Note
Go to the end to download the full example code. or to run this example in your browser via Binder
scikit-learn 1.0 版本发布亮点#
我们非常高兴地宣布发布 scikit-learn 1.0 版本!该库已经稳定了一段时间,发布 1.0 版本是对这一点的认可,并向我们的用户传达这一信息。此次发布除了通常的两个版本弃用周期外,不包含任何重大变更。未来,我们将尽力保持这一模式。
此次发布包括一些新的关键特性以及许多改进和错误修复。我们在下面详细介绍了此次发布的一些主要特性。 有关所有更改的详尽列表 ,请参阅 发布说明 。
要安装最新版本(使用 pip):
pip install --upgrade scikit-learn
或使用 conda:
conda install -c conda-forge scikit-learn
关键词和位置参数#
scikit-learn API 公开了许多具有多个输入参数的函数和方法。例如,在此版本之前,可以实例化一个 HistGradientBoostingRegressor 如下:
HistGradientBoostingRegressor(“平方误差”, 0.1, 100, 31, 无, 20, 0.0, 255, 无, 无, 假, “自动”, “损失”, 0.1, 10, 1e-7, 0, 无)
理解上述代码需要读者查阅API文档,并检查每个参数的位置及其含义。为了提高基于scikit-learn编写的代码的可读性,现在用户必须提供大多数参数的名称,作为关键字参数,而不是位置参数。例如,上述代码将是:
HistGradientBoostingRegressor( 损失函数=”squared_error”, 学习率=0.1, 最大迭代次数=100, 最大叶节点数=31, 最大深度=None, 最小样本叶子数=20, L2正则化=0.0, 最大分箱数=255, 分类特征=None, 单调约束=None, 热启动=False, 提前停止=”auto”, 评分=”loss”, 验证集比例=0.1, 无变化迭代次数=10, 容差=1e-7, 详细程度=0, 随机状态=None, )
这使得代码更加易读。位置参数自0.23版本起已被弃用,现在会引发 TypeError 。在某些情况下,仍允许使用有限数量的位置参数,例如在:class:~decomposition.PCA 中, PCA(10) 仍然被允许,但 PCA(10, False) 则不被允许。
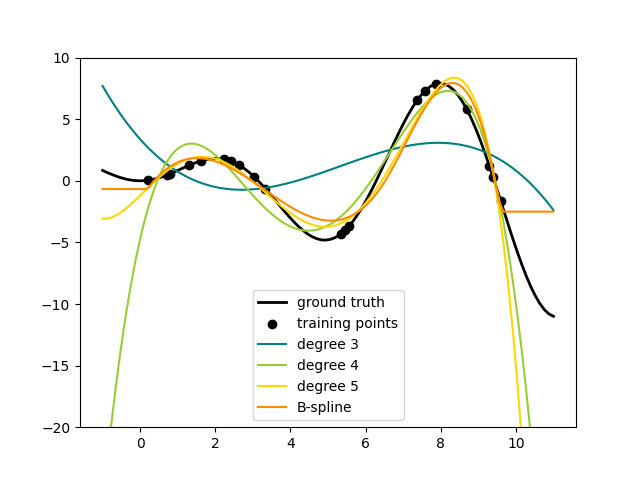
样条变换器#
向数据集的特征集中添加非线性项的一种方法是为连续/数值特征生成样条基函数,使用新的:class:~preprocessing.SplineTransformer 。样条是分段多项式,由其多项式次数和节点位置参数化。SplineTransformer 实现了B样条基函数。
- target:
../linear_model/plot_polynomial_interpolation.html
- align:
center
以下代码展示了样条的实际应用,更多信息请参考:用户指南 。
import numpy as np
from sklearn.preprocessing import SplineTransformer
X = np.arange(5).reshape(5, 1)
spline = SplineTransformer(degree=2, n_knots=3)
spline.fit_transform(X)
array([[0.5 , 0.5 , 0. , 0. ],
[0.125, 0.75 , 0.125, 0. ],
[0. , 0.5 , 0.5 , 0. ],
[0. , 0.125, 0.75 , 0.125],
[0. , 0. , 0.5 , 0.5 ]])
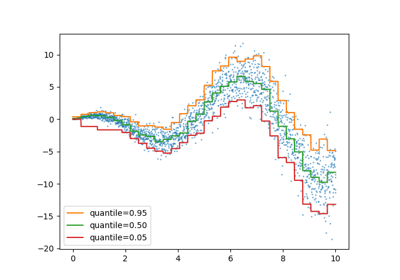
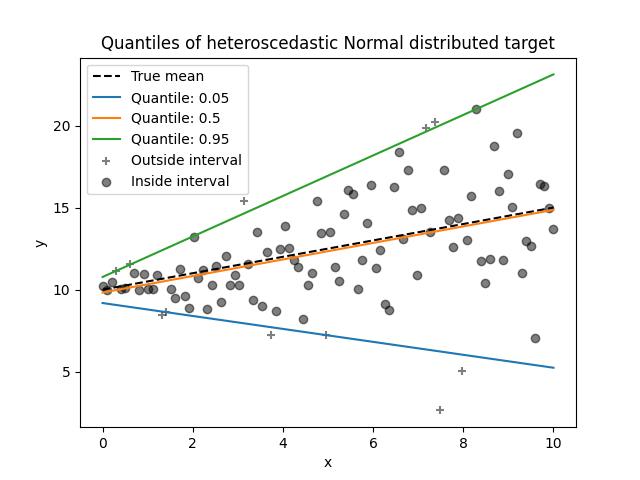
分位数回归#
分位数回归估计条件在 \(X\) 上的 \(y\) 的中位数或其他分位数,而普通最小二乘法 (OLS) 估计条件均值。
作为一个线性模型,新的 QuantileRegressor 为 \(q\) 分位数 \(q \in (0, 1)\) 提供线性预测 \(\hat{y}(w, X) = Xw\) 。权重或系数 \(w\) 通过以下最小化问题求得:
min_{w} {frac{1}{n_{text{samples}}} sum_i PB_q(y_i - X_i w) + alpha ||w||_1}.
