 image0 具有相同的尺寸。
- 返回:
- mcc浮动
Manders 的共定位系数。
注释
Manders 共定位系数 (MCC) 是某个通道(通道 A)的总强度在第二个通道(通道 B)的分割区域内的比例 [1]。其范围从无共定位的 0 到完全共定位的 1。它也被称为 M1 和 M2。
MCC 通常用于测量特定蛋白质在亚细胞区室中的共定位。通常,通过设置一个阈值来生成通道 B 的分割掩码,像素值必须高于该阈值才能包含在 MCC 计算中。在此实现中,通道 B 掩码作为参数 image1_mask 提供,允许用户事先决定确切的分割方法。
实现的方程是:
\[r = \frac{\sum A_{i,coloc}}{\sum A_i}\]- 哪里
\(A_i\) 是 image0 中第 \(i^{th}\) 像素的值,如果 \(Bmask_i > 0\),则 \(A_{i,coloc} = A_i\)。\(Bmask_i\) 是 mask 中第 \(i^{th}\) 像素的值。
MCC 对噪声敏感,第一通道中的扩散信号会夸大其值。在计算 MCC 之前,应对图像进行处理以去除失焦和背景光 [2]。
参考文献
[1]Manders, E.M.M., Verbeek, F.J. 和 Aten, J.A. (1993),双色共聚焦图像中物体共定位的测量。显微镜学杂志, 169: 375-382. https://doi.org/10.1111/j.1365-2818.1993.tb03313.x https://imagej.net/media/manders.pdf
[2]Dunn, K. W., Kamocka, M. M., & McDonald, J. H. (2011). 生物显微镜中评估共定位的实用指南。美国生理学杂志. 细胞生理学, 300(4), C723–C742. https://doi.org/10.1152/ajpcell.00462.2010
- skimage.measure.manders_overlap_coeff(image0, image1, mask=None)[源代码][源代码]#
Manders’ 重叠系数
- 参数:
- image0(M, N) ndarray
通道A的图像。所有像素值应为非负值。
- image1(M, N) ndarray
通道 B 的图像。所有像素值应为非负数。必须与 image0 具有相同的尺寸。
- 掩码(M, N) 布尔类型的 ndarray,可选
只有 image0 和 image1 在这个感兴趣区域掩码内的像素值被包含在计算中。必须与 image0 具有相同的维度。
- 返回:
- moc: 浮点数
Manders’ 重叠系数:两幅图像之间像素强度的重叠系数。
注释
Manders 的重叠系数 (MOC) 由方程 [1] 给出:
\[r = \frac{\sum A_i B_i}{\sqrt{\sum A_i^2 \sum B_i^2}}\]- 哪里
\(A_i\) 是 image0 中第 \(i^{th}\) 像素的值,\(B_i\) 是 image1 中第 \(i^{th}\) 像素的值。
其范围在0(表示没有共定位)到1(表示所有像素完全共定位)之间。
MOC 不考虑像素强度,只考虑两个通道中像素值为正的像素比例 [R2208c1a5d6e1-2] [3]。它的有用性受到了批评,因为它会随着共现性和相关性的差异而变化,因此一个特定的 MOC 值可能表示广泛的共定位模式 [4] [5]。
参考文献
[1]Manders, E.M.M., Verbeek, F.J. 和 Aten, J.A. (1993),双色共聚焦图像中物体共定位的测量。显微镜学杂志, 169: 375-382. https://doi.org/10.1111/j.1365-2818.1993.tb03313.x https://imagej.net/media/manders.pdf
[2]Dunn, K. W., Kamocka, M. M., & McDonald, J. H. (2011). 生物显微镜中评估共定位的实用指南。美国生理学杂志. 细胞生理学, 300(4), C723–C742. https://doi.org/10.1152/ajpcell.00462.2010
[3]Bolte, S. 和 Cordelières, F.P. (2006), 光显微镜下亚细胞共定位分析的导览。显微镜学杂志, 224: 213-232. https://doi.org/10.1111/j.1365-2818.2006.01
[4]Adler J, Parmryd I. (2010),通过相关性量化共定位:皮尔逊相关系数优于曼德尔重叠系数。细胞计量学A。8月;77(8):733-42.https://doi.org/10.1002/cyto.a.20896
[5]Adler, J, Parmryd, I. 定量共定位:应摒弃Manders重叠系数的案例。细胞测量学。2021; 99: 910–920. https://doi.org/10.1002/cyto.a.24336
- skimage.measure.marching_cubes(volume, level=None, *, spacing=(1.0, 1.0, 1.0), gradient_direction='descent', step_size=1, allow_degenerate=True, method='lewiner', mask=None)[源代码][源代码]#
Marching cubes 算法用于在三维体数据中寻找表面。
与 Lorensen 等人的方法 [2] 相比,Lewiner 等人的算法更快,解决了歧义,并保证了拓扑正确的结果。因此,该算法通常是一个更好的选择。
- 参数:
- 卷(M, N, P) ndarray
输入数据量以查找等值面。如果需要,将在内部转换为float32。
- 级别float, 可选
在 volume 中搜索等值面的轮廓值。如果未给出或为 None,则使用 vol 的最小值和最大值的平均值。
- 间距长度为3的浮点数元组,可选
体素间距在对应于 volume 中 numpy 数组索引维度 (M, N, P) 的空间维度中。
- gradient_direction字符串,可选
控制网格是否从等值面生成,使用梯度下降朝向感兴趣的对象(默认),或者相反,考虑*左手*规则。两个选项是:* 下降:对象大于外部 * 上升:外部大于对象
- 步长int, 可选
体素中的步长。默认值为1。较大的步长会更快但结果更粗糙。不过,结果将始终在拓扑上是正确的。
- allow_degeneratebool, 可选
是否允许最终结果中出现退化(即零面积)三角形。默认值为 True。如果为 False,则会移除退化三角形,但会降低算法的速度。
- 方法: {‘lewiner’, ‘lorensen’}, 可选
是否使用Lewiner等人的方法或Lorensen等人的方法。
- 掩码(M, N, P) 数组,可选
布尔数组。行进立方体算法将仅在 True 元素上计算。当接口位于体积 M、N、P 的特定区域(例如立方体的上半部分)时,这将节省计算时间,并且还允许计算有限表面(即不终止于立方体边界的开放表面)。
- 返回:
- verts(V, 3) 数组
V 个唯一网格顶点的空间坐标。坐标顺序与输入 volume (M, N, P) 匹配。如果
allow_degenerate设置为 True,则网格中退化三角形的存在可能导致此数组包含重复顶点。- 面孔(F, 3) 数组
通过引用
verts中的顶点索引来定义三角形面。该算法专门输出三角形,因此每个面正好有三个索引。- 法线(V, 3) 数组
每个顶点的法线方向,根据数据计算得出。
- 值(V,) 数组
给出每个顶点附近局部区域数据最大值的度量。可视化工具可以使用此度量将色图应用于网格。
注释
该算法 [1] 是 Chernyaev 的 Marching Cubes 33 算法的改进版本。它是一种高效的算法,依赖于大量使用查找表来处理许多不同的情况,从而使算法相对简单。此实现是用 Cython 编写的,移植自 Lewiner 的 C++ 实现。
要量化此算法生成的等值面的面积,请将顶点和面传递给
skimage.measure.mesh_surface_area。关于算法输出的可视化,要绘制名为 myvolume 的体积在水平 0.0 处的等高线,使用
mayavi包:>>> >> from mayavi import mlab >> verts, faces, _, _ = marching_cubes(myvolume, 0.0) >> mlab.triangular_mesh([vert[0] for vert in verts], [vert[1] for vert in verts], [vert[2] for vert in verts], faces) >> mlab.show()
同样地,使用
visvis包:>>> >> import visvis as vv >> verts, faces, normals, values = marching_cubes(myvolume, 0.0) >> vv.mesh(np.fliplr(verts), faces, normals, values) >> vv.use().Run()
