Note
Go to the end to download the full example code. or to run this example in your browser via Binder
使用树的森林评估特征重要性#
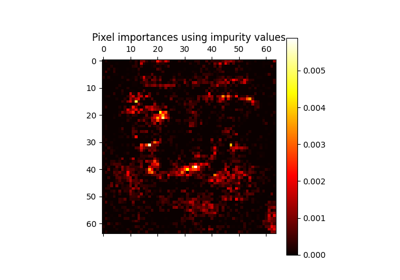
此示例展示了如何使用树的森林来评估在一个人工分类任务中各特征的重要性。蓝色条表示森林中各特征的重要性,误差条则表示各树之间的重要性差异。
如预期所示,图表表明有3个特征是有信息量的,而其余特征则不是。
import matplotlib.pyplot as plt
数据生成和模型拟合#
我们生成一个只有3个信息特征的合成数据集。我们明确不对数据集进行打乱,以确保信息特征对应于X的前三列。此外,我们将把数据集分成训练和测试子集。
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
X, y = make_classification(
n_samples=1000,
n_features=10,
n_informative=3,
n_redundant=0,
n_repeated=0,
n_classes=2,
random_state=0,
shuffle=False,
)
X_train, X_test, y_train, y_test = train_test_split(X, y, stratify=y, random_state=42)
将拟合一个随机森林分类器来计算特征重要性。
from sklearn.ensemble import RandomForestClassifier
feature_names = [f"feature {i}" for i in range(X.shape[1])]
forest = RandomForestClassifier(random_state=0)
forest.fit(X_train, y_train)
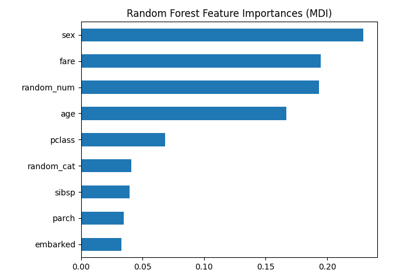
基于平均杂质减少的特征重要性#
特征重要性由拟合属性 feature_importances_ 提供,它们是通过计算每棵树内杂质减少的累积量的均值和标准差得出的。
基于杂质的特征重要性对于 高基数 特征(许多唯一值)可能会产生误导。请参阅下面的 排列特征重要性 作为替代方案。
Elapsed time to compute the importances: 0.003 seconds
让我们绘制基于杂质的重要性。
import pandas as pd
forest_importances = pd.Series(importances, index=feature_names)
fig, ax = plt.subplots()
forest_importances.plot.bar(yerr=std, ax=ax)
ax.set_title("Feature importances using MDI")
ax.set_ylabel("Mean decrease in impurity")
fig.tight_layout()
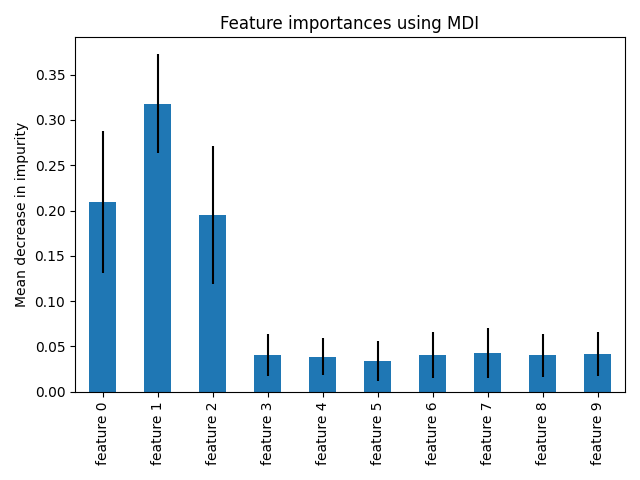
我们观察到,正如预期的那样,前三个特征被认为是重要的。
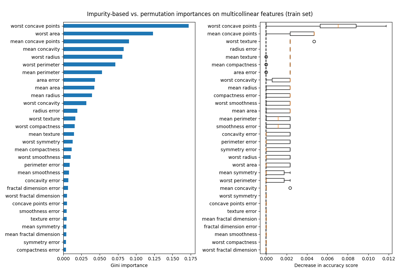
基于特征置换的特征重要性#
置换特征重要性克服了基于不纯度的特征重要性的局限性:它们对高基数特征没有偏向,并且可以在留出的测试集上计算。
from sklearn.inspection import permutation_importance
start_time = time.time()
result = permutation_importance(
forest, X_test, y_test, n_repeats=10, random_state=42, n_jobs=2
)
elapsed_time = time.time() - start_time
print(f"Elapsed time to compute the importances: {elapsed_time:.3f} seconds")
forest_importances = pd.Series(result.importances_mean, index=feature_names)
Elapsed time to compute the importances: 1.332 seconds
完全排列重要性的计算成本更高。特征被打乱n次,并重新拟合模型以估计其重要性。有关更多详细信息,请参见 排列特征重要性 。我们现在可以绘制重要性排名。
fig, ax = plt.subplots()
forest_importances.plot.bar(yerr=result.importances_std, ax=ax)
ax.set_title("Feature importances using permutation on full model")
ax.set_ylabel("Mean accuracy decrease")
fig.tight_layout()
plt.show()
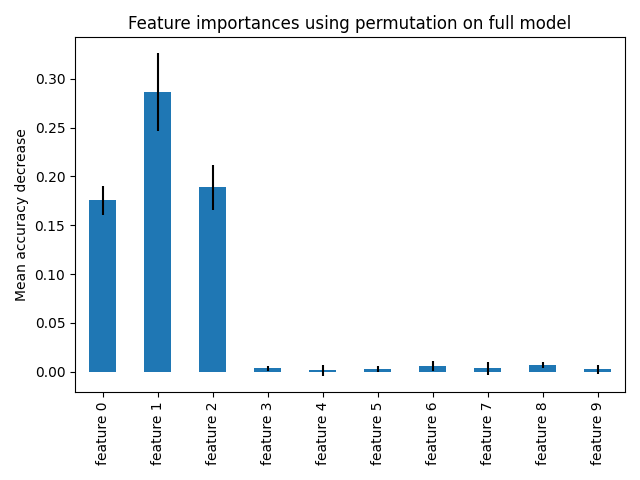
相同的特征在两种方法中都被检测为最重要的特征,尽管相对重要性有所不同。从图中可以看出,MDI比置换重要性更不可能完全忽略某个特征。
Total running time of the script: (0 minutes 1.785 seconds)
Related examples