Note
Go to the end to download the full example code. or to run this example in your browser via Binder
RBF SVM 参数#
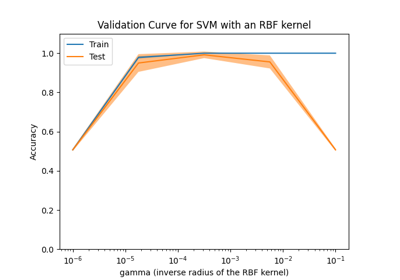
此示例说明了径向基函数(RBF)核 SVM 的参数 gamma 和 C 的影响。
直观地说, gamma 参数定义了单个训练样本的影响范围,较低的值意味着“远”,较高的值意味着“近”。 gamma 参数可以看作是模型选择的支持向量样本影响半径的倒数。
C参数在正确分类训练样本与最大化决策函数的间隔之间进行权衡。对于较大的C值,如果决策函数能更好地正确分类所有训练点,则会接受较小的间隔。较低的C值会鼓励较大的间隔,因此会得到一个更简单的决策函数,但代价是训练准确性。换句话说,C在 SVM 中表现为正则化参数。
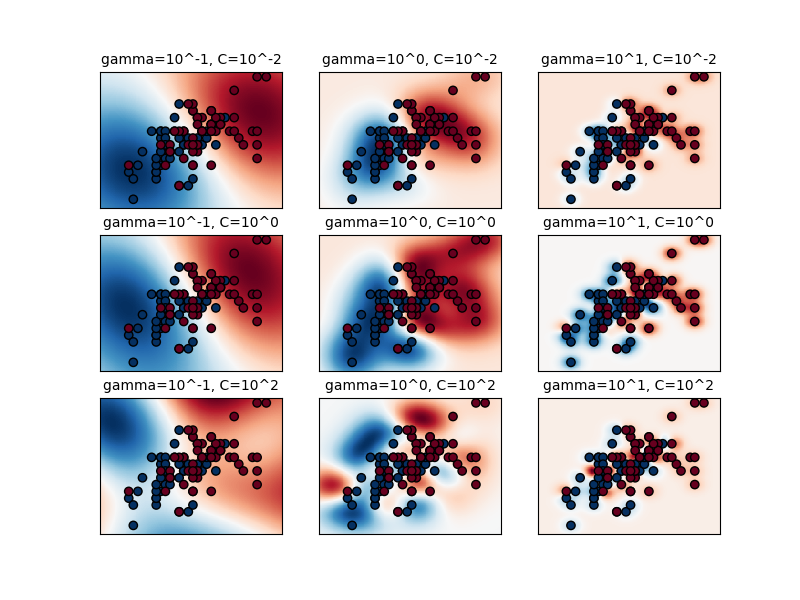
第一个图是对一个简化的分类问题中各种参数值的决策函数的可视化,该问题仅涉及 2 个输入特征和 2 个可能的目标类(二元分类)。请注意,对于具有更多特征或目标类的问题,这种类型的图是不可能绘制的。
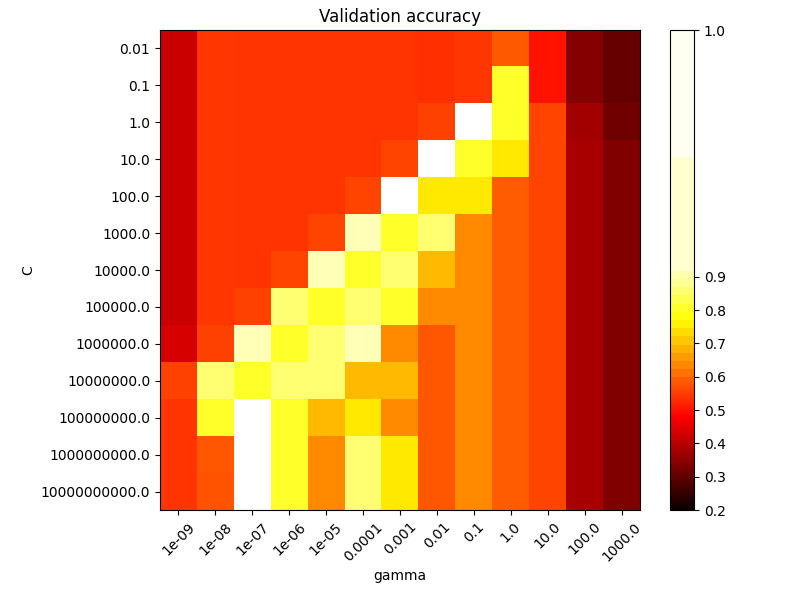
第二个图是分类器的交叉验证准确性作为 C 和 gamma 函数的热图。在此示例中,我们探索了一个相对较大的网格以进行说明。实际上,从 \(10^{-3}\) 到 \(10^3\) 的对数网格通常就足够了。如果最佳参数位于网格的边界上,可以在后续搜索中向该方向扩展。
请注意,热图具有一个特殊的颜色条,其中点值接近表现最佳模型的得分值,以便一眼就能区分它们。
模型的行为对 gamma 参数非常敏感。如果 gamma 太大,支持向量的影响区域仅包括支持向量本身,并且没有任何 C 的正则化能够防止过拟合。
当 gamma 非常小时,模型受到的约束太大,无法捕捉数据的复杂性或“形状”。任何选定支持向量的影响区域将包括整个训练集。结果模型的行为将类似于线性模型,具有一组分离任意两类高密度中心的超平面。
对于中间值,我们可以在第二个图中看到,在 C 和 gamma 的对角线上可以找到好的模型。通过增加正确分类每个点的重要性(较大的 C 值),可以使平滑模型(较低的 gamma 值)变得更复杂,因此形成了表现良好的模型的对角线。
最后,我们还可以观察到,对于某些中间值的 gamma ,当 C 变得非常大时,我们会得到同样表现的模型。这表明支持向量集不再变化。RBF 核的半径本身就作为一个很好的结构正则化器。进一步增加 C 并没有帮助,可能是因为没有更多的训练点违反(在间隔内或分类错误),或者至少找不到更好的解决方案。得分相等的情况下,使用较小的 C 值可能更有意义,因为非常高的 C 值通常会增加拟合时间。
另一方面,较低的 C 值通常会导致更多的支持向量,这可能会增加预测时间。因此,降低 C 值涉及拟合时间和预测时间之间的权衡。
我们还应注意,得分的微小差异是由于交叉验证过程的随机分割造成的。这些虚假的变化可以通过增加 CV 迭代次数 n_splits 来平滑,但代价是计算时间。增加 C_range 和 gamma_range 步数的值将增加超参数热图的分辨率。
实用类,用于将颜色映射的中点移动到感兴趣的值附近。
import numpy as np
from matplotlib.colors import Normalize
class MidpointNormalize(Normalize):
def __init__(self, vmin=None, vmax=None, midpoint=None, clip=False):
self.midpoint = midpoint
Normalize.__init__(self, vmin, vmax, clip)
def __call__(self, value, clip=None):
x, y = [self.vmin, self.midpoint, self.vmax], [0, 0.5, 1]
return np.ma.masked_array(np.interp(value, x, y))
加载和准备数据集#
网格搜索的数据集
用于决策函数可视化的数据集:我们只保留X中的前两个特征,并对数据集进行子采样以仅保留两个类别,使其成为一个二分类问题。
X_2d = X[:, :2]
X_2d = X_2d[y > 0]
y_2d = y[y > 0]
y_2d -= 1
通常情况下,在进行SVM训练时对数据进行缩放是一个好主意。在这个例子中,我们有点作弊了,因为我们对所有数据进行了缩放,而不是在训练集上拟合转换并仅在测试集上应用它。
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
X = scaler.fit_transform(X)
X_2d = scaler.fit_transform(X_2d)
训练分类器#
