备注
前往末尾 下载完整示例代码。或者通过 Binder 在浏览器中运行此示例。
Fisher 向量特征编码#
Fisher 向量是一种图像特征编码和量化技术,可以看作是流行的视觉词袋或 VLAD 算法的一种软性或概率性版本。图像使用视觉词汇进行建模,该词汇通过在低级图像特征(如 SIFT 或 ORB 描述符)上训练的 K 模式高斯混合模型进行估计。Fisher 向量本身是高斯混合模型(GMM)相对于其参数(混合权重、均值和协方差矩阵)的梯度的串联。
在这个例子中,我们为 scikit-learn 中的数字数据集计算 Fisher 向量,并基于这些表示训练一个分类器。
请注意,运行此示例需要 scikit-learn。
precision recall f1-score support
0 0.81 0.86 0.84 44
1 0.78 0.70 0.74 44
2 0.59 0.64 0.61 47
3 0.65 0.66 0.65 47
4 0.60 0.73 0.66 45
5 0.49 0.53 0.51 47
6 0.74 0.43 0.54 54
7 0.65 0.64 0.65 50
8 0.56 0.57 0.57 40
9 0.35 0.41 0.38 32
accuracy 0.62 450
macro avg 0.62 0.62 0.61 450
weighted avg 0.63 0.62 0.62 450
from matplotlib import pyplot as plt
import numpy as np
from sklearn.datasets import load_digits
from sklearn.metrics import classification_report, ConfusionMatrixDisplay
from sklearn.model_selection import train_test_split
from sklearn.svm import LinearSVC
from skimage.transform import resize
from skimage.feature import fisher_vector, ORB, learn_gmm
data = load_digits()
images = data.images
targets = data.target
# Resize images so that ORB detects interest points for all images
images = np.array([resize(image, (80, 80)) for image in images])
# Compute ORB descriptors for each image
descriptors = []
for image in images:
detector_extractor = ORB(n_keypoints=5, harris_k=0.01)
detector_extractor.detect_and_extract(image)
descriptors.append(detector_extractor.descriptors.astype('float32'))
# Split the data into training and testing subsets
train_descriptors, test_descriptors, train_targets, test_targets = train_test_split(
descriptors, targets
)
# Train a K-mode GMM
k = 16
gmm = learn_gmm(train_descriptors, n_modes=k)
# Compute the Fisher vectors
training_fvs = np.array(
[fisher_vector(descriptor_mat, gmm) for descriptor_mat in train_descriptors]
)
testing_fvs = np.array(
[fisher_vector(descriptor_mat, gmm) for descriptor_mat in test_descriptors]
)
svm = LinearSVC().fit(training_fvs, train_targets)
predictions = svm.predict(testing_fvs)
print(classification_report(test_targets, predictions))
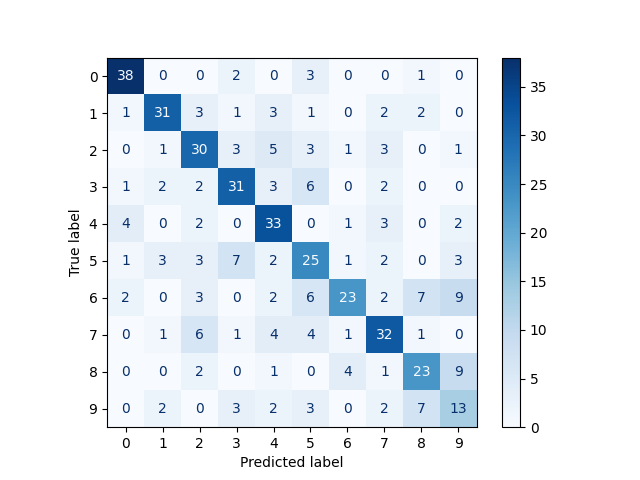
ConfusionMatrixDisplay.from_estimator(
svm,
testing_fvs,
test_targets,
cmap=plt.cm.Blues,
)
plt.show()
脚本总运行时间: (0 分钟 30.792 秒)