Note
Go to the end to download the full example code. or to run this example in your browser via Binder
特征离散化#
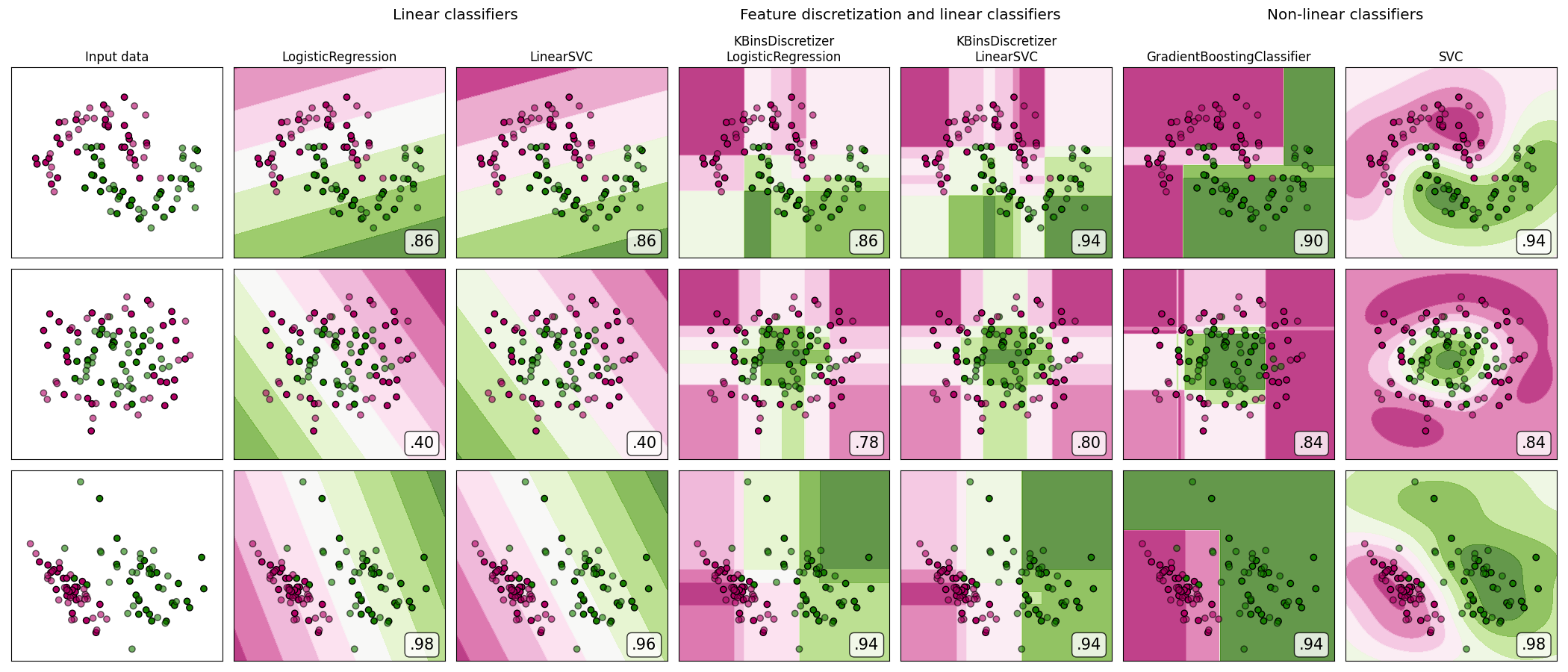
在合成分类数据集上展示特征离散化。特征离散化将每个特征分解为一组等宽分布的区间。然后将离散值进行独热编码,并交给线性分类器。这种预处理使得即使分类器是线性的,也能表现出非线性行为。
在这个例子中,前两行代表线性不可分的数据集(新月形和同心圆),而第三行大致是线性可分的。在两个线性不可分的数据集中,特征离散化大大提高了线性分类器的性能。在线性可分的数据集中,特征离散化降低了线性分类器的性能。还展示了两个非线性分类器以作比较。
这个例子应谨慎对待,因为所传达的直觉不一定适用于真实数据集。特别是在高维空间中,数据更容易线性分离。此外,使用特征离散化和独热编码会增加特征的数量,当样本数量较少时,这很容易导致过拟合。
图中显示了用实色表示的训练点和半透明的测试点。右下角显示了测试集上的分类准确率。
dataset 0
---------
LogisticRegression: 0.86
LinearSVC: 0.86
KBinsDiscretizer + LogisticRegression: 0.86
KBinsDiscretizer + LinearSVC: 0.94
GradientBoostingClassifier: 0.90
SVC: 0.94
dataset 1
---------
LogisticRegression: 0.40
LinearSVC: 0.40
KBinsDiscretizer + LogisticRegression: 0.78
KBinsDiscretizer + LinearSVC: 0.80
GradientBoostingClassifier: 0.84
SVC: 0.84
dataset 2
---------
LogisticRegression: 0.98
LinearSVC: 0.96
KBinsDiscretizer + LogisticRegression: 0.94
KBinsDiscretizer + LinearSVC: 0.94
GradientBoostingClassifier: 0.94
SVC: 0.98
# 代码来源:Tom Dupré la Tour
# 改编自Gaël Varoquaux和Andreas Müller的plot_classifier_comparison
#
# SPDX-License-Identifier: BSD-3-Clause
import matplotlib.pyplot as plt
import numpy as np
from matplotlib.colors import ListedColormap
from sklearn.datasets import make_circles, make_classification, make_moons
from sklearn.ensemble import GradientBoostingClassifier
from sklearn.exceptions import ConvergenceWarning
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import GridSearchCV, train_test_split
from sklearn.pipeline import make_pipeline
from sklearn.preprocessing import KBinsDiscretizer, StandardScaler
from sklearn.svm import SVC, LinearSVC
from sklearn.utils._testing import ignore_warnings
h = 0.02 # step size in the mesh
def get_name(estimator):
name = estimator.__class__.__name__
if name == "Pipeline":
name = [get_name(est[1]) for est in estimator.steps]
name = " + ".join(name)
return name