对于初始搜索,使用以10为底的对数网格通常是有帮助的。使用以2为底的网格可以实现更精细的调整,但代价要高得多。
from sklearn.model_selection import GridSearchCV, StratifiedShuffleSplit
from sklearn.svm import SVC
C_range = np.logspace(-2, 10, 13)
gamma_range = np.logspace(-9, 3, 13)
param_grid = dict(gamma=gamma_range, C=C_range)
cv = StratifiedShuffleSplit(n_splits=5, test_size=0.2, random_state=42)
grid = GridSearchCV(SVC(), param_grid=param_grid, cv=cv)
grid.fit(X, y)
print(
"The best parameters are %s with a score of %0.2f"
% (grid.best_params_, grid.best_score_)
)
The best parameters are {'C': np.float64(1.0), 'gamma': np.float64(0.1)} with a score of 0.97
现在我们需要为二维版本中的所有参数拟合一个分类器(这里我们使用较小的参数集,因为训练需要一些时间)
C_2d_range = [1e-2, 1, 1e2]
gamma_2d_range = [1e-1, 1, 1e1]
classifiers = []
for C in C_2d_range:
for gamma in gamma_2d_range:
clf = SVC(C=C, gamma=gamma)
clf.fit(X_2d, y_2d)
classifiers.append((C, gamma, clf))
可视化#
绘制参数影响的可视化图
import matplotlib.pyplot as plt
plt.figure(figsize=(8, 6))
xx, yy = np.meshgrid(np.linspace(-3, 3, 200), np.linspace(-3, 3, 200))
for k, (C, gamma, clf) in enumerate(classifiers):
# 在网格中评估决策函数
Z = clf.decision_function(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
# 可视化这些参数的决策函数
plt.subplot(len(C_2d_range), len(gamma_2d_range), k + 1)
plt.title("gamma=10^%d, C=10^%d" % (np.log10(gamma), np.log10(C)), size="medium")
# 可视化参数对决策函数的影响
plt.pcolormesh(xx, yy, -Z, cmap=plt.cm.RdBu)
plt.scatter(X_2d[:, 0], X_2d[:, 1], c=y_2d, cmap=plt.cm.RdBu_r, edgecolors="k")
plt.xticks(())
plt.yticks(())
plt.axis("tight")
scores = grid.cv_results_["mean_test_score"].reshape(len(C_range), len(gamma_range))
绘制验证准确率随 gamma 和 C 变化的热图
分数被编码为颜色,使用从深红色到亮黄色变化的热图颜色映射。由于最有趣的分数都位于0.92到0.97范围内,我们使用自定义归一化器将中点设置为0.92,以便更容易地可视化该范围内分数值的小变化,同时不会将所有低分值粗暴地压缩为相同的颜色。
plt.figure(figsize=(8, 6))
plt.subplots_adjust(left=0.2, right=0.95, bottom=0.15, top=0.95)
plt.imshow(
scores,
interpolation="nearest",
cmap=plt.cm.hot,
norm=MidpointNormalize(vmin=0.2, midpoint=0.92),
)
plt.xlabel("gamma")
plt.ylabel("C")
plt.colorbar()
plt.xticks(np.arange(len(gamma_range)), gamma_range, rotation=45)
plt.yticks(np.arange(len(C_range)), C_range)
plt.title("Validation accuracy")
plt.show()
Total running time of the script: (0 minutes 2.685 seconds)
Related examples