skimage.feature#
在给定的灰度图像中查找斑点。 |
|
在给定的灰度图像中查找斑点。 |
|
在给定的灰度图像中查找斑点。 |
|
使用Canny算法对图像进行边缘过滤。 |
|
提取给定图像的FAST角点。 |
|
计算Foerstner角点测量响应图像。 |
|
计算Harris角点测量响应图像。 |
|
计算厨房和罗森菲尔德角测量响应图像。 |
|
计算 Moravec 角点测量响应图像。 |
|
计算角落的方向。 |
|
在角点测量响应图像中寻找峰值。 |
|
计算 Shi-Tomasi (Kanade-Tomasi) 角点测量响应图像。 |
|
确定角点的亚像素位置。 |
|
为给定图像密集提取DAISY特征描述符。 |
|
Haar-like 特征的可视化。 |
|
多块局部二值模式可视化。 |
|
计算给定一些描述符/向量和相关估计的高斯混合模型(GMM)的Fisher向量。 |
|
计算灰度共生矩阵。 |
|
计算 GLCM 的纹理属性。 |
|
计算积分图像中感兴趣区域(ROI)的类Haar特征。 |
|
计算Haar-like特征的坐标。 |
|
计算 Hessian 矩阵。 |
|
计算图像上近似的 Hessian 行列式。 |
|
计算 Hessian 矩阵的特征值。 |
|
提取给定图像的方向梯度直方图 (HOG)。 |
|
给定一组描述符和模式数量(即高斯分布),估计一个高斯混合模型(GMM)。 |
|
计算图像的局部二值模式(LBP)。 |
|
描述符的暴力匹配。 |
|
使用归一化相关性将模板匹配到2-D或3-D图像。 |
|
多块局部二值模式 (MB-LBP)。 |
|
单通道或多通道 nd 图像的局部特征。 |
|
在图像中找到峰值作为坐标列表。 |
|
已弃用: |
|
计算形状指数。 |
|
使用平方差之和计算结构张量。 |
|
计算结构张量的特征值。 |
|
BRIEF 二进制描述符提取器。 |
|
CENSURE 关键点检测器。 |
|
用于对象检测的级联分类器类。 |
|
面向FAST和旋转BRIEF特征检测器及二进制描述符提取器。 |
|
SIFT 特征检测和描述符提取。 |
- skimage.feature.blob_dog(image, min_sigma=1, max_sigma=50, sigma_ratio=1.6, threshold=0.5, overlap=0.5, *, threshold_rel=None, exclude_border=False)[源代码][源代码]#
在给定的灰度图像中查找斑点。
Blob 是通过高斯差分 (DoG) 方法 [1],[2] 找到的。对于每个找到的 Blob,该方法返回其坐标和检测到 Blob 的高斯核的标准偏差。
- 参数:
- 图像ndarray
输入灰度图像,假设斑点在深色背景上为浅色(黑色上的白色)。
- min_sigma标量或标量序列,可选
高斯核的最小标准差。保持较低以检测较小的斑点。高斯滤波器的标准差按每个轴给定为一个序列,或作为一个单一数字,在这种情况下,它对所有轴都是相等的。
- max_sigma标量或标量序列,可选
高斯核的最大标准差。保持这个值较高以检测更大的斑点。高斯滤波器的标准差按每个轴给出一个序列,或者作为一个单一的数字,在这种情况下,它对所有轴都是相等的。
- sigma_ratiofloat, 可选
用于计算高斯差分的标准差之比
- 阈值浮点数或无,可选
尺度空间最大值的绝对下限。小于 threshold 的局部最大值将被忽略。降低此值以检测强度较低的斑点。如果同时指定了 threshold_rel,则使用较大的阈值。如果为 None,则使用 threshold_rel 代替。
- 重叠float, 可选
一个介于0和1之间的值。如果两个斑点的重叠面积超过 阈值 的比例,则较小的斑点将被消除。
- threshold_rel浮点数或无,可选
峰值的最小强度,计算为
max(dog_space) * threshold_rel,其中dog_space指的是内部计算的高斯差分(DoG)图像堆栈。这应该有一个介于0和1之间的值。如果为None,则使用 threshold 代替。- exclude_bordertuple of ints, int, 或 False, 可选
如果是整数元组,元组的长度必须与输入数组的维度匹配。元组的每个元素将排除在该维度上图像边界 exclude_border 像素内的峰值。如果是非零整数,exclude_border 将排除图像边界 exclude_border 像素内的峰值。如果是零或 False,无论峰值与边界的距离如何,都会识别峰值。
- 返回:
- A(n, image.ndim + sigma) ndarray
一个二维数组,每行代表一个2D图像的2个坐标值,或一个3D图像的3个坐标值,再加上使用的sigma(s)。当传递单个sigma时,输出为:
(r, c, sigma)或(p, r, c, sigma),其中(r, c)或(p, r, c)是斑点的坐标,sigma是检测到斑点的Gaussian核的标准差。当使用各向异性Gaussian时(每个维度的sigmas),检测到的sigma将返回每个维度。
注释
每个斑点的半径在2D图像中约为 \(\sqrt{2}\sigma\),在3D图像中约为 \(\sqrt{3}\sigma\)。
参考文献
[2]Lowe, D. G. “尺度不变关键点的独特图像特征。” 《国际计算机视觉杂志》60, 91–110 (2004). https://www.cs.ubc.ca/~lowe/papers/ijcv04.pdf DOI:10.1023/B:VISI.0000029664.99615.94
示例
>>> from skimage import data, feature >>> coins = data.coins() >>> feature.blob_dog(coins, threshold=.05, min_sigma=10, max_sigma=40) array([[128., 155., 10.], [198., 155., 10.], [124., 338., 10.], [127., 102., 10.], [193., 281., 10.], [126., 208., 10.], [267., 115., 10.], [197., 102., 10.], [198., 215., 10.], [123., 279., 10.], [126., 46., 10.], [259., 247., 10.], [196., 43., 10.], [ 54., 276., 10.], [267., 358., 10.], [ 58., 100., 10.], [259., 305., 10.], [185., 347., 16.], [261., 174., 16.], [ 46., 336., 16.], [ 54., 217., 10.], [ 55., 157., 10.], [ 57., 41., 10.], [260., 47., 16.]])
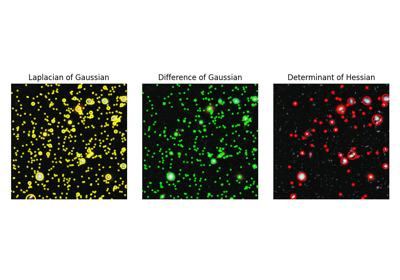
- skimage.feature.blob_doh(image, min_sigma=1, max_sigma=30, num_sigma=10, threshold=0.01, overlap=0.5, log_scale=False, *, threshold_rel=None)[源代码][源代码]#
在给定的灰度图像中查找斑点。
Blob 使用 Hessian 矩阵的行列式方法 [1] 进行检测。对于每个检测到的 Blob,该方法返回其坐标以及用于 Hessian 矩阵的高斯核的标准偏差,该矩阵的行列式检测到了 Blob。Hessian 的行列式近似使用 [2]。
- 参数:
- 图像2D ndarray
输入灰度图像。斑点可以是暗背景上的亮斑点,反之亦然。
- min_sigmafloat, 可选
用于计算Hessian矩阵的高斯核的最小标准差。保持这个值较低以检测较小的斑点。
- max_sigmafloat, 可选
用于计算Hessian矩阵的高斯核的最大标准差。保持此值较高以检测更大的斑点。
- num_sigmaint, 可选
在 min_sigma 和 max_sigma 之间考虑的标准偏差中间值的数量。
- 阈值浮点数或无,可选
尺度空间最大值的绝对下限。小于 threshold 的局部最大值将被忽略。降低此值以检测强度较低的斑点。如果同时指定了 threshold_rel,则使用较大的阈值。如果为 None,则使用 threshold_rel 代替。
- 重叠float, 可选
一个介于0和1之间的值。如果两个斑点的重叠面积超过 阈值 的比例,则较小的斑点将被消除。
- log_scalebool, 可选
如果设置了标准差的中间值,则使用以 10 为底的对数尺度进行插值。如果没有设置,则使用线性插值。
- threshold_rel浮点数或无,可选
峰的最小强度,计算为
max(doh_space) * threshold_rel,其中doh_space指的是内部计算的 Hessian 行列式 (DoH) 图像堆栈。这应该有一个介于 0 和 1 之间的值。如果为 None,则使用 threshold 代替。
- 返回:
- A(n, 3) ndarray
一个二维数组,每行代表3个值,
(y,x,sigma),其中``(y,x)``是斑点的坐标,``sigma``是检测到斑点的Hessian矩阵的高斯核的标准差。
注释
每个斑点的半径大约为 sigma。Hessian行列式的计算与标准偏差无关。因此,检测较大的斑点不会花费更多时间。在方法如
blob_dog()和blob_log()中,为较大的 sigma 计算高斯函数会花费更多时间。缺点是,由于在Hessian行列式近似中使用了箱形滤波器,该方法不能用于检测半径小于 3px 的斑点。参考文献
[2]Herbert Bay, Andreas Ess, Tinne Tuytelaars, Luc Van Gool, “SURF: Speeded Up Robust Features” ftp://ftp.vision.ee.ethz.ch/publications/articles/eth_biwi_00517.pdf
示例
>>> from skimage import data, feature >>> img = data.coins() >>> feature.blob_doh(img) array([[197. , 153. , 20.33333333], [124. , 336. , 20.33333333], [126. , 153. , 20.33333333], [195. , 100. , 23.55555556], [192. , 212. , 23.55555556], [121. , 271. , 30. ], [126. , 101. , 20.33333333], [193. , 275. , 23.55555556], [123. , 205. , 20.33333333], [270. , 363. , 30. ], [265. , 113. , 23.55555556], [262. , 243. , 23.55555556], [185. , 348. , 30. ], [156. , 302. , 30. ], [123. , 44. , 23.55555556], [260. , 173. , 30. ], [197. , 44. , 20.33333333]])
- skimage.feature.blob_log(image, min_sigma=1, max_sigma=50, num_sigma=10, threshold=0.2, overlap=0.5, log_scale=False, *, threshold_rel=None, exclude_border=False)[源代码][源代码]#
在给定的灰度图像中查找斑点。
Blob 使用高斯拉普拉斯(LoG)方法 [1] 进行检测。对于每个检测到的 Blob,该方法返回其坐标和检测到 Blob 的高斯核的标准差。
- 参数:
- 图像ndarray
输入灰度图像,假设斑点在深色背景上为浅色(黑色上的白色)。
- min_sigma标量或标量序列,可选
高斯核的最小标准差。保持较低的值以检测较小的斑点。高斯滤波器的标准差针对每个轴给出一个序列,或者作为一个单一的数字,在这种情况下,它对所有轴都是相等的。
- max_sigma标量或标量序列,可选
高斯核的最大标准差。保持这个值较高以检测更大的斑点。高斯滤波器的标准差按每个轴给出一个序列,或者作为一个单一的数字,在这种情况下,它对所有轴都是相等的。
- num_sigmaint, 可选
在 min_sigma 和 max_sigma 之间考虑的标准偏差中间值的数量。
- 阈值浮点数或无,可选
尺度空间最大值的绝对下限。小于 threshold 的局部最大值将被忽略。降低此值以检测强度较低的斑点。如果同时指定了 threshold_rel,则使用较大的阈值。如果为 None,则使用 threshold_rel 代替。
- 重叠float, 可选
一个介于0和1之间的值。如果两个斑点的重叠面积超过 阈值 的比例,则较小的斑点将被消除。
- log_scalebool, 可选
如果设置了标准差的中间值,则使用以 10 为底的对数尺度进行插值。如果没有设置,则使用线性插值。
- threshold_rel浮点数或无,可选
峰值的最小强度,计算为
max(log_space) * threshold_rel,其中log_space指的是内部计算的高斯拉普拉斯(LoG)图像堆栈。其值应在 0 到 1 之间。如果为 None,则使用 threshold 代替。- exclude_bordertuple of ints, int, 或 False, 可选
如果是整数元组,元组的长度必须与输入数组的维度匹配。元组的每个元素将排除在该维度上图像边界 exclude_border 像素内的峰值。如果是非零整数,exclude_border 将排除图像边界 exclude_border 像素内的峰值。如果是零或 False,无论峰值与边界的距离如何,都会识别峰值。
- 返回:
- A(n, image.ndim + sigma) ndarray
一个二维数组,每行代表一个2D图像的2个坐标值,或一个3D图像的3个坐标值,再加上使用的sigma(s)。当传递单个sigma时,输出为:
(r, c, sigma)或(p, r, c, sigma),其中(r, c)或(p, r, c)是斑点的坐标,sigma是检测到斑点的Gaussian核的标准差。当使用各向异性Gaussian时(每个维度的sigmas),检测到的sigma将返回每个维度。
注释
每个斑点的半径在2D图像中约为 \(\sqrt{2}\sigma\),在3D图像中约为 \(\sqrt{3}\sigma\)。
参考文献
示例
>>> from skimage import data, feature, exposure >>> img = data.coins() >>> img = exposure.equalize_hist(img) # improves detection >>> feature.blob_log(img, threshold = .3) array([[124. , 336. , 11.88888889], [198. , 155. , 11.88888889], [194. , 213. , 17.33333333], [121. , 272. , 17.33333333], [263. , 244. , 17.33333333], [194. , 276. , 17.33333333], [266. , 115. , 11.88888889], [128. , 154. , 11.88888889], [260. , 174. , 17.33333333], [198. , 103. , 11.88888889], [126. , 208. , 11.88888889], [127. , 102. , 11.88888889], [263. , 302. , 17.33333333], [197. , 44. , 11.88888889], [185. , 344. , 17.33333333], [126. , 46. , 11.88888889], [113. , 323. , 1. ]])
- skimage.feature.canny(image, sigma=1.0, low_threshold=None, high_threshold=None, mask=None, use_quantiles=False, *, mode='constant', cval=0.0)[源代码][源代码]#
使用Canny算法对图像进行边缘过滤。
- 参数:
- 图像二维数组
用于检测边缘的灰度输入图像;可以是任何数据类型。
- sigmafloat, 可选
高斯滤波器的标准差。
- 低阈值float, 可选
滞后阈值处理的下限(连接边缘)。如果为 None,则 low_threshold 设置为 dtype 最大值的 10%。