# (估计器,参数网格)的列表,其中参数网格在 GridSearchCV 中使用。
# 在此示例中,参数空间被限制在一个狭窄的范围内以减少运行时间。在实际使用中,应该为算法使用更广泛的搜索空间。
classifiers = [
(
make_pipeline(StandardScaler(), LogisticRegression(random_state=0)),
{"logisticregression__C": np.logspace(-1, 1, 3)},
),
(
make_pipeline(StandardScaler(), LinearSVC(random_state=0)),
{"linearsvc__C": np.logspace(-1, 1, 3)},
),
(
make_pipeline(
StandardScaler(),
KBinsDiscretizer(encode="onehot", random_state=0),
LogisticRegression(random_state=0),
),
{
"kbinsdiscretizer__n_bins": np.arange(5, 8),
"logisticregression__C": np.logspace(-1, 1, 3),
},
),
(
make_pipeline(
StandardScaler(),
KBinsDiscretizer(encode="onehot", random_state=0),
LinearSVC(random_state=0),
),
{
"kbinsdiscretizer__n_bins": np.arange(5, 8),
"linearsvc__C": np.logspace(-1, 1, 3),
},
),
(
make_pipeline(
StandardScaler(), GradientBoostingClassifier(n_estimators=5, random_state=0)
),
{"gradientboostingclassifier__learning_rate": np.logspace(-2, 0, 5)},
),
(
make_pipeline(StandardScaler(), SVC(random_state=0)),
{"svc__C": np.logspace(-1, 1, 3)},
),
]
names = [get_name(e).replace("StandardScaler + ", "") for e, _ in classifiers]
n_samples = 100
datasets = [
make_moons(n_samples=n_samples, noise=0.2, random_state=0),
make_circles(n_samples=n_samples, noise=0.2, factor=0.5, random_state=1),
make_classification(
n_samples=n_samples,
n_features=2,
n_redundant=0,
n_informative=2,
random_state=2,
n_clusters_per_class=1,
),
]
fig, axes = plt.subplots(
nrows=len(datasets), ncols=len(classifiers) + 1, figsize=(21, 9)
)
cm_piyg = plt.cm.PiYG
cm_bright = ListedColormap(["#b30065", "#178000"])
# 遍历数据集
for ds_cnt, (X, y) in enumerate(datasets):
print(f"\ndataset {ds_cnt}\n---------")
# 划分为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.5, random_state=42
)
# 创建背景颜色网格
x_min, x_max = X[:, 0].min() - 0.5, X[:, 0].max() + 0.5
y_min, y_max = X[:, 1].min() - 0.5, X[:, 1].max() + 0.5
xx, yy = np.meshgrid(np.arange(x_min, x_max, h), np.arange(y_min, y_max, h))