为了减少网格中的三角形数量以提高性能,请参阅此 示例 ,该示例使用了
mayavi包。参考文献
[1]Thomas Lewiner, Helio Lopes, Antonio Wilson Vieira 和 Geovan Tavares. 带有拓扑保证的 Marching Cubes 案例的高效实现。图形工具杂志 8(2) pp. 1-15 (2003年12月)。 DOI:10.1080/10867651.2003.10487582
[2]Lorensen, William 和 Harvey E. Cline. 移动立方体:一种高分辨率3D表面构造算法。计算机图形学(SIGGRAPH 87会议论文集)21(4) 1987年7月,第163-170页。 DOI:10.1145/37401.37422
- skimage.measure.mesh_surface_area(verts, faces)[源代码][源代码]#
计算表面积,给定顶点和三角形面。
- 参数:
- verts(V, 3) 浮点数数组
包含 V 个唯一网格顶点坐标的数组。
- 面孔(F, 3) 的整数数组
长度为3的整数列表的列表,引用 verts 中提供的顶点坐标。
- 返回:
- 区域浮动
网格的表面积。单位现在是 [坐标单位] ** 2。
注释
此函数预期的参数是
skimage.measure.marching_cubes的前两个输出。为了获得单位正确的输出,请确保向skimage.measure.marching_cubes传递了正确的 spacing。该算法只有在提供的
faces都是三角形时才能正常工作。
- skimage.measure.moments(image, order=3, *, spacing=None)[源代码][源代码]#
计算所有原始图像矩,直到某个特定阶数。
- 以下属性可以从原始图像矩计算得出:
区域表示为:
M[0, 0]。质心为:{
M[1, 0] / M[0, 0],M[0, 1] / M[0, 0]}。
请注意,原始矩既不是平移、缩放也不是旋转不变的。
- 参数:
- 图像(N[, …]) 双精度或 uint8 数组
光栅化形状作为图像。
- 顺序int, 可选
矩的阶数最大值。默认是 3。
- spacing: 浮点数的元组, 形状 (ndim,)
图像沿每个轴的像素间距。
- 返回:
- m : (
order + 1,order + 1) 数组() 原始图像矩。
- m : (
参考文献
[1]Wilhelm Burger, Mark Burge. 数字图像处理原理:核心算法. Springer-Verlag, 伦敦, 2009.
[2]B. Jähne. Digital Image Processing. Springer-Verlag, Berlin-Heidelberg, 6. edition, 2005.
[3]T. H. Reiss. Recognizing Planar Objects Using Invariant Image Features, from Lecture notes in computer science, p. 676. Springer, Berlin, 1993.
[4]示例
>>> image = np.zeros((20, 20), dtype=np.float64) >>> image[13:17, 13:17] = 1 >>> M = moments(image) >>> centroid = (M[1, 0] / M[0, 0], M[0, 1] / M[0, 0]) >>> centroid (14.5, 14.5)
- skimage.measure.moments_central(image, center=None, order=3, *, spacing=None, **kwargs)[源代码][源代码]#
计算所有中心图像矩,直到某个特定阶数。
中心坐标 (cr, cc) 可以通过原始矩计算为:{
M[1, 0] / M[0, 0],M[0, 1] / M[0, 0]}。注意,中心矩是平移不变的,但不是尺度不变和旋转不变的。
- 参数:
- 图像(N[, …]) 双精度或 uint8 数组
光栅化形状作为图像。
- 中心浮点数元组,可选
图像质心的坐标。如果未提供,将进行计算。
- 顺序int, 可选
计算的矩的最大阶数。
- spacing: 浮点数的元组, 形状 (ndim,)
图像沿每个轴的像素间距。
- 返回:
- mu : (
order + 1,order + 1) 数组() 中心图像矩。
- mu : (
参考文献
[1]Wilhelm Burger, Mark Burge. 数字图像处理原理:核心算法. Springer-Verlag, 伦敦, 2009.
[2]B. Jähne. Digital Image Processing. Springer-Verlag, Berlin-Heidelberg, 6. edition, 2005.
[3]T. H. Reiss. Recognizing Planar Objects Using Invariant Image Features, from Lecture notes in computer science, p. 676. Springer, Berlin, 1993.
[4]示例
>>> image = np.zeros((20, 20), dtype=np.float64) >>> image[13:17, 13:17] = 1 >>> M = moments(image) >>> centroid = (M[1, 0] / M[0, 0], M[0, 1] / M[0, 0]) >>> moments_central(image, centroid) array([[16., 0., 20., 0.], [ 0., 0., 0., 0.], [20., 0., 25., 0.], [ 0., 0., 0., 0.]])
- skimage.measure.moments_coords(coords, order=3)[源代码][源代码]#
计算所有原始图像矩,直到某个特定阶数。
- 以下属性可以从原始图像矩计算得出:
区域表示为:
M[0, 0]。质心为:{
M[1, 0] / M[0, 0],M[0, 1] / M[0, 0]}。
请注意,原始矩既不是平移不变的,也不是尺度不变的,也不是旋转不变的。
- 参数:
- 坐标(N, D) 双精度或 uint8 数组
描述笛卡尔空间中D维图像的N个点的数组。
- 顺序int, 可选
矩的阶数最大值。默认是 3。
- 返回:
- M : (
order + 1,order + 1, …) 数组() 原始图像矩。(D 维)
- M : (
参考文献
[1]Johannes Kilian. 通过矩的简单图像分析。杜伦大学,版本0.2,杜伦,2001年。
示例
>>> coords = np.array([[row, col] ... for row in range(13, 17) ... for col in range(14, 18)], dtype=np.float64) >>> M = moments_coords(coords) >>> centroid = (M[1, 0] / M[0, 0], M[0, 1] / M[0, 0]) >>> centroid (14.5, 15.5)
- skimage.measure.moments_coords_central(coords, center=None, order=3)[源代码][源代码]#
计算所有中心图像矩,直到某个特定阶数。
- 以下属性可以从原始图像矩计算得出:
区域表示为:
M[0, 0]。质心为:{
M[1, 0] / M[0, 0],M[0, 1] / M[0, 0]}。
请注意,原始矩既不是平移、缩放也不是旋转不变的。
- 参数:
- 坐标(N, D) 双精度或 uint8 数组
描述笛卡尔空间中D维图像的N个点的数组。由
np.nonzero返回的坐标元组也可以作为输入。- 中心浮点数元组,可选
图像质心的坐标。如果未提供,将进行计算。
- 顺序int, 可选
矩的阶数最大值。默认是 3。
- 返回:
- Mc : (
order + 1,order + 1, …) 数组() 中心图像矩。(D 维)
- Mc : (
参考文献
[1]Johannes Kilian. 通过矩的简单图像分析。杜伦大学,版本0.2,杜伦,2001年。
示例
>>> coords = np.array([[row, col] ... for row in range(13, 17) ... for col in range(14, 18)]) >>> moments_coords_central(coords) array([[16., 0., 20., 0.], [ 0., 0., 0., 0.], [20., 0., 25., 0.], [ 0., 0., 0., 0.]])