- 高阈值float, 可选
滞后阈值处理的上限(连接边缘)。如果为 None,则 high_threshold 设置为 dtype 最大值的 20%。
- 掩码数组, dtype=布尔, 可选
掩码用于限制 Canny 算法在特定区域的适用性。
- use_quantilesbool, 可选
如果
True,则将 low_threshold 和 high_threshold 视为边缘幅度图像的分位数,而不是绝对边缘幅度值。如果True,则阈值必须在范围 [0, 1] 内。- 模式str, {‘reflect’, ‘constant’, ‘nearest’, ‘mirror’, ‘wrap’}
mode参数决定了在高斯滤波过程中如何处理数组边界,其中cval是当模式等于 ‘constant’ 时的值。- cvalfloat, 可选
如果 mode 是 ‘constant’,则填充输入边缘之外的值。
- 返回:
- 输出二维数组(图像)
二值边缘图。
注释
该算法的步骤如下:
使用带有
sigma宽度的 Gaussian 平滑图像。应用水平和垂直的 Sobel 算子来获取图像中的梯度。边缘强度是梯度的范数。
将细潜在边缘转换为1像素宽的曲线。首先,在每一点找到边缘的法线。这是通过查看X-Sobel和Y-Sobel的符号和相对大小,将点分类为水平、垂直、对角和反对角四类来完成的。然后在法线和反方向查看,看看这些方向中的任何一个的值是否大于所讨论的点。使用插值来获取点的混合,而不是选择最接近法线的那个点。
执行滞后阈值处理:首先将所有高于高阈值的点标记为边缘。然后递归地将任何高于低阈值且与标记点8连通的点标记为边缘。
参考文献
[1]Canny, J., 一种边缘检测的计算方法, IEEE 模式分析与机器智能汇刊, 8:679-714, 1986 DOI:10.1109/TPAMI.1986.4767851
[2]William Green 的 Canny 教程 https://en.wikipedia.org/wiki/Canny_edge_detector
示例
>>> from skimage import feature >>> rng = np.random.default_rng() >>> # Generate noisy image of a square >>> im = np.zeros((256, 256)) >>> im[64:-64, 64:-64] = 1 >>> im += 0.2 * rng.random(im.shape) >>> # First trial with the Canny filter, with the default smoothing >>> edges1 = feature.canny(im) >>> # Increase the smoothing for better results >>> edges2 = feature.canny(im, sigma=3)

- skimage.feature.corner_fast(image, n=12, threshold=0.15)[源代码][源代码]#
提取给定图像的FAST角点。
- 参数:
- 图像(M, N) ndarray
输入图像。
- nint, 可选
在圆上的16个像素中,连续的最小像素数应全部相对于测试像素更亮或更暗。如果 Ic < Ip - 阈值,则圆上的点c相对于测试像素p更暗;如果 Ic > Ip + 阈值,则更亮。这也代表 FAST-n 角点检测器中的n。
- 阈值float, 可选
用于决定圆上的像素相对于测试像素是更亮、更暗还是相似的阈值。当需要更多角点时降低阈值,反之亦然。
- 返回:
- 响应ndarray
FAST 角点响应图像。
参考文献
[1]Rosten, E., & Drummond, T. (2006年5月). 机器学习用于高速角点检测。在欧洲计算机视觉会议 (pp. 430-443). Springer, 柏林, 海德堡. DOI:10.1007/11744023_34 http://www.edwardrosten.com/work/rosten_2006_machine.pdf
[2]Wikipedia, “加速段测试的特征”, https://en.wikipedia.org/wiki/Features_from_accelerated_segment_test
示例
>>> from skimage.feature import corner_fast, corner_peaks >>> square = np.zeros((12, 12)) >>> square[3:9, 3:9] = 1 >>> square.astype(int) array([[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], [0, 0, 0, 1, 1, 1, 1, 1, 1, 0, 0, 0], [0, 0, 0, 1, 1, 1, 1, 1, 1, 0, 0, 0], [0, 0, 0, 1, 1, 1, 1, 1, 1, 0, 0, 0], [0, 0, 0, 1, 1, 1, 1, 1, 1, 0, 0, 0], [0, 0, 0, 1, 1, 1, 1, 1, 1, 0, 0, 0], [0, 0, 0, 1, 1, 1, 1, 1, 1, 0, 0, 0], [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]]) >>> corner_peaks(corner_fast(square, 9), min_distance=1) array([[3, 3], [3, 8], [8, 3], [8, 8]])
- skimage.feature.corner_foerstner(image, sigma=1)[源代码][源代码]#
计算Foerstner角点测量响应图像。
这个角点检测器使用来自自相关矩阵 A 的信息:
A = [(imx**2) (imx*imy)] = [Axx Axy] [(imx*imy) (imy**2)] [Axy Ayy]
其中 imx 和 imy 是使用高斯滤波器平均后的第一导数。角点度量定义如下:
w = det(A) / trace(A) (size of error ellipse) q = 4 * det(A) / trace(A)**2 (roundness of error ellipse)
- 参数:
- 图像(M, N) ndarray
输入图像。
- sigmafloat, 可选
用于高斯核的标准差,该高斯核作为自相关矩阵的加权函数。
- 返回:
- wndarray
误差椭圆大小。
- qndarray
误差椭圆的圆度。
参考文献
[1]Förstner, W., & Gülch, E. (1987年6月). 一种用于检测和精确确定独特点、角点和圆形特征中心的快速算子。在快速处理摄影测量数据国际会议上发表(第281-305页)。https://cseweb.ucsd.edu/classes/sp02/cse252/foerstner/foerstner.pdf
示例
>>> from skimage.feature import corner_foerstner, corner_peaks >>> square = np.zeros([10, 10]) >>> square[2:8, 2:8] = 1 >>> square.astype(int) array([[0, 0, 0, 0, 0, 0, 0, 0, 0, 0], [0, 0, 0, 0, 0, 0, 0, 0, 0, 0], [0, 0, 1, 1, 1, 1, 1, 1, 0, 0], [0, 0, 1, 1, 1, 1, 1, 1, 0, 0], [0, 0, 1, 1, 1, 1, 1, 1, 0, 0], [0, 0, 1, 1, 1, 1, 1, 1, 0, 0], [0, 0, 1, 1, 1, 1, 1, 1, 0, 0], [0, 0, 1, 1, 1, 1, 1, 1, 0, 0], [0, 0, 0, 0, 0, 0, 0, 0, 0, 0], [0, 0, 0, 0, 0, 0, 0, 0, 0, 0]]) >>> w, q = corner_foerstner(square) >>> accuracy_thresh = 0.5 >>> roundness_thresh = 0.3 >>> foerstner = (q > roundness_thresh) * (w > accuracy_thresh) * w >>> corner_peaks(foerstner, min_distance=1) array([[2, 2], [2, 7], [7, 2], [7, 7]])
- skimage.feature.corner_harris(image, method='k', k=0.05, eps=1e-06, sigma=1)[源代码][源代码]#
计算Harris角点测量响应图像。
这个角点检测器使用来自自相关矩阵 A 的信息:
A = [(imx**2) (imx*imy)] = [Axx Axy] [(imx*imy) (imy**2)] [Axy Ayy]
其中 imx 和 imy 是使用高斯滤波器平均后的第一导数。角点度量定义如下:
det(A) - k * trace(A)**2
或者:
2 * det(A) / (trace(A) + eps)
- 参数:
- 图像(M, N) ndarray
输入图像。
- 方法{‘k’, ‘eps’}, 可选
从自相关矩阵计算响应图像的方法。
- kfloat, 可选
用于区分角点和边缘的敏感因子,通常在范围 [0, 0.2] 内。k 值较小时会导致检测到尖锐的角点。
- epsfloat, 可选
归一化因子(Noble 的角测度)。
- sigmafloat, 可选
用于高斯核的标准差,该高斯核作为自相关矩阵的加权函数。
- 返回:
- 响应ndarray
Harris 响应图像。
参考文献
示例
>>> from skimage.feature import corner_harris, corner_peaks >>> square = np.zeros([10, 10]) >>> square[2:8, 2:8] = 1 >>> square.astype(int) array([[0, 0, 0, 0, 0, 0, 0, 0, 0, 0], [0, 0, 0, 0, 0, 0, 0, 0, 0, 0], [0, 0, 1, 1, 1, 1, 1, 1, 0, 0], [0, 0, 1, 1, 1, 1, 1, 1, 0, 0], [0, 0, 1, 1, 1, 1, 1, 1, 0, 0], [0, 0, 1, 1, 1, 1, 1, 1, 0, 0], [0, 0, 1, 1, 1, 1, 1, 1, 0, 0], [0, 0, 1, 1, 1, 1, 1, 1, 0, 0], [0, 0, 0, 0, 0, 0, 0, 0, 0, 0], [0, 0, 0, 0, 0, 0, 0, 0, 0, 0]]) >>> corner_peaks(corner_harris(square), min_distance=1) array([[2, 2], [2, 7], [7, 2], [7, 7]])




- skimage.feature.corner_kitchen_rosenfeld(image, mode='constant', cval=0)[源代码][源代码]#
计算厨房和罗森菲尔德角测量响应图像。
角度的测量计算如下:
(imxx * imy**2 + imyy * imx**2 - 2 * imxy * imx * imy) / (imx**2 + imy**2)
其中 imx 和 imy 是第一个导数,imxx、imxy、imyy 是第二个导数。
- 参数:
- 图像(M, N) ndarray
输入图像。
- 模式{‘constant’, ‘reflect’, ‘wrap’, ‘nearest’, ‘mirror’}, 可选
如何处理图像边界外的值。
- cvalfloat, 可选
与模式 ‘constant’ 结合使用时,图像边界外的值。
- 返回:
- 响应ndarray
厨房和罗森菲尔德响应图像。
参考文献
[1]Kitchen, L., & Rosenfeld, A. (1982). 灰度角点检测。模式识别快报, 1(2), 95-102. DOI:10.1016/0167-8655(82)90020-4
- skimage.feature.corner_moravec(image, window_size=1)[源代码][源代码]#
计算 Moravec 角点测量响应图像。
这是最简单的角点检测器之一,相对较快,但有几个局限性(例如,不具备旋转不变性)。
- 参数:
- 图像(M, N) ndarray
输入图像。
- 窗口大小int, 可选
窗口大小。
- 返回:
- 响应ndarray
Moravec 响应图像。
参考文献
示例
>>> from skimage.feature import corner_moravec >>> square = np.zeros([7, 7]) >>> square[3, 3] = 1 >>> square.astype(int) array([[0, 0, 0, 0, 0, 0, 0], [0, 0, 0, 0, 0, 0, 0], [0, 0, 0, 0, 0, 0, 0], [0, 0, 0, 1, 0, 0, 0], [0, 0, 0, 0, 0, 0, 0], [0, 0, 0, 0, 0, 0, 0], [0, 0, 0, 0, 0, 0, 0]]) >>> corner_moravec(square).astype(int) array([[0, 0, 0, 0, 0, 0, 0], [0, 0, 0, 0, 0, 0, 0], [0, 0, 1, 1, 1, 0, 0], [0, 0, 1, 2, 1, 0, 0], [0, 0, 1, 1, 1, 0, 0], [0, 0, 0, 0, 0, 0, 0], [0, 0, 0, 0, 0, 0, 0]])
- skimage.feature.corner_orientations(image, corners, mask)[源代码][源代码]#
计算角落的方向。
角的朝向是通过使用一阶中心矩即质心法计算的。角的朝向是从角坐标到局部邻域内强度质心的向量的角度,该角度使用一阶中心矩计算。
- 参数:
- 图像(M, N) 数组
输入灰度图像。
- 角落(K, 2) 数组
角落坐标为
(行, 列)。- 掩码二维数组
定义用于计算中心矩的角点局部邻域的掩码。
- 返回:
- 方向(K, 1) 数组
角落方向在范围 [-pi, pi] 内。
参考文献
[1]Ethan Rublee, Vincent Rabaud, Kurt Konolige 和 Gary Bradski 的论文 “ORB : SIFT 和 SURF 的高效替代方案” http://www.vision.cs.chubu.ac.jp/CV-R/pdf/Rublee_iccv2011.pdf
[2]Paul L. Rosin, “测量角点属性” http://users.cs.cf.ac.uk/Paul.Rosin/corner2.pdf
示例
>>> from skimage.morphology import octagon >>> from skimage.feature import (corner_fast, corner_peaks, ... corner_orientations) >>> square = np.zeros((12, 12)) >>> square[3:9, 3:9] = 1 >>> square.astype(int) array([[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], [0, 0, 0, 1, 1, 1, 1, 1, 1, 0, 0, 0], [0, 0, 0, 1, 1, 1, 1, 1, 1, 0, 0, 0], [0, 0, 0, 1, 1, 1, 1, 1, 1, 0, 0, 0], [0, 0, 0, 1, 1, 1, 1, 1, 1, 0, 0, 0], [0, 0, 0, 1, 1, 1, 1, 1, 1, 0, 0, 0], [0, 0, 0, 1, 1, 1, 1, 1, 1, 0, 0, 0], [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]]) >>> corners = corner_peaks(corner_fast(square, 9), min_distance=1) >>> corners array([[3, 3], [3, 8], [8, 3], [8, 8]]) >>> orientations = corner_orientations(square, corners, octagon(3, 2)) >>> np.rad2deg(orientations) array([ 45., 135., -45., -135.])
