Note
Go to the end to download the full example code. or to run this example in your browser via Binder
时间相关特征工程#
本笔记本介绍了在一个高度依赖于商业周期(天、周、月)和年度季节周期的自行车共享需求回归任务中,利用时间相关特征的不同策略。
在此过程中,我们介绍了如何使用 sklearn.preprocessing.SplineTransformer 类及其 extrapolation="periodic" 选项来执行周期性特征工程。
对自行车共享需求数据集进行数据探索#
我们首先从OpenML仓库加载数据。
from sklearn.datasets import fetch_openml
bike_sharing = fetch_openml("Bike_Sharing_Demand", version=2, as_frame=True)
df = bike_sharing.frame
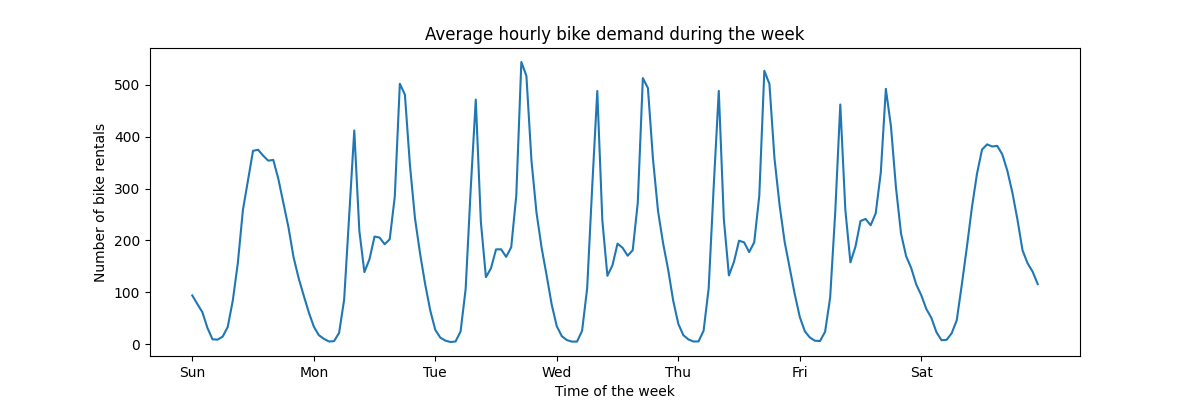
为了快速了解数据的周期性模式,让我们看看一周内每小时的平均需求。
请注意,周是从周日(周末)开始的。我们可以清楚地分辨出工作日早晚的通勤模式,以及周末自行车的休闲使用情况,周末的需求高峰在一天中的中间时段更为分散。
import matplotlib.pyplot as plt
fig, ax = plt.subplots(figsize=(12, 4))
average_week_demand = df.groupby(["weekday", "hour"])["count"].mean()
average_week_demand.plot(ax=ax)
_ = ax.set(
title="Average hourly bike demand during the week",
xticks=[i * 24 for i in range(7)],
xticklabels=["Sun", "Mon", "Tue", "Wed", "Thu", "Fri", "Sat"],
xlabel="Time of the week",
ylabel="Number of bike rentals",
)
预测问题的目标是每小时自行车租赁的绝对数量:
df["count"].max()
np.int64(977)
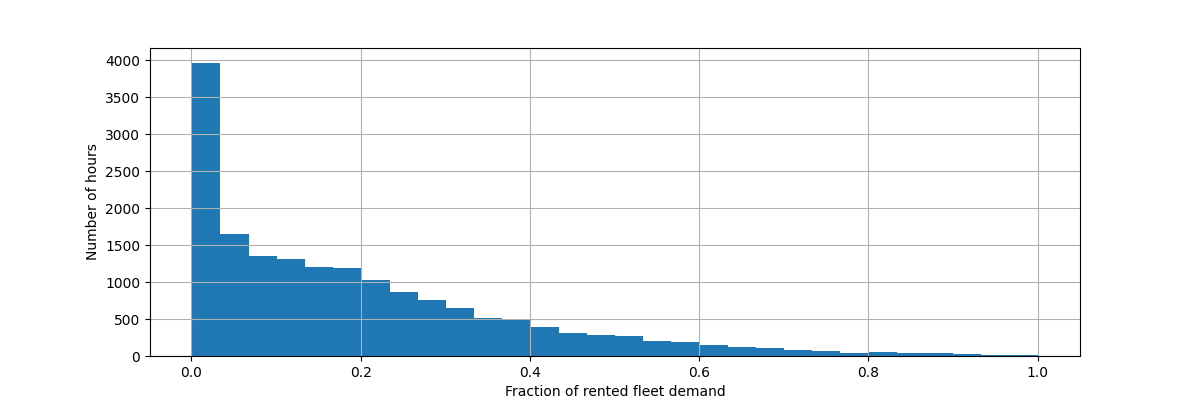
让我们重新调整目标变量(每小时自行车租赁数量)以预测相对需求,这样平均绝对误差更容易被解释为最大需求的一部分。
这些模型的拟合方法都通过最小化均方误差来估计条件均值。 然而,绝对误差则会估计条件中位数。
然而,在讨论中报告测试集上的性能指标时,我们选择关注平均绝对误差而不是(均方)根误差,因为它更直观易懂。然而,请注意,在本研究中,一个指标的最佳模型在另一个指标上也是最佳的。
y = df["count"] / df["count"].max()
fig, ax = plt.subplots(figsize=(12, 4))
y.hist(bins=30, ax=ax)
_ = ax.set(
xlabel="Fraction of rented fleet demand",
ylabel="Number of hours",
)
输入特征数据框是一个带有时间标注的每小时天气状况日志。它包括数值变量和分类变量。请注意,时间信息已经扩展到几个补充列中。
X = df.drop("count", axis="columns")
X
如果时间信息仅以日期或日期时间列的形式存在,我们可以使用pandas将其扩展为一天中的小时、一周中的天、一个月中的天、一年中的月: https://pandas.pydata.org/pandas-docs/stable/user_guide/timeseries.htmltime-date-components
我们现在开始检查分类变量的分布,从 "weather" 开始:
X["weather"].value_counts()
weather
clear 11413
misty 4544
rain 1419
heavy_rain 3
Name: count, dtype: int64
由于只有3个“heavy_rain”事件,我们无法使用此类别通过交叉验证来训练机器学习模型。相反,我们通过将这些事件合并到“rain”类别中来简化表示。
X["weather"] = (
X["weather"]
.astype(object)
.replace(to_replace="heavy_rain", value="rain")
.astype("category")
)
X["weather"].value_counts()
weather
clear 11413
misty 4544
rain 1422
Name: count, dtype: int64
正如预期的那样, "season" 变量是均衡的:
X["season"].value_counts()
season
fall 4496