# 绘制数据集首先
ax = axes[ds_cnt, 0]
if ds_cnt == 0:
ax.set_title("Input data")
# 绘制训练点
ax.scatter(X_train[:, 0], X_train[:, 1], c=y_train, cmap=cm_bright, edgecolors="k")
# 和测试点
ax.scatter(
X_test[:, 0], X_test[:, 1], c=y_test, cmap=cm_bright, alpha=0.6, edgecolors="k"
)
ax.set_xlim(xx.min(), xx.max())
ax.set_ylim(yy.min(), yy.max())
ax.set_xticks(())
ax.set_yticks(())
# 遍历分类器
for est_idx, (name, (estimator, param_grid)) in enumerate(zip(names, classifiers)):
ax = axes[ds_cnt, est_idx + 1]
clf = GridSearchCV(estimator=estimator, param_grid=param_grid)
with ignore_warnings(category=ConvergenceWarning):
clf.fit(X_train, y_train)
score = clf.score(X_test, y_test)
print(f"{name}: {score:.2f}")
# 绘制决策边界。为此,我们将为网格 [x_min, x_max]*[y_min, y_max] 中的每个点分配一个颜色。
if hasattr(clf, "decision_function"):
Z = clf.decision_function(np.column_stack([xx.ravel(), yy.ravel()]))
else:
Z = clf.predict_proba(np.column_stack([xx.ravel(), yy.ravel()]))[:, 1]
# 将结果放入彩色图中
Z = Z.reshape(xx.shape)
ax.contourf(xx, yy, Z, cmap=cm_piyg, alpha=0.8)
# 绘制训练点
ax.scatter(
X_train[:, 0], X_train[:, 1], c=y_train, cmap=cm_bright, edgecolors="k"
)
# 和测试点
ax.scatter(
X_test[:, 0],
X_test[:, 1],
c=y_test,
cmap=cm_bright,
edgecolors="k",
alpha=0.6,
)
ax.set_xlim(xx.min(), xx.max())
ax.set_ylim(yy.min(), yy.max())
ax.set_xticks(())
ax.set_yticks(())
if ds_cnt == 0:
ax.set_title(name.replace(" + ", "\n"))
ax.text(
0.95,
0.06,
(f"{score:.2f}").lstrip("0"),
size=15,
bbox=dict(boxstyle="round", alpha=0.8, facecolor="white"),
transform=ax.transAxes,
horizontalalignment="right",
)
plt.tight_layout()
# 在图形上方添加字幕
plt.subplots_adjust(top=0.90)
suptitles = [
"Linear classifiers",
"Feature discretization and linear classifiers",
"Non-linear classifiers",
]
for i, suptitle in zip([1, 3, 5], suptitles):
ax = axes[0, i]
ax.text(
1.05,
1.25,
suptitle,
transform=ax.transAxes,
horizontalalignment="center",
size="x-large",
)
plt.show()
Total running time of the script: (0 minutes 1.506 seconds)
Related examples