Note
Go to the end to download the full example code. or to run this example in your browser via Binder
泊松回归和非正态损失#
本示例说明了在 [1] 的 法国机动车第三方责任保险索赔数据集 上使用对数线性泊松回归,并将其与使用常规最小二乘误差拟合的线性模型以及使用泊松损失(和对数链接)拟合的非线性 GBRT 模型进行比较。
一些定义:
保单 是保险公司与个人之间的合同:即 投保人,在本例中是车辆驾驶员。
索赔 是投保人向保险公司提出的赔偿保险覆盖损失的请求。
暴露量 是给定保单的保险覆盖期限,以年为单位。
索赔 频率 是索赔数量除以暴露量,通常以每年索赔次数来衡量。
在此数据集中,每个样本对应一个保险保单。可用特征包括驾驶员年龄、车辆年龄、车辆功率等。
我们的目标是根据投保人群的历史数据,预测新投保人因车祸而提出索赔的预期频率。
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
法国机动车第三方责任索赔数据集
让我们从 OpenML 加载电机索赔数据集: https://www.openml.org/d/41214
from sklearn.datasets import fetch_openml
df = fetch_openml(data_id=41214, as_frame=True).frame
df
索赔数量( ClaimNb )是一个可以建模为泊松分布的正整数。假设它是在给定时间间隔( Exposure ,以年为单位)内以恒定速率发生的离散事件的数量。
在这里,我们希望通过(缩放的)泊松分布对 X 条件下的频率 y = ClaimNb / Exposure 进行建模,并使用 Exposure 作为 sample_weight 。
df["Frequency"] = df["ClaimNb"] / df["Exposure"]
print(
"Average Frequency = {}".format(np.average(df["Frequency"], weights=df["Exposure"]))
)
print(
"Fraction of exposure with zero claims = {0:.1%}".format(
df.loc[df["ClaimNb"] == 0, "Exposure"].sum() / df["Exposure"].sum()
)
)
fig, (ax0, ax1, ax2) = plt.subplots(ncols=3, figsize=(16, 4))
ax0.set_title("Number of claims")
_ = df["ClaimNb"].hist(bins=30, log=True, ax=ax0)
ax1.set_title("Exposure in years")
_ = df["Exposure"].hist(bins=30, log=True, ax=ax1)
ax2.set_title("Frequency (number of claims per year)")
_ = df["Frequency"].hist(bins=30, log=True, ax=ax2)
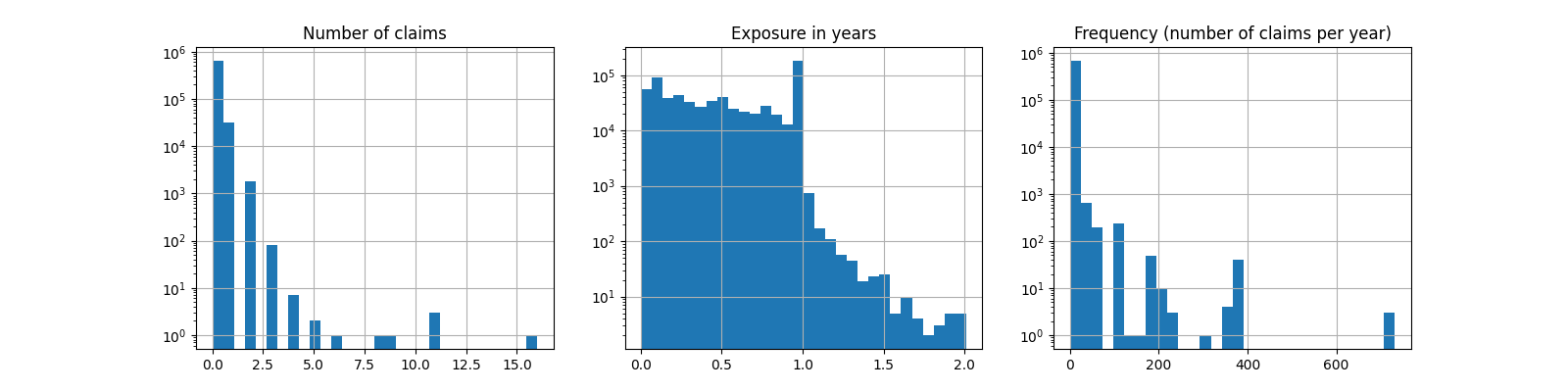
Average Frequency = 0.10070308464041304
Fraction of exposure with zero claims = 93.9%
剩余的列可以用来预测索赔事件的频率。这些列非常异质,包含混合的分类和数值变量,具有不同的尺度,可能分布非常不均匀。
为了使用这些预测变量拟合线性模型,因此有必要执行如下标准特征转换:
from sklearn.compose import ColumnTransformer
from sklearn.pipeline import make_pipeline
from sklearn.preprocessing import (
FunctionTransformer,
KBinsDiscretizer,
OneHotEncoder,
StandardScaler,
)
log_scale_transformer = make_pipeline(
FunctionTransformer(np.log, validate=False), StandardScaler()
)
linear_model_preprocessor = ColumnTransformer(
[
("passthrough_numeric", "passthrough", ["BonusMalus"]),
(
"binned_numeric",
KBinsDiscretizer(n_bins=10, random_state=0),
["VehAge", "DrivAge"],
),
("log_scaled_numeric", log_scale_transformer, ["Density"]),
(