summer 4409
spring 4242
winter 4232
Name: count, dtype: int64
时间序列交叉验证#
由于数据集是按时间排序的事件日志(每小时需求),我们将使用时间敏感的交叉验证分割器来尽可能真实地评估我们的需求预测模型。我们在训练集和测试集之间使用2天的间隔。我们还限制了训练集的大小,以使交叉验证折叠的性能更加稳定。
1000个测试数据点应该足以量化模型的性能。这代表了不到一个半月的连续测试数据:
from sklearn.model_selection import TimeSeriesSplit
ts_cv = TimeSeriesSplit(
n_splits=5,
gap=48,
max_train_size=10000,
test_size=1000,
)
让我们手动检查各个分割,以确认 TimeSeriesSplit 按预期工作,从第一个分割开始:
all_splits = list(ts_cv.split(X, y))
train_0, test_0 = all_splits[0]
X.iloc[test_0]
X.iloc[train_0]
我们现在检查最后一个分割:
train_4, test_4 = all_splits[4]
X.iloc[test_4]
X.iloc[train_4]
一切顺利。我们现在准备进行一些预测建模!
梯度提升#
带有决策树的梯度提升回归通常足够灵活,可以有效处理包含混合类别和数值特征的异构表格数据,只要样本数量足够大。
在这里,我们使用了现代的 HistGradientBoostingRegressor ,它原生支持分类特征。因此,我们只需要设置 categorical_features="from_dtype" ,使具有分类数据类型的特征被视为分类特征。作为参考,我们根据数据类型从数据框中提取分类特征。内部树对这些特征使用专门的树分割规则。
数值变量不需要预处理,并且为了简化起见,我们仅尝试此模型的默认超参数:
from sklearn.compose import ColumnTransformer
from sklearn.ensemble import HistGradientBoostingRegressor
from sklearn.model_selection import cross_validate
from sklearn.pipeline import make_pipeline
gbrt = HistGradientBoostingRegressor(categorical_features="from_dtype", random_state=42)
categorical_columns = X.columns[X.dtypes == "category"]
print("Categorical features:", categorical_columns.tolist())
Categorical features: ['season', 'holiday', 'workingday', 'weather']
让我们通过平均绝对误差来评估我们的梯度提升模型,该误差是基于5次时间序列交叉验证分割的相对需求的平均值:
import numpy as np
def evaluate(model, X, y, cv, model_prop=None, model_step=None):
cv_results = cross_validate(
model,
X,
y,
cv=cv,
scoring=["neg_mean_absolute_error", "neg_root_mean_squared_error"],
return_estimator=model_prop is not None,
)
if model_prop is not None:
if model_step is not None:
values = [
getattr(m[model_step], model_prop) for m in cv_results["estimator"]
]
else:
values = [getattr(m, model_prop) for m in cv_results["estimator"]]
print(f"Mean model.{model_prop} = {np.mean(values)}")
mae = -cv_results["test_neg_mean_absolute_error"]
rmse = -cv_results["test_neg_root_mean_squared_error"]
print(
f"Mean Absolute Error: {mae.mean():.3f} +/- {mae.std():.3f}\n"
f"Root Mean Squared Error: {rmse.mean():.3f} +/- {rmse.std():.3f}"
)
evaluate(gbrt, X, y, cv=ts_cv, model_prop="n_iter_")
Mean model.n_iter_ = 100.0