如上所述,对于对称物体,当以物体的质心(默认)为中心时,奇数阶矩(第1列和第3列,第1行和第3行)为零。如果我们通过添加一个新点来打破对称性,这种情况就不再成立:
>>> coords2 = np.concatenate((coords, [[17, 17]]), axis=0) >>> np.round(moments_coords_central(coords2), ... decimals=2) array([[17. , 0. , 22.12, -2.49], [ 0. , 3.53, 1.73, 7.4 ], [25.88, 6.02, 36.63, 8.83], [ 4.15, 19.17, 14.8 , 39.6 ]])
当中心为 (0, 0) 时,图像矩和中心图像矩是等价的(根据定义):
>>> np.allclose(moments_coords(coords), ... moments_coords_central(coords, (0, 0))) True
- skimage.measure.moments_hu(nu)[源代码][源代码]#
计算图像的 Hu 矩集(仅限 2D)。
注意,这一组矩被证明是平移、缩放和旋转不变的。
- 参数:
- nu(M, M) 数组
归一化的中心图像矩,其中 M 必须 >= 4。
- 返回:
- nu(7,) 数组
Hu 的图像矩集。
参考文献
[1]M. K. Hu, “Visual Pattern Recognition by Moment Invariants”, IRE Trans. Info. Theory, vol. IT-8, pp. 179-187, 1962
[2]Wilhelm Burger, Mark Burge. 数字图像处理原理:核心算法. Springer-Verlag, 伦敦, 2009.
[3]B. Jähne. Digital Image Processing. Springer-Verlag, Berlin-Heidelberg, 6. edition, 2005.
[4]T. H. Reiss. Recognizing Planar Objects Using Invariant Image Features, from Lecture notes in computer science, p. 676. Springer, Berlin, 1993.
[5]示例
>>> image = np.zeros((20, 20), dtype=np.float64) >>> image[13:17, 13:17] = 0.5 >>> image[10:12, 10:12] = 1 >>> mu = moments_central(image) >>> nu = moments_normalized(mu) >>> moments_hu(nu) array([0.74537037, 0.35116598, 0.10404918, 0.04064421, 0.00264312, 0.02408546, 0. ])
- skimage.measure.moments_normalized(mu, order=3, spacing=None)[源代码][源代码]#
计算所有归一化的中心图像矩,直到某个特定阶数。
注意,归一化的中心矩是平移和尺度不变的,但不是旋转不变的。
- 参数:
- mu(M[, …], M) 数组
中心图像矩,其中 M 必须大于或等于
order。- 顺序int, 可选
矩的阶数最大值。默认是 3。
- spacing: 浮点数的元组, 形状 (ndim,)
图像沿每个轴的像素间距。
- 返回:
- nu : (
order + 1``[, ...], ``order + 1) 数组() 归一化中心图像矩。
- nu : (
参考文献
[1]Wilhelm Burger, Mark Burge. 数字图像处理原理:核心算法. Springer-Verlag, 伦敦, 2009.
[2]B. Jähne. Digital Image Processing. Springer-Verlag, Berlin-Heidelberg, 6. edition, 2005.
[3]T. H. Reiss. Recognizing Planar Objects Using Invariant Image Features, from Lecture notes in computer science, p. 676. Springer, Berlin, 1993.
[4]示例
>>> image = np.zeros((20, 20), dtype=np.float64) >>> image[13:17, 13:17] = 1 >>> m = moments(image) >>> centroid = (m[0, 1] / m[0, 0], m[1, 0] / m[0, 0]) >>> mu = moments_central(image, centroid) >>> moments_normalized(mu) array([[ nan, nan, 0.078125 , 0. ], [ nan, 0. , 0. , 0. ], [0.078125 , 0. , 0.00610352, 0. ], [0. , 0. , 0. , 0. ]])
- skimage.measure.pearson_corr_coeff(image0, image1, mask=None)[源代码][源代码]#
计算通道中像素强度之间的皮尔逊相关系数。
- 参数:
- image0(M, N) ndarray
通道A的图像。
- image1(M, N) ndarray
要与通道 B 关联的通道 2 的图像。必须与 image0 具有相同的尺寸。
- 掩码(M, N) 布尔类型的 ndarray,可选
只有 image0 和 image1 像素在这个感兴趣区域掩码内被包含在计算中。必须与 image0 具有相同的维度。
- 返回:
- pcc浮动
在提供的掩码内,两幅图像的像素强度之间的皮尔逊相关系数。
- p值浮动
双尾 p 值。
注释
皮尔逊相关系数 (PCC) 衡量两幅图像像素强度之间的线性相关性。其值范围从 -1(完全线性反相关)到 +1(完全线性相关)。p 值的计算假设每个输入图像中的像素强度呈正态分布。
使用了 Scipy 实现的 Pearson 相关系数。请参考它以获取更多信息和注意事项 [1]。
\[r = \frac{\sum (A_i - m_A_i) (B_i - m_B_i)} {\sqrt{\sum (A_i - m_A_i)^2 \sum (B_i - m_B_i)^2}}\]- 哪里
\(A_i\) 是 image0 中第 \(i^{th}\) 个像素的值,\(B_i\) 是 image1 中第 \(i^{th}\) 个像素的值,\(m_A_i\) 是 image0 中像素值的均值,\(m_B_i\) 是 image1 中像素值的均值。
低PCC值并不一定意味着两个通道的强度之间没有相关性,只是表明它们之间没有线性相关性。你可能希望在2D散点图中绘制两个通道的像素强度,并在视觉上识别出非线性相关性时使用Spearman等级相关性 [2]。还要考虑你是否对相关性或共现性感兴趣,在这种情况下,涉及分割掩码的方法(例如MCC或交集系数)可能更合适 [3] [4]。
提供图像中仅相关部分的掩码(例如,细胞或特定的细胞区室)并去除噪声是重要的,因为PCC对这些措施很敏感 [3] [4]。
参考文献
[3] (1,2)Dunn, K. W., Kamocka, M. M., & McDonald, J. H. (2011). 生物显微镜中评估共定位的实用指南。美国生理学杂志. 细胞生理学, 300(4), C723–C742. https://doi.org/10.1152/ajpcell.00462.2010
[4] (1,2)Bolte, S. 和 Cordelières, F.P. (2006),光显微镜下亚细胞共定位分析的导览。显微镜学杂志, 224: 213-232. https://doi.org/10.1111/j.1365-2818.2006.01706.x
- skimage.measure.perimeter(image, neighborhood=4)[源代码][源代码]#
计算二值图像中所有对象的总周长。
- 参数:
- 图像(M, N) ndarray
二进制输入图像。
- 邻域4 或 8,可选
邻域连通性用于边界像素的确定。它用于计算轮廓。更高的邻域会扩大计算周长的边界。
- 返回:
- 周长浮动
二值图像中所有对象的总周长。
参考文献
[1]K. Benkrid, D. Crookes. Design and FPGA Implementation of a Perimeter Estimator. The Queen’s University of Belfast. http://www.cs.qub.ac.uk/~d.crookes/webpubs/papers/perimeter.doc
示例
>>> from skimage import data, util >>> from skimage.measure import label >>> # coins image (binary) >>> img_coins = data.coins() > 110 >>> # total perimeter of all objects in the image >>> perimeter(img_coins, neighborhood=4) 7796.867... >>> perimeter(img_coins, neighborhood=8) 8806.268...
