Note
Go to the end to download the full example code. or to run this example in your browser via Binder
IsolationForest 示例#
使用 IsolationForest 进行异常检测的示例。
孤立森林 是由“隔离树”组成的集成方法,通过递归随机划分来“隔离”观测值,这可以用树结构表示。隔离一个样本所需的分割次数对于异常值较少,而对于正常值较多。
在本示例中,我们演示了两种可视化在玩具数据集上训练的 Isolation Forest 决策边界的方法。
数据生成#
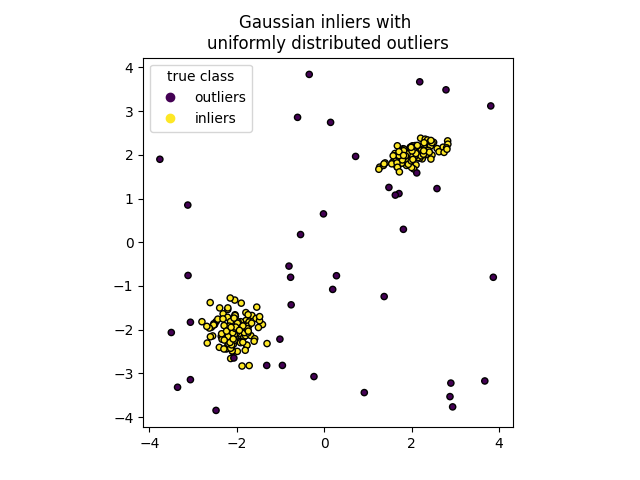
我们通过随机采样标准正态分布(由 numpy.random.randn 返回)生成两个簇(每个簇包含 n_samples )。其中一个是球形的,另一个是稍微变形的。
为了与 IsolationForest 的标注保持一致,内点(即高斯簇)被赋予真实标签 1 ,而离群点(使用 numpy.random.uniform 创建)被赋予标签 -1 。
import numpy as np
from sklearn.model_selection import train_test_split
n_samples, n_outliers = 120, 40
rng = np.random.RandomState(0)
covariance = np.array([[0.5, -0.1], [0.7, 0.4]])
cluster_1 = 0.4 * rng.randn(n_samples, 2) @ covariance + np.array([2, 2]) # general
cluster_2 = 0.3 * rng.randn(n_samples, 2) + np.array([-2, -2]) # spherical
outliers = rng.uniform(low=-4, high=4, size=(n_outliers, 2))
X = np.concatenate([cluster_1, cluster_2, outliers])
y = np.concatenate(
[np.ones((2 * n_samples), dtype=int), -np.ones((n_outliers), dtype=int)]
)
X_train, X_test, y_train, y_test = train_test_split(X, y, stratify=y, random_state=42)
我们可以将结果聚类可视化:
import matplotlib.pyplot as plt
scatter = plt.scatter(X[:, 0], X[:, 1], c=y, s=20, edgecolor="k")
handles, labels = scatter.legend_elements()
plt.axis("square")
plt.legend(handles=handles, labels=["outliers", "inliers"], title="true class")
plt.title("Gaussian inliers with \nuniformly distributed outliers")
plt.show()
模型训练#
from sklearn.ensemble import IsolationForest
clf = IsolationForest(max_samples=100, random_state=0)
clf.fit(X_train)
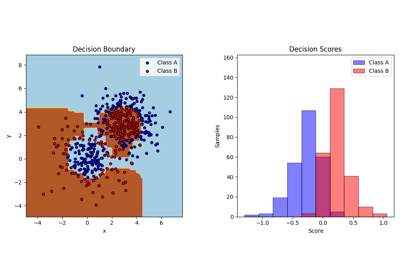
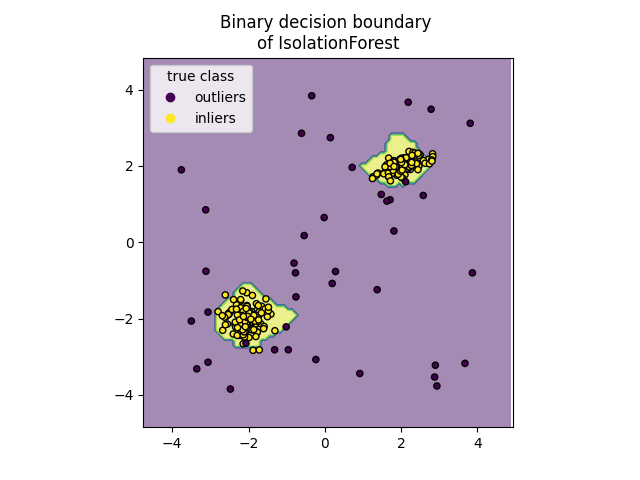
绘制离散决策边界#
我们使用类 DecisionBoundaryDisplay 来可视化离散决策边界。背景颜色表示该区域内的样本是否被预测为异常点。散点图显示真实标签。
import matplotlib.pyplot as plt
from sklearn.inspection import DecisionBoundaryDisplay
disp = DecisionBoundaryDisplay.from_estimator(
clf,
X,
response_method="predict",
alpha=0.5,
)
disp.ax_.scatter(X[:, 0], X[:, 1], c=y, s=20, edgecolor="k")
disp.ax_.set_title("Binary decision boundary \nof IsolationForest")
plt.axis("square")
plt.legend(handles=handles, labels=["outliers", "inliers"], title="true class")
plt.show()
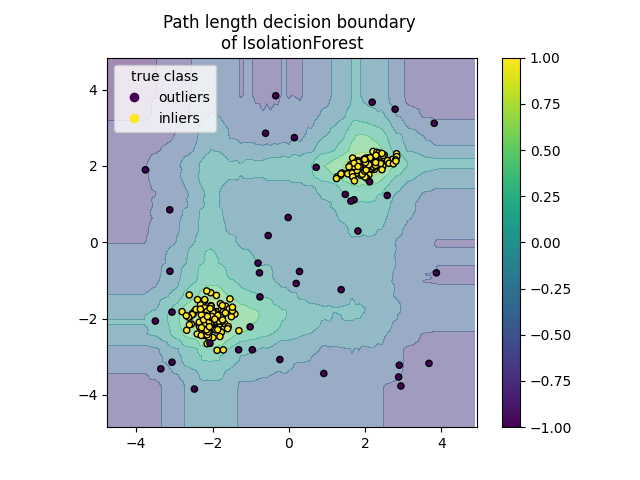
绘制路径长度决策边界#
通过设置 response_method="decision_function" ,DecisionBoundaryDisplay 的背景代表了观测值的正常性度量。该分数由在一片随机森林中平均的路径长度给出,而路径长度本身由隔离给定样本所需的叶子深度(或等效的分裂次数)决定。
当一片随机树组成的森林为某些特定样本生成较短的路径长度时,它们很可能是异常值,且正常性的度量接近于 0 。类似地,较长的路径对应于接近于 1 的值,并且更有可能是内点。
disp = DecisionBoundaryDisplay.from_estimator(
clf,
X,
response_method="decision_function",
alpha=0.5,
)
disp.ax_.scatter(X[:, 0], X[:, 1], c=y, s=20, edgecolor="k")
disp.ax_.set_title("Path length decision boundary \nof IsolationForest")
plt.axis("square")
plt.legend(handles=handles, labels=["outliers", "inliers"], title="true class")
plt.colorbar(disp.ax_.collections[1])
plt.show()
Total running time of the script: (0 minutes 0.208 seconds)
Related examples