8.2. 计算性能#
对于某些应用,估计器的性能(主要是预测时的延迟和吞吐量)至关重要。考虑训练吞吐量也可能是有趣的,但在生产环境中这通常不那么重要(因为训练通常是离线进行的)。
我们将在这里回顾在不同上下文中可以从多个scikit-learn估计器中预期的数量级,并提供一些克服性能瓶颈的技巧和窍门。
预测延迟被测量为进行预测所需的经过时间(例如,以微秒为单位)。延迟通常被视为一个分布,操作工程师经常关注该分布在给定百分位数的延迟(例如,第90百分位数)。
预测吞吐量定义为软件在给定时间内可以提供的预测数量(例如,以每秒预测数为单位)。
性能优化的一个重要方面是它可能会损害预测准确性。确实,更简单的模型(例如,线性而非非线性,或参数更少)通常运行更快,但并不总是能够像更复杂的模型那样考虑数据的相同确切属性。
8.2.1. 预测延迟#
在使用/选择机器学习工具包时,人们可能最直接关注的是在生产环境中进行预测的延迟。
影响预测延迟的主要因素是
特征数量
输入数据表示和稀疏性
模型复杂度
特征提取
最后一个主要参数是进行批量预测或逐个预测的可能性。
8.2.1.1. 批量模式与原子模式#
一般来说,批量进行预测(同时处理多个实例)由于多种原因(分支预测性、CPU缓存、 线性代数库优化等)。在这里,我们看到在一个特征较少的设置中,无论选择哪种估计器,批量模式总是更快,对于其中一些估计器,速度快了1到2个数量级:
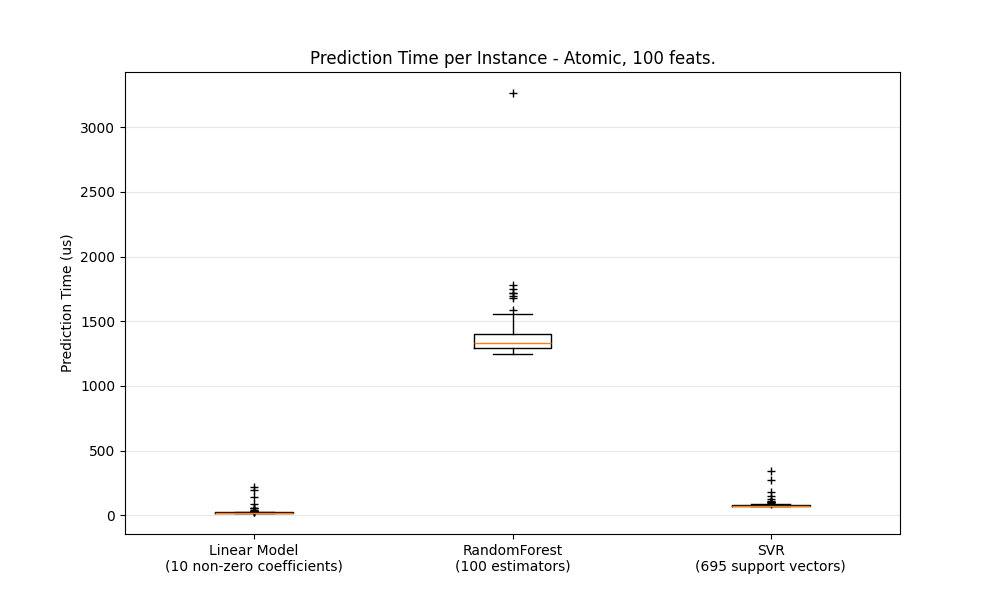
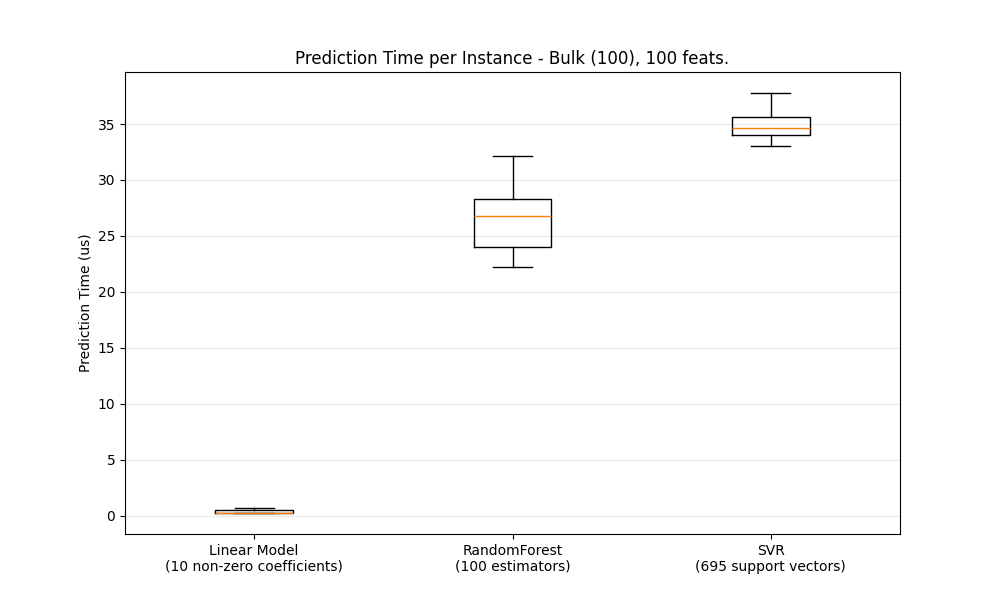
要为您的案例基准测试不同的估计器,您可以简单地更改此示例中的 n_features 参数:
预测延迟 。这将为您提供预测延迟数量级的估计。
8.2.1.2. 配置 Scikit-learn 以减少验证开销#
Scikit-learn 在数据上进行一些验证,增加了每次调用 predict 和类似函数的开销。特别是,检查特征是否有限(不是 NaN 或无限)涉及遍历整个数据。如果您确保您的数据是可接受的,您可以通过在导入 scikit-learn 之前将环境变量 SKLEARN_ASSUME_FINITE 设置为非空字符串,或者在 Python 中使用 set_config 来配置它,从而抑制对有限性的检查。除了这些全局设置之外, config_context 允许您在指定上下文中设置此配置:
