make_hastie_10_2#
- sklearn.datasets.make_hastie_10_2(n_samples=12000, *, random_state=None)#
生成用于Hastie等人在2009年提出的二分类数据,示例10.2。
十个特征是标准独立高斯分布,目标
y定义如下:y[i] = 1 if np.sum(X[i] ** 2) > 9.34 else -1
更多信息请参阅 用户指南 。
- Parameters:
- n_samplesint, default=12000
样本数量。
- random_stateint, RandomState实例或None, default=None
确定用于创建数据集的随机数生成。为多个函数调用传递一个int以获得可重复的输出。 请参阅 术语表 。
- Returns:
- Xndarray of shape (n_samples, 10)
输入样本。
- yndarray of shape (n_samples,)
输出值。
See also
make_gaussian_quantiles此数据集方法的泛化。
References
[1]T. Hastie, R. Tibshirani and J. Friedman, “Elements of Statistical Learning Ed. 2”, Springer, 2009.
Examples
>>> from sklearn.datasets import make_hastie_10_2 >>> X, y = make_hastie_10_2(n_samples=24000, random_state=42) >>> X.shape (24000, 10) >>> y.shape (24000,) >>> list(y[:5]) [-1.0, 1.0, -1.0, 1.0, -1.0]
Gallery examples#
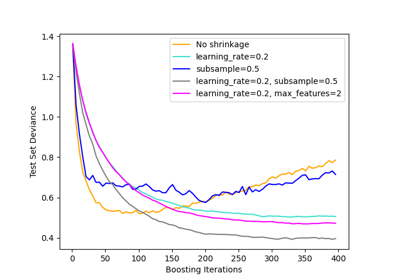
sphx_glr_auto_examples_ensemble_plot_gradient_boosting_regularization.py
梯度提升正则化