Note
Go to the end to download the full example code. or to run this example in your browser via Binder
使用分类器链进行多标签分类#
本示例展示了如何使用 ClassifierChain 来解决多标签分类问题。
解决此类任务的最简单策略是对每个标签(即目标变量的每一列)独立训练一个二元分类器。在预测时,二元分类器的集合用于组装多任务预测。
这种策略无法建模不同任务之间的关系。ClassifierChain 是一个实现了更高级策略的元估计器(即一个包含内部估计器的估计器)。二元分类器的集合被用作一个链,其中链中一个分类器的预测被用作训练下一个新标签分类器的特征。因此,这些额外的特征允许每个链利用标签之间的相关性。
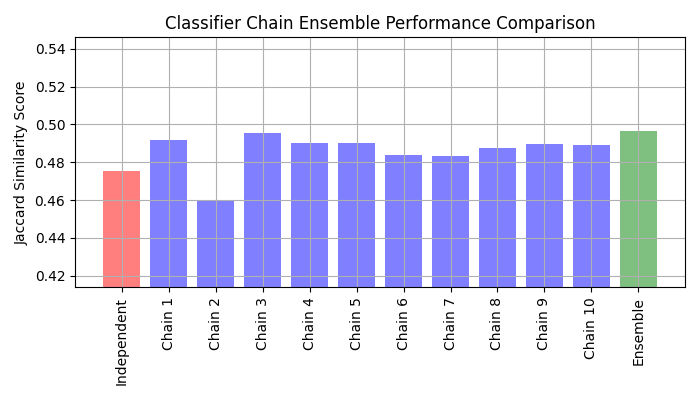
链的 Jaccard 相似度 分数往往高于独立基础模型的分数。
# 作者:scikit-learn 开发者
# SPDX-License-Identifier: BSD-3-Clause
加载数据集#
在这个例子中,我们使用 yeast 数据集,该数据集包含 2,417 个数据点,每个数据点有 103 个特征和 14 个可能的标签。每个数据点至少有一个标签。作为基线,我们首先为14个标签中的每一个训练一个逻辑回归分类器。为了评估这些分类器的性能,我们在一个保留的测试集上进行预测,并计算每个样本的 Jaccard 相似度。
import matplotlib.pyplot as plt
import numpy as np
from sklearn.datasets import fetch_openml
from sklearn.model_selection import train_test_split
# 从 https://www.openml.org/d/40597 加载一个多标签数据集
X, Y = fetch_openml("yeast", version=4, return_X_y=True)
Y = Y == "TRUE"
X_train, X_test, Y_train, Y_test = train_test_split(X, Y, test_size=0.2, random_state=0)
拟合模型#
我们拟合了由 OneVsRestClassifier 包装的 LogisticRegression 模型和多个 ClassifierChain 组成的集成模型。
LogisticRegression 被 OneVsRestClassifier 包装#
由于默认情况下 LogisticRegression 无法处理具有多个目标的数据,我们需要使用 OneVsRestClassifier 。
在拟合模型后,我们计算 Jaccard 相似度。
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import jaccard_score
from sklearn.multiclass import OneVsRestClassifier
base_lr = LogisticRegression()
ovr = OneVsRestClassifier(base_lr)
ovr.fit(X_train, Y_train)
Y_pred_ovr = ovr.predict(X_test)
ovr_jaccard_score = jaccard_score(Y_test, Y_pred_ovr, average="samples")
二元分类器链#
由于每条链中的模型是随机排列的,因此链之间的性能差异显著。可以假设存在一个最佳的类顺序,可以产生最佳性能。然而,我们事先并不知道这个顺序。相反,我们可以通过对链的二元预测进行平均并应用0.5的阈值来构建分类器链的投票集成。集成的Jaccard相似度得分高于独立模型,并且往往超过集成中每条链的得分(尽管这在随机排列的链中并不保证)。
from sklearn.multioutput import ClassifierChain
chains = [ClassifierChain(base_lr, order="random", random_state=i) for i in range(10)]
for chain in chains:
chain.fit(X_train, Y_train)
Y_pred_chains = np.array([chain.predict_proba(X_test) for chain in chains])
chain_jaccard_scores = [
jaccard_score(Y_test, Y_pred_chain >= 0.5, average="samples")
for Y_pred_chain in Y_pred_chains
]
Y_pred_ensemble = Y_pred_chains.mean(axis=0)
ensemble_jaccard_score = jaccard_score(
Y_test, Y_pred_ensemble >= 0.5, average="samples"
)
绘制结果#
绘制独立模型、每个链和集成的Jaccard相似性得分(请注意,此图的纵轴并不是从0开始)。
model_scores = [ovr_jaccard_score] + chain_jaccard_scores + [ensemble_jaccard_score]
model_names = (
"Independent",
"Chain 1",
"Chain 2",
"Chain 3",
"Chain 4",
"Chain 5",
"Chain 6",
"Chain 7",
"Chain 8",
"Chain 9",
"Chain 10",
"Ensemble",
)
x_pos = np.arange(len(model_names))
fig, ax = plt.subplots(figsize=(7, 4))
ax.grid(True)
ax.set_title("Classifier Chain Ensemble Performance Comparison")
ax.set_xticks(x_pos)
ax.set_xticklabels(model_names, rotation="vertical")
ax.set_ylabel("Jaccard Similarity Score")
ax.set_ylim([min(model_scores) * 0.9, max(model_scores) * 1.1])
colors = ["r"] + ["b"] * len(chain_jaccard_scores) + ["g"]
ax.bar(x_pos, model_scores, alpha=0.5, color=colors)
plt.tight_layout()
plt.show()
结果解释#
从该图中可以得出三个主要结论:
由
OneVsRestClassifier包装的独立模型的表现比分类器链的集成和某些单独的链要差。这是因为逻辑回归没有建模标签之间的关系。ClassifierChain利用了标签之间的相关性,但由于标签排序的随机性,它的结果可能比独立模型更差。链的集成表现更好,因为它不仅捕捉了标签之间的关系,而且不会对它们的正确顺序做出强假设。
Total running time of the script: (0 minutes 0.952 seconds)
Related examples