>>> import sklearn
>>> with sklearn.config_context(assume_finite=True):
... pass # 在此处进行学习/预测,减少验证
请注意,这会影响上下文中所有使用 assert_all_finite 的情况。
8.2.1.3. 特征数量的影响#
显然,当特征数量增加时,每个示例的内存消耗也会增加。确实,对于一个包含 \(M\) 个实例和 \(N\) 个特征的矩阵,空间复杂度为 \(O(NM)\) 。从计算角度来看,这也意味着基本操作的数量(例如,线性模型中向量-矩阵乘积的乘法)也会增加。以下是预测延迟随特征数量变化的图表:
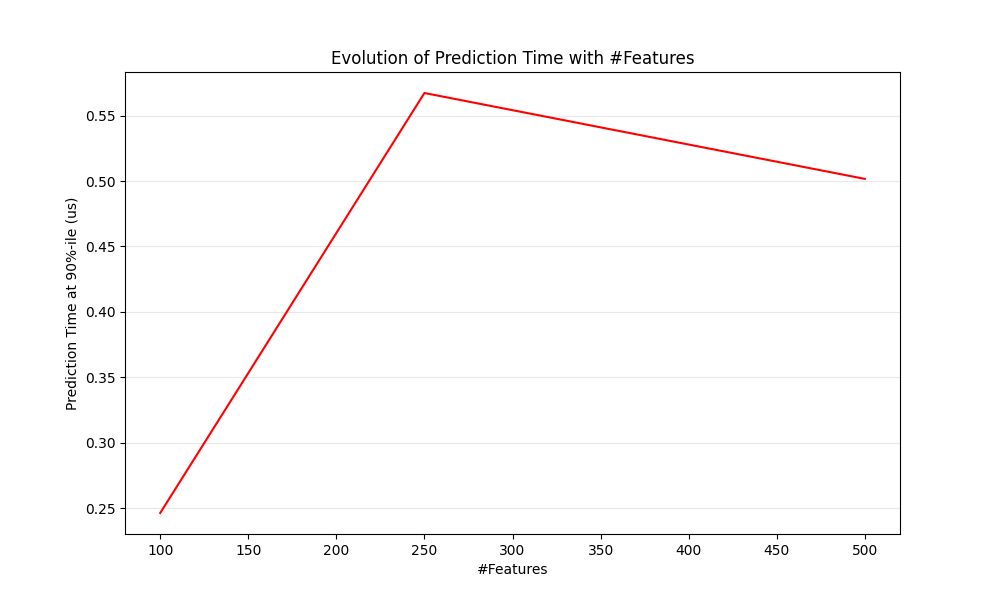
总体而言,您可以预期预测时间至少会随特征数量的增加而线性增长(非线性情况可能取决于全局内存占用和估计器)。
8.2.1.4. 输入数据表示的影响#
Scipy 提供了稀疏矩阵数据结构,这些结构针对存储稀疏数据进行了优化。稀疏格式的最主要特点是您不存储零值,因此如果您的数据是稀疏的,那么您将使用更少的内存。在稀疏( CSR 或 CSC )表示中,非零值平均只占用一个 32 位整数位置 + 64 位浮点值 + 矩阵中每行或每列的额外 32 位。在密集(或稀疏)线性模型中使用稀疏输入可以显著加快预测速度,因为只有非零值特征会影响点积,从而影响模型预测。因此,如果您在 1e6 维空间中有 100 个非零值,您只需要 100 次乘法和加法操作,而不是 1e6 次。
然而,在密集表示上的计算可能会利用 BLAS 中高度优化的向量操作和多线程,并且往往会导致较少的 CPU 缓存未命中。因此,稀疏度通常应该相当高(最大10%的非零值,具体取决于硬件),以便在具有多个CPU和优化BLAS实现的机器上,稀疏输入表示比密集输入表示更快。
以下是测试输入稀疏度的示例代码:
def sparsity_ratio(X):
return 1.0 - np.count_nonzero(X) / float(X.shape[0] * X.shape[1])
print("输入稀疏度比率:", sparsity_ratio(X))
根据经验法则,如果稀疏度比率大于90%,您可能会从稀疏格式中受益。有关如何构建(或将数据转换为)稀疏矩阵格式的更多信息,请查看Scipy的稀疏矩阵格式 文档 。大多数情况下, CSR 和 CSC 格式效果最佳。
8.2.1.5. 模型复杂度的影响#
一般来说,当模型复杂度增加时,预测能力和延迟预计会增加。增加预测能力通常是有趣的,但对于许多应用,我们最好不要增加太多预测延迟。现在我们将回顾这一想法,针对不同类型的监督模型。
对于:mod:sklearn.linear_model (例如Lasso、ElasticNet、SGDClassifier/Regressor、Ridge & RidgeClassifier、PassiveAggressiveClassifier/Regressor、LinearSVC、LogisticRegression…),预测时应用的决策函数是相同的(点积),因此延迟应该相当。
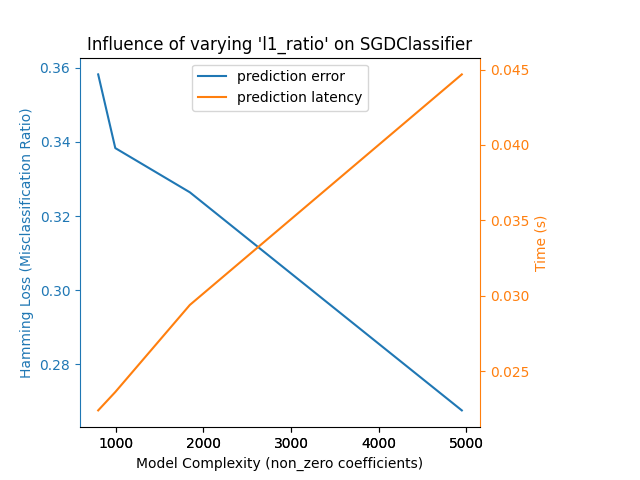
以下是使用:class:~linear_model.SGDClassifier 和 elasticnet 惩罚的示例。正则化强度由 alpha 参数全局控制。通过设置足够高的 alpha ,可以增加 elasticnet 的 l1_ratio 参数,以在模型系数中强制执行不同级别的稀疏性。更高的稀疏性在这里被解释为更低的模型复杂度,因为我们需要的系数更少。
详细描述它。当然,稀疏性反过来也会影响预测时间,因为稀疏点积所需的时间大致与非零系数的数量成正比。
对于具有非线性核的 sklearn.svm 算法族,延迟与支持向量的数量有关(越少越快)。延迟和吞吐量应(渐近地)与 SVC 或 SVR 模型中的支持向量数量线性增长。核函数也会影响延迟,因为它用于每个支持向量计算输入向量的投影。在下图中,使用了 NuSVR 的 nu 参数来影响支持向量的数量。
