Note
Go to the end to download the full example code. or to run this example in your browser via Binder
scikit-learn 1.2 版本发布亮点#
我们很高兴地宣布发布 scikit-learn 1.2 版本!此版本包含许多错误修复和改进,以及一些新的关键功能。以下是本次发布的一些主要功能。 有关所有更改的详尽列表 ,请参阅 发布说明 。
要安装最新版本(使用 pip):
pip install --upgrade scikit-learn
或使用 conda:
conda install -c conda-forge scikit-learn
Pandas输出与 set_output API#
scikit-learn的转换器现在支持通过 set_output API输出pandas格式的数据。
要了解更多关于 set_output API的信息,请参见示例:
介绍 set_output API 和
这个 `视频,scikit-learn转换器的pandas DataFrame输出(一些示例)<https://youtu.be/5bCg8VfX2x8>`_ _。
import numpy as np
from sklearn.datasets import load_iris
from sklearn.preprocessing import StandardScaler, KBinsDiscretizer
from sklearn.compose import ColumnTransformer
X, y = load_iris(as_frame=True, return_X_y=True)
sepal_cols = ["sepal length (cm)", "sepal width (cm)"]
petal_cols = ["petal length (cm)", "petal width (cm)"]
preprocessor = ColumnTransformer(
[
("scaler", StandardScaler(), sepal_cols),
("kbin", KBinsDiscretizer(encode="ordinal"), petal_cols),
],
verbose_feature_names_out=False,
).set_output(transform="pandas")
X_out = preprocessor.fit_transform(X)
X_out.sample(n=5, random_state=0)
直方图梯度提升树中的交互约束#
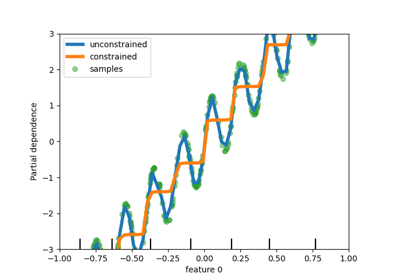
HistGradientBoostingRegressor 和 HistGradientBoostingClassifier 现在支持通过 interaction_cst 参数进行交互约束。详情请参见 用户指南 。在以下示例中,不允许特征之间进行交互。
from sklearn.datasets import load_diabetes
