4.2. 排列特征重要性#
排列特征重要性是一种模型检查技术,用于衡量每个特征对在给定表格数据集上拟合模型的统计性能的贡献。这种技术对于非线性或不透明的估计器特别有用,它涉及随机打乱单个特征的值并观察模型得分的结果下降[1]_。通过打破特征与目标之间的关系,我们可以确定模型对特定特征的依赖程度。
在以下图中,我们观察到特征排列对特征与目标之间的相关性以及模型统计性能的影响。
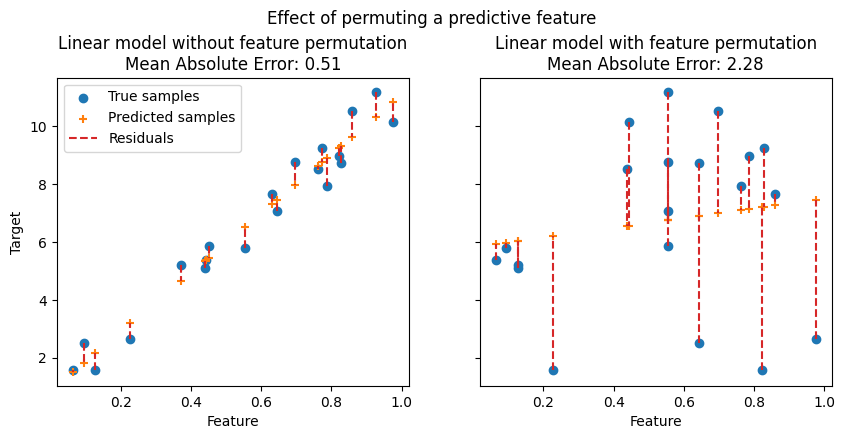
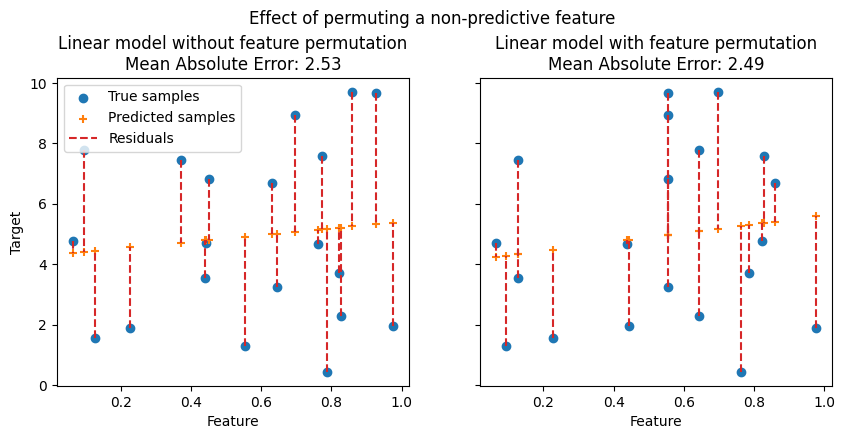
在上图中,我们观察到排列一个预测性特征会打破特征与目标之间的相关性,从而导致模型统计性能下降。在下图中,我们观察到排列一个非预测性特征不会显著降低模型统计性能。
排列特征重要性的一个关键优势是它是模型无关的,即它可以应用于任何拟合的估计器。此外,它可以多次计算,使用特征的不同排列,进一步提供特定训练模型中估计特征重要性的方差度量。
下图显示了在包含 random_cat 和 random_num 特征(即与目标变量无任何相关性的分类和数值特征)的增强版泰坦尼克数据集上训练的 RandomForestClassifier 的排列特征重要性:
.. figure:: ../auto_examples/inspection/images/sphx_glr_plot_permutation_importance_002.png
- target:
../auto_examples/inspection/plot_permutation_importance.html
- align:
center
- scale:
70
Warning
对于一个表现不佳的模型(交叉验证得分低),被认为具有**低重要性**的特征,对于一个表现良好的模型可能是**非常重要**的。因此,在计算重要性之前,始终使用保留集(或更好的交叉验证)评估模型的预测能力是非常重要的。排列重要性并不反映特征本身的内在预测价值,而是**该特征对于特定模型的重要性**。
permutation_importance 函数计算给定数据集的 estimators 的特征重要性。参数 n_repeats 设置特征随机打乱的次数,并返回特征重要性的样本。
让我们考虑以下训练好的回归模型:
>>> from sklearn.datasets import load_diabetes
>>> from sklearn.model_selection import train_test_split
>>> from sklearn.linear_model import Ridge
>>> diabetes = load_diabetes()
>>> X_train, X_val, y_train, y_val = train_test_split(
... diabetes.data, diabetes.target, random_state=0)
...
