Note
Go to the end to download the full example code. or to run this example in your browser via Binder
使用特征脸和支持向量机进行人脸识别的示例#
本示例中使用的数据集是“Labeled Faces in the Wild”(简称LFW)的预处理摘录:
from time import time
import matplotlib.pyplot as plt
from scipy.stats import loguniform
from sklearn.datasets import fetch_lfw_people
from sklearn.decomposition import PCA
from sklearn.metrics import ConfusionMatrixDisplay, classification_report
from sklearn.model_selection import RandomizedSearchCV, train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.svm import SVC
下载数据(如果尚未存在于磁盘上)并将其加载为 numpy 数组
lfw_people = fetch_lfw_people(min_faces_per_person=70, resize=0.4)
# 检查图像数组以找到形状(用于绘图)
n_samples, h, w = lfw_people.images.shape
# 对于机器学习,我们直接使用这两个数据(因为该模型忽略了相对像素位置信息)。
X = lfw_people.data
n_features = X.shape[1]
# 要预测的标签是人的ID
y = lfw_people.target
target_names = lfw_people.target_names
n_classes = target_names.shape[0]
print("Total dataset size:")
print("n_samples: %d" % n_samples)
print("n_features: %d" % n_features)
print("n_classes: %d" % n_classes)
Total dataset size:
n_samples: 1288
n_features: 1850
n_classes: 7
拆分为训练集和测试集,并保留25%的数据用于测试。
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.25, random_state=42
)
scaler = StandardScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test)
计算人脸数据集上的PCA(特征脸)(视为无标签数据集):无监督特征提取/降维
n_components = 150
print(
"Extracting the top %d eigenfaces from %d faces" % (n_components, X_train.shape[0])
)
t0 = time()
pca = PCA(n_components=n_components, svd_solver="randomized", whiten=True).fit(X_train)
print("done in %0.3fs" % (time() - t0))
eigenfaces = pca.components_.reshape((n_components, h, w))
print("Projecting the input data on the eigenfaces orthonormal basis")
t0 = time()
X_train_pca = pca.transform(X_train)
X_test_pca = pca.transform(X_test)
print("done in %0.3fs" % (time() - t0))
Extracting the top 150 eigenfaces from 966 faces
done in 0.506s
Projecting the input data on the eigenfaces orthonormal basis
done in 0.058s
训练一个SVM分类模型
print("Fitting the classifier to the training set")
t0 = time()
param_grid = {
"C": loguniform(1e3, 1e5),
"gamma": loguniform(1e-4, 1e-1),
}
clf = RandomizedSearchCV(
SVC(kernel="rbf", class_weight="balanced"), param_grid, n_iter=10
)
clf = clf.fit(X_train_pca, y_train)
print("done in %0.3fs" % (time() - t0))
print("Best estimator found by grid search:")
print(clf.best_estimator_)
Fitting the classifier to the training set
done in 4.307s
Best estimator found by grid search:
SVC(C=np.float64(70550.73312335386), class_weight='balanced',
gamma=np.float64(0.0034333176762869253))
对测试集上模型质量的定量评估
print("Predicting people's names on the test set")
t0 = time()
y_pred = clf.predict(X_test_pca)
print("done in %0.3fs" % (time() - t0))
print(classification_report(y_test, y_pred, target_names=target_names))
ConfusionMatrixDisplay.from_estimator(
clf, X_test_pca, y_test, display_labels=target_names, xticks_rotation="vertical"
)
plt.tight_layout()
plt.show()
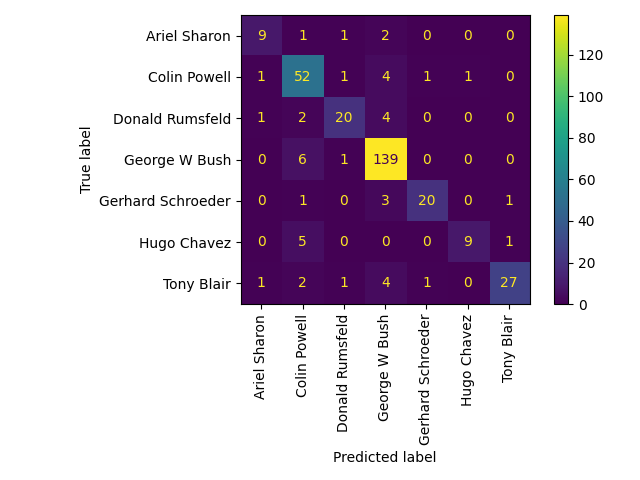
Predicting people's names on the test set
done in 0.029s
precision recall f1-score support
Ariel Sharon 0.75 0.69 0.72 13
Colin Powell 0.75 0.87 0.81 60
Donald Rumsfeld 0.83 0.74 0.78 27
George W Bush 0.89 0.95 0.92 146
Gerhard Schroeder 0.91 0.80 0.85 25
Hugo Chavez 0.90 0.60 0.72 15
Tony Blair 0.93 0.75 0.83 36
accuracy 0.86 322
macro avg 0.85 0.77 0.80 322
weighted avg 0.86 0.86 0.85 322
使用matplotlib对预测结果进行定性评估
def plot_gallery(images, titles, h, w, n_row=3, n_col=4):
"""帮助函数用于绘制肖像画廊"""
plt.figure(figsize=(1.8 * n_col, 2.4 * n_row))
plt.subplots_adjust(bottom=0, left=0.01, right=0.99, top=0.90, hspace=0.35)
for i in range(n_row * n_col):
plt.subplot(n_row, n_col, i + 1)
plt.imshow(images[i].reshape((h, w)), cmap=plt.cm.gray)
plt.title(titles[i], size=12)
plt.xticks(())
plt.yticks(())
绘制测试集部分数据的预测结果
def title(y_pred, y_test, target_names, i):
pred_name = target_names[y_pred[i]].rsplit(" ", 1)[-1]
true_name = target_names[y_test[i]].rsplit(" ", 1)[-1]
return "predicted: %s\ntrue: %s" % (pred_name, true_name)
prediction_titles = [
title(y_pred, y_test, target_names, i) for i in range(y_pred.shape[0])
]
plot_gallery(X_test, prediction_titles, h, w)

绘制最具代表性的特征脸画廊
eigenface_titles = ["eigenface %d" % i for i in range(eigenfaces.shape[0])]
plot_gallery(eigenfaces, eigenface_titles, h, w)
plt.show()

面部识别问题通过训练卷积神经网络可以更有效地解决,但这类模型不在scikit-learn库的范围内。感兴趣的读者应该尝试使用pytorch或tensorflow来实现这些模型。
Total running time of the script: (0 minutes 5.341 seconds)
Related examples