Note
Go to the end to download the full example code. or to run this example in your browser via Binder
文本文档的外存分类#
这是一个示例,展示了如何使用scikit-learn进行外存分类:从不适合主存的数据中学习。我们使用一个在线分类器,即支持partial_fit方法的分类器,它将被分批次地喂入示例。为了保证特征空间随时间保持不变,我们利用HashingVectorizer将每个示例投影到相同的特征空间。这在文本分类的情况下特别有用,因为每批次中可能会出现新的特征(单词)。
# 作者:scikit-learn 开发者
# SPDX-License-Identifier: BSD-3-Clause
import itertools
import re
import sys
import tarfile
import time
from hashlib import sha256
from html.parser import HTMLParser
from pathlib import Path
from urllib.request import urlretrieve
import matplotlib.pyplot as plt
import numpy as np
from matplotlib import rcParams
from sklearn.datasets import get_data_home
from sklearn.feature_extraction.text import HashingVectorizer
from sklearn.linear_model import PassiveAggressiveClassifier, Perceptron, SGDClassifier
from sklearn.naive_bayes import MultinomialNB
def _not_in_sphinx():
# 检测我们是否由sphinx构建器运行的黑客方法
return "__file__" in globals()
路透社数据集相关例程#
本示例中使用的数据集是由UCI机器学习库提供的Reuters-21578数据集。首次运行时,它将被自动下载和解压。
class ReutersParser(HTMLParser):
"""实用类,用于解析SGML文件并一次生成一个文档。"""
def __init__(self, encoding="latin-1"):
HTMLParser.__init__(self)
self._reset()
self.encoding = encoding
def handle_starttag(self, tag, attrs):
method = "start_" + tag
getattr(self, method, lambda x: None)(attrs)
def handle_endtag(self, tag):
method = "end_" + tag
getattr(self, method, lambda: None)()
def _reset(self):
self.in_title = 0
self.in_body = 0
self.in_topics = 0
self.in_topic_d = 0
self.title = ""
self.body = ""
self.topics = []
self.topic_d = ""
def parse(self, fd):
self.docs = []
for chunk in fd:
self.feed(chunk.decode(self.encoding))
for doc in self.docs:
yield doc
self.docs = []
self.close()
def handle_data(self, data):
if self.in_body:
self.body += data
elif self.in_title:
self.title += data
elif self.in_topic_d:
self.topic_d += data
def start_reuters(self, attributes):
pass
def end_reuters(self):
self.body = re.sub(r"\s+", r" ", self.body)
self.docs.append(
{"title": self.title, "body": self.body, "topics": self.topics}
)
self._reset()
def start_title(self, attributes):
self.in_title = 1
def end_title(self):
self.in_title = 0
def start_body(self, attributes):
self.in_body = 1
def end_body(self):
self.in_body = 0
def start_topics(self, attributes):
self.in_topics = 1
def end_topics(self):
self.in_topics = 0
def start_d(self, attributes):
self.in_topic_d = 1
def end_d(self):
self.in_topic_d = 0
self.topics.append(self.topic_d)
self.topic_d = ""
def stream_reuters_documents(data_path=None):
"""遍历路透社数据集的文档。
如果 `data_path` 目录不存在,路透社档案将自动下载并解压。
文档表示为包含 'body' (字符串)、'title' (字符串)、'topics' (字符串列表) 键的字典。
"""
DOWNLOAD_URL = (
"http://archive.ics.uci.edu/ml/machine-learning-databases/"
"reuters21578-mld/reuters21578.tar.gz"
)
ARCHIVE_SHA256 = "3bae43c9b14e387f76a61b6d82bf98a4fb5d3ef99ef7e7075ff2ccbcf59f9d30"
ARCHIVE_FILENAME = "reuters21578.tar.gz"
if data_path is None:
data_path = Path(get_data_home()) / "reuters"
else:
data_path = Path(data_path)
if not data_path.exists():
"""Download the dataset."""
print("downloading dataset (once and for all) into %s" % data_path)
data_path.mkdir(parents=True, exist_ok=True)
def progress(blocknum, bs, size):
total_sz_mb = "%.2f MB" % (size / 1e6)
current_sz_mb = "%.2f MB" % ((blocknum * bs) / 1e6)
if _not_in_sphinx():
sys.stdout.write("\rdownloaded %s / %s" % (current_sz_mb, total_sz_mb))
archive_path = data_path / ARCHIVE_FILENAME
urlretrieve(DOWNLOAD_URL, filename=archive_path, reporthook=progress)
if _not_in_sphinx():
sys.stdout.write("\r")
# 检查存档是否被篡改:
assert sha256(archive_path.read_bytes()).hexdigest() == ARCHIVE_SHA256
print("untarring Reuters dataset...")