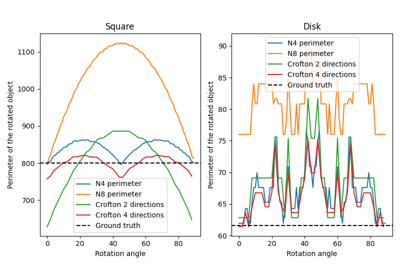
- skimage.measure.perimeter_crofton(image, directions=4)[源代码][源代码]#
计算二值图像中所有对象的总Crofton周长。
- 参数:
- 图像(M, N) ndarray
输入图像。如果图像不是二进制的,所有大于零的值都被视为对象。
- 方向2 或 4,可选
用于近似Crofton周长的方向数。默认使用4个方向:这应该比使用2个方向更准确。两种情况下的计算时间相同。
- 返回:
- 周长浮动
二值图像中所有对象的总周长。
注释
此度量基于Crofton公式[1],这是积分几何中的一个度量。它通过沿所有方向的双重积分来定义一般曲线的长度评估。在离散空间中,2或4个方向给出了相当好的近似,对于更复杂的形状,4个方向比2个方向更准确。
类似于
perimeter(),此函数返回连续空间中周长的近似值。参考文献
[1]https://en.wikipedia.org/wiki/Crofton_公式
[2]S. Rivollier. Analyse d’image geometrique et morphometrique par diagrammes de forme et voisinages adaptatifs generaux. PhD thesis, 2010. Ecole Nationale Superieure des Mines de Saint-Etienne. https://tel.archives-ouvertes.fr/tel-00560838
示例
>>> from skimage import data, util >>> from skimage.measure import label >>> # coins image (binary) >>> img_coins = data.coins() > 110 >>> # total perimeter of all objects in the image >>> perimeter_crofton(img_coins, directions=2) 8144.578... >>> perimeter_crofton(img_coins, directions=4) 7837.077...
- skimage.measure.points_in_poly(points, verts)[源代码][源代码]#
测试点是否位于多边形内部。
- 参数:
- 点(K, 2) 数组
输入点,
(x, y)。- verts(L, 2) 数组
多边形的顶点,按顺时针或逆时针排序。第一个点可能会(但不需要)重复。
- 返回:
- 掩码(K,) 布尔数组
如果对应点在多边形内部则为真。
- skimage.measure.profile_line(image, src, dst, linewidth=1, order=None, mode='reflect', cval=0.0, *, reduce_func=<function mean>)[源代码][源代码]#
返回沿扫描线测量的图像的强度分布。
- 参数:
- 图像ndarray, 形状 (M, N[, C])
图像,可以是灰度图像(2D 数组)或彩色图像(3D 数组,其中最后一个轴包含通道信息)。
- src类似数组,形状为 (2,)
扫描线起点的坐标。
- dst类似数组,形状为 (2,)
扫描线终点的坐标。与标准的numpy索引不同,目标点是 包含 在轮廓中的。
- 行宽int, 可选
扫描的宽度,垂直于线条
- 顺序int 在 {0, 1, 2, 3, 4, 5} 中,可选
样条插值的顺序,如果 image.dtype 是 bool 则默认为 0,否则为 1。顺序必须在 0-5 范围内。详情请参见
skimage.transform.warp。- 模式{‘constant’, ‘nearest’, ‘reflect’, ‘mirror’, ‘wrap’}, 可选
如何计算图像范围之外的任何值。
- cvalfloat, 可选
如果 mode 是 ‘constant’,在图像外部使用什么常数值。
- reduce_func可调用,可选
当 linewidth > 1 时,用于计算垂直于 profile_line 方向的像素值聚合的函数。如果设置为 None,则将返回未减少的数组。
- 返回:
- 返回值数组
沿扫描线的强度分布。分布的长度是扫描线计算长度的上限。
示例
>>> x = np.array([[1, 1, 1, 2, 2, 2]]) >>> img = np.vstack([np.zeros_like(x), x, x, x, np.zeros_like(x)]) >>> img array([[0, 0, 0, 0, 0, 0], [1, 1, 1, 2, 2, 2], [1, 1, 1, 2, 2, 2], [1, 1, 1, 2, 2, 2], [0, 0, 0, 0, 0, 0]]) >>> profile_line(img, (2, 1), (2, 4)) array([1., 1., 2., 2.]) >>> profile_line(img, (1, 0), (1, 6), cval=4) array([1., 1., 1., 2., 2., 2., 2.])
目标点包含在配置文件中,这与标准的 numpy 索引不同。例如:
>>> profile_line(img, (1, 0), (1, 6)) # The final point is out of bounds array([1., 1., 1., 2., 2., 2., 2.]) >>> profile_line(img, (1, 0), (1, 5)) # This accesses the full first row array([1., 1., 1., 2., 2., 2.])