from sklearn.ensemble import HistGradientBoostingRegressor
X, y = load_diabetes(return_X_y=True, as_frame=True)
hist_no_interact = HistGradientBoostingRegressor(
interaction_cst=[[i] for i in range(X.shape[1])], random_state=0
)
hist_no_interact.fit(X, y)
新的和增强的显示#
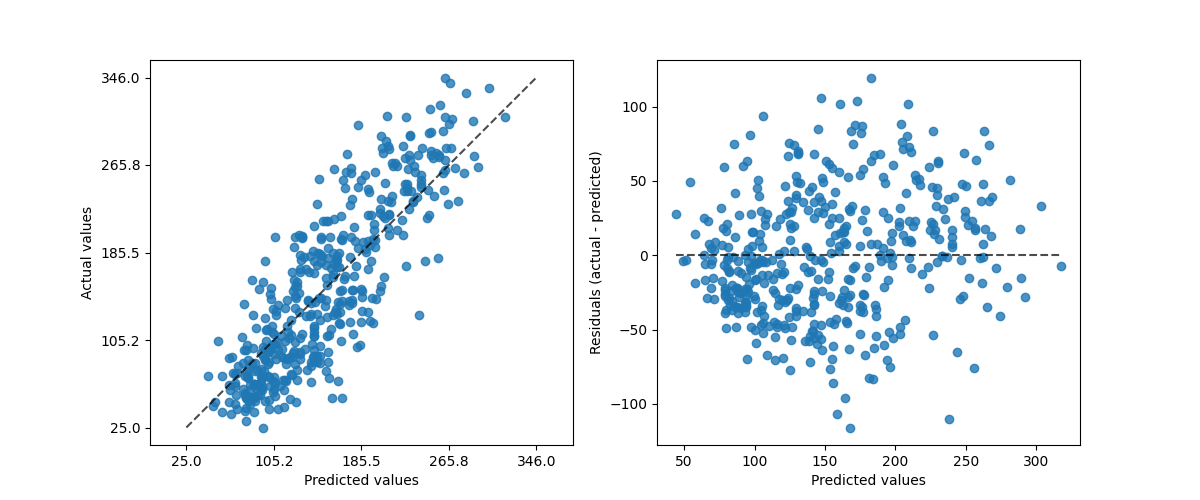
PredictionErrorDisplay 提供了一种定性分析回归模型的方法。
import matplotlib.pyplot as plt
from sklearn.metrics import PredictionErrorDisplay
fig, axs = plt.subplots(nrows=1, ncols=2, figsize=(12, 5))
_ = PredictionErrorDisplay.from_estimator(
hist_no_interact, X, y, kind="actual_vs_predicted", ax=axs[0]
)
_ = PredictionErrorDisplay.from_estimator(
hist_no_interact, X, y, kind="residual_vs_predicted", ax=axs[1]
)
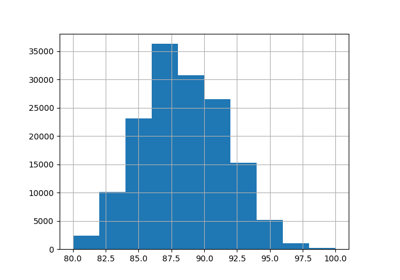
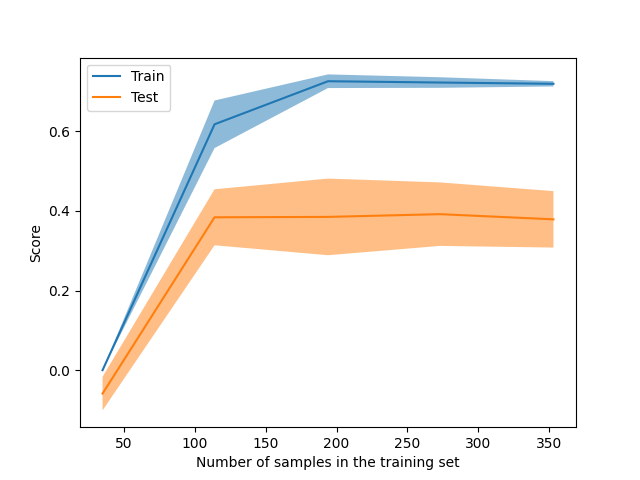
LearningCurveDisplay 现在可以用于绘制 learning_curve 的结果。
from sklearn.model_selection import LearningCurveDisplay
_ = LearningCurveDisplay.from_estimator(
hist_no_interact, X, y, cv=5, n_jobs=2, train_sizes=np.linspace(0.1, 1, 5)
)
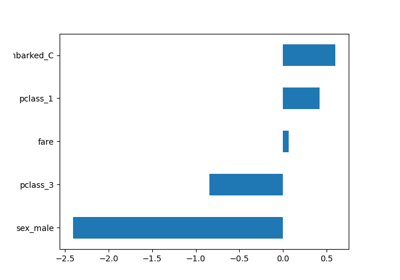
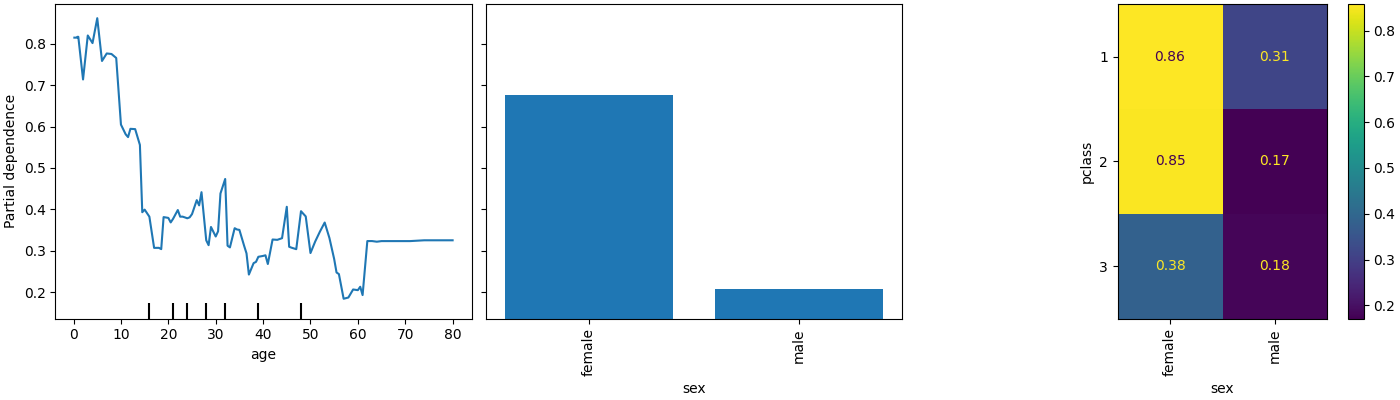
PartialDependenceDisplay 新增了一个参数 categorical_features ,用于通过条形图和热图显示分类特征的部分依赖性。
from sklearn.datasets import fetch_openml
X, y = fetch_openml(
"titanic", version=1, as_frame=True, return_X_y=True, parser="pandas"
)
X = X.select_dtypes(["number", "category"]).drop(columns=["body"])