- skimage.feature.corner_peaks(image, min_distance=1, threshold_abs=None, threshold_rel=None, exclude_border=True, indices=True, num_peaks=inf, footprint=None, labels=None, *, num_peaks_per_label=inf, p_norm=inf)[源代码][源代码]#
在角点测量响应图像中寻找峰值。
这与
skimage.feature.peak_local_max不同,因为它抑制了具有相同累加器值的多个连接峰值。- 参数:
- 图像(M, N) ndarray
输入图像。
- min_distanceint, 可选
峰与峰之间允许的最小距离。
- **
- p_norm浮动
使用哪种 Minkowski p-范数。应在 [1, inf] 范围内。如果可能发生溢出,有限的大 p 可能会导致 ValueError。
inf对应于切比雪夫距离,2 对应于欧几里得距离。
- 返回:
- 输出ndarray 或布尔值的 ndarray
如果 indices = True :(行,列,…)峰值的坐标。
如果 indices = False :布尔数组,形状与 image 相同,峰值由 True 值表示。
注释
在 0.18 版本发生变更: threshold_rel 的默认值已更改为 None,这相当于让
skimage.feature.peak_local_max决定默认值。这等同于 threshold_rel=0。num_peaks 限制在抑制连接峰值之前应用。要限制抑制后的峰值数量,请设置 num_peaks=np.inf 并在处理此函数的输出后进行后处理。
示例
>>> from skimage.feature import peak_local_max >>> response = np.zeros((5, 5)) >>> response[2:4, 2:4] = 1 >>> response array([[0., 0., 0., 0., 0.], [0., 0., 0., 0., 0.], [0., 0., 1., 1., 0.], [0., 0., 1., 1., 0.], [0., 0., 0., 0., 0.]]) >>> peak_local_max(response) array([[2, 2], [2, 3], [3, 2], [3, 3]]) >>> corner_peaks(response) array([[2, 2]])
- skimage.feature.corner_shi_tomasi(image, sigma=1)[源代码][源代码]#
计算 Shi-Tomasi (Kanade-Tomasi) 角点测量响应图像。
这个角点检测器使用来自自相关矩阵 A 的信息:
A = [(imx**2) (imx*imy)] = [Axx Axy] [(imx*imy) (imy**2)] [Axy Ayy]
其中 imx 和 imy 是高斯滤波器平均后的第一导数。角点度量定义为 A 的较小特征值:
((Axx + Ayy) - sqrt((Axx - Ayy)**2 + 4 * Axy**2)) / 2
- 参数:
- 图像(M, N) ndarray
输入图像。
- sigmafloat, 可选
用于高斯核的标准差,该高斯核作为自相关矩阵的加权函数。
- 返回:
- 响应ndarray
Shi-Tomasi 响应图像。
参考文献
示例
>>> from skimage.feature import corner_shi_tomasi, corner_peaks >>> square = np.zeros([10, 10]) >>> square[2:8, 2:8] = 1 >>> square.astype(int) array([[0, 0, 0, 0, 0, 0, 0, 0, 0, 0], [0, 0, 0, 0, 0, 0, 0, 0, 0, 0], [0, 0, 1, 1, 1, 1, 1, 1, 0, 0], [0, 0, 1, 1, 1, 1, 1, 1, 0, 0], [0, 0, 1, 1, 1, 1, 1, 1, 0, 0], [0, 0, 1, 1, 1, 1, 1, 1, 0, 0], [0, 0, 1, 1, 1, 1, 1, 1, 0, 0], [0, 0, 1, 1, 1, 1, 1, 1, 0, 0], [0, 0, 0, 0, 0, 0, 0, 0, 0, 0], [0, 0, 0, 0, 0, 0, 0, 0, 0, 0]]) >>> corner_peaks(corner_shi_tomasi(square), min_distance=1) array([[2, 2], [2, 7], [7, 2], [7, 7]])
- skimage.feature.corner_subpix(image, corners, window_size=11, alpha=0.99)[源代码][源代码]#
确定角点的亚像素位置。
统计测试决定角点是定义为两条边的交点还是单个峰值。根据分类结果,亚像素角点位置是基于灰度值的局部协方差确定的。如果任一统计测试的显著性水平不足,角点无法分类,输出亚像素位置被设置为NaN。
- 参数:
- 图像(M, N) ndarray
输入图像。
- 角落(K, 2) ndarray
角坐标 (行, 列)。
- 窗口大小int, 可选
用于亚像素估计的搜索窗口大小。
- alphafloat, 可选
角点分类的显著性水平。
- 返回:
- 职位(K, 2) ndarray
亚像素角点位置。对于“未分类”的角点,值为 NaN。
参考文献
[1]Förstner, W., & Gülch, E. (1987年6月). 一种用于检测和精确确定独特点、角点和圆形特征中心的快速算子。在快速处理摄影测量数据国际会议上发表(第281-305页)。https://cseweb.ucsd.edu/classes/sp02/cse252/foerstner/foerstner.pdf
示例
>>> from skimage.feature import corner_harris, corner_peaks, corner_subpix >>> img = np.zeros((10, 10)) >>> img[:5, :5] = 1 >>> img[5:, 5:] = 1 >>> img.astype(int) array([[1, 1, 1, 1, 1, 0, 0, 0, 0, 0], [1, 1, 1, 1, 1, 0, 0, 0, 0, 0], [1, 1, 1, 1, 1, 0, 0, 0, 0, 0], [1, 1, 1, 1, 1, 0, 0, 0, 0, 0], [1, 1, 1, 1, 1, 0, 0, 0, 0, 0], [0, 0, 0, 0, 0, 1, 1, 1, 1, 1], [0, 0, 0, 0, 0, 1, 1, 1, 1, 1], [0, 0, 0, 0, 0, 1, 1, 1, 1, 1], [0, 0, 0, 0, 0, 1, 1, 1, 1, 1], [0, 0, 0, 0, 0, 1, 1, 1, 1, 1]]) >>> coords = corner_peaks(corner_harris(img), min_distance=2) >>> coords_subpix = corner_subpix(img, coords, window_size=7) >>> coords_subpix array([[4.5, 4.5]])
- skimage.feature.daisy(image, step=4, radius=15, rings=3, histograms=8, orientations=8, normalization='l1', sigmas=None, ring_radii=None, visualize=False)[源代码][源代码]#
为给定图像密集提取DAISY特征描述符。
DAISY 是一个类似于 SIFT 的特征描述符,它以一种允许快速密集提取的方式制定。通常,这对于基于特征袋的图像表示是实用的。
该实现遵循 Tola 等人 [1] 的方法,但在以下几点上有所不同:
直方图箱贡献通过在色调范围(角度范围)上使用圆形高斯窗口进行平滑处理。
此代码中的空间高斯平滑的sigma值与Tola等人[R3f18658b3c6d-2]_原始代码中的sigma值不匹配。在他们的代码中,空间平滑应用于输入图像和中心直方图。然而,这种平滑在[R3f18658b3c6d-1]_中没有记录,因此被省略。
- 参数:
- 图像(M, N) 数组
输入图像(灰度)。
- 步骤int, 可选
描述符采样点之间的距离。
- 半径int, 可选
最外环的半径(以像素为单位)。
- 环int, 可选
环的数量。
- 直方图int, 可选
每个环采样的直方图数量。
- 方向int, 可选
每个直方图的方向数(bins)。
- 规范化[ ‘l1’ | ‘l2’ | ‘daisy’ | ‘off’ ], 可选
如何标准化描述符
‘l1’: 每个描述符的L1归一化。
‘l2’: 每个描述符的L2归一化。
‘daisy’: 单个直方图的L2归一化。
‘off’: 禁用归一化。
- sigmas浮点型的一维数组,可选
中心直方图和每个环形直方图的空间高斯平滑的标准偏差。sigma 数组应从中心向外排序。即,第一个 sigma 值定义中心直方图的空间平滑,最后一个 sigma 值定义最外环的空间平滑。指定 sigmas 会覆盖以下参数。
rings = len(sigmas) - 1- ring_radii可选的整数一维数组
每个环的半径(以像素为单位)。指定 ring_radii 将覆盖以下两个参数。
rings = len(ring_radii)radius = ring_radii[-1]如果同时给出了 sigmas 和 ring_radii,它们必须满足以下谓词,因为中心直方图不需要半径。
len(ring_radii) == len(sigmas) + 1- 可视化bool, 可选
生成DAISY描述符的可视化
- 返回:
- 描述数组
给定图像的DAISY描述符网格,作为数组维度 (P, Q, R)
P = ceil((M - radius*2) / step)Q = ceil((N - radius*2) / step)R = (rings * histograms + 1) * orientations- descs_img(M, N, 3) 数组(仅当 visualize==True 时)
DAISY 描述符的可视化。
参考文献
[1]Tola 等人。“Daisy: 一种应用于宽基线立体匹配的高效密集描述符。” 模式分析与机器智能,IEEE 交易 32.5 (2010): 815-830.