Mean Absolute Error: 0.044 +/- 0.003
Root Mean Squared Error: 0.068 +/- 0.005
我们看到我们将 max_iter 设置得足够大,以至于发生了提前停止。
该模型的平均误差约为最大需求的4%到5%。对于没有进行任何超参数调整的首次试验来说,这已经相当不错了!我们只需要将分类变量显式化。注意,时间相关特征是按原样传递的,即没有对其进行处理。但这对基于树的模型来说并不是大问题,因为它们可以学习有序输入特征与目标之间的非单调关系。
对于线性回归模型情况并非如此,正如我们将在下文中看到的。
朴素线性回归#
像往常一样,对于线性模型,分类变量需要进行独热编码。为了保持一致性,我们使用:class:~sklearn.preprocessing.MinMaxScaler 将数值特征缩放到相同的0-1范围,尽管在这种情况下它对结果的影响不大,因为它们已经在可比的尺度上。
from sklearn.linear_model import RidgeCV
from sklearn.preprocessing import MinMaxScaler, OneHotEncoder
one_hot_encoder = OneHotEncoder(handle_unknown="ignore", sparse_output=False)
alphas = np.logspace(-6, 6, 25)
naive_linear_pipeline = make_pipeline(
ColumnTransformer(
transformers=[
("categorical", one_hot_encoder, categorical_columns),
],
remainder=MinMaxScaler(),
),
RidgeCV(alphas=alphas),
)
evaluate(
naive_linear_pipeline, X, y, cv=ts_cv, model_prop="alpha_", model_step="ridgecv"
)
Mean model.alpha_ = 2.7298221281347037
Mean Absolute Error: 0.142 +/- 0.014
Root Mean Squared Error: 0.184 +/- 0.020
很高兴看到所选的 alpha_ 在我们指定的范围内。
性能不佳:平均误差约为最大需求的14%。这比梯度提升模型的平均误差高出三倍多。我们可以怀疑,周期性时间相关特征的原始编码(仅进行最小-最大缩放)可能会阻碍线性回归模型正确利用时间信息:线性回归不会自动建模输入特征和目标之间的非单调关系。必须在输入中设计非线性项。
例如,”hour” 特征的原始数值编码会导致线性模型无法识别早晨从6点到8点的小时增加应该对自行车租赁数量有强烈的正面影响,而晚上从18点到20点的类似幅度增加应该对预测的自行车租赁数量有强烈的负面影响。
时间步作为类别#
由于时间特征是以离散方式使用整数编码的(“小时”特征中有24个唯一值),我们可以选择将其视为分类变量,使用独热编码,从而忽略小时值顺序所隐含的任何假设。
使用独热编码处理时间特征为线性模型提供了更多灵活性,因为我们为每个离散时间级别引入了一个额外的特征。
one_hot_linear_pipeline = make_pipeline(
ColumnTransformer(
transformers=[
("categorical", one_hot_encoder, categorical_columns),
("one_hot_time", one_hot_encoder, ["hour", "weekday", "month"]),
],
remainder=MinMaxScaler(),
),
RidgeCV(alphas=alphas),
)
evaluate(one_hot_linear_pipeline, X, y, cv=ts_cv)
Mean Absolute Error: 0.099 +/- 0.011
Root Mean Squared Error: 0.131 +/- 0.011
该模型的平均错误率为10%,这比使用时间特征的原始(序数)编码要好得多,这证实了我们的直觉,即线性回归模型受益于不以单调方式处理时间进展的额外灵活性。
然而,这引入了大量的新特征。如果一天中的时间用自一天开始以来的分钟数而不是小时数来表示,独热编码将引入1440个特征而不是24个特征。这可能会导致一些显著的过拟合。为了避免这种情况,我们可以使用 sklearn.preprocessing.KBinsDiscretizer 重新分箱细粒度的有序或数值变量的级别,同时仍然受益于独热编码的非单调表达优势。
最后,我们还观察到,独热编码完全忽略了小时级别的顺序,而这可能是一个有趣的归纳偏差,需要在某种程度上保留。在下文中,我们尝试探索平滑的、非单调的编码,这种编码在局部上保留了时间特征的相对顺序。
三角特征#
作为第一次尝试,我们可以尝试使用具有匹配周期的正弦和余弦变换来编码每个周期性特征。
