Note
Go to the end to download the full example code. or to run this example in your browser via Binder
单变量特征选择#
本笔记本是使用单变量特征选择来提高噪声数据集分类准确性的示例。
在此示例中,一些噪声(无信息)特征被添加到鸢尾花数据集中。支持向量机(SVM)用于在应用单变量特征选择之前和之后对数据集进行分类。对于每个特征,我们绘制单变量特征选择的p值和相应的SVM权重。通过这种方式,我们将比较模型准确性并检查单变量特征选择对模型权重的影响。
生成示例数据#
import numpy as np
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
# The iris dataset
X, y = load_iris(return_X_y=True)
# 一些不相关的噪声数据
E = np.random.RandomState(42).uniform(0, 0.1, size=(X.shape[0], 20))
# 将噪声数据添加到信息特征中
X = np.hstack((X, E))
# 将数据集拆分以选择特征并评估分类器
X_train, X_test, y_train, y_test = train_test_split(X, y, stratify=y, random_state=0)
单变量特征选择#
使用F检验进行单变量特征选择以对特征进行评分。 我们使用默认选择函数选择四个最显著的特征。
from sklearn.feature_selection import SelectKBest, f_classif
selector = SelectKBest(f_classif, k=4)
selector.fit(X_train, y_train)
scores = -np.log10(selector.pvalues_)
scores /= scores.max()
import matplotlib.pyplot as plt
X_indices = np.arange(X.shape[-1])
plt.figure(1)
plt.clf()
plt.bar(X_indices - 0.05, scores, width=0.2)
plt.title("Feature univariate score")
plt.xlabel("Feature number")
plt.ylabel(r"Univariate score ($-Log(p_{value})$)")
plt.show()
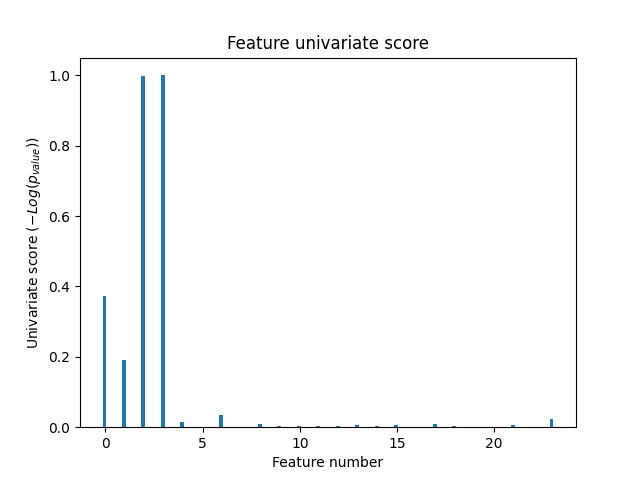
在所有特征中,只有4个原始特征是显著的。我们可以看到它们在单变量特征选择中得分最高。
与支持向量机的比较#
无单变量特征选择
from sklearn.pipeline import make_pipeline
from sklearn.preprocessing import MinMaxScaler
from sklearn.svm import LinearSVC
clf = make_pipeline(MinMaxScaler(), LinearSVC())
clf.fit(X_train, y_train)
print(
"Classification accuracy without selecting features: {:.3f}".format(
clf.score(X_test, y_test)
)
)
svm_weights = np.abs(clf[-1].coef_).sum(axis=0)
svm_weights /= svm_weights.sum()
Classification accuracy without selecting features: 0.789
在单变量特征选择之后
clf_selected = make_pipeline(SelectKBest(f_classif, k=4), MinMaxScaler(), LinearSVC())
clf_selected.fit(X_train, y_train)
print(
"Classification accuracy after univariate feature selection: {:.3f}".format(
clf_selected.score(X_test, y_test)
)
)
svm_weights_selected = np.abs(clf_selected[-1].coef_).sum(axis=0)
svm_weights_selected /= svm_weights_selected.sum()
Classification accuracy after univariate feature selection: 0.868
plt.bar(
X_indices - 0.45, scores, width=0.2, label=r"Univariate score ($-Log(p_{value})$)"
)
plt.bar(X_indices - 0.25, svm_weights, width=0.2, label="SVM weight")
plt.bar(
X_indices[selector.get_support()] - 0.05,
svm_weights_selected,
width=0.2,
label="SVM weights after selection",
)
plt.title("Comparing feature selection")
plt.xlabel("Feature number")
plt.yticks(())
plt.axis("tight")
plt.legend(loc="upper right")
plt.show()
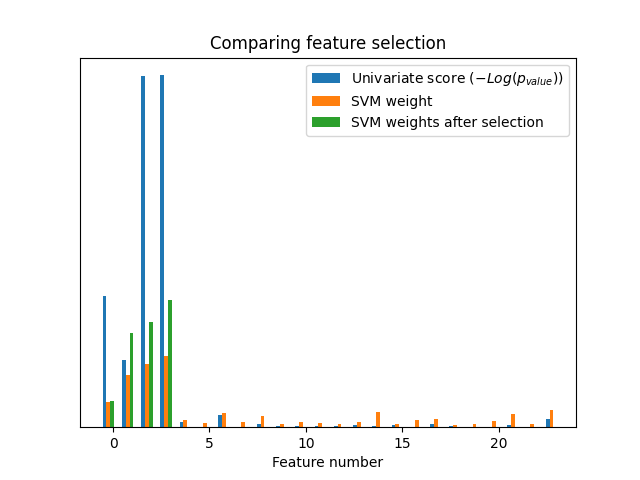
如果不进行单变量特征选择,SVM会给前4个原始显著特征分配较大的权重,但也会选择许多无信息特征。在SVM之前应用单变量特征选择会增加SVM分配给显著特征的权重,从而改进分类效果。
Total running time of the script: (0 minutes 0.087 seconds)
Related examples