对于不同的 reduce_func 输入:
>>> profile_line(img, (1, 0), (1, 3), linewidth=3, reduce_func=np.mean) array([0.66666667, 0.66666667, 0.66666667, 1.33333333]) >>> profile_line(img, (1, 0), (1, 3), linewidth=3, reduce_func=np.max) array([1, 1, 1, 2]) >>> profile_line(img, (1, 0), (1, 3), linewidth=3, reduce_func=np.sum) array([2, 2, 2, 4])
当 reduce_func 为 None 或 reduce_func 对每个像素值单独作用时,将返回未缩减的数组。
>>> profile_line(img, (1, 2), (4, 2), linewidth=3, order=0, ... reduce_func=None) array([[1, 1, 2], [1, 1, 2], [1, 1, 2], [0, 0, 0]]) >>> profile_line(img, (1, 0), (1, 3), linewidth=3, reduce_func=np.sqrt) array([[1. , 1. , 0. ], [1. , 1. , 0. ], [1. , 1. , 0. ], [1.41421356, 1.41421356, 0. ]])
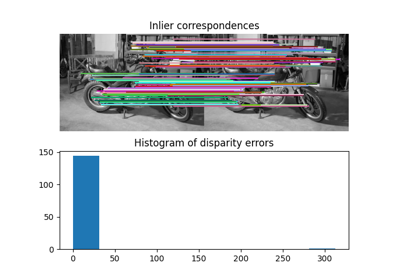
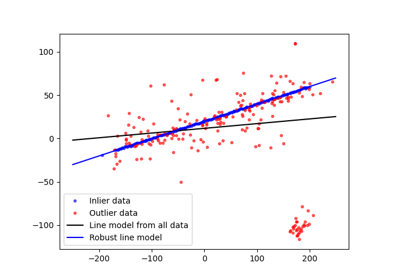
- skimage.measure.ransac(data, model_class, min_samples, residual_threshold, is_data_valid=None, is_model_valid=None, max_trials=100, stop_sample_num=inf, stop_residuals_sum=0, stop_probability=1, rng=None, initial_inliers=None)[源代码][源代码]#
使用 RANSAC(随机样本一致性)算法将模型拟合到数据。
RANSAC 是一种用于从完整数据集中的内点子集进行参数稳健估计的迭代算法。每次迭代执行以下任务:
从原始数据中选择 min_samples 个随机样本,并检查数据集是否有效(参见 is_data_valid)。
估计一个模型到随机子集(model_cls.estimate(*data[random_subset])并检查估计的模型是否有效(参见 is_model_valid)。
通过计算残差到估计模型的残差(model_cls.residuals(*data))将所有数据分类为内点或离群点 - 所有残差小于 residual_threshold 的数据样本被视为内点。
如果内点样本数最大,则将估计的模型保存为最佳模型。如果当前估计的模型具有相同数量的内点,则只有在残差和更小的情况下,才将其视为最佳模型。
这些步骤要么执行最大次数,要么直到满足某个特殊停止条件为止。最终模型是使用先前确定的最佳模型的所有内点样本估计的。
- 参数:
- 数据[列表, 元组] (N, …) 数组
模型拟合的数据集,其中 N 是数据点的数量,其余维度取决于模型的要求。如果模型类需要多个输入数据数组(例如
skimage.transform.AffineTransform的源和目标坐标),它们可以作为元组或列表可选地传递。请注意,在这种情况下,函数estimate(*data)、residuals(*data)、is_model_valid(model, *random_data)和is_data_valid(*random_data)必须都将每个数据数组作为单独的参数。- model_class对象
具有以下对象方法的对象:
success = estimate(*data)residuals(*data)
其中 success 表示模型估计是否成功(True 或 None 表示成功,False 表示失败)。
- min_samplesint in range (0, N)
拟合模型所需的最小数据点数。
- 残差阈值浮点数大于 0
数据点被分类为内点的最大距离。
- is_data_valid函数, 可选
在模型拟合数据之前,此函数会使用随机选择的数据进行调用:is_data_valid(*random_data)。
- is_model_valid函数, 可选
此函数使用估计的模型和随机选择的数据调用:is_model_valid(model, *random_data),。
- max_trialsint, 可选
随机样本选择的迭代次数上限。
- stop_sample_numint, 可选
如果找到至少这个数量的内点,则停止迭代。
- stop_residuals_sumfloat, 可选
如果残差的和小于或等于此阈值,则停止迭代。
- stop_probability浮点数在范围 [0, 1] 内,可选
如果训练数据的至少一个无异常值的集合以
概率 >= stop_probability被采样,RANSAC 迭代将停止,这取决于当前最佳模型的内点比率和试验次数。这要求至少生成 N 个样本(试验):N >= log(1 - 概率) / log(1 - e**m)
其中概率(置信度)通常设置为一个高值,如0.99,e是当前内点相对于总样本数的比例,m是min_samples值。
- rng : {
numpy.random.Generator, int}, 可选toctree是一个 reStructuredText 指令 ,这是一个非常多功能的标记。指令可以有参数、选项和内容。 伪随机数生成器。默认情况下,使用 PCG64 生成器(参见
numpy.random.default_rng())。如果 rng 是整数,则用于为生成器设定种子。- 初始内点类数组的布尔值,形状为 (N,),可选
模型估计的初始样本选择
- 返回:
- 模型对象
最佳模型,具有最大的共识集。
- 内点(N,) 数组
被分类为
True的内点布尔掩码。
参考文献
[1]“RANSAC”, 维基百科, https://en.wikipedia.org/wiki/RANSAC
示例
生成无倾斜的椭圆数据并添加噪声:
>>> t = np.linspace(0, 2 * np.pi, 50) >>> xc, yc = 20, 30 >>> a, b = 5, 10 >>> x = xc + a * np.cos(t) >>> y = yc + b * np.sin(t) >>> data = np.column_stack([x, y]) >>> rng = np.random.default_rng(203560) # do not copy this value >>> data += rng.normal(size=data.shape)
添加一些错误数据:
>>> data[0] = (100, 100) >>> data[1] = (110, 120) >>> data[2] = (120, 130) >>> data[3] = (140, 130)
使用所有可用数据估计椭圆模型:
>>> model = EllipseModel() >>> model.estimate(data) True >>> np.round(model.params) array([ 72., 75., 77., 14., 1.])