"onehot_categorical",
OneHotEncoder(),
["VehBrand", "VehPower", "VehGas", "Region", "Area"],
),
],
remainder="drop",
)
一个恒定预测基线#
值得注意的是,超过93%的保单持有人没有索赔。如果我们将这个问题转换为二元分类任务,它将显得极度不平衡,甚至一个仅预测均值的简单模型也能达到93%的准确率。
为了评估所用指标的相关性,我们将以一个“虚拟”估计器作为基准,该估计器始终预测训练样本的平均频率。
from sklearn.dummy import DummyRegressor
from sklearn.model_selection import train_test_split
from sklearn.pipeline import Pipeline
df_train, df_test = train_test_split(df, test_size=0.33, random_state=0)
dummy = Pipeline(
[
("preprocessor", linear_model_preprocessor),
("regressor", DummyRegressor(strategy="mean")),
]
).fit(df_train, df_train["Frequency"], regressor__sample_weight=df_train["Exposure"])
让我们使用三种不同的回归指标来计算这个常数预测基线的性能:
from sklearn.metrics import (
mean_absolute_error,
mean_poisson_deviance,
mean_squared_error,
)
def score_estimator(estimator, df_test):
"""在测试集上对估计器进行评分。"""
y_pred = estimator.predict(df_test)
print(
"MSE: %.3f"
% mean_squared_error(
df_test["Frequency"], y_pred, sample_weight=df_test["Exposure"]
)
)
print(
"MAE: %.3f"
% mean_absolute_error(
df_test["Frequency"], y_pred, sample_weight=df_test["Exposure"]
)
)
# 忽略非正预测值,因为它们对泊松偏差无效。
mask = y_pred > 0
if (~mask).any():
n_masked, n_samples = (~mask).sum(), mask.shape[0]
print(
"WARNING: Estimator yields invalid, non-positive predictions "
f" for {n_masked} samples out of {n_samples}. These predictions "
"are ignored when computing the Poisson deviance."
)
print(
"mean Poisson deviance: %.3f"
% mean_poisson_deviance(
df_test["Frequency"][mask],
y_pred[mask],
sample_weight=df_test["Exposure"][mask],
)
)
print("Constant mean frequency evaluation:")
score_estimator(dummy, df_test)
Constant mean frequency evaluation:
MSE: 0.564
MAE: 0.189
mean Poisson deviance: 0.625
(广义)线性模型#
我们首先使用(带有l2惩罚的)最小二乘线性回归模型来对目标变量进行建模,这种模型更常被称为Ridge回归。我们使用较低的惩罚参数 alpha ,因为我们预计这样的线性模型在如此大的数据集上会欠拟合。
泊松偏差无法在模型预测的非正值上计算。对于确实返回一些非正预测值的模型(例如 Ridge ),我们会忽略相应的样本,这意味着得到的泊松偏差是近似的。另一种方法是使用 TransformedTargetRegressor 元估计器将 y_pred 映射到严格的正域。
print("Ridge evaluation:")
score_estimator(ridge_glm, df_test)
Ridge evaluation:
MSE: 0.560
MAE: 0.186
WARNING: Estimator yields invalid, non-positive predictions for 595 samples out of 223745. These predictions are ignored when computing the Poisson deviance.
