Note
Go to the end to download the full example code. or to run this example in your browser via Binder
邻域成分分析示例#
本示例展示了一种学习到的距离度量,该度量最大化了最近邻分类的准确性。它提供了与原始点空间相比的这种度量的可视化表示。更多信息请参阅 用户指南 。
# SPDX-License-Identifier: BSD-3-Clause
import matplotlib.pyplot as plt
import numpy as np
from matplotlib import cm
from scipy.special import logsumexp
from sklearn.datasets import make_classification
from sklearn.neighbors import NeighborhoodComponentsAnalysis
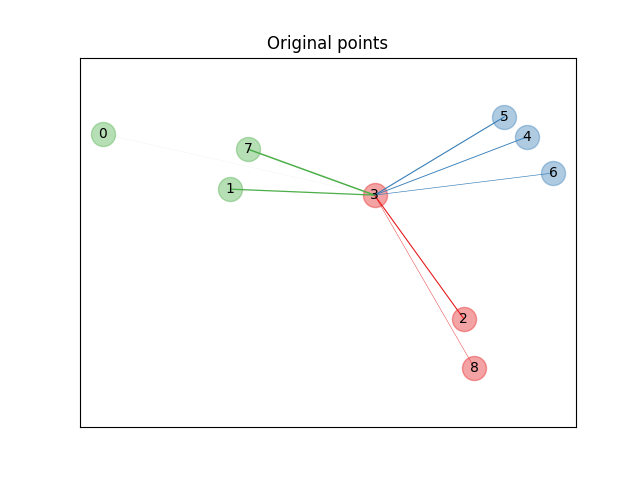
原始点#
首先,我们创建一个包含来自3个类别的9个样本的数据集,并在原始空间中绘制这些点。在这个例子中,我们重点关注点3的分类。点3与其他点之间的连线粗细与它们之间的距离成正比。
X, y = make_classification(
n_samples=9,
n_features=2,
n_informative=2,
n_redundant=0,
n_classes=3,
n_clusters_per_class=1,
class_sep=1.0,
random_state=0,
)
plt.figure(1)
ax = plt.gca()
for i in range(X.shape[0]):
ax.text(X[i, 0], X[i, 1], str(i), va="center", ha="center")
ax.scatter(X[i, 0], X[i, 1], s=300, c=cm.Set1(y[[i]]), alpha=0.4)
ax.set_title("Original points")
ax.axes.get_xaxis().set_visible(False)
ax.axes.get_yaxis().set_visible(False)
ax.axis("equal") # so that boundaries are displayed correctly as circles
def link_thickness_i(X, i):
diff_embedded = X[i] - X
dist_embedded = np.einsum("ij,ij->i", diff_embedded, diff_embedded)
dist_embedded[i] = np.inf
# 计算指数化距离(使用对数-和-指数技巧以避免数值不稳定性)
exp_dist_embedded = np.exp(-dist_embedded - logsumexp(-dist_embedded))
return exp_dist_embedded
def relate_point(X, i, ax):
pt_i = X[i]
for j, pt_j in enumerate(X):
thickness = link_thickness_i(X, i)
if i != j:
line = ([pt_i[0], pt_j[0]], [pt_i[1], pt_j[1]])
ax.plot(*line, c=cm.Set1(y[j]), linewidth=5 * thickness[j])
i = 3
relate_point(X, i, ax)
plt.show()
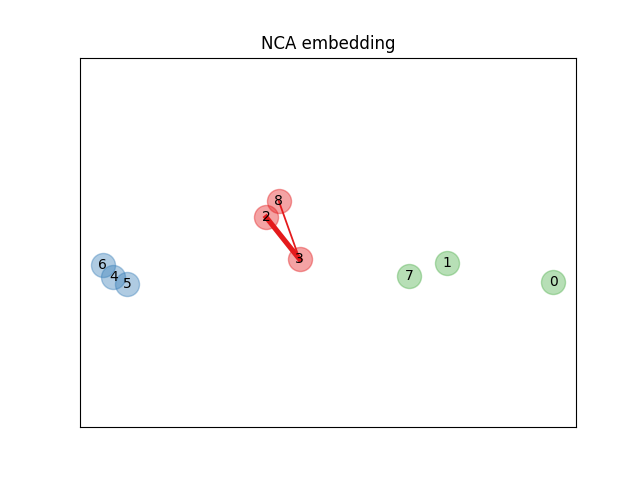
学习嵌入#
我们使用 NeighborhoodComponentsAnalysis 来学习一个嵌入,并在转换后绘制点。然后我们使用该嵌入来找到最近的邻居。
nca = NeighborhoodComponentsAnalysis(max_iter=30, random_state=0)
nca = nca.fit(X, y)
plt.figure(2)
ax2 = plt.gca()
X_embedded = nca.transform(X)
relate_point(X_embedded, i, ax2)
for i in range(len(X)):
ax2.text(X_embedded[i, 0], X_embedded[i, 1], str(i), va="center", ha="center")
ax2.scatter(X_embedded[i, 0], X_embedded[i, 1], s=300, c=cm.Set1(y[[i]]), alpha=0.4)
ax2.set_title("NCA embedding")
ax2.axes.get_xaxis().set_visible(False)
ax2.axes.get_yaxis().set_visible(False)
ax2.axis("equal")
plt.show()
Total running time of the script: (0 minutes 0.066 seconds)
Related examples