- skimage.feature.draw_haar_like_feature(image, r, c, width, height, feature_coord, color_positive_block=(1.0, 0.0, 0.0), color_negative_block=(0.0, 1.0, 0.0), alpha=0.5, max_n_features=None, rng=None)[源代码][源代码]#
Haar-like 特征的可视化。
- 参数:
- 图像(M, N) ndarray
需要计算特征的积分图像区域。
- r整数
检测窗口左上角的行坐标。
- c整数
检测窗口左上角的列坐标。
- 宽度整数
检测窗口的宽度。
- 高度整数
检测窗口的高度。
- feature_coordndarray 的列表元组或 None,可选
要提取的坐标数组。当你只想重新计算特征的一个子集时,这很有用。在这种情况下,feature_type 需要是一个数组,包含每个特征的类型,如
haar_like_feature_coord()返回的那样。默认情况下,计算所有坐标。- color_positive_block由3个浮点数组成的元组
指定正区块颜色的浮点数。相应的值定义了 (R, G, B) 值。默认值为红色 (1, 0, 0)。
- color_negative_block由3个浮点数组成的元组
指定负块颜色的浮点数 对应的值定义 (R, G, B) 值。默认值为蓝色 (0, 1, 0)。
- alpha浮动
范围在 [0, 1] 内的值,用于指定可视化的不透明度。1 - 完全透明,0 - 不透明。
- max_n_featuresint, 默认=None
要返回的最大特征数量。默认情况下,返回所有特征。
- rng : {
numpy.random.Generator, int}, 可选toctree是一个 reStructuredText 指令 ,这是一个非常多功能的标记。指令可以有参数、选项和内容。 伪随机数生成器。默认情况下,使用 PCG64 生成器(参见
numpy.random.default_rng())。如果 rng 是整数,则用于为生成器设定种子。当生成的特征集小于可用特征的总数时,使用 rng。
- 返回:
- 功能(M, N), ndarray
一张将添加不同特征的图片。
示例
>>> import numpy as np >>> from skimage.feature import haar_like_feature_coord >>> from skimage.feature import draw_haar_like_feature >>> feature_coord, _ = haar_like_feature_coord(2, 2, 'type-4') >>> image = draw_haar_like_feature(np.zeros((2, 2)), ... 0, 0, 2, 2, ... feature_coord, ... max_n_features=1) >>> image array([[[0. , 0.5, 0. ], [0.5, 0. , 0. ]], [[0.5, 0. , 0. ], [0. , 0.5, 0. ]]])


- skimage.feature.draw_multiblock_lbp(image, r, c, width, height, lbp_code=0, color_greater_block=(1, 1, 1), color_less_block=(0, 0.69, 0.96), alpha=0.5)[源代码][源代码]#
多块局部二值模式可视化。
总和较高的区块用阿尔法混合的白色矩形着色,而总和较低的区块用阿尔法混合的青色着色。颜色和 alpha 参数可以更改。
- 参数:
- 图像float 或 uint 的 ndarray
用于可视化图案的图像。
- r整数
包含特征的矩形左上角的行坐标。
- c整数
包含特征的矩形左上角的列坐标。
- 宽度整数
用于计算特征的9个等宽矩形之一的宽度。
- 高度整数
用于计算特征的9个等面积矩形之一的高度。
- lbp_code整数
要可视化的特征描述符。如果未提供,将使用值为0的描述符。
- color_greater_block由3个浮点数组成的元组
指定具有更高强度值的块的颜色的浮点数。它们的范围应在 [0, 1] 之间。相应的值定义 (R, G, B) 值。默认值为白色 (1, 1, 1)。
- color_greater_block由3个浮点数组成的元组
指定颜色为强度值较高的块的浮点数。它们应在范围 [0, 1] 内。相应的值定义 (R, G, B) 值。默认值为青色 (0, 0.69, 0.96)。
- alpha浮动
范围在 [0, 1] 内的值,用于指定可视化的不透明度。1 - 完全透明,0 - 不透明。
- 返回:
- 输出浮点数 ndarray
带有MB-LBP可视化的图像。
参考文献
[1]L. Zhang, R. Chu, S. Xiang, S. Liao, S.Z. Li. “Face Detection Based on Multi-Block LBP Representation”, In Proceedings: Advances in Biometrics, International Conference, ICB 2007, Seoul, Korea. http://www.cbsr.ia.ac.cn/users/scliao/papers/Zhang-ICB07-MBLBP.pdf DOI:10.1007/978-3-540-74549-5_2
- skimage.feature.fisher_vector(descriptors, gmm, *, improved=False, alpha=0.5)[源代码][源代码]#
计算给定一些描述符/向量和相关估计的高斯混合模型(GMM)的Fisher向量。
- 参数:
- 描述符np.ndarray, 形状=(n_descriptors, descriptor_length)
要计算Fisher向量表示的描述符的NumPy数组。
- gmm
sklearn.mixture.GaussianMixture 一个估计的高斯混合模型(GMM)对象,包含计算Fisher向量所需的必要参数。
- 改进bool, 默认=False
标志表示是否计算改进的Fisher向量。改进的Fisher向量是L2和幂归一化的。幂归一化简单来说就是 f(z) = sign(z) pow(abs(z), alpha),其中 0 <= alpha <= 1。
- alphafloat, 默认值=0.5
功率归一化步骤的参数。如果 improved=False,则忽略。
- 返回:
- fisher_vectornp.ndarray
计算Fisher向量,它是GMM相对于其参数(混合权重、均值和协方差矩阵)的梯度的串联。对于D维的输入描述符或向量,以及K模式的GMM,Fisher向量的维度将是2KD + K。因此,其维度与描述符/向量的数量无关。
参考文献
[1]Perronnin, F. 和 Dance, C. 在图像分类中使用视觉词汇的Fisher核,IEEE计算机视觉与模式识别会议,2007年
[2]Perronnin, F. 和 Sanchez, J. 和 Mensink T. 改进用于大规模图像分类的 Fisher 核, ECCV, 2010
示例
>>> from skimage.feature import fisher_vector, learn_gmm >>> sift_for_images = [np.random.random((10, 128)) for _ in range(10)] >>> num_modes = 16 >>> # Estimate 16-mode GMM with these synthetic SIFT vectors >>> gmm = learn_gmm(sift_for_images, n_modes=num_modes) >>> test_image_descriptors = np.random.random((25, 128)) >>> # Compute the Fisher vector >>> fv = fisher_vector(test_image_descriptors, gmm)
- skimage.feature.graycomatrix(image, distances, angles, levels=None, symmetric=False, normed=False)[源代码][源代码]#
计算灰度共生矩阵。
灰度共生矩阵是一个图像中在给定偏移量下共现的灰度值的直方图。
在 0.19 版本发生变更: greymatrix 在 0.19 版本中被重命名为 graymatrix。
- 参数:
- 图像array_like
整数类型的输入图像。仅支持正值图像。如果类型不是 uint8,则需要设置参数 levels。
- 距离array_like
像素对距离偏移列表。
- 角度array_like
以弧度为单位的像素对角度列表。
- 级别int, 可选
输入图像应包含 [0, levels-1] 范围内的整数,其中 levels 表示统计的灰度级数(通常对于 8 位图像为 256)。此参数对于 16 位或更高位图像来说是必需的,通常是图像的最大值。由于输出矩阵至少为 levels x levels,因此可能更倾向于对输入图像进行分箱处理,而不是为 levels 使用较大值。
- 对称bool, 可选
如果为真,输出矩阵 P[:, :, d, theta] 是对称的。这是通过忽略值对的顺序来实现的,因此当遇到给定偏移量的 (i, j) 时,(i, j) 和 (j, i) 都会被累加。默认值为 False。
- 标准化bool, 可选
如果为 True,则通过除以给定偏移量的累积共现总数来归一化每个矩阵 P[:, :, d, theta]。结果矩阵的元素总和为 1。默认值为 False。
- 返回:
- P4-D ndarray
灰度共生直方图。值 P[i,j,d,theta] 是灰度 j 在距离 d 和角度 theta 处从灰度 i 出现的次数。如果 normed 是 False,输出类型为 uint32,否则为 float64。维度为:级别 x 级别 x 距离数 x 角度数。
参考文献
[1]M. Hall-Beyer, 2007. GLCM Texture: A Tutorial https://prism.ucalgary.ca/handle/1880/51900 DOI:10.11575/PRISM/33280
[2]R.M. Haralick, K. Shanmugam, 和 I. Dinstein, “图像分类的纹理特征”, IEEE 系统、人、与控制论汇刊, 卷 SMC-3, 第 6 期, 页 610-621, 1973 年 11 月. DOI:10.1109/TSMC.1973.4309314
[3]M. Nadler and E.P. Smith, Pattern Recognition Engineering, Wiley-Interscience, 1993.
[4]Wikipedia, https://en.wikipedia.org/wiki/Co-occurrence_matrix
示例
计算2个GLCM:一个用于向右偏移1像素,另一个用于向上偏移1像素。
>>> image = np.array([[0, 0, 1, 1], ... [0, 0, 1, 1], ... [0, 2, 2, 2], ... [2, 2, 3, 3]], dtype=np.uint8) >>> result = graycomatrix(image, [1], [0, np.pi/4, np.pi/2, 3*np.pi/4], ... levels=4) >>> result[:, :, 0, 0] array([[2, 2, 1, 0], [0, 2, 0, 0], [0, 0, 3, 1], [0, 0, 0, 1]], dtype=uint32) >>> result[:, :, 0, 1] array([[1, 1, 3, 0], [0, 1, 1, 0], [0, 0, 0, 2], [0, 0, 0, 0]], dtype=uint32) >>> result[:, :, 0, 2] array([[3, 0, 2, 0], [0, 2, 2, 0], [0, 0, 1, 2], [0, 0, 0, 0]], dtype=uint32) >>> result[:, :, 0, 3] array([[2, 0, 0, 0], [1, 1, 2, 0], [0, 0, 2, 1], [0, 0, 0, 0]], dtype=uint32)
- skimage.feature.graycoprops(P, prop='contrast')[源代码][源代码]#
计算 GLCM 的纹理属性。
计算灰度共生矩阵的一个特征,作为矩阵的紧凑摘要。这些属性计算如下:
‘contrast’: \(\sum_{i,j=0}^{levels-1} P_{i,j}(i-j)^2\)
‘差异性’: \(\sum_{i,j=0}^{levels-1}P_{i,j}|i-j|\)
‘同质性’: \(\sum_{i,j=0}^{levels-1}\frac{P_{i,j}}{1+(i-j)^2}\)
‘ASM’: \(\sum_{i,j=0}^{levels-1} P_{i,j}^2\)
‘energy’: \(\sqrt{ASM}\)
- ‘相关性’:
- \[\begin{split}\[\sum_{i,j=0}^{levels-1} P_{i,j}\left[\frac{(i-\mu_i) \\ (j-\mu_j)}{\sqrt{(\sigma_i^2)(\sigma_j^2)}}\right]\]\end{split}\]
每个 GLCM 在计算纹理属性之前都被归一化,使其总和为 1。
在 0.19 版本发生变更: greycoprops 在 0.19 版本中被重命名为
graycoprops。- 参数:
- Pndarray
输入数组。P 是要计算指定属性的灰度共生直方图。P[i,j,d,theta] 的值是灰度级 j 在距离 d 和角度 theta 处从灰度级 i 出现的次数。
- 属性{‘对比度’, ‘不相似性’, ‘同质性’, ‘能量’, ‘相关性’, ‘ASM’}, 可选
要计算的 GLCM 属性。默认值为 ‘contrast’。
- 返回:
- 结果2-D ndarray
二维数组。results[d, a] 是第 d 个距离和第 a 个角度的属性 ‘prop’。
参考文献
[1]M. Hall-Beyer, 2007. GLCM Texture: A Tutorial v. 1.0 through 3.0. The GLCM Tutorial Home Page, https://prism.ucalgary.ca/handle/1880/51900 DOI:10.11575/PRISM/33280
示例
计算距离为 [1, 2] 和角度为 [0 度, 90 度] 的 GLCM 对比度
>>> image = np.array([[0, 0, 1, 1], ... [0, 0, 1, 1], ... [0, 2, 2, 2], ... [2, 2, 3, 3]], dtype=np.uint8) >>> g = graycomatrix(image, [1, 2], [0, np.pi/2], levels=4, ... normed=True, symmetric=True) >>> contrast = graycoprops(g, 'contrast') >>> contrast array([[0.58333333, 1. ], [1.25 , 2.75 ]])
- skimage.feature.haar_like_feature(int_image, r, c, width, height, feature_type=None, feature_coord=None)[源代码][源代码]#
计算积分图像中感兴趣区域(ROI)的类Haar特征。
Haar-like 特征已成功用于图像分类和目标检测 [1]。它已被用于 [2] 中提出的实时人脸检测算法。
- 参数:
- int_image(M, N) ndarray
需要计算特征的积分图像。
- r整数
检测窗口左上角的行坐标。
- c整数
检测窗口左上角的列坐标。
- 宽度整数
检测窗口的宽度。
- 高度整数
检测窗口的高度。
- feature_typestr 或 str 列表 或 None,可选
要考虑的功能类型:
‘type-2-x’: 沿x轴变化的2个矩形;
‘type-2-y’: 沿 y 轴变化的 2 个矩形;
‘type-3-x’: 沿x轴变化的3个矩形;
‘type-3-y’: 沿y轴变化的3个矩形;
‘type-4’: 沿x轴和y轴变化的4个矩形。
默认情况下,所有功能都会被提取。
如果与 feature_coord 一起使用,它应对应于每个相关坐标特征的特征类型。
- feature_coordndarray 的列表元组或 None,可选
要提取的坐标数组。当你只想重新计算特征的一个子集时,这很有用。在这种情况下,feature_type 需要是一个数组,包含每个特征的类型,如
haar_like_feature_coord()返回的那样。默认情况下,计算所有坐标。
- 返回:
- haar_features(n_features,) int 或 float 的 ndarray
生成的 Haar-like 特征。每个值等于正矩形和负矩形和的差。数据类型取决于 int_image 的数据类型:当 int_image 的数据类型为 uint 或 int 时为 int,当 int_image 的数据类型为 float 时为 float。
注释
在并行提取这些特征时,要注意后端的选择(即多进程与多线程)将对性能产生影响。经验法则是:在提取图像中所有可能的感兴趣区域(ROI)的特征时使用多进程;在提取有限数量的ROI的特定位置的特征时使用多线程。更多见解请参考示例 使用 Haar-like 特征描述符进行人脸分类。
参考文献
[2]Oren, M., Papageorgiou, C., Sinha, P., Osuna, E., & Poggio, T. (1997年6月). 使用小波模板进行行人检测。在计算机视觉与模式识别,1997年。会议录,1997年IEEE计算机学会会议 (第193-199页)。IEEE。http://tinyurl.com/y6ulxfta DOI:10.1109/CVPR.1997.609319
[3]Viola, Paul, 和 Michael J. Jones. “鲁棒实时人脸检测.” 国际计算机视觉杂志 57.2 (2004): 137-154. https://www.merl.com/publications/docs/TR2004-043.pdf DOI:10.1109/CVPR.2001.990517
示例
>>> import numpy as np >>> from skimage.transform import integral_image >>> from skimage.feature import haar_like_feature >>> img = np.ones((5, 5), dtype=np.uint8) >>> img_ii = integral_image(img) >>> feature = haar_like_feature(img_ii, 0, 0, 5, 5, 'type-3-x') >>> feature array([-1, -2, -3, -4, -5, -1, -2, -3, -4, -5, -1, -2, -3, -4, -5, -1, -2, -3, -4, -1, -2, -3, -4, -1, -2, -3, -4, -1, -2, -3, -1, -2, -3, -1, -2, -3, -1, -2, -1, -2, -1, -2, -1, -1, -1])
你可以为一些预计算的坐标计算特征。
>>> from skimage.feature import haar_like_feature_coord >>> feature_coord, feature_type = zip( ... *[haar_like_feature_coord(5, 5, feat_t) ... for feat_t in ('type-2-x', 'type-3-x')]) >>> # only select one feature over two >>> feature_coord = np.concatenate([x[::2] for x in feature_coord]) >>> feature_type = np.concatenate([x[::2] for x in feature_type]) >>> feature = haar_like_feature(img_ii, 0, 0, 5, 5, ... feature_type=feature_type, ... feature_coord=feature_coord) >>> feature array([ 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, -1, -3, -5, -2, -4, -1, -3, -5, -2, -4, -2, -4, -2, -4, -2, -1, -3, -2, -1, -1, -1, -1, -1])
- skimage.feature.haar_like_feature_coord(width, height, feature_type=None)[源代码][源代码]#
计算Haar-like特征的坐标。
- 参数:
- 宽度整数
检测窗口的宽度。
- 高度整数
检测窗口的高度。
- feature_typestr 或 str 列表 或 None,可选
要考虑的功能类型:
‘type-2-x’: 沿x轴变化的2个矩形;
‘type-2-y’: 沿 y 轴变化的 2 个矩形;
‘type-3-x’: 沿x轴变化的3个矩形;
‘type-3-y’: 沿y轴变化的3个矩形;
‘type-4’: 沿x轴和y轴变化的4个矩形。
默认情况下,所有功能都会被提取。
- 返回:
- feature_coord(n_features, n_rectangles, 2, 2), 包含元组坐标的列表的 ndarray
每个特征的矩形坐标。
- feature_type(n_features,), str 的 ndarray
每个特征对应的类型。
示例
>>> import numpy as np >>> from skimage.transform import integral_image >>> from skimage.feature import haar_like_feature_coord >>> feat_coord, feat_type = haar_like_feature_coord(2, 2, 'type-4') >>> feat_coord array([ list([[(0, 0), (0, 0)], [(0, 1), (0, 1)], [(1, 1), (1, 1)], [(1, 0), (1, 0)]])], dtype=object) >>> feat_type array(['type-4'], dtype=object)
- skimage.feature.hessian_matrix(image, sigma=1, mode='constant', cval=0, order='rc', use_gaussian_derivatives=None)[源代码][源代码]#
计算 Hessian 矩阵。
在二维中,Hessian矩阵定义为:
H = [Hrr Hrc] [Hrc Hcc]
这是通过将图像与高斯核在相应的 r 和 c 方向上的二阶导数进行卷积计算得到的。
这里的实现还支持 n 维数据。
- 参数:
- 图像ndarray
输入图像。
- sigma浮动
用于高斯核的标准差,该高斯核作为自相关矩阵的加权函数。
- 模式{‘constant’, ‘reflect’, ‘wrap’, ‘nearest’, ‘mirror’}, 可选
如何处理图像边界外的值。
- cvalfloat, 可选
与模式 ‘constant’ 结合使用时,图像边界外的值。
- 顺序{‘rc’, ‘xy’}, 可选
对于2D图像,此参数允许在梯度计算中使用图像轴的反向或正向顺序。’rc’ 表示首先使用第一个轴(Hrr, Hrc, Hcc),而 ‘xy’ 表示首先使用最后一个轴(Hxx, Hxy, Hyy)。具有更高维度的图像必须始终使用 ‘rc’ 顺序。
- use_gaussian_derivatives布尔值,可选
指示Hessian是通过与高斯导数卷积计算的,还是通过简单的有限差分操作计算的。
- 返回:
- H_elemsndarray 列表
输入图像中每个像素的Hessian矩阵的上对角元素。在2D中,这将是一个包含[Hrr, Hrc, Hcc]的三元素列表。在nD中,列表将包含``(n**2 + n) / 2``个数组。
注释
导数和卷积的分配性质允许我们将图像 I 与高斯核 G 平滑后的导数重新表述为图像与 G 的导数的卷积。
\[\frac{\partial }{\partial x_i}(I * G) = I * \left( \frac{\partial }{\partial x_i} G \right)\]当
use_gaussian_derivatives为True时,此属性用于计算构成 Hessian 矩阵的二阶导数。当
use_gaussian_derivatives为False时,将使用高斯平滑图像上的简单有限差分代替。示例
>>> from skimage.feature import hessian_matrix >>> square = np.zeros((5, 5)) >>> square[2, 2] = 4 >>> Hrr, Hrc, Hcc = hessian_matrix(square, sigma=0.1, order='rc', ... use_gaussian_derivatives=False) >>> Hrc array([[ 0., 0., 0., 0., 0.], [ 0., 1., 0., -1., 0.], [ 0., 0., 0., 0., 0.], [ 0., -1., 0., 1., 0.], [ 0., 0., 0., 0., 0.]])