这包括弹球损失(也称为线性损失),
另请参见 mean_pinball_loss ,
PB_q(t) = q max(t, 0) + (1 - q) max(-t, 0) = begin{cases} q t, & t > 0, \ 0, & t = 0, \ (1-q) t, & t < 0 end{cases}
以及由参数 alpha 控制的 L1 惩罚,类似于 linear_model.Lasso 。
请查看以下示例以了解其工作原理,更多详细信息请参阅:用户指南 。
- target:
../linear_model/plot_quantile_regression.html
- align:
center
- scale:
50%
特征名称支持#
当估计器在:term:fit 期间传入一个 pandas 数据框
<https://pandas.pydata.org/docs/user_guide/dsintro.htmldataframe> _时,
估计器将设置一个包含特征名称的 feature_names_in_ 属性。请注意,特征名称支持仅在数据框中的列名全部为字符串时启用。 feature_names_in_ 用于检查在非:term: fit 期间(如:term: predict )传入的数据框的列名是否与:term: fit `中的特征一致。
from sklearn.preprocessing import StandardScaler
import pandas as pd
X = pd.DataFrame([[1, 2, 3], [4, 5, 6]], columns=["a", "b", "c"])
scalar = StandardScaler().fit(X)
scalar.feature_names_in_
array(['a', 'b', 'c'], dtype=object)
:term:` get_feature_names_out 的支持适用于已经具有 get_feature_names 的转换器以及输入和输出之间存在一对一对应关系的转换器,例如 :class: ~preprocessing.StandardScaler ` 。在未来的版本中,所有其他转换器都将添加 :term:` get_feature_names_out 的支持。此外,:meth: compose.ColumnTransformer.get_feature_names_out`也可以用于组合其转换器的特征名称:
from sklearn.compose import ColumnTransformer
from sklearn.preprocessing import OneHotEncoder
import pandas as pd
X = pd.DataFrame({"pet": ["dog", "cat", "fish"], "age": [3, 7, 1]})
preprocessor = ColumnTransformer(
[
("numerical", StandardScaler(), ["age"]),
("categorical", OneHotEncoder(), ["pet"]),
],
verbose_feature_names_out=False,
).fit(X)
preprocessor.get_feature_names_out()