使用 RANSAC 估计椭圆模型:
>>> ransac_model, inliers = ransac(data, EllipseModel, 20, 3, max_trials=50) >>> abs(np.round(ransac_model.params)) array([20., 30., 10., 6., 2.]) >>> inliers array([False, False, False, False, True, True, True, True, True, True, True, True, True, True, True, True, True, True, True, True, True, True, True, True, True, True, True, True, True, True, True, True, True, True, True, True, True, True, True, True, True, True, True, True, True, True, True, True, True, True], dtype=bool) >>> sum(inliers) > 40 True
RANSAC 可以用于稳健地估计几何变换。在本节中,我们还展示了如何使用总样本的比例,而不是绝对数量。
>>> from skimage.transform import SimilarityTransform >>> rng = np.random.default_rng() >>> src = 100 * rng.random((50, 2)) >>> model0 = SimilarityTransform(scale=0.5, rotation=1, ... translation=(10, 20)) >>> dst = model0(src) >>> dst[0] = (10000, 10000) >>> dst[1] = (-100, 100) >>> dst[2] = (50, 50) >>> ratio = 0.5 # use half of the samples >>> min_samples = int(ratio * len(src)) >>> model, inliers = ransac( ... (src, dst), ... SimilarityTransform, ... min_samples, ... 10, ... initial_inliers=np.ones(len(src), dtype=bool), ... ) >>> inliers array([False, False, False, True, True, True, True, True, True, True, True, True, True, True, True, True, True, True, True, True, True, True, True, True, True, True, True, True, True, True, True, True, True, True, True, True, True, True, True, True, True, True, True, True, True, True, True, True, True, True])


- skimage.measure.regionprops(label_image, intensity_image=None, cache=True, *, extra_properties=None, spacing=None, offset=None)[源代码][源代码]#
测量标记图像区域的属性。
- 参数:
- label_image(M, N[, P]) ndarray
带标签的输入图像。值为0的标签将被忽略。
在 0.14.1 版本发生变更: 之前,
label_image由numpy.squeeze处理,因此允许任意数量的单一维度。这导致了单一维度图像的处理不一致。要恢复旧的行为,请使用regionprops(np.squeeze(label_image), ...)。- intensity_image(M, N[, P][, C]) ndarray, 可选
强度(即输入)图像,其大小与标记图像相同,另外可选地增加一个维度用于多通道数据。目前,如果存在这个额外的通道维度,它必须是最后一个轴。默认值为 None。
在 0.18.0 版本发生变更: 为频道提供额外维度的能力已添加。
- 缓存bool, 可选
确定是否缓存计算属性。对于缓存的属性,计算速度会快很多,但内存消耗会增加。
- extra_properties可调用对象的可迭代对象
添加额外的属性计算函数,这些函数不包含在 skimage 中。属性的名称由函数名称派生,dtype 通过在小的样本上调用函数来推断。如果额外属性的名称与现有属性的名称冲突,额外属性将不可见,并发出 UserWarning。属性计算函数必须将其第一个参数作为区域掩码。如果属性需要强度图像,则必须接受强度图像作为第二个参数。
- spacing: 浮点数的元组, 形状 (ndim,)
图像沿每个轴的像素间距。
- offset : 类数组形式的整数, 形状 (label_image.ndim,), 可选类数组的整数,形状
标签图像的原点(“左上”角)的坐标。通常这是 ([0, ]0, 0),但如果想获取较大体积内子体积的区域属性,可能会有所不同。
- 返回:
- 属性RegionProperties 列表
每个项目描述一个带标签的区域,可以使用下面列出的属性进行访问。
参见
注释
以下属性可以作为属性或键来访问:
- 区域浮动
区域的面积,即区域像素数乘以像素面积。
- area_bbox浮动
边界框的面积,即边界框的像素数乘以像素面积。
- area_convex浮动
凸包图像的面积,即包围该区域的最小凸多边形的面积。
- area_filled浮动
填充所有孔洞后的区域面积。
- axis_major_length浮动
与该区域具有相同归一化二阶中心矩的椭圆的长轴长度。
- axis_minor_length浮动
与该区域具有相同归一化二阶中心矩的椭圆的短轴长度。
- bbox元组
边界框
(min_row, min_col, max_row, max_col)。属于边界框的像素位于半开区间[min_row; max_row)和[min_col; max_col)内。- 质心数组
质心坐标元组
(行, 列)。- centroid_local数组
质心坐标元组
(行, 列),相对于区域边界框。- centroid_weighted数组
质心坐标元组
(行, 列)根据强度图像加权。- centroid_weighted_local数组
质心坐标元组
(行, 列),相对于区域边界框,加权于强度图像。- coords_scaled(K, 2) ndarray
区域坐标列表
(行, 列)按间距缩放。- 坐标(K, 2) ndarray
区域的坐标列表
(行, 列)。- 离心率浮动
具有与该区域相同二阶矩的椭圆的离心率。离心率是焦点距离(焦点之间的距离)与长轴长度的比值。该值在区间 [0, 1) 内。当其为 0 时,椭圆变为一个圆。
- equivalent_diameter_area浮动
与该区域面积相同的圆的直径。
- 欧拉数整数
非零像素集合的欧拉特征数。计算为连通分量数减去孔数(输入.ndim连通性)。在3D中,连通分量数加上孔数减去隧道数。
- 范围浮动
区域中的像素与总边界框中的像素的比率。计算公式为
面积 / (行数 * 列数)- feret_diameter_max浮动
最大Feret直径计算为区域凸包轮廓上两点之间的最长距离,由
find_contours确定。 [5]- 图像(H, J) ndarray
切片二值区域图像,其大小与边界框相同。
- image_convex(H, J) ndarray
与边界框大小相同的二值凸包图像。
- image_filled(H, J) ndarray
填充了孔洞的二值区域图像,其大小与边界框相同。
- 图像强度ndarray
区域边界框内的图像。
- inertia_tensorndarray
该区域围绕其质量旋转的惯性张量。
- inertia_tensor_eigvals元组
惯性张量的特征值按降序排列。
- intensity_max浮动
该地区强度最大的值。
- intensity_mean浮动
区域中平均强度的值。
- intensity_min浮动
该区域中强度最小的值。
- intensity_std浮动
区域中强度的标准偏差。
- 标签整数
标记输入图像中的标签。
- 时刻(3, 3) ndarray
空间矩最高到3阶:
m_ij = sum{ array(row, col) * row^i * col^j }
其中求和是针对区域的 行, 列 坐标进行的。
- moments_central(3, 3) ndarray
中心矩(平移不变)至三阶:
mu_ij = sum{ array(row, col) * (row - row_c)^i * (col - col_c)^j }
其中求和是对区域的 row, col 坐标进行的,而 row_c 和 col_c 是区域质心的坐标。
- moments_hu元组
Hu矩(平移、缩放和旋转不变性)。
- moments_normalized(3, 3) ndarray
归一化矩(平移和尺度不变)至三阶:
nu_ij = mu_ij / m_00^[(i+j)/2 + 1]
其中 m_00 是第零阶空间矩。
- moments_weighted(3, 3) ndarray
强度图像的空间矩,最高至3阶:
wm_ij = sum{ array(row, col) * row^i * col^j }
其中求和是针对区域的 行, 列 坐标进行的。
- moments_weighted_central(3, 3) ndarray
强度图像的中心矩(平移不变)至三阶:
wmu_ij = sum{ array(row, col) * (row - row_c)^i * (col - col_c)^j }
其中,求和是对区域的 行, 列 坐标进行的,而 row_c 和 col_c 是区域加权质心的坐标。
- moments_weighted_hu元组
Hu矩(平移、缩放和旋转不变)的强度图像。
- moments_weighted_normalized(3, 3) ndarray
归一化矩(平移和尺度不变)的强度图像,最高至3阶:
wnu_ij = wmu_ij / wm_00^[(i+j)/2 + 1]
其中
wm_00是第零阶空间矩(强度加权面积)。- num_pixels整数
前景像素的数量。
- 方向浮动
0轴(行)与具有相同二阶矩的椭圆的主轴之间的角度,范围从 -pi/2 到 pi/2 逆时针方向。
- 周长浮动
使用4-连通性,通过边界像素中心将轮廓近似为一条线的对象周长。
- perimeter_crofton浮动
通过Crofton公式在4个方向上近似计算对象的周长。
- 切片切片元组
从源图像中提取对象的切片。
- solidity浮动
区域中的像素与凸包图像的像素的比率。
每个区域也支持迭代,因此你可以这样做:
for prop in region: print(prop, region[prop])
参考文献
[1]Wilhelm Burger, Mark Burge. 数字图像处理原理:核心算法. Springer-Verlag, 伦敦, 2009.