每个序数时间特征被转换为两个特征,这两个特征以非单调的方式编码等效信息,更重要的是,在周期范围的第一个值和最后一个值之间没有任何跳跃。
from sklearn.preprocessing import FunctionTransformer
def sin_transformer(period):
return FunctionTransformer(lambda x: np.sin(x / period * 2 * np.pi))
def cos_transformer(period):
return FunctionTransformer(lambda x: np.cos(x / period * 2 * np.pi))
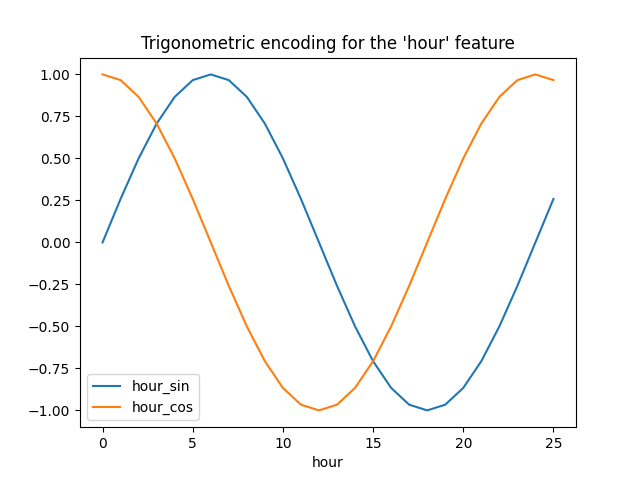
让我们通过一些合成的小时数据并在小时=23之外进行一些外推,来可视化此特征扩展的效果:
import pandas as pd
hour_df = pd.DataFrame(
np.arange(26).reshape(-1, 1),
columns=["hour"],
)
hour_df["hour_sin"] = sin_transformer(24).fit_transform(hour_df)["hour"]
hour_df["hour_cos"] = cos_transformer(24).fit_transform(hour_df)["hour"]
hour_df.plot(x="hour")
_ = plt.title("Trigonometric encoding for the 'hour' feature")
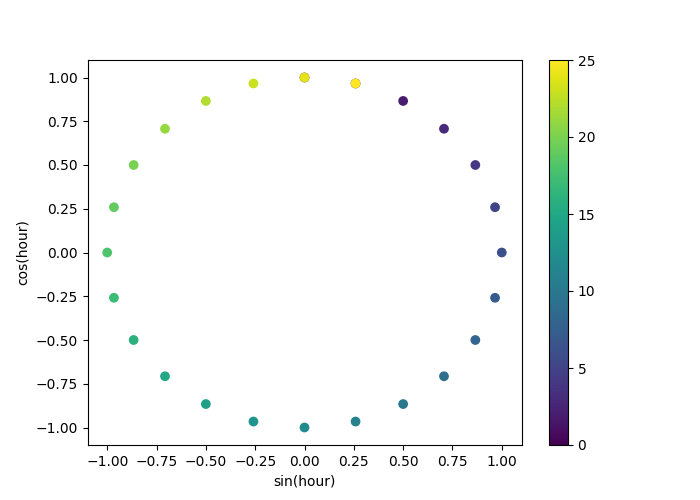
让我们使用一个二维散点图,并将小时编码为颜色,以更好地查看这种表示如何将一天的24小时映射到二维空间,有点类似于某种24小时版本的模拟时钟。请注意,由于正弦/余弦表示的周期性,“第25小时”被映射回第1小时。
fig, ax = plt.subplots(figsize=(7, 5))
sp = ax.scatter(hour_df["hour_sin"], hour_df["hour_cos"], c=hour_df["hour"])
ax.set(
xlabel="sin(hour)",
ylabel="cos(hour)",
)
_ = fig.colorbar(sp)
我们现在可以使用这种策略构建一个特征提取管道:
cyclic_cossin_transformer = ColumnTransformer(
transformers=[
("categorical", one_hot_encoder, categorical_columns),
("month_sin", sin_transformer(12), ["month"]),
("month_cos", cos_transformer(12), ["month"]),
("weekday_sin", sin_transformer(7), ["weekday"]),
("weekday_cos", cos_transformer(7), ["weekday"]),
("hour_sin", sin_transformer(24), ["hour"]),
("hour_cos", cos_transformer(24), ["hour"]),
],
remainder=MinMaxScaler(),
)
cyclic_cossin_linear_pipeline = make_pipeline(
cyclic_cossin_transformer,
RidgeCV(alphas=alphas),
)
evaluate(cyclic_cossin_linear_pipeline, X, y, cv=ts_cv)
Mean Absolute Error: 0.125 +/- 0.014
Root Mean Squared Error: 0.166 +/- 0.020
通过这种简单的特征工程,我们的线性回归模型性能比使用原始序数时间特征稍好,但不如使用独热编码时间特征。我们将在本笔记本的末尾进一步分析这一令人失望结果的可能原因。
周期样条特征#
我们可以尝试使用样条变换对周期性时间相关特征进行另一种编码,使用足够多的样条,从而相比于正弦/余弦变换得到更多的扩展特征:
from sklearn.preprocessing import SplineTransformer
def periodic_spline_transformer(period, n_splines=None, degree=3):
if n_splines is None:
n_splines = period
n_knots = n_splines + 1 # periodic and include_bias is True
return SplineTransformer(
degree=degree,
n_knots=n_knots,
knots=np.linspace(0, period, n_knots).reshape(n_knots, 1),
