Note
Go to the end to download the full example code. or to run this example in your browser via Binder
谱聚类算法演示#
此示例演示如何生成数据集并使用谱聚类算法进行双聚类。
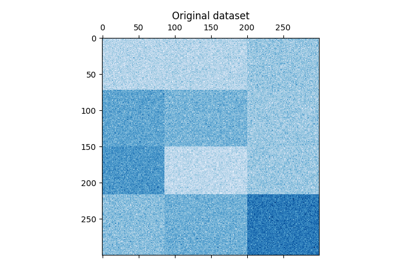
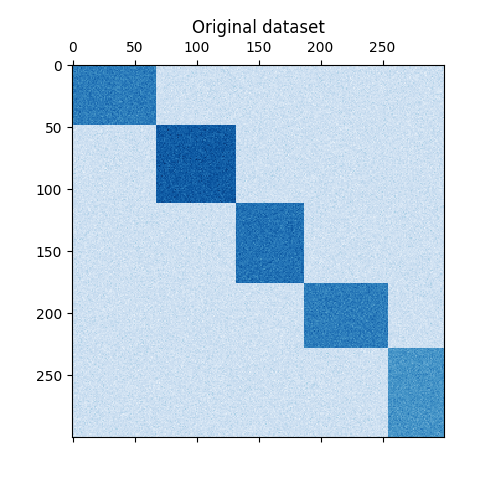
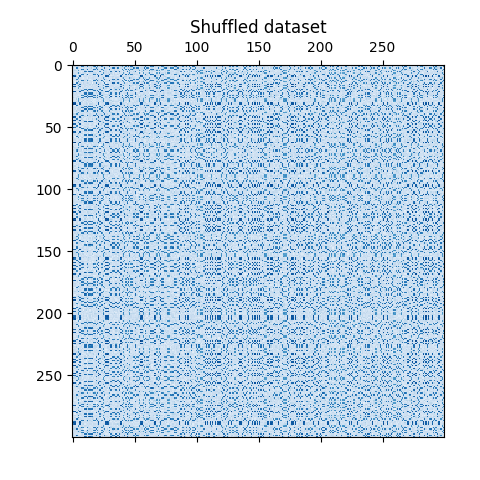
数据集使用 make_biclusters 函数生成,该函数创建一个包含小值的矩阵,并在其中植入包含大值的双聚类。然后对行和列进行洗牌,并传递给谱聚类算法。重新排列洗牌后的矩阵以使双聚类连续,展示了算法如何准确地找到双聚类。
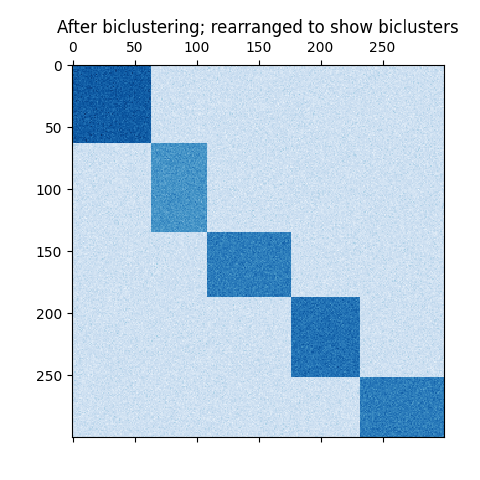
consensus score: 1.000
# 作者:scikit-learn开发者
# SPDX许可证标识:BSD-3-Clause
import numpy as np
from matplotlib import pyplot as plt
from sklearn.cluster import SpectralCoclustering
from sklearn.datasets import make_biclusters
from sklearn.metrics import consensus_score
data, rows, columns = make_biclusters(
shape=(300, 300), n_clusters=5, noise=5, shuffle=False, random_state=0
)
plt.matshow(data, cmap=plt.cm.Blues)
plt.title("Original dataset")
# shuffle clusters
rng = np.random.RandomState(0)
row_idx = rng.permutation(data.shape[0])
col_idx = rng.permutation(data.shape[1])
data = data[row_idx][:, col_idx]
plt.matshow(data, cmap=plt.cm.Blues)
plt.title("Shuffled dataset")
model = SpectralCoclustering(n_clusters=5, random_state=0)
model.fit(data)
score = consensus_score(model.biclusters_, (rows[:, row_idx], columns[:, col_idx]))
print("consensus score: {:.3f}".format(score))
fit_data = data[np.argsort(model.row_labels_)]
fit_data = fit_data[:, np.argsort(model.column_labels_)]
plt.matshow(fit_data, cmap=plt.cm.Blues)
plt.title("After biclustering; rearranged to show biclusters")
plt.show()
Total running time of the script: (0 minutes 0.178 seconds)
Related examples