[2]B. Jähne. Digital Image Processing. Springer-Verlag, Berlin-Heidelberg, 6. edition, 2005.
[3]T. H. Reiss. Recognizing Planar Objects Using Invariant Image Features, from Lecture notes in computer science, p. 676. Springer, Berlin, 1993.
[4][5]W. Pabst, E. Gregorová. Characterization of particles and particle systems, pp. 27-28. ICT Prague, 2007. https://old.vscht.cz/sil/keramika/Characterization_of_particles/CPPS%20_English%20version_.pdf
示例
>>> from skimage import data, util >>> from skimage.measure import label, regionprops >>> img = util.img_as_ubyte(data.coins()) > 110 >>> label_img = label(img, connectivity=img.ndim) >>> props = regionprops(label_img) >>> # centroid of first labeled object >>> props[0].centroid (22.72987986048314, 81.91228523446583) >>> # centroid of first labeled object >>> props[0]['centroid'] (22.72987986048314, 81.91228523446583)
通过将函数作为
extra_properties传递来添加自定义测量>>> from skimage import data, util >>> from skimage.measure import label, regionprops >>> import numpy as np >>> img = util.img_as_ubyte(data.coins()) > 110 >>> label_img = label(img, connectivity=img.ndim) >>> def pixelcount(regionmask): ... return np.sum(regionmask) >>> props = regionprops(label_img, extra_properties=(pixelcount,)) >>> props[0].pixelcount 7741 >>> props[1]['pixelcount'] 42
- skimage.measure.regionprops_table(label_image, intensity_image=None, properties=('label', 'bbox'), *, cache=True, separator='-', extra_properties=None, spacing=None)[源代码][源代码]#
计算图像属性并将它们作为与pandas兼容的表格返回。
表格是一个字典,将列名映射到值数组。详见下面的注释部分。
Added in version 0.16.
- 参数:
- label_image(M, N[, P]) ndarray
带标签的输入图像。值为0的标签将被忽略。
- intensity_image(M, N[, P][, C]) ndarray, 可选
强度(即输入)图像,其大小与标记图像相同,另外可选地增加一个维度用于多通道数据。如果存在通道维度,则必须位于最后一个轴。默认为 None。
在 0.18.0 版本发生变更: 为频道提供额外维度的能力已添加。
- 属性tuple 或 list 类型的 str,可选
将在结果字典中包含的属性 有关可用属性的列表,请参阅
regionprops()。用户应记住添加“label”以跟踪区域身份。- 缓存bool, 可选
确定是否缓存计算属性。对于缓存的属性,计算速度会快很多,但内存消耗会增加。
- 分隔符str, 可选
对于未列在 OBJECT_COLUMNS 中的非标量属性,每个元素将出现在其自己的列中,该元素的索引与属性名称之间用此分隔符分隔。例如,2D 区域的惯性张量将出现在四列中:
inertia_tensor-0-0、inertia_tensor-0-1、inertia_tensor-1-0和inertia_tensor-1-1``(其中分隔符是 ``-)。对象列是那些不能以这种方式分割的列,因为列的数量会根据对象的不同而变化。例如,
image和coords。- extra_properties可调用对象的可迭代对象
添加额外的属性计算函数,这些函数不包含在 skimage 中。属性的名称由函数名称派生,dtype 通过在小的样本上调用函数来推断。如果额外属性的名称与现有属性的名称冲突,额外属性将不可见,并发出 UserWarning。属性计算函数必须将其第一个参数作为区域掩码。如果属性需要强度图像,则必须接受强度图像作为第二个参数。
- spacing: 浮点数的元组, 形状 (ndim,)
图像沿每个轴的像素间距。
- 返回:
- out_dictdict
字典将属性名称映射到该属性的值数组,每个区域对应一个值。此字典可以用作 pandas
DataFrame的输入,以将属性名称映射到框架中的列,并将区域映射到行。如果图像没有区域,数组的长度将为 0,但类型正确。
注释
每一列包含一个标量属性、一个对象属性,或是一个多维数组中的元素。
每个区域的标量值属性,例如“偏心率”,将以该属性名称为键的浮点数或整数数组的形式出现。
对于给定图像维度的多维属性 固定大小,例如“质心”(在3D图像中,每个质心将有三个元素,无论区域大小如何),将被拆分为那么多列,名称分别为 {property_name}{separator}{element_num}(对于1D属性),{property_name}{separator}{elem_num0}{separator}{elem_num1}(对于2D属性),依此类推。
对于没有固定大小的多维属性,例如“image”(区域的图像大小根据区域大小而变化),将使用对象数组,相应的属性名称作为键。
示例
>>> from skimage import data, util, measure >>> image = data.coins() >>> label_image = measure.label(image > 110, connectivity=image.ndim) >>> props = measure.regionprops_table(label_image, image, ... properties=['label', 'inertia_tensor', ... 'inertia_tensor_eigvals']) >>> props {'label': array([ 1, 2, ...]), ... 'inertia_tensor-0-0': array([ 4.012...e+03, 8.51..., ...]), ... ..., 'inertia_tensor_eigvals-1': array([ 2.67...e+02, 2.83..., ...])}
生成的字典可以直接传递给 pandas,如果已安装,以获得一个干净的 DataFrame:
>>> import pandas as pd >>> data = pd.DataFrame(props) >>> data.head() label inertia_tensor-0-0 ... inertia_tensor_eigvals-1 0 1 4012.909888 ... 267.065503 1 2 8.514739 ... 2.834806 2 3 0.666667 ... 0.000000 3 4 0.000000 ... 0.000000 4 5 0.222222 ... 0.111111
[5行 x 7列]
如果我们想要测量一个不是内置属性的特征,我们可以定义自定义函数并将它们作为
extra_properties传递。例如,我们可以创建一个自定义函数来测量区域中的强度四分位数:>>> from skimage import data, util, measure >>> import numpy as np >>> def quartiles(regionmask, intensity): ... return np.percentile(intensity[regionmask], q=(25, 50, 75)) >>> >>> image = data.coins() >>> label_image = measure.label(image > 110, connectivity=image.ndim) >>> props = measure.regionprops_table(label_image, intensity_image=image, ... properties=('label',), ... extra_properties=(quartiles,)) >>> import pandas as pd >>> pd.DataFrame(props).head() label quartiles-0 quartiles-1 quartiles-2 0 1 117.00 123.0 130.0 1 2 111.25 112.0 114.0 2 3 111.00 111.0 111.0 3 4 111.00 111.5 112.5 4 5 112.50 113.0 114.0