extrapolation="periodic",
include_bias=True,
)
让我们再次通过一些合成的小时数据并在小时=23之外进行一些外推来可视化此特征扩展的效果:
hour_df = pd.DataFrame(
np.linspace(0, 26, 1000).reshape(-1, 1),
columns=["hour"],
)
splines = periodic_spline_transformer(24, n_splines=12).fit_transform(hour_df)
splines_df = pd.DataFrame(
splines,
columns=[f"spline_{i}" for i in range(splines.shape[1])],
)
pd.concat([hour_df, splines_df], axis="columns").plot(x="hour", cmap=plt.cm.tab20b)
_ = plt.title("Periodic spline-based encoding for the 'hour' feature")
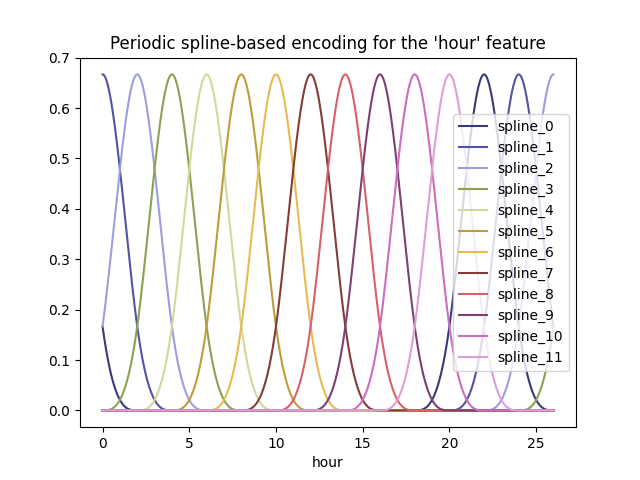
由于使用了 extrapolation="periodic" 参数,我们观察到在超出午夜时,特征编码保持平滑。
我们现在可以使用这种替代的周期性特征工程策略来构建一个预测管道。
可以使用比离散水平更少的样条来表示这些有序值。这使得基于样条的编码比独热编码更高效,同时保留了大部分的表达能力:
cyclic_spline_transformer = ColumnTransformer(
transformers=[
("categorical", one_hot_encoder, categorical_columns),
("cyclic_month", periodic_spline_transformer(12, n_splines=6), ["month"]),
("cyclic_weekday", periodic_spline_transformer(7, n_splines=3), ["weekday"]),
("cyclic_hour", periodic_spline_transformer(24, n_splines=12), ["hour"]),
],
remainder=MinMaxScaler(),
)
cyclic_spline_linear_pipeline = make_pipeline(
cyclic_spline_transformer,
RidgeCV(alphas=alphas),
)
evaluate(cyclic_spline_linear_pipeline, X, y, cv=ts_cv)
Mean Absolute Error: 0.097 +/- 0.011
Root Mean Squared Error: 0.132 +/- 0.013
样条特征使线性模型能够成功利用周期性时间相关特征,并将误差从最大需求的约14%减少到约10%,这与我们在使用独热编码特征时观察到的情况类似。
定性分析特征对线性模型预测的影响#
在这里,我们希望可视化特征工程选择对预测时间相关形状的影响。
为此,我们考虑一个任意的基于时间的分割,以比较在一系列保留数据点上的预测。
naive_linear_pipeline.fit(X.iloc[train_0], y.iloc[train_0])
naive_linear_predictions = naive_linear_pipeline.predict(X.iloc[test_0])
one_hot_linear_pipeline.fit(X.iloc[train_0], y.iloc[train_0])
one_hot_linear_predictions = one_hot_linear_pipeline.predict(X.iloc[test_0])
cyclic_cossin_linear_pipeline.fit(X.iloc[train_0], y.iloc[train_0])
cyclic_cossin_linear_predictions = cyclic_cossin_linear_pipeline.predict(X.iloc[test_0])
cyclic_spline_linear_pipeline.fit(X.iloc[train_0], y.iloc[train_0])
cyclic_spline_linear_predictions = cyclic_spline_linear_pipeline.predict(X.iloc[test_0])
我们通过放大测试集的最后96小时(4天)来可视化这些预测,以获得一些定性见解:
last_hours = slice(-96, None)
fig, ax = plt.subplots(figsize=(12, 4))
fig.suptitle("Predictions by linear models")
ax.plot(