mean Poisson deviance: 0.597
接下来我们对目标变量拟合泊松回归模型。我们将正则化强度 alpha 设置为样本数量的约1e-6(即 1e-12 ),以模拟岭回归模型,其L2惩罚项随样本数量的变化而不同。
由于泊松回归器在内部对期望目标值的对数进行建模,而不是直接对期望值进行建模(对数链接函数与恒等链接函数的区别),因此 X 和 y 之间的关系不再是完全线性的。因此,泊松回归器被称为广义线性模型(GLM),而不是像岭回归那样的普通线性模型。
from sklearn.linear_model import PoissonRegressor
n_samples = df_train.shape[0]
poisson_glm = Pipeline(
[
("preprocessor", linear_model_preprocessor),
("regressor", PoissonRegressor(alpha=1e-12, solver="newton-cholesky")),
]
)
poisson_glm.fit(
df_train, df_train["Frequency"], regressor__sample_weight=df_train["Exposure"]
)
print("PoissonRegressor evaluation:")
score_estimator(poisson_glm, df_test)
PoissonRegressor evaluation:
MSE: 0.560
MAE: 0.186
mean Poisson deviance: 0.594
泊松回归的梯度提升回归树#
最后,我们将考虑一个非线性模型,即梯度提升回归树。基于树的模型不需要对类别数据进行独热编码:相反,我们可以使用 OrdinalEncoder 将每个类别标签编码为任意整数。使用这种编码,树会将类别特征视为有序特征,这可能并不总是期望的行为。然而,对于足够深的树,这种影响是有限的,因为它们能够恢复特征的类别性质。与 OneHotEncoder 相比,OrdinalEncoder 的主要优势在于它可以加快训练速度。
梯度提升还可以使用泊松损失(带有隐式对数链接函数)来拟合树,而不是默认的最小二乘损失。在这里,我们只使用泊松损失来拟合树,以保持这个示例简洁。
from sklearn.ensemble import HistGradientBoostingRegressor
from sklearn.preprocessing import OrdinalEncoder
tree_preprocessor = ColumnTransformer(
[
(
"categorical",
OrdinalEncoder(),
["VehBrand", "VehPower", "VehGas", "Region", "Area"],
),
("numeric", "passthrough", ["VehAge", "DrivAge", "BonusMalus", "Density"]),
],
remainder="drop",
)
poisson_gbrt = Pipeline(
[
("preprocessor", tree_preprocessor),
(
"regressor",
HistGradientBoostingRegressor(loss="poisson", max_leaf_nodes=128),
),
]
)
poisson_gbrt.fit(
df_train, df_train["Frequency"], regressor__sample_weight=df_train["Exposure"]
)
print("Poisson Gradient Boosted Trees evaluation:")
score_estimator(poisson_gbrt, df_test)