- skimage.measure.shannon_entropy(image, base=2)[源代码][源代码]#
计算图像的香农熵。
香农熵定义为 S = -sum(pk * log(pk)),其中 pk 是值为 k 的像素的频率/概率。
- 参数:
- 图像(M, N) ndarray
灰度输入图像。
- 基础float, 可选
要使用的对数底数。
- 返回:
- 熵浮动
注释
返回值以比特(base=2 时为香农(Sh))、自然单位(base=np.e 时为纳特(nat))和哈特利(base=10 时为哈特利(Hart))为单位进行测量。
参考文献
[2]https://en.wiktionary.org/wiki/Shannon_熵
示例
>>> from skimage import data >>> from skimage.measure import shannon_entropy >>> shannon_entropy(data.camera()) 7.231695011055706
- skimage.measure.subdivide_polygon(coords, degree=2, preserve_ends=False)[源代码][源代码]#
使用B样条细分多边形曲线。
请注意,生成的曲线始终在原始多边形的凸包内。细分后,圆形多边形保持闭合。
- 参数:
- 坐标(K, 2) 数组
坐标数组。
- 度{1, 2, 3, 4, 5, 6, 7}, 可选
B样条的度数。默认值为2。
- preserve_endsbool, 可选
保留非圆形多边形的首尾坐标。默认值为 False。
- 返回:
- 坐标(L, 2) 数组
细分坐标数组。
参考文献
- class skimage.measure.CircleModel[源代码][源代码]#
基类:
BaseModel二维圆的总体最小二乘估计器。
圆的功能模型是:
r**2 = (x - xc)**2 + (y - yc)**2
该估计器最小化所有点到圆的距离平方:
min{ sum((r - sqrt((x_i - xc)**2 + (y_i - yc)**2))**2) }
求解参数需要至少3个点。
- 属性:
- 参数元组
按照以下顺序设置圆模型参数 xc, yc, r。
注释
使用 [1] 中给出的球面估计的二维版本进行估计。
参考文献
[1]Jekel, Charles F. 通过逆向气泡膨胀获取PVC涂层聚酯的非线性正交各向异性材料模型。硕士论文 (MEng), 斯泰伦博斯大学, 2016. 附录A, 第83-87页. https://hdl.handle.net/10019.1/98627
示例
>>> t = np.linspace(0, 2 * np.pi, 25) >>> xy = CircleModel().predict_xy(t, params=(2, 3, 4)) >>> model = CircleModel() >>> model.estimate(xy) True >>> tuple(np.round(model.params, 5)) (2.0, 3.0, 4.0) >>> res = model.residuals(xy) >>> np.abs(np.round(res, 9)) array([0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.])
- estimate(data)[源代码][源代码]#
使用总体最小二乘法从数据中估计圆模型。
- 参数:
- 数据(N, 2) 数组
N 个点的
(x, y)坐标,分别表示。
- 返回:
- 成功布尔
如果模型估计成功,则为真。
- class skimage.measure.EllipseModel[源代码][源代码]#
基类:
BaseModel二维椭圆的总最小二乘估计器。
椭圆的功能模型是:
xt = xc + a*cos(theta)*cos(t) - b*sin(theta)*sin(t) yt = yc + a*sin(theta)*cos(t) + b*cos(theta)*sin(t) d = sqrt((x - xt)**2 + (y - yt)**2)
其中
(xt, yt)是椭圆上最接近(x, y)的点。因此 d 是该点到椭圆的最短距离。该估计器基于最小二乘最小化。最优解是直接计算的,不需要迭代。这导致了一种简单、稳定且鲁棒的拟合方法。
params属性包含以下顺序的参数:xc, yc, a, b, theta
- 属性:
- 参数元组
椭圆模型参数按以下顺序 xc, yc, a, b, theta。
示例
>>> xy = EllipseModel().predict_xy(np.linspace(0, 2 * np.pi, 25), ... params=(10, 15, 8, 4, np.deg2rad(30))) >>> ellipse = EllipseModel() >>> ellipse.estimate(xy) True >>> np.round(ellipse.params, 2) array([10. , 15. , 8. , 4. , 0.52]) >>> np.round(abs(ellipse.residuals(xy)), 5) array([0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.])
- estimate(data)[源代码][源代码]#
使用总体最小二乘法从数据中估计椭圆模型。
- 参数:
- 数据(N, 2) 数组
N 个点的
(x, y)坐标,分别表示。
- 返回:
- 成功布尔
如果模型估计成功,则为真。
参考文献
[1]Halir, R.; Flusser, J. “数值稳定的直接最小二乘椭圆拟合”. 在 Proc. 第六届中欧计算机图形学与可视化国际会议. WSCG (Vol. 98, pp. 125-132).
- class skimage.measure.LineModelND[源代码][源代码]#
基类:
BaseModelN 维直线的总最小二乘估计器。
与普通最小二乘线估计相反,该估计器最小化了点到估计线的垂直距离。
线由一个点(原点)和一个单位向量(方向)定义,根据以下向量方程:
X = origin + lambda * direction
- 属性:
- 参数元组
线模型参数按以下顺序 origin, direction。
示例
>>> x = np.linspace(1, 2, 25) >>> y = 1.5 * x + 3 >>> lm = LineModelND() >>> lm.estimate(np.stack([x, y], axis=-1)) True >>> tuple(np.round(lm.params, 5)) (array([1.5 , 5.25]), array([0.5547 , 0.83205])) >>> res = lm.residuals(np.stack([x, y], axis=-1)) >>> np.abs(np.round(res, 9)) array([0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.]) >>> np.round(lm.predict_y(x[:5]), 3) array([4.5 , 4.562, 4.625, 4.688, 4.75 ]) >>> np.round(lm.predict_x(y[:5]), 3) array([1. , 1.042, 1.083, 1.125, 1.167])
- estimate(data)[源代码][源代码]#
从数据中估计线性模型。
这最小化了从给定数据点到估计线的最短(正交)距离之和。
- 参数:
- 数据(N, dim) 数组
在维度 dim >= 2 的空间中的 N 个点。
- 返回:
- 成功布尔
如果模型估计成功,则为真。
- predict(x, axis=0, params=None)[源代码][源代码]#
预测估计的线模型与给定轴正交的超平面的交点。
- 参数:
- x(n, 1) 数组
沿轴的坐标。
- 轴整数
与超平面相交的直线的正交轴。
- 参数(2,) 数组,可选
表单中的可选自定义参数集 (origin, direction)。
- 返回:
- 数据(n, m) 数组
预测的坐标。
- Raises:
- ValueError
如果这条线与给定的轴平行。
- predict_x(y, params=None)[源代码][源代码]#
使用估计的模型预测二维线的x坐标。
别名:
predict(y, axis=1)[:, 0]
- 参数:
- y数组
y-坐标。
- 参数(2,) 数组,可选
表单中的可选自定义参数集 (origin, direction)。
- 返回:
- x数组
预测的 x 坐标。