with tarfile.open(archive_path, "r:gz") as fp:
fp.extractall(data_path, filter="data")
print("done.")
parser = ReutersParser()
for filename in data_path.glob("*.sgm"):
for doc in parser.parse(open(filename, "rb")):
yield doc
Main#
创建向量化器并将特征数量限制在一个合理的最大值
vectorizer = HashingVectorizer(
decode_error="ignore", n_features=2**18, alternate_sign=False
)
# 迭代器遍历解析后的路透社SGML文件。
data_stream = stream_reuters_documents()
# 我们学习“acq”类与所有其他类之间的二元分类。
# 选择“acq”是因为它在路透社文件中分布相对均匀。对于其他数据集,应注意创建一个具有现实比例的正实例的测试集。
all_classes = np.array([0, 1])
positive_class = "acq"
# 以下是一些支持 `partial_fit` 方法的分类器
partial_fit_classifiers = {
"SGD": SGDClassifier(max_iter=5),
"Perceptron": Perceptron(),
"NB Multinomial": MultinomialNB(alpha=0.01),
"Passive-Aggressive": PassiveAggressiveClassifier(),
}
def get_minibatch(doc_iter, size, pos_class=positive_class):
"""提取一个小批量的示例,返回一个元组 X_text 和 y。
注意:大小是在排除没有分配主题的无效文档之前的。
"""
data = [
("{title}\n\n{body}".format(**doc), pos_class in doc["topics"])
for doc in itertools.islice(doc_iter, size)
if doc["topics"]
]
if not len(data):
return np.asarray([], dtype=int), np.asarray([], dtype=int)
X_text, y = zip(*data)
return X_text, np.asarray(y, dtype=int)
def iter_minibatches(doc_iter, minibatch_size):
"""小批量生成器。"""
X_text, y = get_minibatch(doc_iter, minibatch_size)
while len(X_text):
yield X_text, y
X_text, y = get_minibatch(doc_iter, minibatch_size)
# 测试数据统计
test_stats = {"n_test": 0, "n_test_pos": 0}
# 首先,我们保留一些示例来估计准确性
n_test_documents = 1000
tick = time.time()
X_test_text, y_test = get_minibatch(data_stream, 1000)
parsing_time = time.time() - tick
tick = time.time()
X_test = vectorizer.transform(X_test_text)
vectorizing_time = time.time() - tick
test_stats["n_test"] += len(y_test)
test_stats["n_test_pos"] += sum(y_test)
print("Test set is %d documents (%d positive)" % (len(y_test), sum(y_test)))
def progress(cls_name, stats):
"""报告进度信息,返回一个字符串。"""
duration = time.time() - stats["t0"]
s = "%20s classifier : \t" % cls_name
s += "%(n_train)6d train docs (%(n_train_pos)6d positive) " % stats
s += "%(n_test)6d test docs (%(n_test_pos)6d positive) " % test_stats
s += "accuracy: %(accuracy).3f " % stats
s += "in %.2fs (%5d docs/s)" % (duration, stats["n_train"] / duration)
return s
cls_stats = {}
for cls_name in partial_fit_classifiers:
stats = {
"n_train": 0,
"n_train_pos": 0,
"accuracy": 0.0,
"accuracy_history": [(0, 0)],
"t0": time.time(),
"runtime_history": [(0, 0)],
"total_fit_time": 0.0,
}
cls_stats[cls_name] = stats
get_minibatch(data_stream, n_test_documents)