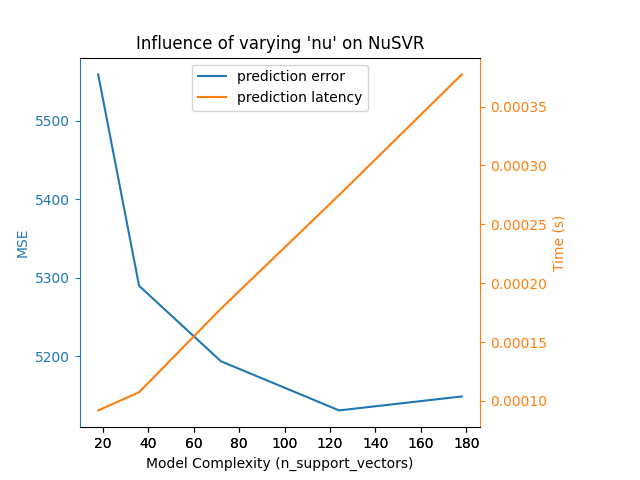
对于 sklearn.ensemble 的树(例如 RandomForest、GBT、ExtraTrees 等),树的数量和深度起着最重要的作用。延迟和吞吐量应与树的数量线性缩放。在这种情况下,我们直接使用了 GradientBoostingRegressor 的 n_estimators 参数。
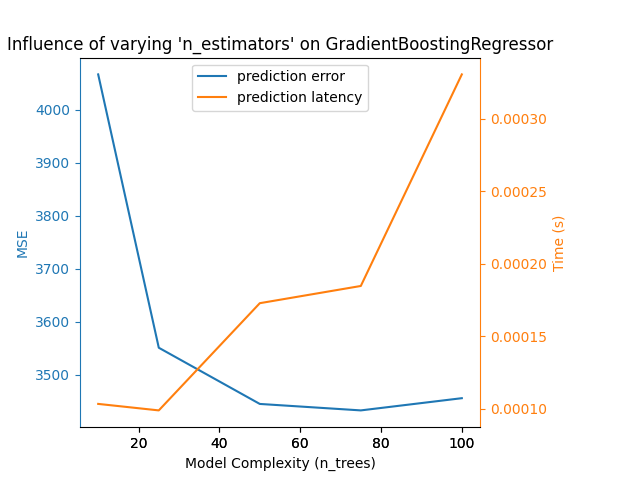
在任何情况下,请注意降低模型复杂度可能会损害准确性,如上所述。例如,非线性可分问题可以通过 使用一个快速的线性模型,但预测能力很可能会在这个过程中受到影响。
8.2.1.6. 特征提取延迟#
大多数scikit-learn模型通常都非常快,因为它们要么是用编译的Cython扩展实现的,要么是使用优化的计算库实现的。另一方面,在许多现实世界的应用中,特征提取过程(即将原始数据如数据库行或网络数据包转换为numpy数组)决定了整体的预测时间。例如,在路透社文本分类任务中,整个准备过程(读取和解析SGML文件,对文本进行分词并将其哈希到公共向量空间)所花费的时间是实际预测代码的100到500倍,具体取决于所选模型。
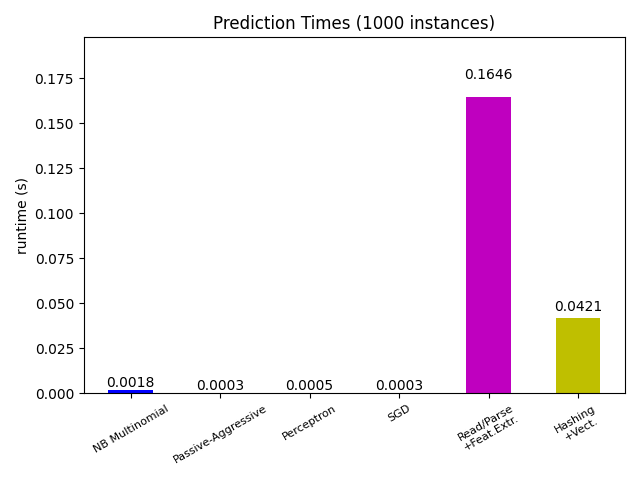
因此,在许多情况下,建议仔细计时和分析您的特征提取代码,因为当您的整体延迟对于您的应用来说太慢时,这可能是一个开始优化的好地方。
8.2.2. 预测吞吐量#
在评估生产系统规模时,另一个重要的指标是吞吐量,即在给定时间内可以进行的预测数量。以下是从:ref:sphx_glr_auto_examples_applications_plot_prediction_latency.py 示例中获取的基准测试,该测试测量了在合成数据上对多个估计器的这一数量:
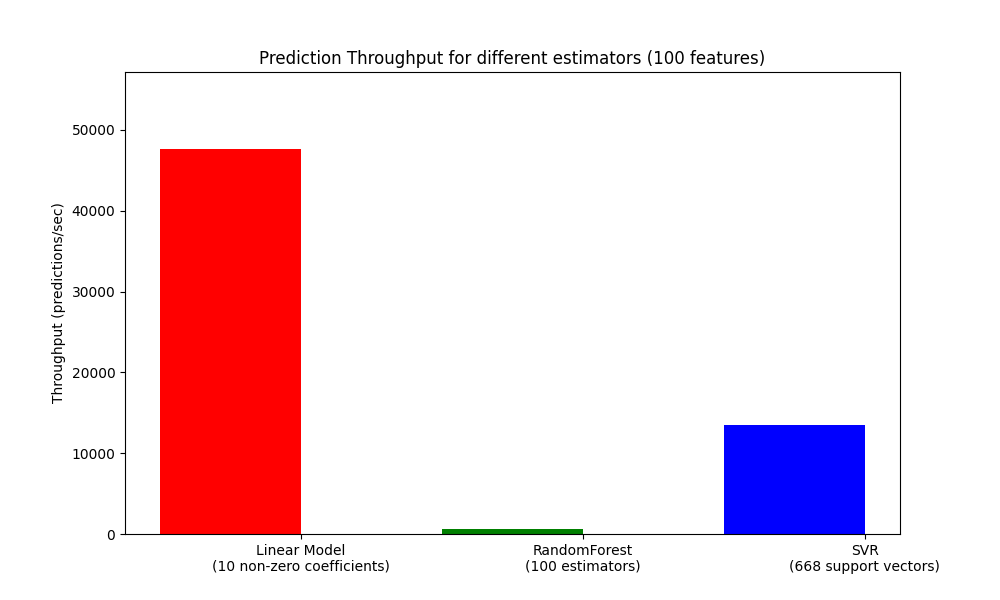
这些吞吐量是在单个进程上实现的。提高应用程序吞吐量的一个明显方法是启动额外的实例。 (通常因为