- skimage.feature.hessian_matrix_det(image, sigma=1, approximate=True)[源代码][源代码]#
计算图像上近似的 Hessian 行列式。
二维近似方法使用积分图像上的盒式滤波器来计算近似的Hessian行列式。
- 参数:
- 图像ndarray
用于计算 Hessian 行列式的图像。
- sigmafloat, 可选
用于Hessian矩阵的高斯核的标准差。
- 近似bool, 可选
如果
True且图像是二维的,使用一个快得多的近似计算。此参数对三维及更高维图像无效。
- 返回:
- 出数组
Hessian 行列式的数组。
注释
对于2D图像,当
approximate=True时,此方法的运行时间仅取决于图像的大小。正如预期的那样,它与 sigma 无关。缺点是,对于小于 3 的 sigma ,结果不准确,即与通过计算Hessian矩阵并取其行列式得到的结果不相似。参考文献
[1]Herbert Bay, Andreas Ess, Tinne Tuytelaars, Luc Van Gool, “SURF: Speeded Up Robust Features” ftp://ftp.vision.ee.ethz.ch/publications/articles/eth_biwi_00517.pdf
- skimage.feature.hessian_matrix_eigvals(H_elems)[源代码][源代码]#
计算 Hessian 矩阵的特征值。
- 参数:
- H_elemsndarray 列表
Hessian 矩阵的上对角元素,由
hessian_matrix返回。
- 返回:
- eigsndarray
Hessian 矩阵的特征值,按降序排列。特征值是主要维度。也就是说,
eigs[i, j, k]包含在位置 (j, k) 处的第 i 大的特征值。
示例
>>> from skimage.feature import hessian_matrix, hessian_matrix_eigvals >>> square = np.zeros((5, 5)) >>> square[2, 2] = 4 >>> H_elems = hessian_matrix(square, sigma=0.1, order='rc', ... use_gaussian_derivatives=False) >>> hessian_matrix_eigvals(H_elems)[0] array([[ 0., 0., 2., 0., 0.], [ 0., 1., 0., 1., 0.], [ 2., 0., -2., 0., 2.], [ 0., 1., 0., 1., 0.], [ 0., 0., 2., 0., 0.]])
- skimage.feature.hog(image, orientations=9, pixels_per_cell=(8, 8), cells_per_block=(3, 3), block_norm='L2-Hys', visualize=False, transform_sqrt=False, feature_vector=True, *, channel_axis=None)[源代码][源代码]#
提取给定图像的方向梯度直方图 (HOG)。
通过计算方向梯度直方图 (HOG)
(可选) 全局图像归一化
在 row 和 col 中计算梯度图像
计算梯度直方图
跨块标准化
展平为特征向量
- 参数:
- 图像(M, N[, C]) ndarray
输入图像。
- 方向int, 可选
方向箱的数量。
- pixels_per_cell2-元组 (int, int), 可选
单元格的大小(以像素为单位)。
- cells_per_block2-元组 (int, int), 可选
每个块中的单元格数量。
- block_normstr {‘L1’, ‘L1-sqrt’, ‘L2’, ‘L2-Hys’}, 可选
块归一化方法:
L1使用L1范数进行归一化。
L1-sqrt使用L1范数进行归一化,然后取平方根。
L2使用 L2-范数进行归一化。
L2-Hys使用L2范数进行归一化,然后将其最大值限制为0.2(Hys`代表`滞后),并使用L2范数进行重新归一化。(默认)详情请参见[Ra159ccd8c91f-3]_,[4]。
- 可视化bool, 可选
同时返回一个HOG图像。对于每个单元格和方向箱,图像包含一条以单元格中心为中心的线段,该线段垂直于方向箱所跨越的角度范围的中点,并且其强度与相应的直方图值成比例。
- transform_sqrtbool, 可选
在处理之前,应用幂律压缩来归一化图像。如果图像包含负值,请勿使用此方法。另请参见下面的 notes 部分。
- 特征向量bool, 可选
在返回结果之前,通过调用 .ravel() 将数据作为特征向量返回。
- channel_axisint 或 None, 可选
如果为 None,则假定图像是灰度图像(单通道)。否则,此参数指示数组的哪个轴对应于通道。
Added in version 0.19: channel_axis 在 0.19 版本中被添加。
- 返回:
- 出(n_blocks_row, n_blocks_col, n_cells_row, n_cells_col, n_orient) ndarray
图像的HOG描述符。如果 feature_vector 为 True,则返回一个一维(扁平化)数组。
- hog_image(M, N) ndarray, 可选
HOG 图像的可视化。仅在 visualize 为 True 时提供。
- Raises:
- ValueError
如果图像对于像素每单元格和单元格每块的值来说太小。
注释
所展示的代码实现了来自 [2] 的 HOG 提取方法,并进行了以下更改:(I) 使用 (3, 3) 单元块(论文中为 (2, 2));(II) 单元内不进行平滑处理(论文中使用 sigma=8pix 的高斯空间窗口);(III) 使用 L1 块归一化(论文中为 L2-Hys)。
幂律压缩,也称为伽马校正,用于减少阴影和光照变化的影响。压缩使暗区变亮。当 transform_sqrt 关键字参数设置为
True时,函数会计算每个颜色通道的平方根,然后对图像应用 hog 算法。参考文献
[2]Dalal, N 和 Triggs, B, 用于人体检测的方向梯度直方图, IEEE 计算机学会计算机视觉与模式识别会议 2005 圣地亚哥, CA, USA, https://lear.inrialpes.fr/people/triggs/pubs/Dalal-cvpr05.pdf, DOI:10.1109/CVPR.2005.177
[3]Lowe, D.G., 从尺度不变关键点中提取的独特图像特征, 国际计算机视觉杂志 (2004) 60: 91, http://www.cs.ubc.ca/~lowe/papers/ijcv04.pdf, DOI:10.1023/B:VISI.0000029664.99615.94
[4]Dalal, N, 在图像和视频中寻找人, 人机交互 [cs.HC], 格勒诺布尔国立理工学院 - INPG, 2006, https://tel.archives-ouvertes.fr/tel-00390303/file/NavneetDalalThesis.pdf

- skimage.feature.learn_gmm(descriptors, *, n_modes=32, gm_args=None)[源代码][源代码]#
给定一组描述符和模式数量(即高斯分布),估计一个高斯混合模型(GMM)。这个函数本质上是一个围绕 scikit-learn 实现的 GMM 的包装器,即
sklearn.mixture.GaussianMixture类。由于Fisher向量的性质,底层scikit-learn类唯一强制的参数是covariance_type,它必须是’diag’。
没有简单的方法可以事先知道 n_modes 的值。通常,该值通常是
{16, 32, 64, 128}之一。可以训练几个 GMM,并选择使 GMM 的对数概率最大化的那个,或者选择 n_modes 使得在结果的 Fisher 向量上训练的下游分类器具有最大性能。- 参数:
- 描述符np.ndarray (N, M) 或列表 [(N1, M), (N2, M), …]
用于估计GMM的描述符的NumPy数组列表,或单个NumPy数组。允许使用NumPy数组列表的原因是,在使用Fisher向量编码时,通常会为数据集中的每个样本/图像分别计算描述符/向量,例如每个图像的SIFT向量。如果传入的是列表,那么每个元素必须是一个NumPy数组,其中行数可能不同(例如,每个图像的SIFT向量数量不同),但每个数组的列数必须相同(即维度必须相同)。
- n_modes整数
在GMM估计期间要估计的模式/高斯分布的数量。
- gm_argsdict
可以传递给底层 scikit-learn
sklearn.mixture.GaussianMixture类的关键字参数。
- 返回:
- gmm
sklearn.mixture.GaussianMixture 估计的GMM对象,包含计算Fisher向量所需的必要参数。
- gmm
参考文献
示例
>>> from skimage.feature import fisher_vector >>> rng = np.random.Generator(np.random.PCG64()) >>> sift_for_images = [rng.standard_normal((10, 128)) for _ in range(10)] >>> num_modes = 16 >>> # Estimate 16-mode GMM with these synthetic SIFT vectors >>> gmm = learn_gmm(sift_for_images, n_modes=num_modes)
- skimage.feature.local_binary_pattern(image, P, R, method='default')[源代码][源代码]#
计算图像的局部二值模式(LBP)。
LBP 是一种常用于纹理分类的视觉描述符。
- 参数:
- 图像(M, N) 数组
2D 灰度图像。
- P整数
环形对称邻域集点的数量(角空间的量化)。
- R浮动
圆的半径(操作符的空间分辨率)。
- 方法str {‘default’, ‘ror’, ‘uniform’, ‘nri_uniform’, ‘var’}, 可选
确定模式的方法:
- 返回:
- 输出(M, N) 数组
LBP 图像。
参考文献
[1]T. Ojala, M. Pietikainen, T. Maenpaa, “Multiresolution gray-scale and rotation invariant texture classification with local binary patterns”, IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 24, no. 7, pp. 971-987, July 2002 DOI:10.1109/TPAMI.2002.1017623
[2]T. Ahonen, A. Hadid and M. Pietikainen. “Face recognition with local binary patterns”, in Proc. Eighth European Conf. Computer Vision, Prague, Czech Republic, May 11-14, 2004, pp. 469-481, 2004. http://citeseerx.ist.psu.edu/viewdoc/summary?doi=10.1.1.214.6851 DOI:10.1007/978-3-540-24670-1_36
[3]T. Ahonen, A. Hadid and M. Pietikainen, “Face Description with Local Binary Patterns: Application to Face Recognition”, IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 28, no. 12, pp. 2037-2041, Dec. 2006 DOI:10.1109/TPAMI.2006.244
- skimage.feature.match_descriptors(descriptors1, descriptors2, metric=None, p=2, max_distance=inf, cross_check=True, max_ratio=1.0)[源代码][源代码]#
描述符的暴力匹配。
对于第一组中的每个描述符,此匹配器会找到第二组中最接近的描述符(并且在启用交叉检查的情况下,反之亦然)。
- 参数:
- 描述符1(M, P) 数组
第一张图像中关于M个关键点的P大小的描述符。
- 描述符2(N, P) 数组
第二张图像中关于 N 个关键点的 P 大小的描述符。
- 指标{‘euclidean’, ‘cityblock’, ‘minkowski’, ‘hamming’, …} , 可选
计算两个描述符之间距离的度量。查看
scipy.spatial.distance.cdist以获取所有可能的类型。对于二进制描述符,应使用汉明距离。默认情况下,对于 dtype 为 float 或 double 的所有描述符,使用 L2-范数,对于二进制描述符,自动使用汉明距离。- pint, 可选
应用于
metric='minkowski'的 p-范数。- 最大距离float, 可选
在不同图像中的两个关键点描述符之间允许的最大距离,以被视为匹配。
- 交叉检查bool, 可选
如果为真,匹配的关键点在交叉检查后返回,即如果关键点2是第二张图像中关键点1的最佳匹配,且关键点1是第一张图像中关键点2的最佳匹配,则返回匹配对(关键点1,关键点2)。
- max_ratiofloat, 可选
第二组描述符中第一个和第二个最近描述符之间距离的最大比率。此阈值有助于过滤两组描述符之间的模糊匹配。此值的选择取决于所选描述符的统计数据,例如,对于SIFT描述符,通常选择0.8的值,参见D.G. Lowe,“从尺度不变关键点中提取的独特图像特征”,国际计算机视觉杂志,2004年。
- 返回:
- 匹配(Q, 2) 数组
第一组和第二组描述符中对应匹配的索引,其中
matches[:, 0]表示第一组的索引,matches[:, 1]表示第二组的索引。

- skimage.feature.match_template(image, template, pad_input=False, mode='constant', constant_values=0)[源代码][源代码]#
使用归一化相关性将模板匹配到2-D或3-D图像。
输出是一个数组,其值介于 -1.0 和 1.0 之间。给定位置的值对应于图像与模板之间的相关系数。
对于 pad_input=True,匹配对应于模板的中心,否则对应于模板的左上角。要找到最佳匹配,您必须在响应(输出)图像中搜索峰值。
- 参数:
- 图像(M, N[, P]) 数组
2-D 或 3-D 输入图像。
- 模板(m, n[, p]) 数组
定位模板。它必须是 (m <= M, n <= N[, p <= P])。
- pad_input布尔
如果为 True,则填充 image 以使输出与图像大小相同,并且输出值对应于模板中心。否则,输出是一个形状为 (M - m + 1, N - n + 1) 的数组,适用于 (M, N) 图像和 (m, n) 模板,并且匹配对应于模板的原点(左上角)。
- mode : 参见
numpy.pad,可选见 填充模式。
- constant_values : 参见
numpy.pad,可选见 与
mode='constant'一起使用的常量值。
- 返回:
- 输出数组
响应图像与相关系数。
注释
交叉相关的详细信息在 [1] 中呈现。此实现使用图像和模板的FFT卷积。参考文献 [2] 提出了类似的推导,但本参考文献中提出的近似方法未在我们的实现中使用。
参考文献
[1]J. P. Lewis, “Fast Normalized Cross-Correlation”, Industrial Light and Magic.
