Note
Go to the end to download the full example code. or to run this example in your browser via Binder
通过代价复杂度剪枝对决策树进行后剪枝#
DecisionTreeClassifier 提供了诸如 min_samples_leaf 和 max_depth 等参数来防止树过拟合。代价复杂度剪枝提供了另一种控制树大小的选项。在 DecisionTreeClassifier 中,这种剪枝技术由代价复杂度参数 ccp_alpha 参数化。较大的 ccp_alpha 值会增加被剪枝的节点数量。这里我们仅展示 ccp_alpha 对正则化树的影响以及如何根据验证分数选择 ccp_alpha 。
有关剪枝的详细信息,请参见 最小成本复杂度剪枝 。
import matplotlib.pyplot as plt
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
叶子总杂质与修剪树的有效alpha值#
最小成本复杂度修剪递归地找到具有“最弱链接”的节点。最弱链接的特征在于一个有效的alpha值,其中具有最小有效alpha值的节点首先被修剪。为了了解哪些 ccp_alpha 值可能是合适的,scikit-learn提供了 DecisionTreeClassifier.cost_complexity_pruning_path ,该函数返回修剪过程每一步的有效alpha值和相应的叶子总杂质。随着alpha值的增加,树的修剪程度增加,这会增加其叶子的总杂质。
X, y = load_breast_cancer(return_X_y=True)
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=0)
clf = DecisionTreeClassifier(random_state=0)
path = clf.cost_complexity_pruning_path(X_train, y_train)
ccp_alphas, impurities = path.ccp_alphas, path.impurities
在下图中,最大有效 alpha 值被移除,因为它是只有一个节点的简单树。
fig, ax = plt.subplots()
ax.plot(ccp_alphas[:-1], impurities[:-1], marker="o", drawstyle="steps-post")
ax.set_xlabel("effective alpha")
ax.set_ylabel("total impurity of leaves")
ax.set_title("Total Impurity vs effective alpha for training set")
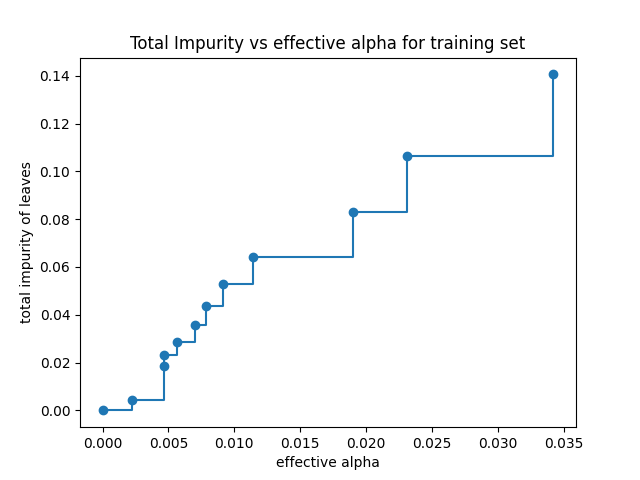
Text(0.5, 1.0, 'Total Impurity vs effective alpha for training set')
接下来,我们使用有效的 alpha 值训练决策树。 ccp_alphas 中的最后一个值是修剪整个树的 alpha 值,使得树 clfs[-1] 只剩下一个节点。
clfs = []
for ccp_alpha in ccp_alphas:
clf = DecisionTreeClassifier(random_state=0, ccp_alpha=ccp_alpha)
clf.fit(X_train, y_train)
clfs.append(clf)
print(