# 丢弃测试集
# 我们将以1000个文档的小批量数据来喂给分类器;这意味着我们在任何时候内存中最多有1000个文档。文档批次越小,部分拟合方法的相对开销就越大。
minibatch_size = 1000
# 创建一个数据流来解析路透社的SGML文件,并以流的形式迭代文档。
minibatch_iterators = iter_minibatches(data_stream, minibatch_size)
total_vect_time = 0.0
# 主循环:在小批量示例上迭代
for i, (X_train_text, y_train) in enumerate(minibatch_iterators):
tick = time.time()
X_train = vectorizer.transform(X_train_text)
total_vect_time += time.time() - tick
for cls_name, cls in partial_fit_classifiers.items():
tick = time.time()
# 使用当前小批量中的示例更新估计器
cls.partial_fit(X_train, y_train, classes=all_classes)
# 累积测试准确性统计数据
cls_stats[cls_name]["total_fit_time"] += time.time() - tick
cls_stats[cls_name]["n_train"] += X_train.shape[0]
cls_stats[cls_name]["n_train_pos"] += sum(y_train)
tick = time.time()
cls_stats[cls_name]["accuracy"] = cls.score(X_test, y_test)
cls_stats[cls_name]["prediction_time"] = time.time() - tick
acc_history = (cls_stats[cls_name]["accuracy"], cls_stats[cls_name]["n_train"])
cls_stats[cls_name]["accuracy_history"].append(acc_history)
run_history = (
cls_stats[cls_name]["accuracy"],
total_vect_time + cls_stats[cls_name]["total_fit_time"],
)
cls_stats[cls_name]["runtime_history"].append(run_history)
if i % 3 == 0:
print(progress(cls_name, cls_stats[cls_name]))
if i % 3 == 0:
print("\n")
Test set is 982 documents (90 positive)
SGD classifier : 988 train docs ( 122 positive) 982 test docs ( 90 positive) accuracy: 0.848 in 0.42s ( 2366 docs/s)
Perceptron classifier : 988 train docs ( 122 positive) 982 test docs ( 90 positive) accuracy: 0.928 in 0.42s ( 2347 docs/s)
NB Multinomial classifier : 988 train docs ( 122 positive) 982 test docs ( 90 positive) accuracy: 0.910 in 0.43s ( 2275 docs/s)
Passive-Aggressive classifier : 988 train docs ( 122 positive) 982 test docs ( 90 positive) accuracy: 0.933 in 0.44s ( 2256 docs/s)
SGD classifier : 3395 train docs ( 430 positive) 982 test docs ( 90 positive) accuracy: 0.942 in 1.47s ( 2303 docs/s)
Perceptron classifier : 3395 train docs ( 430 positive) 982 test docs ( 90 positive) accuracy: 0.952 in 1.48s ( 2299 docs/s)
NB Multinomial classifier : 3395 train docs ( 430 positive) 982 test docs ( 90 positive) accuracy: 0.916 in 1.49s ( 2281 docs/s)
Passive-Aggressive classifier : 3395 train docs ( 430 positive) 982 test docs ( 90 positive) accuracy: 0.955 in 1.49s ( 2276 docs/s)
SGD classifier : 5734 train docs ( 701 positive) 982 test docs ( 90 positive) accuracy: 0.958 in 2.17s ( 2648 docs/s)
Perceptron classifier : 5734 train docs ( 701 positive) 982 test docs ( 90 positive) accuracy: 0.950 in 2.17s ( 2644 docs/s)