GIL 而使用 Python 进程) 共享相同的模型。也可以添加机器来分散负载。关于如何实现这一点的详细解释超出了本文档的范围。
8.2.3. 技巧和窍门#
8.2.3.1. 线性代数库#
由于 scikit-learn 严重依赖 Numpy/Scipy 以及一般的线性代数,因此有必要明确关注这些库的版本。基本上,你应该确保 Numpy 是使用优化的 BLAS /
LAPACK 库构建的。
并非所有模型都能从优化的 BLAS 和 Lapack 实现中受益。例如,基于(随机化)决策树的模型通常不依赖于其内部循环中的 BLAS 调用,内核 SVM( SVC 、 SVR 、 NuSVC 、 NuSVR )也是如此。另一方面,通过 BLAS DGEMM 调用(通过 numpy.dot )实现的线性模型通常会从调优的 BLAS 实现中获得巨大收益,并导致比非优化 BLAS 快几个数量级的速度。
你可以使用以下命令显示你的 NumPy / SciPy / scikit-learn 安装使用的 BLAS / LAPACK 实现:
python -c "import sklearn; sklearn.show_versions()"
优化的 BLAS / LAPACK 实现包括:
Atlas(需要通过在目标机器上重新构建来进行硬件特定调优)
OpenBLAS
MKL
Apple Accelerate 和 vecLib 框架(仅限 OSX)
- 更多信息可以在 NumPy 安装页面 和 Daniel Nouri 的这篇
博客文章 中找到,其中包含一些适用于 Debian / Ubuntu 的详细安装步骤。
8.2.3.2. 限制工作内存#
在使用标准numpy向量化操作实现某些计算时,可能会涉及使用大量临时内存。这可能会潜在地耗尽系统内存。在计算可以分块进行的情况下,我们尝试这样做,并允许用户通过 set_config 或:func:config_context 提示最大工作内存大小(默认为1GB)。以下示例建议将临时工作内存限制为128 MiB:
>>> import sklearn
>>> with sklearn.config_context(working_memory=128):