"Number of nodes in the last tree is: {} with ccp_alpha: {}".format(
clfs[-1].tree_.node_count, ccp_alphas[-1]
)
)
Number of nodes in the last tree is: 1 with ccp_alpha: 0.3272984419327777
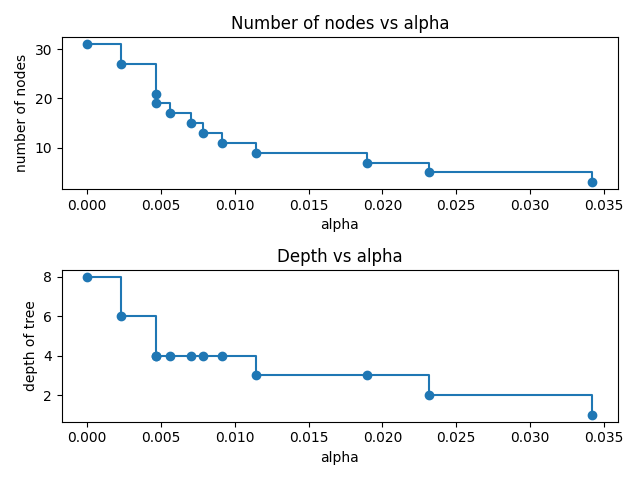
在本示例的剩余部分中,我们移除 clfs 和 ccp_alphas 中的最后一个元素,因为它是只有一个节点的简单树。这里我们展示了随着alpha增加,节点数量和树的深度如何减少。
clfs = clfs[:-1]
ccp_alphas = ccp_alphas[:-1]
node_counts = [clf.tree_.node_count for clf in clfs]
depth = [clf.tree_.max_depth for clf in clfs]
fig, ax = plt.subplots(2, 1)
ax[0].plot(ccp_alphas, node_counts, marker="o", drawstyle="steps-post")
ax[0].set_xlabel("alpha")
ax[0].set_ylabel("number of nodes")
ax[0].set_title("Number of nodes vs alpha")
ax[1].plot(ccp_alphas, depth, marker="o", drawstyle="steps-post")
ax[1].set_xlabel("alpha")
ax[1].set_ylabel("depth of tree")
ax[1].set_title("Depth vs alpha")
fig.tight_layout()
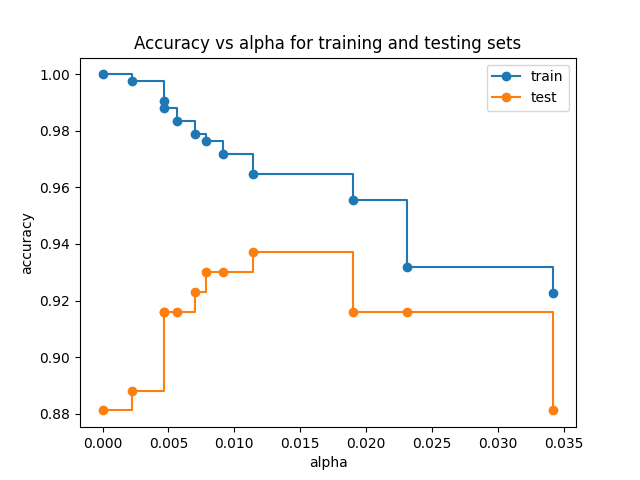
训练集和测试集的准确率与alpha的关系#
当 ccp_alpha 设置为零并保持 DecisionTreeClassifier 的其他默认参数时,树会过拟合,导致训练集的准确率为100%,测试集的准确率为88%。随着alpha的增加,树的修剪程度增加,从而创建一个泛化能力更强的决策树。在这个例子中,设置 ccp_alpha=0.015 可以最大化测试集的准确率。
train_scores = [clf.score(X_train, y_train) for clf in clfs]
test_scores = [clf.score(X_test, y_test) for clf in clfs]
fig, ax = plt.subplots()
ax.set_xlabel("alpha")
ax.set_ylabel("accuracy")
ax.set_title("Accuracy vs alpha for training and testing sets")
ax.plot(ccp_alphas, train_scores, marker="o", label="train", drawstyle="steps-post")
ax.plot(ccp_alphas, test_scores, marker="o", label="test", drawstyle="steps-post")
ax.legend()
plt.show()
Total running time of the script: (0 minutes 0.374 seconds)
Related examples