NB Multinomial classifier : 5734 train docs ( 701 positive) 982 test docs ( 90 positive) accuracy: 0.922 in 2.18s ( 2635 docs/s)
Passive-Aggressive classifier : 5734 train docs ( 701 positive) 982 test docs ( 90 positive) accuracy: 0.959 in 2.18s ( 2632 docs/s)
SGD classifier : 8595 train docs ( 1165 positive) 982 test docs ( 90 positive) accuracy: 0.924 in 2.86s ( 3000 docs/s)
Perceptron classifier : 8595 train docs ( 1165 positive) 982 test docs ( 90 positive) accuracy: 0.963 in 2.87s ( 2997 docs/s)
NB Multinomial classifier : 8595 train docs ( 1165 positive) 982 test docs ( 90 positive) accuracy: 0.939 in 2.87s ( 2991 docs/s)
Passive-Aggressive classifier : 8595 train docs ( 1165 positive) 982 test docs ( 90 positive) accuracy: 0.967 in 2.88s ( 2988 docs/s)
SGD classifier : 11538 train docs ( 1571 positive) 982 test docs ( 90 positive) accuracy: 0.958 in 3.54s ( 3258 docs/s)
Perceptron classifier : 11538 train docs ( 1571 positive) 982 test docs ( 90 positive) accuracy: 0.964 in 3.54s ( 3254 docs/s)
NB Multinomial classifier : 11538 train docs ( 1571 positive) 982 test docs ( 90 positive) accuracy: 0.941 in 3.55s ( 3247 docs/s)
Passive-Aggressive classifier : 11538 train docs ( 1571 positive) 982 test docs ( 90 positive) accuracy: 0.961 in 3.55s ( 3245 docs/s)
SGD classifier : 14460 train docs ( 1888 positive) 982 test docs ( 90 positive) accuracy: 0.963 in 4.25s ( 3402 docs/s)
Perceptron classifier : 14460 train docs ( 1888 positive) 982 test docs ( 90 positive) accuracy: 0.968 in 4.25s ( 3401 docs/s)
NB Multinomial classifier : 14460 train docs ( 1888 positive) 982 test docs ( 90 positive) accuracy: 0.943 in 4.26s ( 3396 docs/s)
Passive-Aggressive classifier : 14460 train docs ( 1888 positive) 982 test docs ( 90 positive) accuracy: 0.969 in 4.26s ( 3394 docs/s)
SGD classifier : 17244 train docs ( 2187 positive) 982 test docs ( 90 positive) accuracy: 0.969 in 4.91s ( 3514 docs/s)
Perceptron classifier : 17244 train docs ( 2187 positive) 982 test docs ( 90 positive) accuracy: 0.956 in 4.91s ( 3512 docs/s)
NB Multinomial classifier : 17244 train docs ( 2187 positive) 982 test docs ( 90 positive) accuracy: 0.945 in 4.91s ( 3509 docs/s)
Passive-Aggressive classifier : 17244 train docs ( 2187 positive) 982 test docs ( 90 positive) accuracy: 0.974 in 4.92s ( 3507 docs/s)
绘制结果#
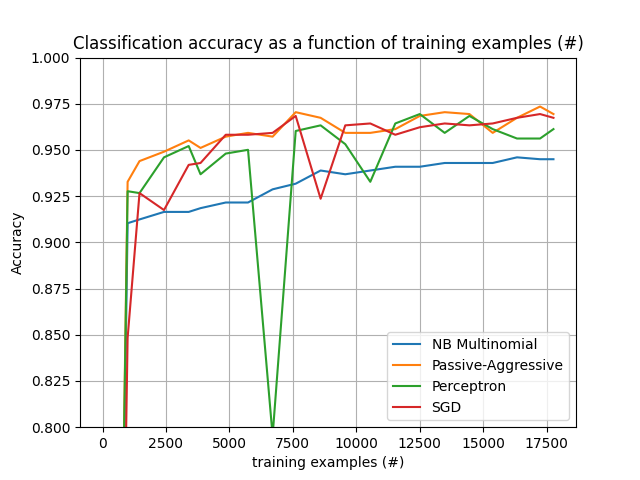
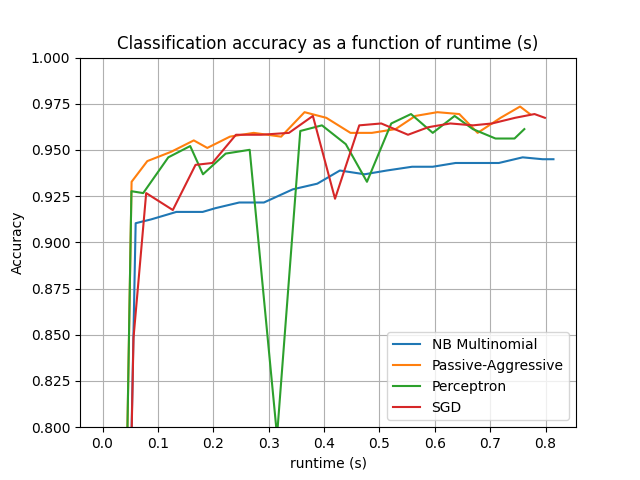
该图展示了分类器的学习曲线:分类准确率在小批量处理过程中的变化。准确率是在前1000个样本上测量的,这些样本被保留作为验证集。
为了限制内存消耗,我们将示例排队到固定数量后再将它们提供给学习器。
def plot_accuracy(x, y, x_legend):
"""绘制准确率随x变化的图。"""
x = np.array(x)
y = np.array(y)