y.iloc[test_0].values[last_hours],
"x-",
alpha=0.2,
label="Actual demand",
color="black",
)
ax.plot(naive_linear_predictions[last_hours], "x-", label="Ordinal time features")
ax.plot(
cyclic_cossin_linear_predictions[last_hours],
"x-",
label="Trigonometric time features",
)
ax.plot(
cyclic_spline_linear_predictions[last_hours],
"x-",
label="Spline-based time features",
)
ax.plot(
one_hot_linear_predictions[last_hours],
"x-",
label="One-hot time features",
)
_ = ax.legend()
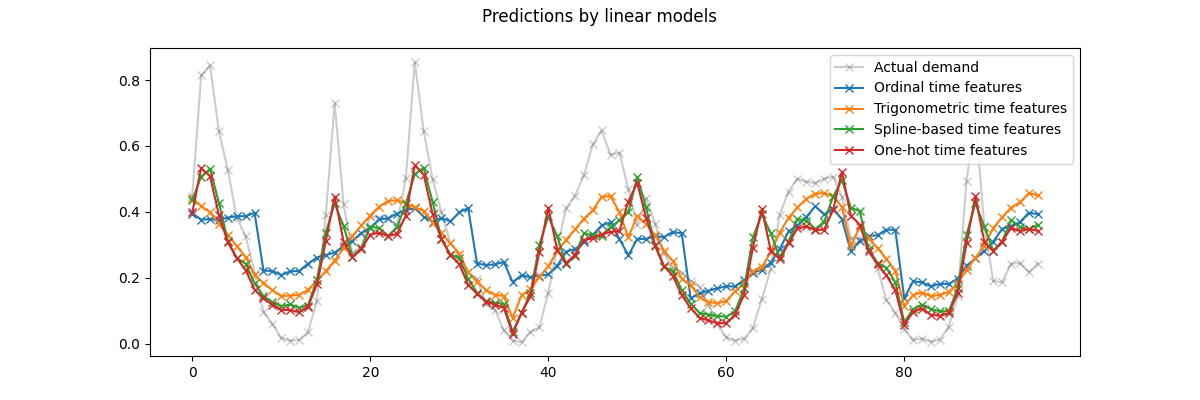
我们可以从上图得出以下结论:
原始序数时间相关特征 存在问题,因为它们没有捕捉到自然的周期性:我们观察到在每天结束时,当小时特征从23变回0时,预测结果会出现大的跳跃。我们可以预期在每周或每年结束时会出现类似的现象。
正如预期的那样,**三角特征**(正弦和余弦)在午夜时没有这些不连续性,但线性回归模型未能利用这些特征来正确建模日内变化。使用更高次谐波的三角特征或具有不同相位的自然周期的附加三角特征可能会解决这个问题。
基于周期样条的特征 同时解决了这两个问题:它们通过使用12个样条使线性模型能够关注特定的小时,从而提供了更高的表达能力。此外,
extrapolation="periodic"选项确保了hour=23和hour=0之间的平滑表示。独热编码特征 的行为类似于基于周期样条的特征,但更加尖锐:例如,它们可以更好地模拟工作日早晨的高峰,因为这个高峰持续时间不到一小时。然而,我们将在下文中看到,对于线性模型来说可能是优势的特征,对于更具表现力的模型来说不一定是优势。
我们还可以比较每个特征工程管道提取的特征数量:
naive_linear_pipeline[:-1].transform(X).shape
(17379, 19)
one_hot_linear_pipeline[:-1].transform(X).shape
(17379, 59)
cyclic_cossin_linear_pipeline[:-1].transform(X).shape
(17379, 22)
cyclic_spline_linear_pipeline[:-1].transform(X).shape
(17379, 37)
这证实了独热编码和样条编码策略相比其他方法为时间表示创建了更多的特征,这反过来给下游的线性模型提供了更多的灵活性(自由度)以避免欠拟合。
最后,我们观察到没有一个线性模型能够近似真实的自行车租赁需求,尤其是在工作日的高峰时段需求非常尖锐,而在周末则平缓得多:基于样条或独热编码的最准确的线性模型往往会在周末预测出与通勤相关的自行车租赁高峰,而在工作日则低估了与通勤相关的事件。
这些系统性预测误差揭示了一种欠拟合形式,可以通过特征之间缺乏交互项来解释,例如“工作日”和从“小时”派生的特征。这个问题将在下一节中解决。
使用样条和多项式特征对成对交互进行建模#
线性模型不会自动捕捉输入特征之间的交互效应。某些特征在边际上是非线性的,这种情况并不会有所帮助,例如由 SplineTransformer 构造的特征(或独热编码或分箱)。
然而,可以在粗粒度样条编码的小时上使用 PolynomialFeatures 类,以明确地对“工作日”/“小时”交互建模,而不会引入太多新变量:
from sklearn.pipeline import FeatureUnion
from sklearn.preprocessing import PolynomialFeatures
hour_workday_interaction = make_pipeline(
ColumnTransformer(
[
("cyclic_hour", periodic_spline_transformer(24, n_splines=8), ["hour"]),
("workingday", FunctionTransformer(lambda x: x == "True"), ["workingday"]),
]
),
PolynomialFeatures(degree=2, interaction_only=True, include_bias=False),
)
这些特征随后与之前样条基管道中已经计算出的特征相结合。通过显式地对这种成对交互建模,我们可以观察到性能的显著提升:
cyclic_spline_interactions_pipeline = make_pipeline(
FeatureUnion(
[
("marginal", cyclic_spline_transformer),