[2]Briechle 和 Hanebeck, “使用快速归一化互相关进行模板匹配”, SPIE 会议录 (2001). DOI:10.1117/12.421129
示例
>>> template = np.zeros((3, 3)) >>> template[1, 1] = 1 >>> template array([[0., 0., 0.], [0., 1., 0.], [0., 0., 0.]]) >>> image = np.zeros((6, 6)) >>> image[1, 1] = 1 >>> image[4, 4] = -1 >>> image array([[ 0., 0., 0., 0., 0., 0.], [ 0., 1., 0., 0., 0., 0.], [ 0., 0., 0., 0., 0., 0.], [ 0., 0., 0., 0., 0., 0.], [ 0., 0., 0., 0., -1., 0.], [ 0., 0., 0., 0., 0., 0.]]) >>> result = match_template(image, template) >>> np.round(result, 3) array([[ 1. , -0.125, 0. , 0. ], [-0.125, -0.125, 0. , 0. ], [ 0. , 0. , 0.125, 0.125], [ 0. , 0. , 0.125, -1. ]]) >>> result = match_template(image, template, pad_input=True) >>> np.round(result, 3) array([[-0.125, -0.125, -0.125, 0. , 0. , 0. ], [-0.125, 1. , -0.125, 0. , 0. , 0. ], [-0.125, -0.125, -0.125, 0. , 0. , 0. ], [ 0. , 0. , 0. , 0.125, 0.125, 0.125], [ 0. , 0. , 0. , 0.125, -1. , 0.125], [ 0. , 0. , 0. , 0.125, 0.125, 0.125]])

- skimage.feature.multiblock_lbp(int_image, r, c, width, height)[源代码][源代码]#
多块局部二值模式 (MB-LBP)。
这些特征的计算方式类似于局部二值模式(LBPs),(参见
local_binary_pattern()),不同之处在于使用的是求和块而非单个像素值。MB-LBP 是 LBP 的扩展,可以在常数时间内使用积分图像在多个尺度上计算。使用九个等大小的矩形来计算特征。对于每个矩形,计算像素强度的总和。这些总和与中心矩形的总和的比较决定了特征,类似于 LBP。
- 参数:
- int_image(N, M) 数组
积分图像。
- r整数
包含特征的矩形左上角的行坐标。
- c整数
包含特征的矩形左上角的列坐标。
- 宽度整数
用于计算特征的9个等宽矩形之一的宽度。
- 高度整数
用于计算特征的9个等面积矩形之一的高度。
- 返回:
- 输出整数
8位 MB-LBP 特征描述符。
参考文献
[1]L. Zhang, R. Chu, S. Xiang, S. Liao, S.Z. Li. “Face Detection Based on Multi-Block LBP Representation”, In Proceedings: Advances in Biometrics, International Conference, ICB 2007, Seoul, Korea. http://www.cbsr.ia.ac.cn/users/scliao/papers/Zhang-ICB07-MBLBP.pdf DOI:10.1007/978-3-540-74549-5_2
- skimage.feature.multiscale_basic_features(image, intensity=True, edges=True, texture=True, sigma_min=0.5, sigma_max=16, num_sigma=None, num_workers=None, *, channel_axis=None)[源代码][源代码]#
单通道或多通道 nd 图像的局部特征。
通过高斯模糊,在不同尺度上计算强度、梯度强度和局部结构。
- 参数:
- 图像ndarray
输入图像,可以是灰度图像或多通道图像。
- 强度bool, 默认 True
如果为真,不同尺度上的像素强度平均值将被添加到特征集中。
- 边缘bool, 默认 True
如果为真,不同尺度上局部梯度强度的平均值将被添加到特征集中。
- 纹理bool, 默认 True
如果为真,在不同尺度下高斯模糊后的Hessian矩阵的特征值将被添加到特征集中。
- sigma_minfloat, 可选
在提取特征之前,用于平均局部邻域的高斯核的最小值。
- sigma_maxfloat, 可选
在使用高斯核提取特征之前,用于平均局部邻域的最大值。
- num_sigmaint, 可选
高斯核在 sigma_min 和 sigma_max 之间的值的数量。如果为 None,则使用 sigma_min 乘以 2 的幂。
- num_workersint 或 None, 可选
要使用的并行线程数。如果设置为
None,则使用所有可用核心。- channel_axisint 或 None, 可选
如果为 None,则假定图像是灰度图像(单通道)。否则,此参数指示数组的哪个轴对应于通道。
Added in version 0.19:
channel_axis在 0.19 版本中被添加。
- 返回:
- 功能np.ndarray
形状为
image.shape + (n_features,)的数组。当 channel_axis 不是 None 时,所有通道沿着特征维度连接。(即n_features == n_features_singlechannel * n_channels)
- skimage.feature.peak_local_max(image, min_distance=1, threshold_abs=None, threshold_rel=None, exclude_border=True, num_peaks=inf, footprint=None, labels=None, num_peaks_per_label=inf, p_norm=inf)[源代码][源代码]#
在图像中找到峰值作为坐标列表。
峰值是区域 2 * min_distance + 1 内的局部最大值(即峰值之间的最小距离至少为 min_distance)。
如果同时提供了 threshold_abs 和 threshold_rel,则选择两者中的最大值作为峰值的最小强度阈值。
在 0.18 版本发生变更: 在版本 0.18 之前,在 min_distance 半径内的所有相同高度的峰值都会被返回,但这可能会导致意外行为。从 0.18 开始,区域内会返回一个任意的峰值。参见问题 gh-2592。
- 参数:
- 图像ndarray
输入图像。
- min_distanceint, 可选
允许的峰值之间的最小距离。要找到最大数量的峰值,请使用 min_distance=1。
- threshold_abs浮点数或无,可选
峰的最小强度。默认情况下,绝对阈值是图像的最小强度。
- threshold_rel浮点数或无,可选
峰的最小强度,计算为
max(image) * threshold_rel。- exclude_borderint, int 的元组, 或 bool, 可选
如果为正整数,exclude_border 会排除图像边界 exclude_border 像素内的峰值。如果为非负整数的元组,元组的长度必须与输入数组的维度匹配。元组的每个元素将排除沿该维度图像边界 exclude_border 像素内的峰值。如果为 True,则使用 min_distance 参数的值。如果为零或 False,则无论峰值与边界的距离如何,都会识别峰值。
- num_peaksint, 可选
最大峰值数量。当峰值数量超过 num_peaks 时,根据最高峰值强度返回 num_peaks 个峰值。
- 足迹布尔类型的 ndarray,可选
如果提供,footprint == 1 表示在 image 的每个点上搜索峰值的局部区域。
- 标签整数 ndarray,可选
如果提供,每个唯一的区域 labels == value 代表一个唯一的峰值搜索区域。零保留为背景。
- 每个标签的峰值数量int, 可选
每个标签的最大峰值数。
- p_norm浮动
使用哪种 Minkowski p-范数。应在 [1, inf] 范围内。如果可能发生溢出,有限的大 p 可能会导致 ValueError。
inf对应于切比雪夫距离,2 对应于欧几里得距离。
- 返回:
- 输出ndarray
峰的坐标。
注释
峰值局部最大值函数返回图像中局部峰值(最大值)的坐标。在内部,使用最大值滤波器来寻找局部最大值。此操作会膨胀原始图像。在比较膨胀后的图像和原始图像后,该函数返回膨胀图像与原始图像相等处的峰值坐标。
示例
>>> img1 = np.zeros((7, 7)) >>> img1[3, 4] = 1 >>> img1[3, 2] = 1.5 >>> img1 array([[0. , 0. , 0. , 0. , 0. , 0. , 0. ], [0. , 0. , 0. , 0. , 0. , 0. , 0. ], [0. , 0. , 0. , 0. , 0. , 0. , 0. ], [0. , 0. , 1.5, 0. , 1. , 0. , 0. ], [0. , 0. , 0. , 0. , 0. , 0. , 0. ], [0. , 0. , 0. , 0. , 0. , 0. , 0. ], [0. , 0. , 0. , 0. , 0. , 0. , 0. ]])
>>> peak_local_max(img1, min_distance=1) array([[3, 2], [3, 4]])
>>> peak_local_max(img1, min_distance=2) array([[3, 2]])
>>> img2 = np.zeros((20, 20, 20)) >>> img2[10, 10, 10] = 1 >>> img2[15, 15, 15] = 1 >>> peak_idx = peak_local_max(img2, exclude_border=0) >>> peak_idx array([[10, 10, 10], [15, 15, 15]])
>>> peak_mask = np.zeros_like(img2, dtype=bool) >>> peak_mask[tuple(peak_idx.T)] = True >>> np.argwhere(peak_mask) array([[10, 10, 10], [15, 15, 15]])


- skimage.feature.plot_matches(ax, image1, image2, keypoints1, keypoints2, matches, keypoints_color='k', matches_color=None, only_matches=False, alignment='horizontal')[源代码][源代码]#
已弃用:
plot_matches自版本 0.23 起已弃用,并将在版本 0.25 中移除。请改用 skimage.feature.plot_matched_features。绘制匹配的特征。
自 0.23 版本弃用.