Poisson Gradient Boosted Trees evaluation:
MSE: 0.565
MAE: 0.184
mean Poisson deviance: 0.575
与上述泊松广义线性模型类似,梯度提升树模型最小化泊松偏差。然而,由于更高的预测能力,它达到了更低的泊松偏差值。
使用单次训练/测试拆分来评估模型容易受到随机波动的影响。如果计算资源允许,应验证交叉验证的性能指标是否会得出类似的结论。
这些模型之间的定性差异也可以通过比较观测目标值的直方图与预测值的直方图来可视化:
fig, axes = plt.subplots(nrows=2, ncols=4, figsize=(16, 6), sharey=True)
fig.subplots_adjust(bottom=0.2)
n_bins = 20
for row_idx, label, df in zip(range(2), ["train", "test"], [df_train, df_test]):
df["Frequency"].hist(bins=np.linspace(-1, 30, n_bins), ax=axes[row_idx, 0])
axes[row_idx, 0].set_title("Data")
axes[row_idx, 0].set_yscale("log")
axes[row_idx, 0].set_xlabel("y (observed Frequency)")
axes[row_idx, 0].set_ylim([1e1, 5e5])
axes[row_idx, 0].set_ylabel(label + " samples")
for idx, model in enumerate([ridge_glm, poisson_glm, poisson_gbrt]):
y_pred = model.predict(df)
pd.Series(y_pred).hist(
bins=np.linspace(-1, 4, n_bins), ax=axes[row_idx, idx + 1]
)
axes[row_idx, idx + 1].set(
title=model[-1].__class__.__name__,
yscale="log",
xlabel="y_pred (predicted expected Frequency)",
)
plt.tight_layout()
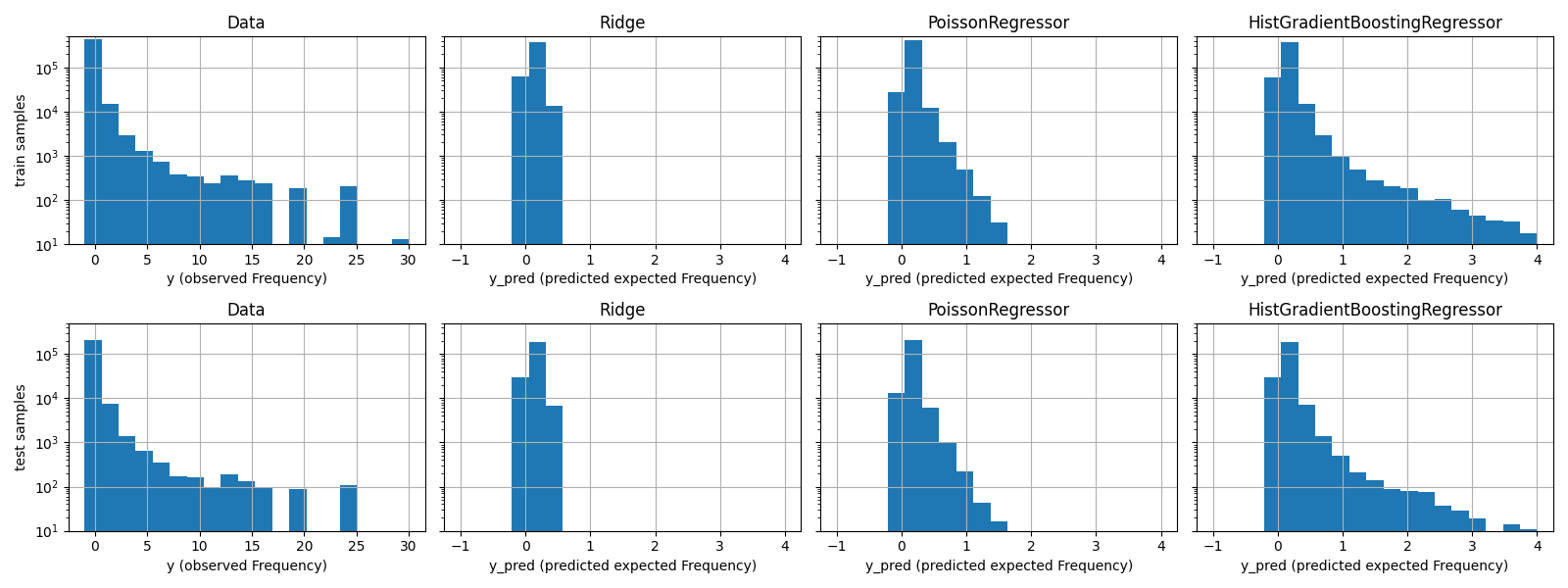
实验数据呈现出 y 的长尾分布。在所有模型中,我们预测随机变量的期望频率,因此极端值必然比观察到的该随机变量的实现值要少。这解释了为什么模型预测的直方图的众数不一定对应于最小值。此外, Ridge 中使用的正态分布具有恒定方差,而在 PoissonRegressor 和 HistGradientBoostingRegressor 中使用的泊松分布的方差与预测的期望值成正比。
因此,在所考虑的估计器中, PoissonRegressor 和 HistGradientBoostingRegressor 先验上更适合对非负数据的长尾分布进行建模,而相比之下, Ridge 模型对目标变量的分布做出了错误的假设。
HistGradientBoostingRegressor 估计器具有最大的灵活性,并且能够预测更高的期望值。
请注意,我们本可以对 HistGradientBoostingRegressor 模型使用最小二乘损失。这将错误地假设响应变量是正态分布的,就像 Ridge 模型一样,并且可能还会导致略微负的预测。然而,梯度提升树仍然会表现得相对较好,特别是由于树的灵活性和大量的训练样本,它们的表现会优于 PoissonRegressor 。
预测校准评估#
为了确保估计器对不同类型的保单持有人产生合理的预测,我们可以根据每个模型返回的 y_pred 对测试样本进行分箱。然后,对于每个箱,我们将平均预测 y_pred 与平均观察目标进行比较:
from sklearn.utils import gen_even_slices
def _mean_frequency_by_risk_group(y_true, y_pred, sample_weight=None, n_bins=100):
"""比较按 y_pred 排序的分箱中的预测值和观测值。
我们按 ``y_pred`` 对样本进行排序并将其分箱。
在每个分箱中,将观测到的均值与预测的均值进行比较。
Parameters
----------
y_true: array-like, 形状为 (n_samples,)
真实的(正确的)目标值。
y_pred: array-like, 形状为 (n_samples,)
估计的目标值。
sample_weight : array-like, 形状为 (n_samples,)
样本权重。
n_bins: int
使用的分箱数量。
返回
-------
bin_centers: ndarray, 形状为 (n_bins,)
分箱中心
y_true_bin: ndarray, 形状为 (n_bins,)
每个分箱的平均 y_true
y_pred_bin: ndarray, 形状为 (n_bins,)
每个分箱的平均 y_pred
"""
idx_sort = np.argsort(y_pred)
bin_centers = np.arange(0, 1, 1 / n_bins) + 0.5 / n_bins
y_pred_bin = np.zeros(n_bins)
y_true_bin = np.zeros(n_bins)
for n, sl in enumerate(gen_even_slices(len(y_true), n_bins)):
weights = sample_weight[idx_sort][sl]
y_pred_bin[n] = np.average(y_pred[idx_sort][sl], weights=weights)
y_true_bin[n] = np.average(y_true[idx_sort][sl], weights=weights)
return bin_centers, y_true_bin, y_pred_bin
print(f"Actual number of claims: {df_test['ClaimNb'].sum()}")
fig, ax = plt.subplots(nrows=2, ncols=2, figsize=(12, 8))
plt.subplots_adjust(wspace=0.3)
for axi, model in zip(ax.ravel(), [ridge_glm, poisson_glm, poisson_gbrt, dummy]):
y_pred = model.predict(df_test)
y_true = df_test["Frequency"].values
exposure = df_test["Exposure"].values
q, y_true_seg, y_pred_seg = _mean_frequency_by_risk_group(
y_true, y_pred, sample_weight=exposure, n_bins=10
)
# 管道最后一步中使用的估计器的模型名称。
print(f"Predicted number of claims by {model[-1]}: {np.sum(y_pred * exposure):.1f}")
axi.plot(q, y_pred_seg, marker="x", linestyle="--", label="predictions")
axi.plot(q, y_true_seg, marker="o", linestyle="--", label="observations")