("interactions", hour_workday_interaction),
]
),
RidgeCV(alphas=alphas),
)
evaluate(cyclic_spline_interactions_pipeline, X, y, cv=ts_cv)
Mean Absolute Error: 0.078 +/- 0.009
Root Mean Squared Error: 0.104 +/- 0.009
使用核函数对非线性特征交互进行建模#
先前的分析强调了对 "workingday" 和 "hours" 之间的交互进行建模的必要性。我们希望建模的另一个非线性交互示例可能是雨天的影响,例如,雨天的影响在工作日和周末及假期可能并不相同。
为了对所有此类交互进行建模,我们可以在所有边际特征进行样条扩展后,使用多项式扩展。然而,这将产生数量级为平方的特征,可能导致过拟合和计算可行性问题。
或者,我们可以使用Nyström方法来计算近似的多项式核展开。让我们尝试后者:
from sklearn.kernel_approximation import Nystroem
cyclic_spline_poly_pipeline = make_pipeline(
cyclic_spline_transformer,
Nystroem(kernel="poly", degree=2, n_components=300, random_state=0),
RidgeCV(alphas=alphas),
)
evaluate(cyclic_spline_poly_pipeline, X, y, cv=ts_cv)
Mean Absolute Error: 0.053 +/- 0.002
Root Mean Squared Error: 0.076 +/- 0.004
我们观察到,该模型的表现几乎可以媲美梯度提升树,平均误差约为最大需求的5%。
请注意,尽管该管道的最后一步是线性回归模型,但中间步骤如样条特征提取和Nyström核近似是高度非线性的。因此,复合管道比仅使用原始特征的简单线性回归模型表达能力更强。
为了完整性起见,我们还评估了独热编码和核近似的组合:
one_hot_poly_pipeline = make_pipeline(
ColumnTransformer(
transformers=[
("categorical", one_hot_encoder, categorical_columns),
("one_hot_time", one_hot_encoder, ["hour", "weekday", "month"]),
],
remainder="passthrough",
),
Nystroem(kernel="poly", degree=2, n_components=300, random_state=0),
RidgeCV(alphas=alphas),
)
evaluate(one_hot_poly_pipeline, X, y, cv=ts_cv)
Mean Absolute Error: 0.082 +/- 0.006
Root Mean Squared Error: 0.111 +/- 0.011
虽然在使用线性模型时,独热编码特征与基于样条的特征具有竞争力,但在使用非线性核的低秩近似时,情况不再如此:这可以通过样条特征更平滑并允许核近似找到更具表现力的决策函数来解释。
现在让我们定性地看看核模型和梯度提升树的预测,这些模型应该能够更好地模拟特征之间的非线性交互:
gbrt.fit(X.iloc[train_0], y.iloc[train_0])
gbrt_predictions = gbrt.predict(X.iloc[test_0])
one_hot_poly_pipeline.fit(X.iloc[train_0], y.iloc[train_0])
one_hot_poly_predictions = one_hot_poly_pipeline.predict(X.iloc[test_0])
cyclic_spline_poly_pipeline.fit(X.iloc[train_0], y.iloc[train_0])
cyclic_spline_poly_predictions = cyclic_spline_poly_pipeline.predict(X.iloc[test_0])
我们再次聚焦于测试集的最后4天:
last_hours = slice(-96, None)
fig, ax = plt.subplots(figsize=(12, 4))
fig.suptitle("Predictions by non-linear regression models")
ax.plot(
y.iloc[test_0].values[last_hours],
"x-",
alpha=0.2,
label="Actual demand",
color="black",
)
ax.plot(
gbrt_predictions[last_hours],
"x-",
label="Gradient Boosted Trees",
