train_test_split#
- sklearn.model_selection.train_test_split(*arrays, test_size=None, train_size=None, random_state=None, shuffle=True, stratify=None)#
将数组或矩阵拆分为随机的训练和测试子集。
- 快速实用工具,封装了输入验证、
next(ShuffleSplit().split(X, y)),以及对输入数据的处理
到一个单一的调用中,用于在一行代码中拆分(并可选地子采样)数据。
更多信息请参阅 用户指南 。
- Parameters:
- *arrays具有相同长度 / shape[0] 的可索引序列
允许的输入是列表、numpy 数组、scipy-sparse 矩阵或 pandas 数据框。
- test_sizefloat 或 int, 默认=None
如果为浮点数,应在 0.0 和 1.0 之间,并表示要包含在测试拆分中的数据集比例。如果为整数,表示测试样本的绝对数量。如果为 None,该值设置为训练大小的补数。如果
train_size也为 None,则将设置为 0.25。- train_sizefloat 或 int, 默认=None
如果为浮点数,应在 0.0 和 1.0 之间,并表示要包含在训练拆分中的数据集比例。如果为整数,表示训练样本的绝对数量。如果为 None,该值自动设置为测试大小的补数。
- random_stateint, RandomState 实例或 None, 默认=None
控制在对数据应用拆分之前应用的洗牌。传递一个 int 以在多次函数调用中生成可重复的输出。请参阅 术语表 。
- shufflebool, 默认=True
在拆分之前是否对数据进行洗牌。如果 shuffle=False,则 stratify 必须为 None。
- stratify类数组, 默认=None
如果不为 None,数据将按分层方式拆分,使用此作为类标签。更多信息请参阅 用户指南 。
- Returns:
- splitting列表, 长度=2 * len(arrays)
包含输入的训练-测试拆分的列表。
Added in version 0.16: 如果输入是稀疏的,输出将是一个
scipy.sparse.csr_matrix。否则,输出类型与输入类型相同。
Examples
>>> import numpy as np >>> from sklearn.model_selection import train_test_split >>> X, y = np.arange(10).reshape((5, 2)), range(5) >>> X array([[0, 1], [2, 3], [4, 5], [6, 7], [8, 9]]) >>> list(y) [0, 1, 2, 3, 4]
>>> X_train, X_test, y_train, y_test = train_test_split( ... X, y, test_size=0.33, random_state=42) ... >>> X_train array([[4, 5], [0, 1], [6, 7]]) >>> y_train [2, 0, 3] >>> X_test array([[2, 3], [8, 9]]) >>> y_test [1, 4]
>>> train_test_split(y, shuffle=False) [[0, 1, 2], [3, 4]]
Gallery examples#
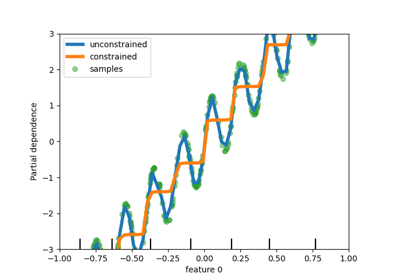

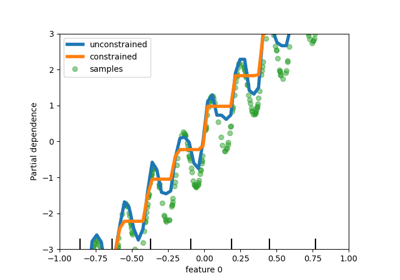
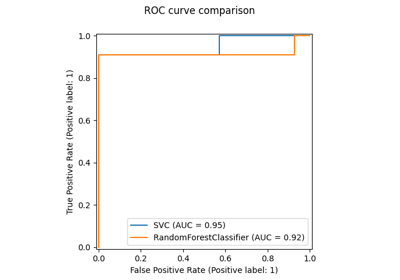
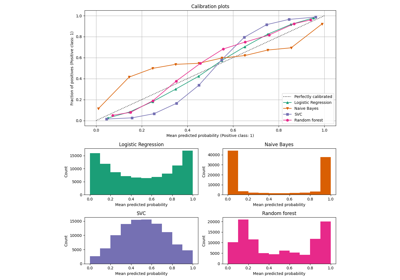
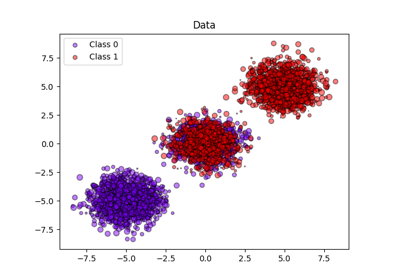
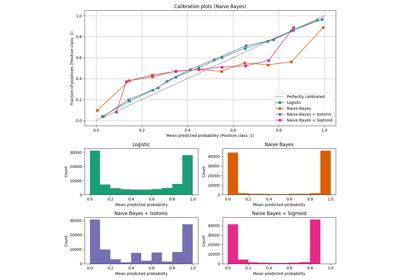


sphx_glr_auto_examples_ensemble_plot_gradient_boosting_regularization.py
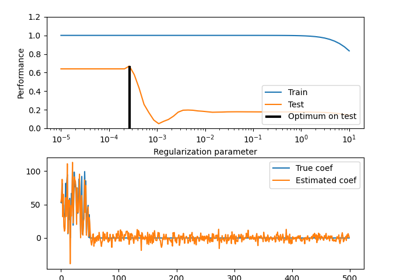
梯度提升正则化