>>> model = Ridge(alpha=1e-2).fit(X_train, y_train)
>>> model.score(X_val, y_val)
0.356...
其验证性能,通过 \(R^2\) 得分衡量,显著高于随机水平。这使得可以使用 permutation_importance 函数来探究哪些特征最具预测性:
>>> from sklearn.inspection import permutation_importance
>>> r = permutation_importance(model, X_val, y_val,
... n_repeats=30,
... random_state=0)
...
>>> for i in r.importances_mean.argsort()[::-1]:
... if r.importances_mean[i] - 2 * r.importances_std[i] > 0:
... print(f"{diabetes.feature_names[i]:<8}"
... f"{r.importances_mean[i]:.3f}"
... f" +/- {r.importances_std[i]:.3f}")
... print(f"{diabetes.feature_names[i]:<8}"
... f"{r.importances_mean[i]:.3f}"
... f" +/- {r.importances_std[i]:.3f}")
...
s5 0.204 +/- 0.050
bmi 0.176 +/- 0.048
bp 0.088 +/- 0.033
sex 0.056 +/- 0.023
需要注意的是,顶级特征的重要性值代表了参考分数0.356的很大一部分。
排列重要性可以在训练集上或保留的测试集或验证集上计算。使用保留集可以突出哪些特征对被检查模型的泛化能力贡献最大。在训练集上重要但在保留集上不重要的特征可能会导致模型过拟合。
排列特征重要性取决于使用 scoring 参数指定的评分函数。此参数接受多个评分器,这比依次使用不同评分器调用:func:permutation_importance 更高效,因为它重用了模型预测。
#使用多个评分器的排列特征重要性示例
在下面的示例中,我们使用了一个指标列表,但还有更多可能的输入格式,如:ref:multimetric_scoring 文档中所述。
>>> scoring = ['r2', 'neg_mean_absolute_percentage_error', 'neg_mean_squared_error'] >>> r_multi = permutation_importance( ... model, X_val, y_val, n_repeats=30, random_state=0, scoring=scoring) ... >>> for metric in r_multi: ... print(f"{metric}") ... r = r_multi[metric] ... for i in r.importances_mean.argsort()[::-1]: ... if r.importances_mean[i] - 2 * r.importances_std[i] > 0: ... print(f" {diabetes.feature_names[i]:<8}" ... f"{r.importances_mean[i]:.3f}" ... f" +/- {r.importances_std[i]:.3f}") ... r2 s5 0.204 +/- 0.050 bmi 0.176 +/- 0.048bp 0.088 +/- 0.033 sex 0.056 +/- 0.023