... pass # 在此处进行分块工作
一个遵循此设置的分块操作示例是:func:~metrics.pairwise_distances_chunked ,它有助于计算成对距离矩阵的行级缩减。
8.2.3.3. 模型压缩#
scikit-learn中的模型压缩目前仅涉及线性模型。在这种情况下,它意味着我们希望控制模型稀疏性(即模型向量中非零坐标的数量)。通常,将模型稀疏性与稀疏输入数据表示结合起来是一个好主意。
以下是演示 sparsify() 方法使用的示例代码:
clf = SGDRegressor(penalty='elasticnet', l1_ratio=0.25)
clf.fit(X_train, y_train).sparsify()
clf.predict(X_test)
在这个示例中,我们倾向于使用 elasticnet 惩罚,因为它通常是模型紧凑性和预测能力之间的良好折中。还可以进一步调整 l1_ratio 参数(与正则化强度 alpha 结合)来控制这种权衡。
在合成数据上的典型 基准测试 显示,当模型和输入都稀疏时(非零系数比率分别为0.000024和0.027400),延迟减少了30%以上。根据您的数据和模型的稀疏性和大小,实际效果可能会有所不同。 此外,稀疏化对于减少部署在生产服务器上的预测模型的内存使用非常有用。
8.2.3.4. 模型重塑#
模型重塑包括仅选择可用特征的一部分来拟合模型。换句话说,如果一个模型在学习阶段丢弃了某些特征,我们随后可以从输入中去除这些特征。这有许多好处。首先,它减少了模型本身的内存(因此也是时间)开销。它还允许在知道从前一次运行中保留哪些特征后,丢弃管道中的显式特征选择组件。最后,它可以通过不收集和构建模型丢弃的特征来帮助减少数据访问和特征提取层上游的处理时间和I/O使用。例如,如果原始数据来自数据库,它可以使编写更简单和更快的查询成为可能,或者通过使查询返回更轻的记录来减少I/O使用。目前,在scikit-learn中需要手动进行重塑。对于稀疏输入(特别是在 CSR 格式中),通常不需要生成相关特征,留下它们的列空即可。