)
ax.plot(
one_hot_poly_predictions[last_hours],
"x-",
label="One-hot + polynomial kernel",
)
ax.plot(
cyclic_spline_poly_predictions[last_hours],
"x-",
label="Splines + polynomial kernel",
)
_ = ax.legend()
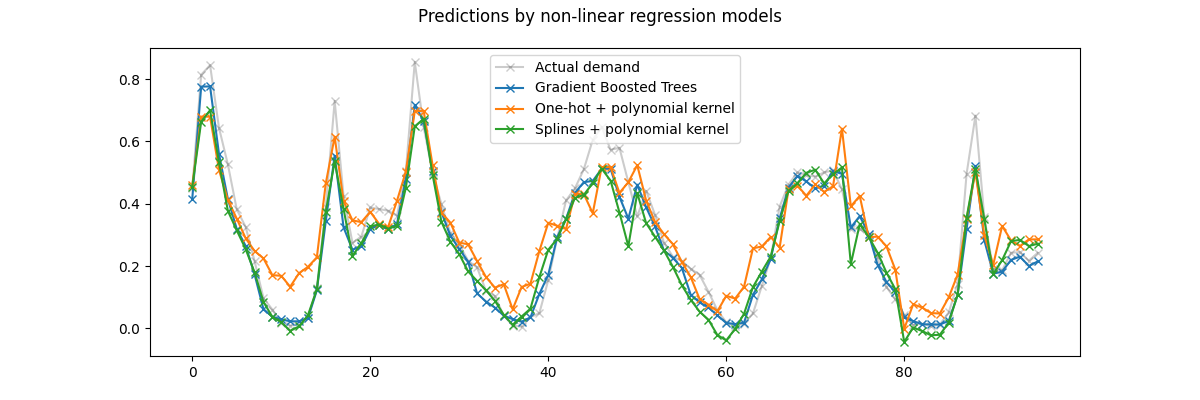
首先,请注意,树可以自然地建模非线性特征交互,因为默认情况下,决策树被允许生长超过2层深度。
在这里,我们可以观察到样条特征和非线性核的组合效果相当好,几乎可以媲美梯度提升回归树的准确性。
相反,独热编码的时间特征在低秩核模型中的表现并不理想。特别是,它们对低需求时段的估计明显高于其他竞争模型。
我们还观察到,没有一个模型能够成功预测工作日高峰时段的一些租赁高峰。这可能是因为需要额外的特征来进一步提高预测的准确性。例如,能够随时获取车队的地理分布或需要维修而无法使用的自行车比例可能会有所帮助。
让我们最终通过真实需求与预测需求的散点图,更定量地观察这三个模型的预测误差:
from sklearn.metrics import PredictionErrorDisplay
fig, axes = plt.subplots(nrows=2, ncols=3, figsize=(13, 7), sharex=True, sharey="row")
fig.suptitle("Non-linear regression models", y=1.0)
predictions = [
one_hot_poly_predictions,
cyclic_spline_poly_predictions,
gbrt_predictions,
]
labels = [
"One hot +\npolynomial kernel",
"Splines +\npolynomial kernel",
"Gradient Boosted\nTrees",
]
plot_kinds = ["actual_vs_predicted", "residual_vs_predicted"]
for axis_idx, kind in enumerate(plot_kinds):
for ax, pred, label in zip(axes[axis_idx], predictions, labels):
disp = PredictionErrorDisplay.from_predictions(
y_true=y.iloc[test_0],
y_pred=pred,
kind=kind,
scatter_kwargs={"alpha": 0.3},
ax=ax,
)
ax.set_xticks(np.linspace(0, 1, num=5))
if axis_idx == 0:
ax.set_yticks(np.linspace(0, 1, num=5))
ax.legend(
["Best model", label],
loc="upper center",
bbox_to_anchor=(0.5, 1.3),
ncol=2,
)
ax.set_aspect("equal", adjustable="box")
plt.show()
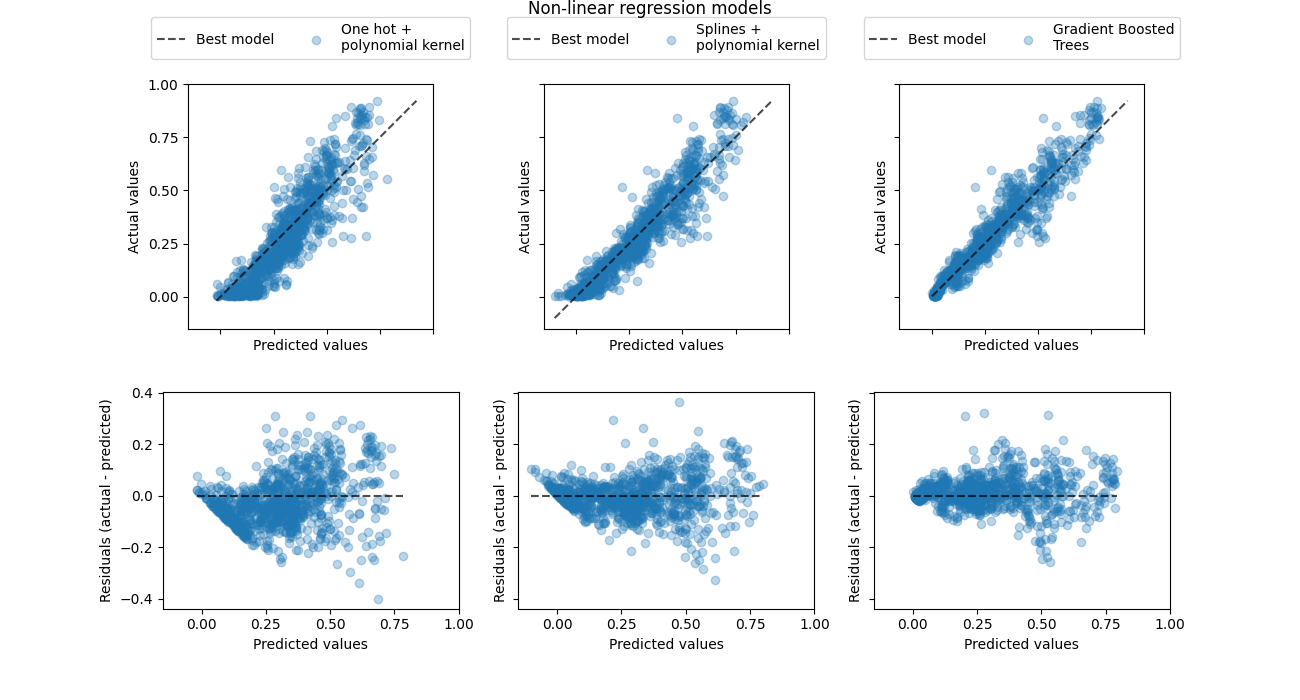
这张可视化图表验证了我们在前一张图表中得出的结论。
所有模型都低估了高需求事件(工作日高峰时段),但梯度提升模型的低估程度稍微小一些。梯度提升模型对低需求事件的预测平均来说较为准确,而独热编码多项式回归管道在这种情况下似乎系统性地高估了需求。总体而言,梯度提升树的预测比核模型更接近对角线。
结论#
我们注意到,通过使用更多的成分(更高阶的核近似),我们可以为核模型获得稍微更好的结果,但代价是更长的拟合和预测时间。对于较大的 n_components 值,单热编码特征的性能甚至可以与样条特征相匹配。
Nystroem + RidgeCV 回归器也可以被 MLPRegressor 替代,使用一层或两层隐藏层,我们将获得非常相似的结果。
我们在本案例研究中使用的数据集是按小时采样的。然而,基于周期样条的特征可以非常高效地用更细粒度的时间分辨率(例如每分钟测量一次而不是每小时)来建模日内时间或周内时间,而不会引入更多的特征。独热编码时间表示法则无法提供这种灵活性。
最后,在本笔记本中我们使用了 RidgeCV ,因为从计算的角度来看它非常高效。然而,它将目标变量建模为具有恒定方差的高斯随机变量。对于正回归问题,使用泊松分布或伽马分布可能更有意义。这可以通过使用 GridSearchCV(TweedieRegressor(power=2), param_grid({"alpha": alphas})) 来实现,而不是 RidgeCV 。
Total running time of the script: (0 minutes 12.619 seconds)
Related examples