axi.set_xlim(0, 1.0)
axi.set_ylim(0, 0.5)
axi.set(
title=model[-1],
xlabel="Fraction of samples sorted by y_pred",
ylabel="Mean Frequency (y_pred)",
)
axi.legend()
plt.tight_layout()
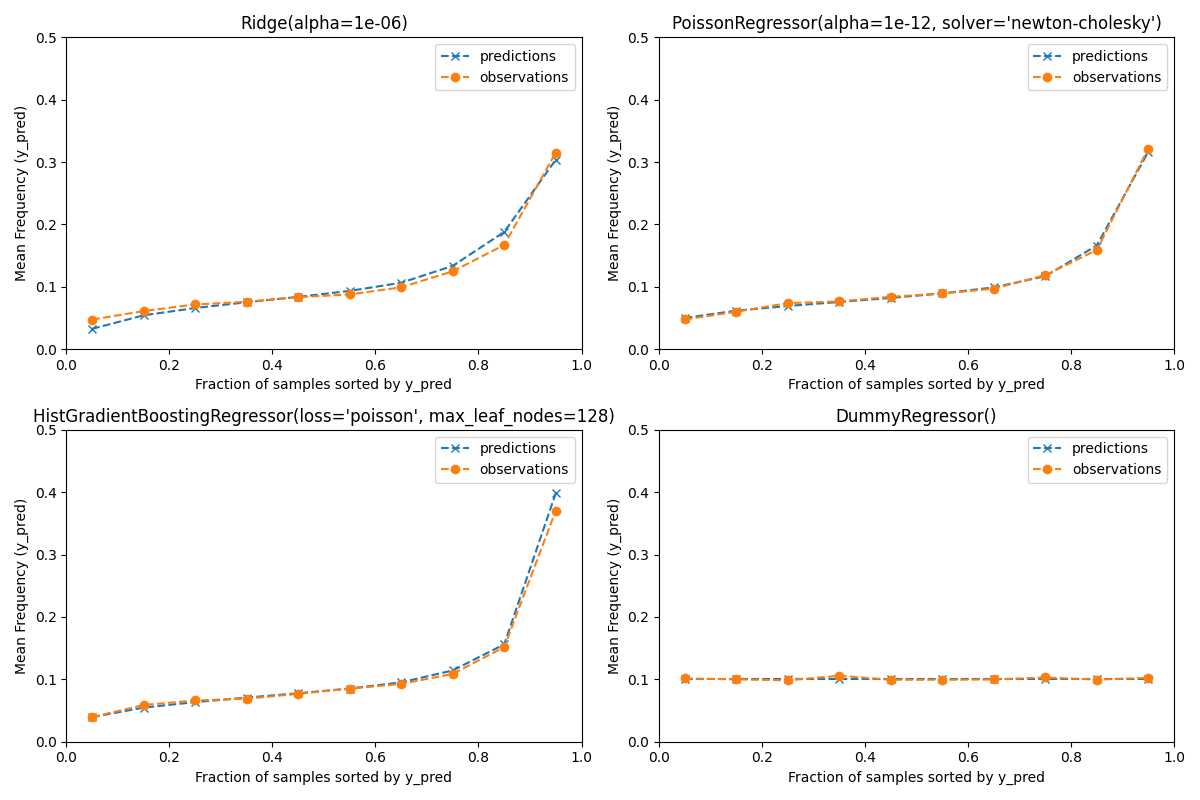
Actual number of claims: 11935
Predicted number of claims by Ridge(alpha=1e-06): 11933.4
Predicted number of claims by PoissonRegressor(alpha=1e-12, solver='newton-cholesky'): 11932.0
Predicted number of claims by HistGradientBoostingRegressor(loss='poisson', max_leaf_nodes=128): 12249.5
Predicted number of claims by DummyRegressor(): 11931.2
虚拟回归模型预测一个恒定的频率。该模型不会为所有样本分配相同的并列排名,但总体上仍然校准良好(用于估计整个群体的平均频率)。
Ridge 回归模型可能会预测出与数据不匹配的非常低的预期频率。因此,它可能会严重低估某些保单持有人的风险。
PoissonRegressor 和 HistGradientBoostingRegressor 在预测值和观测值之间表现出更好的一致性,尤其是对于较低的预测目标值。
所有预测的总和也证实了 Ridge 模型的校准问题:它低估了测试集中超过3%的索赔总数,而其他三个模型则可以大致恢复测试组合的索赔总数。
排名能力评估#
对于某些业务应用,我们对模型将最具风险的保单持有人与最安全的保单持有人进行排序的能力感兴趣,而不考虑预测的绝对值。在这种情况下,模型评估会将问题视为排序问题,而不是回归问题。
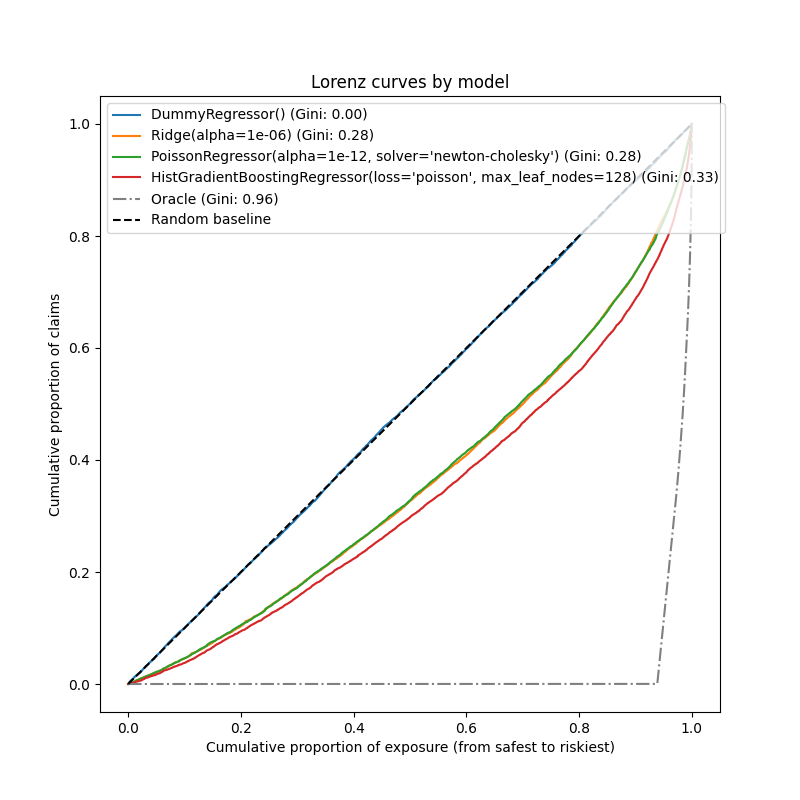
为了从这个角度比较这三个模型,可以绘制测试样本中按模型预测从最安全到最危险排序的累计索赔比例与累计暴露比例的图表。
这个图称为洛伦兹曲线,可以用基尼指数来概括:
from sklearn.metrics import auc
def lorenz_curve(y_true, y_pred, exposure):
y_true, y_pred = np.asarray(y_true), np.asarray(y_pred)
exposure = np.asarray(exposure)
# 按预测风险从低到高排序样本:
ranking = np.argsort(y_pred)
ranked_frequencies = y_true[ranking]
ranked_exposure = exposure[ranking]
cumulated_claims = np.cumsum(ranked_frequencies * ranked_exposure)
cumulated_claims /= cumulated_claims[-1]
cumulated_exposure = np.cumsum(ranked_exposure)
cumulated_exposure /= cumulated_exposure[-1]
return cumulated_exposure, cumulated_claims
fig, ax = plt.subplots(figsize=(8, 8))
for model in [dummy, ridge_glm, poisson_glm, poisson_gbrt]:
y_pred = model.predict(df_test)
cum_exposure, cum_claims = lorenz_curve(
df_test["Frequency"], y_pred, df_test["Exposure"]
)
gini = 1 - 2 * auc(cum_exposure, cum_claims)
label = "{} (Gini: {:.2f})".format(model[-1], gini)
ax.plot(cum_exposure, cum_claims, linestyle="-", label=label)
# Oracle model: y_pred == y_test
cum_exposure, cum_claims = lorenz_curve(
df_test["Frequency"], df_test["Frequency"], df_test["Exposure"]
)
gini = 1 - 2 * auc(cum_exposure, cum_claims)
label = "Oracle (Gini: {:.2f})".format(gini)
ax.plot(cum_exposure, cum_claims, linestyle="-.", color="gray", label=label)
# 随机基线
ax.plot([0, 1], [0, 1], linestyle="--", color="black", label="Random baseline")
ax.set(
title="Lorenz curves by model",
xlabel="Cumulative proportion of exposure (from safest to riskiest)",
ylabel="Cumulative proportion of claims",
)
ax.legend(loc="upper left")
<matplotlib.legend.Legend object at 0xffff883a9290>
正如预期的那样,虚拟回归器无法正确地对样本进行排序,因此在此图中表现最差。
基于树的模型在按风险对保单持有人进行排名方面显著更好,而两个线性模型的表现相似。
所有三个模型的表现都显著优于随机猜测,但距离完美预测仍有很大差距。
由于问题的性质,最后一点是预期的:事故的发生主要受环境因素的影响,这些因素并未在数据集的列中体现,确实可以被视为纯粹的随机事件。
线性模型假设输入变量之间没有交互,这可能导致欠拟合。插入多项式特征提取器(PolynomialFeatures )确实将其区分能力提高了2个基尼指数点。特别是,它提高了模型识别前5%最高风险档案的能力。
主要收获#
可以通过模型生成良好校准的预测和良好的排序能力来评估其性能。
可以通过绘制按预测风险分组的测试样本组的平均观测值与平均预测值来评估模型的校准情况。
岭回归模型的最小二乘损失(以及隐式使用的恒等链接函数)似乎导致该模型校准不佳。特别是,它倾向于低估风险,甚至可能预测无效的负频率。
使用具有对数链接的泊松损失可以纠正这些问题,并导致一个校准良好的线性模型。
基尼指数反映了模型对预测结果进行排序的能力,而不考虑其绝对值,因此仅评估其排序能力。
尽管校准有所改进,这两种线性模型的排序能力相当,并且远低于梯度提升回归树的排序能力。
作为评估指标计算的泊松偏差反映了模型的校准和排序能力。它还对期望值和响应变量的方差之间的理想关系做出了线性假设。为了简洁起见,我们没有检查这一假设是否成立。
传统的回归指标如均方误差和平均绝对误差在具有大量零值的计数值上难以进行有意义的解释。
plt.show()
Total running time of the script: (0 minutes 12.417 seconds)
Related examples