- neg_mean_absolute_percentage_error
s5 0.081 +/- 0.020 bmi 0.064 +/- 0.015 bp 0.029 +/- 0.010
- neg_mean_squared_error
s5 1013.866 +/- 246.445 bmi 872.726 +/- 240.298 bp 438.663 +/- 163.022 sex 277.376 +/- 115.123
不同指标下特征的排名大致相同,即使重要性值的尺度差异很大。然而,这并不保证,不同的指标可能导致显著不同的特征重要性,特别是在为不平衡分类问题训练的模型中,分类指标的选择可能至关重要。
4.2.1. 排列重要性算法的概述#
输入:拟合的预测模型 \(m\) ,表格数据集(训练或验证) \(D\) 。
计算模型 \(m\) 在数据 \(D\) 上的参考分数 \(s\) (例如,分类器的准确性或回归器的 \(R^2\) )。
对于每个特征 \(j\) (\(D\) 的列):
对于每次重复 \(k\) 在 \({1, ..., K}\) 中:
随机打乱数据集 \(D\) 的列 \(j\) ,生成一个损坏的数据版本,命名为 \(\tilde{D}_{k,j}\) 。
计算模型 \(m\) 在损坏数据 \(\tilde{D}_{k,j}\) 上的分数 \(s_{k,j}\) 。
计算特征 \(f_j\) 的重要性 \(i_j\) ,定义为:
\[i_j = s - \frac{1}{K} \sum_{k=1}^{K} s_{k,j}\]
4.2.2. 与基于树的杂质重要性的关系#
基于树的模型提供了另一种基于平均杂质减少(MDI)的 特征重要性度量 。杂质通过决策树的分裂准则来量化。 (Gini、对数损失或均方误差)。然而,这种方法在模型过拟合时可能会赋予那些在未见数据上可能不具备预测能力的特征以高重要性。另一方面,基于排列的特征重要性避免了这个问题,因为它可以在未见数据上进行计算。
此外,基于杂质的树特征重要性**存在强烈偏差**,并且**倾向于高基数特征**(通常是数值特征),而不是低基数特征,如二元特征或具有少量可能类别的分类变量。
基于排列的特征重要性不会表现出这种偏差。此外,基于排列的特征重要性可以用任何性能指标在模型预测上进行计算,并且可以用于分析任何模型类别(不仅仅是基于树的模型)。
以下示例突出了基于杂质的特征重要性与基于排列的特征重要性之间的局限性: 置换重要性与随机森林特征重要性(MDI)对比 。
4.2.3. 误导性值在强相关特征上#
当两个特征相关且其中一个特征被排列时,模型仍然可以通过其相关特征访问后者。这导致两个特征的报告重要性值较低,尽管它们**实际上**可能很重要。
下图显示了使用:ref:breast_cancer_dataset 训练的:class:~sklearn.ensemble.RandomForestClassifier 的排列特征重要性,该数据集包含强相关特征。一个天真的解释可能会建议所有特征都不重要:
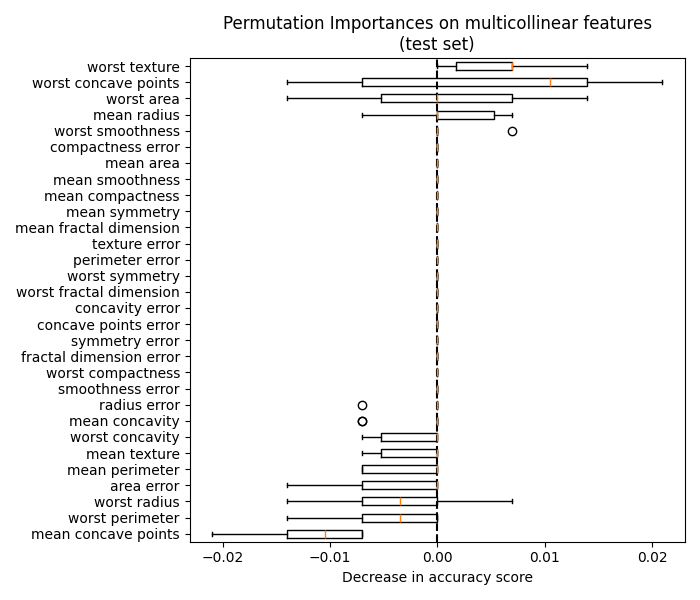
处理这个问题的一种方法是将有相关性的特征进行聚类,并且只 从每个聚类中保留一个特征。
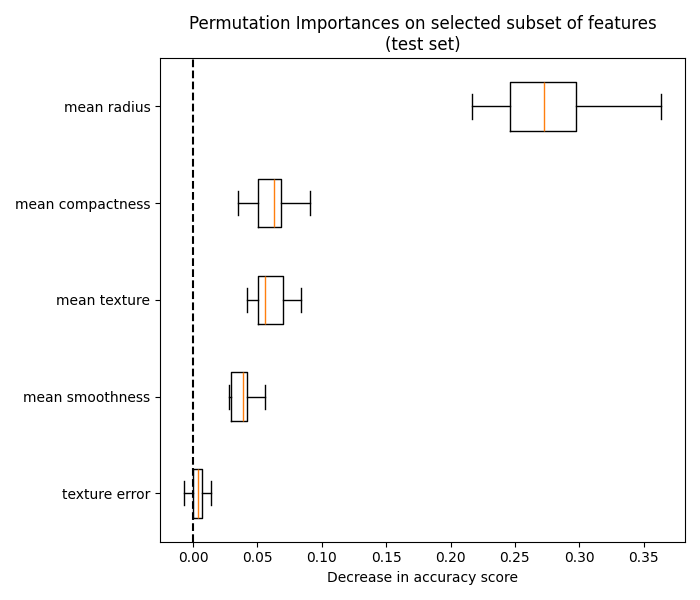
有关此类策略的更多详细信息,请参阅示例 具有多重共线性或相关特征的排列重要性 。
示例
参考文献