from sklearn.preprocessing import OrdinalEncoder
from sklearn.pipeline import make_pipeline
categorical_features = ["pclass", "sex", "embarked"]
model = make_pipeline(
ColumnTransformer(
transformers=[("cat", OrdinalEncoder(), categorical_features)],
remainder="passthrough",
),
HistGradientBoostingRegressor(random_state=0),
).fit(X, y)
from sklearn.inspection import PartialDependenceDisplay
fig, ax = plt.subplots(figsize=(14, 4), constrained_layout=True)
_ = PartialDependenceDisplay.from_estimator(
model,
X,
features=["age", "sex", ("pclass", "sex")],
categorical_features=categorical_features,
ax=ax,
)
更快的解析器在 fetch_openml#
fetch_openml 现在支持一个新的 "pandas" 解析器,该解析器在内存和 CPU 使用上更高效。在 v1.4 版本中,默认值将更改为 parser="auto" ,它将自动为密集数据使用 "pandas" 解析器,为稀疏数据使用 "liac-arff" 解析器。
X, y = fetch_openml(
"titanic", version=1, as_frame=True, return_X_y=True, parser="pandas"
)
X.head()
LinearDiscriminantAnalysis 中的实验性数组 API 支持#
在 LinearDiscriminantAnalysis 中添加了对 Array API 规范的实验性支持。该估计器现在可以在任何符合数组 API 的库上运行,例如 GPU 加速的数组库 CuPy _。详情请参见 用户指南 。
改进了许多估计器的效率#
在1.1版本中,许多依赖于成对距离计算的估计器(主要是与聚类、流形学习和邻居搜索算法相关的估计器)的效率在处理float64密集输入时得到了极大提高。效率改进尤其体现在减少了内存占用,并在多核机器上具有更好的可扩展性。
在1.2版本中,这些估计器的效率在处理float32和float64数据集的所有密集和稀疏输入组合时得到了进一步提高,但不包括欧几里得距离和平方欧几里得距离度量的稀疏-密集和密集-稀疏组合。
受影响的估计器的详细列表可以在:ref:changelog <release_notes_1_2> 中找到。
Total running time of the script: (0 minutes 2.875 seconds)
Related examples