- 参数:
- axmatplotlib.axes.Axes
在此轴上绘制匹配和图像。
- image1(N, M [, 3]) 数组
第一张灰度或彩色图像。
- image2(N, M [, 3]) 数组
第二张灰度或彩色图像。
- 要点1(K1, 2) 数组
第一个关键点的坐标为
(行, 列)。- 要点2(K2, 2) 数组
第二个关键点的坐标为
(行, 列)。- 匹配(Q, 2) 数组
第一组和第二组描述符中对应匹配的索引,其中
matches[:, 0]表示第一组的索引,matches[:, 1]表示第二组的索引。- keypoints_colormatplotlib 颜色,可选
关键点位置的颜色。
- matches_colormatplotlib 颜色,可选
用于连接关键点匹配的线条的颜色。默认情况下,颜色是随机选择的。
- 仅匹配bool, 可选
是否仅绘制匹配项而不绘制关键点位置。
- 对齐{‘horizontal’, ‘vertical’}, 可选
是否并排显示图像,
'horizontal',或一个在另一个之上,'vertical'。
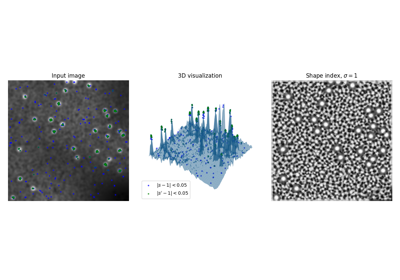
- skimage.feature.shape_index(image, sigma=1, mode='constant', cval=0)[源代码][源代码]#
计算形状指数。
Koenderink & van Doorn [1] 定义的形状指数是一种局部曲率的单值度量,假设图像为一个3D平面,其强度代表高度。
它源自Hessian矩阵的特征值,其值范围从-1到1(在*平坦*区域中未定义(=NaN)),以下范围代表以下形状:
形状指数的范围及其对应的形状。# 间隔(s in …)
形状
[ -1, -7/8)
球形杯
[-7/8, -5/8)
通过
[-5/8, -3/8)
鲁特
[-3/8, -1/8)
鞍槽
[-1/8, +1/8)
鞍座
[+1/8, +3/8)
鞍脊
[+3/8, +5/8)
岭
[+5/8, +7/8)
穹顶
[+7/8, +1]
球冠
- 参数:
- 图像(M, N) ndarray
输入图像。
- sigmafloat, 可选
用于高斯核的标准差,该高斯核用于在计算Hessian特征值之前平滑输入数据。
- 模式{‘constant’, ‘reflect’, ‘wrap’, ‘nearest’, ‘mirror’}, 可选
如何处理图像边界外的值
- cvalfloat, 可选
与模式 ‘constant’ 结合使用时,图像边界外的值。
- 返回:
- sndarray
形状索引
参考文献
[1]Koenderink, J. J. & van Doorn, A. J., “表面形状和曲率尺度”, 图像与视觉计算, 1992, 10, 557-564. DOI:10.1016/0262-8856(92)90076-F
示例
>>> from skimage.feature import shape_index >>> square = np.zeros((5, 5)) >>> square[2, 2] = 4 >>> s = shape_index(square, sigma=0.1) >>> s array([[ nan, nan, -0.5, nan, nan], [ nan, -0. , nan, -0. , nan], [-0.5, nan, -1. , nan, -0.5], [ nan, -0. , nan, -0. , nan], [ nan, nan, -0.5, nan, nan]])
- skimage.feature.structure_tensor(image, sigma=1, mode='constant', cval=0, order='rc')[源代码][源代码]#
使用平方差之和计算结构张量。
二维结构张量 A 定义为:
A = [Arr Arc] [Arc Acc]
这是通过图像中每个像素周围局部窗口内的加权平方差之和来近似的。这个公式可以扩展到更多维度(参见 [1])。
- 参数:
- 图像ndarray
输入图像。
- sigma浮点数或浮点数数组,可选
用于高斯核的标准差,该核作为局部平方差和的加权函数。如果 sigma 是一个可迭代对象,其长度必须等于 image.ndim,并且每个元素用于沿其各自轴应用的高斯核。
- 模式{‘constant’, ‘reflect’, ‘wrap’, ‘nearest’, ‘mirror’}, 可选
如何处理图像边界外的值。
- cvalfloat, 可选
与模式 ‘constant’ 结合使用时,图像边界外的值。
- 顺序{‘rc’, ‘xy’}, 可选
注意:’xy’ 仅适用于2D图像,更高维度必须始终使用 ‘rc’ 顺序。此参数允许在梯度计算中使用图像轴的反向或正向顺序。’rc’ 表示首先使用第一个轴(Arr, Arc, Acc),而 ‘xy’ 表示首先使用最后一个轴(Axx, Axy, Ayy)。
- 返回:
- A_elemsndarray 列表
输入图像中每个像素的结构张量的上对角元素。
参考文献
示例
>>> from skimage.feature import structure_tensor >>> square = np.zeros((5, 5)) >>> square[2, 2] = 1 >>> Arr, Arc, Acc = structure_tensor(square, sigma=0.1, order='rc') >>> Acc array([[0., 0., 0., 0., 0.], [0., 1., 0., 1., 0.], [0., 4., 0., 4., 0.], [0., 1., 0., 1., 0.], [0., 0., 0., 0., 0.]])
- skimage.feature.structure_tensor_eigenvalues(A_elems)[源代码][源代码]#
计算结构张量的特征值。
- 参数:
- A_elemsndarray 列表
结构张量的上对角元素,由
structure_tensor返回。
- 返回:
- ndarray
结构张量的特征值,按降序排列。特征值是主要维度。也就是说,坐标 [i, j, k] 对应于位置 (j, k) 处的第 i 大特征值。
示例
>>> from skimage.feature import structure_tensor >>> from skimage.feature import structure_tensor_eigenvalues >>> square = np.zeros((5, 5)) >>> square[2, 2] = 1 >>> A_elems = structure_tensor(square, sigma=0.1, order='rc') >>> structure_tensor_eigenvalues(A_elems)[0] array([[0., 0., 0., 0., 0.], [0., 2., 4., 2., 0.], [0., 4., 0., 4., 0.], [0., 2., 4., 2., 0.], [0., 0., 0., 0., 0.]])
- class skimage.feature.BRIEF(descriptor_size=256, patch_size=49, mode='normal', sigma=1, rng=1)[源代码][源代码]#
基类:
DescriptorExtractorBRIEF 二进制描述符提取器。
BRIEF (Binary Robust Independent Elementary Features) 是一种高效的特征点描述符。即使在仅使用相对较少的比特位时,它也具有很高的区分性,并且通过简单的强度差异测试来计算。
对于每个关键点,会进行特定分布的 N 对像素的强度比较,从而生成一个长度为 N 的二进制描述符。对于二进制描述符,可以使用汉明距离进行特征匹配,这相比于 L2 范数,计算成本更低。
- 参数:
- descriptor_sizeint, 可选
每个关键点的 BRIEF 描述符的大小。作者推荐的大小为 128、256 和 512。默认值为 256。
- patch_sizeint, 可选
二维方形补丁采样区域在关键点周围的长度。默认值是49。
- 模式{‘normal’, ‘uniform’}, 可选
关键点周围决策像素对采样位置的概率分布。
- rng : {
numpy.random.Generator, int}, 可选toctree是一个 reStructuredText 指令 ,这是一个非常多功能的标记。指令可以有参数、选项和内容。 伪随机数生成器 (RNG)。默认情况下,使用 PCG64 生成器(参见
numpy.random.default_rng())。如果 rng 是整数,则用于为生成器设定种子。PRNG 用于决策像素对的随机采样。从一个边长为 patch_size 的方形窗口中,使用 mode 参数采样像素对,以构建基于强度比较的描述符。
为了在图像之间进行匹配,应使用相同的 rng 来构建描述符。为了便于实现这一点:
rng 默认值为 1
对
extract方法的后续调用将使用相同的 rng/seed。
- sigmafloat, 可选
应用于图像的高斯低通滤波器的标准差,以缓解噪声敏感性,强烈建议获取具有区分性和良好的描述符。
- 属性:
- 描述符 : (Q, 描述符大小) 的布尔型数组(问题,
过滤掉边界关键点后,大小为 descriptor_size 的 Q 个关键点的二进制描述符的 2D ndarray,索引
(i, j)处的值为True或False,表示第 i 个关键点在第 j 个决策像素对上的强度比较结果。即Q == np.sum(mask)。- 掩码(N,) 类型的布尔数组
指示关键点是否已被过滤掉 (
False) 或是在 descriptors 数组中被描述 (True) 的掩码。
示例
>>> from skimage.feature import (corner_harris, corner_peaks, BRIEF, ... match_descriptors) >>> import numpy as np >>> square1 = np.zeros((8, 8), dtype=np.int32) >>> square1[2:6, 2:6] = 1 >>> square1 array([[0, 0, 0, 0, 0, 0, 0, 0], [0, 0, 0, 0, 0, 0, 0, 0], [0, 0, 1, 1, 1, 1, 0, 0], [0, 0, 1, 1, 1, 1, 0, 0], [0, 0, 1, 1, 1, 1, 0, 0], [0, 0, 1, 1, 1, 1, 0, 0], [0, 0, 0, 0, 0, 0, 0, 0], [0, 0, 0, 0, 0, 0, 0, 0]], dtype=int32) >>> square2 = np.zeros((9, 9), dtype=np.int32) >>> square2[2:7, 2:7] = 1 >>> square2 array([[0, 0, 0, 0, 0, 0, 0, 0, 0], [0, 0, 0, 0, 0, 0, 0, 0, 0], [0, 0, 1, 1, 1, 1, 1, 0, 0], [0, 0, 1, 1, 1, 1, 1, 0, 0], [0, 0, 1, 1, 1, 1, 1, 0, 0], [0, 0, 1, 1, 1, 1, 1, 0, 0], [0, 0, 1, 1, 1, 1, 1, 0, 0], [0, 0, 0, 0, 0, 0, 0, 0, 0], [0, 0, 0, 0, 0, 0, 0, 0, 0]], dtype=int32) >>> keypoints1 = corner_peaks(corner_harris(square1), min_distance=1) >>> keypoints2 = corner_peaks(corner_harris(square2), min_distance=1) >>> extractor = BRIEF(patch_size=5) >>> extractor.extract(square1, keypoints1) >>> descriptors1 = extractor.descriptors >>> extractor.extract(square2, keypoints2) >>> descriptors2 = extractor.descriptors >>> matches = match_descriptors(descriptors1, descriptors2) >>> matches array([[0, 0], [1, 1], [2, 2], [3, 3]]) >>> keypoints1[matches[:, 0]] array([[2, 2], [2, 5], [5, 2], [5, 5]]) >>> keypoints2[matches[:, 1]] array([[2, 2], [2, 6], [6, 2], [6, 6]])
- class skimage.feature.CENSURE(min_scale=1, max_scale=7, mode='DoB', non_max_threshold=0.15, line_threshold=10)[源代码][源代码]#
基类:
FeatureDetectorCENSURE 关键点检测器。
- min_scaleint, 可选
提取关键点的最小尺度。
- max_scaleint, 可选
提取关键点的最大比例。关键点将从所有比例中提取,除了第一个和最后一个,即从范围 [min_scale + 1, max_scale - 1] 内的比例中提取。不同比例的滤波器大小使得两个相邻比例构成一个八度。
- 模式{‘出生日期’, ‘八角形’, ‘星形’}, 可选
用于获取输入图像尺度的双层滤波器类型。可能的值有 ‘DoB’、’Octagon’ 和 ‘STAR’。这三种模式分别代表双层滤波器的形状,即方框(正方形)、八边形和星形。例如,双层八边形滤波器由一个较小的内八边形和一个较大的外八边形组成,滤波器权重在内八边形中均匀为负,在差异区域中均匀为正。使用 STAR 和 Octagon 以获得更好的特征,使用 DoB 以获得更好的性能。
- 非最大值阈值float, 可选
用于抑制在非极大值抑制后获得的弱幅度响应的极大值和极小值的阈值。
- line_thresholdfloat, 可选
拒绝主曲率比大于此值的兴趣点的阈值。
- 属性:
- 要点(N, 2) 数组
关键点坐标为
(行, 列)。- 刻度(N,) 数组
对应的刻度。
参考文献
[1]Motilal Agrawal, Kurt Konolige 和 Morten Rufus Blas 的 “CENSURE: 用于实时特征检测和匹配的中心环绕极值”,https://link.springer.com/chapter/10.1007/978-3-540-88693-8_8 DOI:10.1007/978-3-540-88693-8_8
[2]Adam Schmidt, Marek Kraft, Michal Fularz 和 Zuzanna Domagala 的 “机器人导航中点特征检测器和描述符的比较评估” http://yadda.icm.edu.pl/yadda/element/bwmeta1.element.baztech-268aaf28-0faf-4872-a4df-7e2e61cb364c/c/Schmidt_comparative.pdf DOI:10.1.1.465.1117
示例
>>> from skimage.data import astronaut >>> from skimage.color import rgb2gray >>> from skimage.feature import CENSURE >>> img = rgb2gray(astronaut()[100:300, 100:300]) >>> censure = CENSURE() >>> censure.detect(img) >>> censure.keypoints array([[ 4, 148], [ 12, 73], [ 21, 176], [ 91, 22], [ 93, 56], [ 94, 22], [ 95, 54], [100, 51], [103, 51], [106, 67], [108, 15], [117, 20], [122, 60], [125, 37], [129, 37], [133, 76], [145, 44], [146, 94], [150, 114], [153, 33], [154, 156], [155, 151], [184, 63]]) >>> censure.scales array([2, 6, 6, 2, 4, 3, 2, 3, 2, 6, 3, 2, 2, 3, 2, 2, 2, 3, 2, 2, 4, 2, 2])

- class skimage.feature.Cascade#
