Note
Go to the end to download the full example code. or to run this example in your browser via Binder
归纳聚类#
聚类可能是昂贵的,特别是当我们的数据集包含数百万个数据点时。许多聚类算法不是归纳的,因此不能直接应用于新数据样本,而无需重新计算聚类,这可能是不可行的。相反,我们可以使用聚类来学习一个带有分类器的归纳模型,这有几个好处:
它允许聚类扩展并应用于新数据
与重新拟合新样本的聚类不同,它确保了标记过程在时间上的一致性
它允许我们使用分类器的推理能力来描述或解释聚类
这个例子展示了一个元估计器的通用实现,它通过从聚类标签中引入分类器来扩展聚类。
# 作者: Chirag Nagpal
# Christos Aridas
import matplotlib.pyplot as plt
from sklearn.base import BaseEstimator, clone
from sklearn.cluster import AgglomerativeClustering
from sklearn.datasets import make_blobs
from sklearn.ensemble import RandomForestClassifier
from sklearn.inspection import DecisionBoundaryDisplay
from sklearn.utils.metaestimators import available_if
from sklearn.utils.validation import check_is_fitted
N_SAMPLES = 5000
RANDOM_STATE = 42
def _classifier_has(attr):
"""检查是否可以将方法委托给底层分类器。
首先,我们检查第一个已拟合的分类器(如果有),否则我们检查未拟合的分类器。
"""
return lambda estimator: (
hasattr(estimator.classifier_, attr)
if hasattr(estimator, "classifier_")
else hasattr(estimator.classifier, attr)
)
class InductiveClusterer(BaseEstimator):
def __init__(self, clusterer, classifier):
self.clusterer = clusterer
self.classifier = classifier
def fit(self, X, y=None):
self.clusterer_ = clone(self.clusterer)
self.classifier_ = clone(self.classifier)
y = self.clusterer_.fit_predict(X)
self.classifier_.fit(X, y)
return self
@available_if(_classifier_has("predict"))
def predict(self, X):
check_is_fitted(self)
return self.classifier_.predict(X)
@available_if(_classifier_has("decision_function"))
def decision_function(self, X):
check_is_fitted(self)
return self.classifier_.decision_function(X)
def plot_scatter(X, color, alpha=0.5):
return plt.scatter(X[:, 0], X[:, 1], c=color, alpha=alpha, edgecolor="k")
# 从聚类中生成一些训练数据
X, y = make_blobs(
n_samples=N_SAMPLES,
cluster_std=[1.0, 1.0, 0.5],
centers=[(-5, -5), (0, 0), (5, 5)],
random_state=RANDOM_STATE,
)
# 在训练数据上训练一个聚类算法并获取聚类标签
clusterer = AgglomerativeClustering(n_clusters=3)
cluster_labels = clusterer.fit_predict(X)
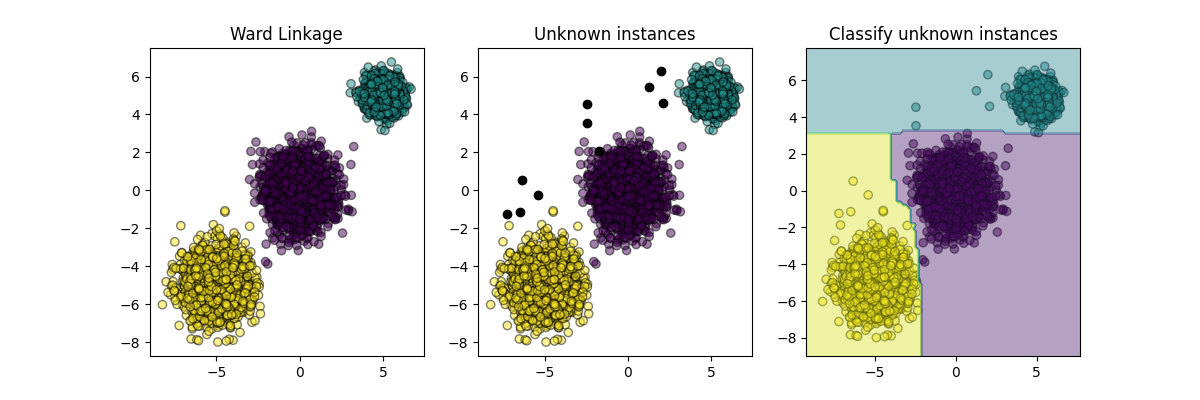
plt.figure(figsize=(12, 4))
plt.subplot(131)
plot_scatter(X, cluster_labels)
plt.title("Ward Linkage")
# 生成新样本并将其与原始数据集一起绘制
X_new, y_new = make_blobs(
n_samples=10, centers=[(-7, -1), (-2, 4), (3, 6)], random_state=RANDOM_STATE
)
plt.subplot(132)
plot_scatter(X, cluster_labels)
plot_scatter(X_new, "black", 1)
plt.title("Unknown instances")
# 声明归纳学习模型,该模型将用于预测未知实例的聚类归属。
classifier = RandomForestClassifier(random_state=RANDOM_STATE)
inductive_learner = InductiveClusterer(clusterer, classifier).fit(X)
probable_clusters = inductive_learner.predict(X_new)
ax = plt.subplot(133)
plot_scatter(X, cluster_labels)
plot_scatter(X_new, probable_clusters)
# Plotting decision regions
DecisionBoundaryDisplay.from_estimator(
inductive_learner, X, response_method="predict", alpha=0.4, ax=ax
)
plt.title("Classify unknown instances")
plt.show()
Total running time of the script: (0 minutes 1.250 seconds)
Related examples