array(['age', 'pet_cat', 'pet_dog', 'pet_fish'], dtype=object)
当此 预处理器 与管道一起使用时,分类器使用的特征名称通过切片和调用:term:get_feature_names_out 获得:
from sklearn.linear_model import LogisticRegression
from sklearn.pipeline import make_pipeline
y = [1, 0, 1]
pipe = make_pipeline(preprocessor, LogisticRegression())
pipe.fit(X, y)
pipe[:-1].get_feature_names_out()
array(['age', 'pet_cat', 'pet_dog', 'pet_fish'], dtype=object)
一个更灵活的绘图API#
metrics.ConfusionMatrixDisplay 、metrics.PrecisionRecallDisplay 、metrics.DetCurveDisplay 和:class:inspection.PartialDependenceDisplay 现在公开了两个类方法: from_estimator 和 from_predictions ,允许用户根据预测结果或估计器创建图表。这意味着相应的 plot_* 函数已被弃用。请查看:ref:示例一<sphx_glr_auto_examples_model_selection_plot_confusion_matrix.py> 和:ref:示例二<sphx_glr_auto_examples_classification_plot_digits_classification.py> 了解如何使用新的绘图功能。
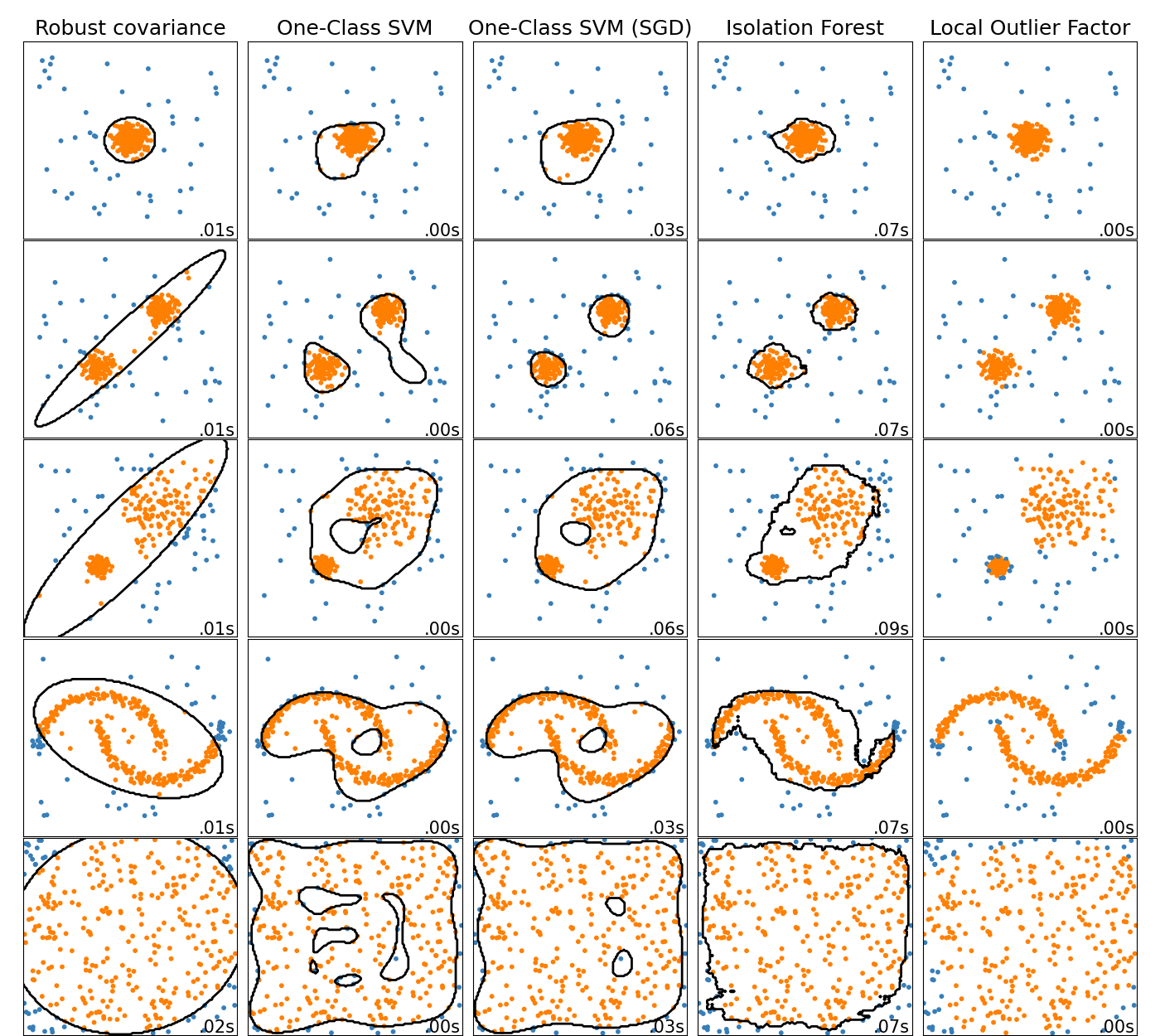
在线单类支持向量机#
新的类 SGDOneClassSVM 实现了使用随机梯度下降的在线线性单类支持向量机。结合核近似技术,SGDOneClassSVM 可以用来近似核化单类支持向量机(在 OneClassSVM 中实现)的解,其拟合时间复杂度与样本数量呈线性关系。注意,核化单类支持向量机的复杂度在最佳情况下与样本数量呈二次方关系。因此,SGDOneClassSVM 非常适合用于训练样本数量较大的数据集(> 10,000),对于这些数据集,SGD 变体的速度可以快几个数量级。请查看这个 示例 了解其用法,以及 用户指南 获取更多细节。
- target:
../miscellaneous/plot_anomaly_comparison.html
- align:
center
基于直方图的梯度提升模型现在已经稳定#
HistGradientBoostingRegressor 和
HistGradientBoostingClassifier 不再是实验性的,
可以直接导入并使用,如下所示:
from sklearn.ensemble import HistGradientBoostingClassifier
新的文档改进#
此版本包含许多文档改进。在合并的2100多个拉取请求中,大约有800个是对我们文档的改进。
Total running time of the script: (0 minutes 0.009 seconds)
Related examples