基类:
object用于对象检测的级联分类器类。
级联分类器背后的主要思想是创建中等精度的分类器,并将它们集成到一个强分类器中,而不是仅仅创建一个强分类器。级联分类器的第二个优点是,可以通过仅评估级联中的部分分类器来分类简单的例子,这使得整个过程比评估一个强分类器的过程快得多。
- 属性:
- epscnp.float32_t
准确性参数。增加它,会使分类器检测到更少的误报,但同时误报率也会增加。
- stages_numberPy_ssize_t
级联中的阶段数量。每个级联由树桩组成,即训练后的特征。
- stumps_numberPy_ssize_t
级联所有阶段中树桩的总体数量。
- features_numberPy_ssize_t
级联使用的不同特征的总体数量。两个树桩可以使用相同的特征,但具有不同的训练值。
- window_widthPy_ssize_t
使用的检测窗口的宽度。小于此窗口的物体无法被检测到。
- window_heightPy_ssize_t
检测窗口的高度。
- 阶段阶段*
指向使用 Stage 结构体存储阶段信息的 C 数组的指针。
- 功能MBLBP*
指向使用 MBLBP 结构存储 MBLBP 特征的 C 数组的指针。
- LUTscnp.uint32_t*
指向C数组的指针,该数组包含训练后的MBLBP特征(MBLBPStumps)用于评估特定区域所使用的查找表。
注释
级联方法首先由 Viola 和 Jones 描述 [1],[2],尽管这些最初的出版物使用了一组类 Haar 特征。这个实现则使用了多尺度块局部二值模式 (MB-LBP) 特征 [3]。
参考文献
[1]Viola, P. 和 Jones, M. “使用增强的简单特征级联进行快速目标检测”,载于:2001年IEEE计算机学会计算机视觉与模式识别会议论文集。CVPR 2001,第I-I页。DOI:10.1109/CVPR.2001.990517
[2]Viola, P. 和 Jones, M.J, “鲁棒实时人脸检测”, 国际计算机视觉杂志 57, 137–154 (2004). DOI:10.1023/B:VISI.0000013087.49260.fb
[3]Liao, S. 等。学习多尺度块局部二值模式用于人脸识别。国际生物识别会议 (ICB),2007,第828-837页。见:计算机科学讲义,第4642卷。Springer, 柏林, 海德堡。DOI:10.1007/978-3-540-74549-5_87
- __init__()#
初始化级联分类器。
- 参数:
- xml_file文件的路径或文件的对象
一个OpenCv格式的文件,从中加载所有级联分类器的参数。
- epscnp.float32_t
准确性参数。增加它,会使分类器检测到更少的误报,但同时误报率也会增加。
- detect_multi_scale(img, scale_factor, step_ratio, min_size, max_size, min_neighbor_number=4, intersection_score_threshold=0.5)#
在输入图像的多个尺度上搜索对象。
该函数接收输入图像、搜索窗口在每一步被乘以的比例因子、指定应用于输入图像以检测对象的搜索窗口区间的最小窗口大小和最大窗口大小。
- 参数:
- img2-D 或 3-D ndarray
表示输入图像的 Ndarray。
- scale_factorcnp.float32_t
搜索窗口在每一步被乘以的比例。
- step_ratiocnp.float32_t
每次图像缩放时搜索步长乘以的比例。1 表示穷举搜索,通常速度较慢。通过将此参数设置为更高的值,结果会更差,但计算速度会快得多。通常,区间 [1, 1.5] 内的值能给出良好的结果。
- min_sizetuple (int, int)
搜索窗口的最小尺寸。
- max_sizetuple (int, int)
搜索窗口的最大尺寸。
- min_neighbor_number整数
为了使检测被函数批准,所需的最小交集检测数量。
- intersection_score_thresholdcnp.float32_t
合并两个检测结果为一个的最小比值(交集面积)/(小矩形比值)。
- 返回:
- 输出字典列表
字典的形式为 {‘r’: int, ‘c’: int, ‘width’: int, ‘height’: int},其中 ‘r’ 表示检测窗口左上角的行位置,’c’ 表示列位置,’width’ 表示检测窗口的宽度,’height’ 表示检测窗口的高度。
- eps#
!! 由 numpydoc 处理 !!
- features_number#
!! 由 numpydoc 处理 !!
- stages_number#
!! 由 numpydoc 处理 !!
- stumps_number#
!! 由 numpydoc 处理 !!
- window_height#
!! 由 numpydoc 处理 !!
- window_width#
!! 由 numpydoc 处理 !!

- class skimage.feature.ORB(downscale=1.2, n_scales=8, n_keypoints=500, fast_n=9, fast_threshold=0.08, harris_k=0.04)[源代码][源代码]#
基类:
FeatureDetector,DescriptorExtractor面向FAST和旋转BRIEF特征检测器及二进制描述符提取器。
- 参数:
- n_keypointsint, 可选
要返回的关键点数量。如果检测到的关键点数量超过 n_keypoints,函数将根据 Harris 角点响应返回最佳的 n_keypoints。如果没有,则返回所有检测到的关键点。
- fast_nint, 可选
skimage.feature.corner_fast中的 n 参数。在圆上的16个像素中,至少有连续的 n 个像素应该相对于测试像素要么更亮要么更暗。如果圆上的点 c 相对于测试像素 p 更暗,则满足Ic < Ip - threshold,如果更亮则满足Ic > Ip + threshold。这也代表了FAST-n角点检测器中的 n。- fast_thresholdfloat, 可选
feature.corner_fast中的threshold参数。用于决定圆上的像素相对于测试像素是更亮、更暗还是相似的阈值。当需要更多角点时降低阈值,反之亦然。- harris_kfloat, 可选
skimage.feature.corner_harris中的 k 参数。用于区分角点和边缘的敏感因子,通常在范围[0, 0.2]内。k 值较小时,会检测到尖锐的角点。- 缩小float, 可选
图像金字塔的降采样因子。默认值1.2被选择,以便有更多的密集尺度,从而为后续的特征描述提供更强的尺度不变性。
- n_scalesint, 可选
从图像金字塔底部提取特征的最大尺度数。
- 属性:
- 要点(N, 2) 数组
关键点坐标为
(行, 列)。- 刻度(N,) 数组
对应的刻度。
- 方向(N,) 数组
对应的弧度方向。
- 响应(N,) 数组
对应的Harris角点响应。
- 描述符 : (Q, 描述符大小) 的布尔型数组(问题,
大小为 descriptor_size 的二进制描述符的二维数组,用于过滤掉边界关键点后的 Q 个关键点,索引
(i, j)处的值为True或False,表示第 i 个关键点在第 j 个决策像素对上的强度比较结果。即Q == np.sum(mask)。
参考文献
[1]Ethan Rublee, Vincent Rabaud, Kurt Konolige 和 Gary Bradski 的论文 “ORB: SIFT 和 SURF 的高效替代方案” http://www.vision.cs.chubu.ac.jp/CV-R/pdf/Rublee_iccv2011.pdf
示例
>>> from skimage.feature import ORB, match_descriptors >>> img1 = np.zeros((100, 100)) >>> img2 = np.zeros_like(img1) >>> rng = np.random.default_rng(19481137) # do not copy this value >>> square = rng.random((20, 20)) >>> img1[40:60, 40:60] = square >>> img2[53:73, 53:73] = square >>> detector_extractor1 = ORB(n_keypoints=5) >>> detector_extractor2 = ORB(n_keypoints=5) >>> detector_extractor1.detect_and_extract(img1) >>> detector_extractor2.detect_and_extract(img2) >>> matches = match_descriptors(detector_extractor1.descriptors, ... detector_extractor2.descriptors) >>> matches array([[0, 0], [1, 1], [2, 2], [3, 4], [4, 3]]) >>> detector_extractor1.keypoints[matches[:, 0]] array([[59. , 59. ], [40. , 40. ], [57. , 40. ], [46. , 58. ], [58.8, 58.8]]) >>> detector_extractor2.keypoints[matches[:, 1]] array([[72., 72.], [53., 53.], [70., 53.], [59., 71.], [72., 72.]])
- __init__(downscale=1.2, n_scales=8, n_keypoints=500, fast_n=9, fast_threshold=0.08, harris_k=0.04)[源代码][源代码]#
- class skimage.feature.SIFT(upsampling=2, n_octaves=8, n_scales=3, sigma_min=1.6, sigma_in=0.5, c_dog=0.013333333333333334, c_edge=10, n_bins=36, lambda_ori=1.5, c_max=0.8, lambda_descr=6, n_hist=4, n_ori=8)[源代码][源代码]#
基类:
FeatureDetector,DescriptorExtractorSIFT 特征检测和描述符提取。
- 参数:
- 上采样int, 可选
在进行特征检测之前,图像会按1(无放大)、2或4的倍数进行放大。方法:双三次插值。
- n_octavesint, 可选
最大八度数。每增加一个八度,图像大小减半,sigma 加倍。八度数将根据需要减少,以确保在最小的尺度上每个维度至少有12个像素。
- n_scalesint, 可选
每个八度音阶中的最大刻度数。
- sigma_minfloat, 可选
种子图像的模糊级别。如果启用了上采样,sigma_min 会按因子 1/upsampling 进行缩放。
- sigma_infloat, 可选
输入图像的假设模糊程度。
- c_dogfloat, 可选
在DoG中丢弃低对比度极值的阈值。其最终值取决于n_scales,关系为:final_c_dog = (2^(1/n_scales)-1) / (2^(1/3)-1) * c_dog
- c_edgefloat, 可选
丢弃位于边缘的极值的阈值。如果 H 是一个极值的 Hessian 矩阵,其“边缘性”由 tr(H)²/det(H) 描述。如果边缘性高于 (c_edge + 1)²/c_edge,则该极值被丢弃。
- n_binsint, 可选
描述关键点周围梯度方向的直方图中的箱数。
- lambda_orifloat, 可选
用于找到关键点参考方向的窗口宽度为 6 * lambda_ori * sigma,并且由标准差为 2 * lambda_ori * sigma 加权。
- c_maxfloat, 可选
在方向直方图中,次级峰值被接受为方向的阈值
- lambda_descrfloat, 可选
用于定义关键点描述符的窗口宽度为 2 * lambda_descr * sigma * (n_hist+1)/n_hist,并且其权重为 lambda_descr * sigma 的标准差。
- n_histint, 可选
用于定义关键点描述符的窗口由 n_hist * n_hist 个直方图组成。
- n_oriint, 可选
描述符块直方图中的箱数。
- 属性:
- delta_min浮动
第一组八度音阶的采样距离。其最终值为 1/上采样。
- float_dtype类型
图像的数据类型。
- scalespace_sigmas(n_octaves, n_scales + 3) 数组
所有八度音阶中所有音阶的sigma值。
- 要点(N, 2) 数组
关键点坐标为
(行, 列)。- 职位(N, 2) 数组
亚像素精度的关键点坐标,表示为
(行, 列)。- sigmas(N,) 数组
关键点的相应 sigma(模糊)值。
- 刻度(N,) 数组
关键点的相应尺度。
- 方向(N,) 数组
每个关键点周围的梯度方向。
- 八度音阶(N,) 数组
关键点对应的八度。
- 描述符(N, n_hist*n_hist*n_ori) 数组
关键点的描述符。
注释
SIFT算法由David Lowe [1],[2] 开发,后来由英属哥伦比亚大学获得专利。由于该专利在2020年到期,因此可以免费使用。这里的实现紧密遵循 [3] 中的详细描述,包括使用相同的默认参数。
参考文献
[1]D.G. Lowe. “基于局部尺度不变特征的对象识别”, 第七届IEEE国际计算机视觉会议论文集, 1999年, 第2卷, 第1150-1157页. DOI:10.1109/ICCV.1999.790410
[2]D.G. Lowe. “基于尺度不变关键点的独特图像特征”, 国际计算机视觉杂志, 2004年, 第60卷, 第91–110页. DOI:10.1023/B:VISI.0000029664.99615.94
[3]I. R. Otero and M. Delbracio. “Anatomy of the SIFT Method”, Image Processing On Line, 4 (2014), pp. 370–396. DOI:10.5201/ipol.2014.82
示例
>>> from skimage.feature import SIFT, match_descriptors >>> from skimage.data import camera >>> from skimage.transform import rotate >>> img1 = camera() >>> img2 = rotate(camera(), 90) >>> detector_extractor1 = SIFT() >>> detector_extractor2 = SIFT() >>> detector_extractor1.detect_and_extract(img1) >>> detector_extractor2.detect_and_extract(img2) >>> matches = match_descriptors(detector_extractor1.descriptors, ... detector_extractor2.descriptors, ... max_ratio=0.6) >>> matches[10:15] array([[ 10, 412], [ 11, 417], [ 12, 407], [ 13, 411], [ 14, 406]]) >>> detector_extractor1.keypoints[matches[10:15, 0]] array([[ 95, 214], [ 97, 211], [ 97, 218], [102, 215], [104, 218]]) >>> detector_extractor2.keypoints[matches[10:15, 1]] array([[297, 95], [301, 97], [294, 97], [297, 102], [293, 104]])
- __init__(upsampling=2, n_octaves=8, n_scales=3, sigma_min=1.6, sigma_in=0.5, c_dog=0.013333333333333334, c_edge=10, n_bins=36, lambda_ori=1.5, c_max=0.8, lambda_descr=6, n_hist=4, n_ori=8)[源代码][源代码]#
- property deltas#
所有八度的采样距离