plt.title("Classification accuracy as a function of %s" % x_legend)
plt.xlabel("%s" % x_legend)
plt.ylabel("Accuracy")
plt.grid(True)
plt.plot(x, y)
rcParams["legend.fontsize"] = 10
cls_names = list(sorted(cls_stats.keys()))
# 绘制准确性演变图
#
#
plt.figure()
for _, stats in sorted(cls_stats.items()):
# 绘制准确性随示例变化的图表
accuracy, n_examples = zip(*stats["accuracy_history"])
plot_accuracy(n_examples, accuracy, "training examples (#)")
ax = plt.gca()
ax.set_ylim((0.8, 1))
plt.legend(cls_names, loc="best")
plt.figure()
for _, stats in sorted(cls_stats.items()):
# 绘制运行时间与准确率变化图
accuracy, runtime = zip(*stats["runtime_history"])
plot_accuracy(runtime, accuracy, "runtime (s)")
ax = plt.gca()
ax.set_ylim((0.8, 1))
plt.legend(cls_names, loc="best")
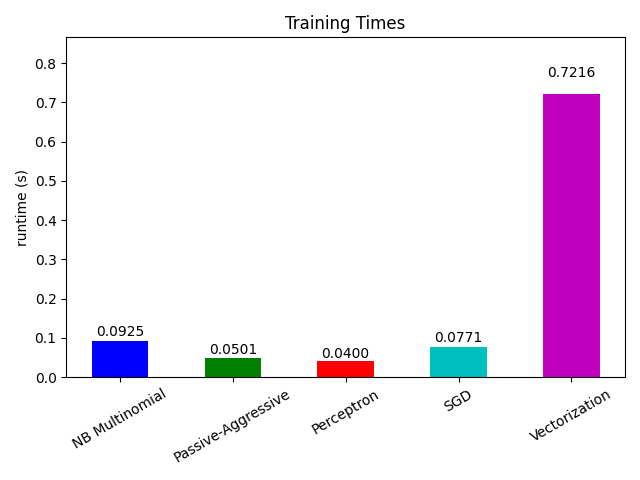
# 绘制拟合时间
plt.figure()
fig = plt.gcf()
cls_runtime = [stats["total_fit_time"] for cls_name, stats in sorted(cls_stats.items())]
cls_runtime.append(total_vect_time)
cls_names.append("Vectorization")
bar_colors = ["b", "g", "r", "c", "m", "y"]
ax = plt.subplot(111)
rectangles = plt.bar(range(len(cls_names)), cls_runtime, width=0.5, color=bar_colors)
ax.set_xticks(np.linspace(0, len(cls_names) - 1, len(cls_names)))
ax.set_xticklabels(cls_names, fontsize=10)
ymax = max(cls_runtime) * 1.2
ax.set_ylim((0, ymax))
ax.set_ylabel("runtime (s)")
ax.set_title("Training Times")
def autolabel(rectangles):
"""在矩形上通过自动标签附加一些文本。"""
for rect in rectangles:
height = rect.get_height()
ax.text(
rect.get_x() + rect.get_width() / 2.0,
1.05 * height,
"%.4f" % height,
ha="center",
va="bottom",
)
plt.setp(plt.xticks()[1], rotation=30)
autolabel(rectangles)
plt.tight_layout()
plt.show()
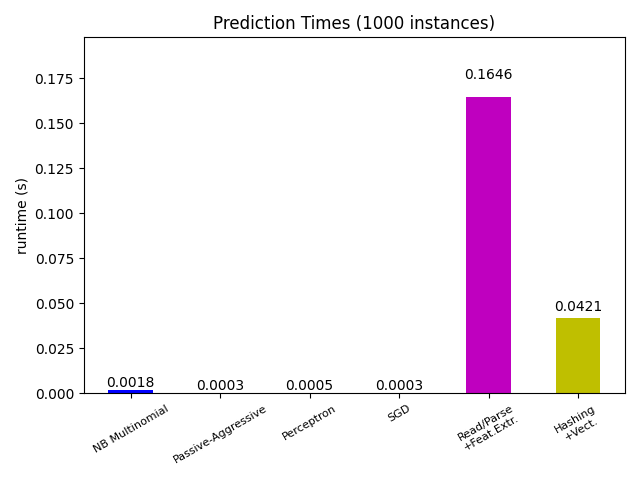
# 绘制预测时间
plt.figure()
cls_runtime = []
cls_names = list(sorted(cls_stats.keys()))
for cls_name, stats in sorted(cls_stats.items()):
cls_runtime.append(stats["prediction_time"])
cls_runtime.append(parsing_time)
cls_names.append("Read/Parse\n+Feat.Extr.")
cls_runtime.append(vectorizing_time)
cls_names.append("Hashing\n+Vect.")
ax = plt.subplot(111)
rectangles = plt.bar(range(len(cls_names)), cls_runtime, width=0.5, color=bar_colors)
ax.set_xticks(np.linspace(0, len(cls_names) - 1, len(cls_names)))
ax.set_xticklabels(cls_names, fontsize=8)
plt.setp(plt.xticks()[1], rotation=30)
ymax = max(cls_runtime) * 1.2
ax.set_ylim((0, ymax))
ax.set_ylabel("runtime (s)")
ax.set_title("Prediction Times (%d instances)" % n_test_documents)
autolabel(rectangles)
plt.tight_layout()
plt.show()
Total running time of the script: (0 minutes 5.493 seconds)
Related examples