OPTICS#
- class sklearn.cluster.OPTICS(*, min_samples=5, max_eps=inf, metric='minkowski', p=2, metric_params=None, cluster_method='xi', eps=None, xi=0.05, predecessor_correction=True, min_cluster_size=None, algorithm='auto', leaf_size=30, memory=None, n_jobs=None)#
估计向量数组的聚类结构。
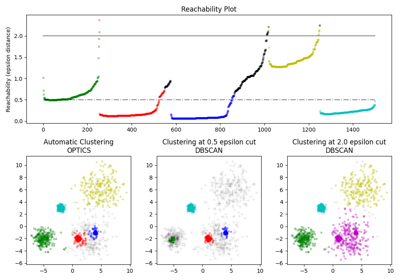
OPTICS(Ordering Points To Identify the Clustering Structure),与DBSCAN紧密相关,找到高密度核心样本并从它们扩展聚类[1]。与DBSCAN不同,OPTICS保持可变邻域半径的聚类层次结构。比当前的sklearn实现更适合用于大型数据集。
然后使用类似DBSCAN的方法(cluster_method = ‘dbscan’)或[1]中提出的自动技术(cluster_method = ‘xi’)提取聚类。
此实现与原始OPTICS有所不同,首先对所有点执行k最近邻搜索以识别核心大小,然后在构建聚类顺序时仅计算到未处理点的距离。请注意,我们没有使用堆来管理扩展候选者,因此时间复杂度将是O(n^2)。
更多信息请参阅 用户指南 。
- Parameters:
- min_samplesint > 1 或 0 到 1 之间的浮点数, 默认=5
邻域中点的数量,使得一个点被认为是核心点。此外,上下陡峭区域不能有超过
min_samples个连续的非陡峭点。表示为绝对数量或样本数量的分数(四舍五入至少为2)。- max_epsfloat, 默认=np.inf
两个样本之间的最大距离,使得一个样本被认为是另一个样本的邻域。默认值
np.inf将跨越所有尺度识别聚类;减少max_eps将导致更短的运行时间。- metricstr 或 callable, 默认=’minkowski’
用于距离计算的度量。可以使用scikit-learn或scipy.spatial.distance中的任何度量。
如果度量是可调用函数,则对每对实例(行)调用它,并记录结果值。可调用函数应接受两个数组作为输入并返回一个表示它们之间距离的值。这适用于Scipy的度量,但比将度量名称作为字符串传递效率低。如果度量是”precomputed”,则假定
X是距离矩阵且必须是方阵。度量的有效值为:
来自scikit-learn: [‘cityblock’, ‘cosine’, ‘euclidean’, ‘l1’, ‘l2’, ‘manhattan’]
来自scipy.spatial.distance: [‘braycurtis’, ‘canberra’, ‘chebyshev’, ‘correlation’, ‘dice’, ‘hamming’, ‘jaccard’, ‘kulsinski’, ‘mahalanobis’, ‘minkowski’, ‘rogerstanimoto’, ‘russellrao’, ‘seuclidean’, ‘sokalmichener’, ‘sokalsneath’, ‘sqeuclidean’, ‘yule’]
稀疏矩阵仅支持scikit-learn度量。有关这些度量的详细信息,请参阅scipy.spatial.distance的文档。
Note
'kulsinski'在SciPy 1.9中已弃用,将在SciPy 1.11中移除。- pfloat, 默认=2
来自
pairwise_distances的Minkowski度量的参数。当 p = 1 时,这相当于使用 manhattan_distance (l1),当 p = 2 时,相当于使用 euclidean_distance (l2)。对于任意 p,使用 minkowski_distance (l_p)。- metric_paramsdict, 默认=None
度量函数的额外关键字参数。
- cluster_methodstr, 默认=’xi’
使用计算的可达性和顺序提取聚类的方法。可能的值为 “xi” 和 “dbscan”。
- epsfloat, 默认=None
两个样本之间的最大距离,使得一个样本被认为是另一个样本的邻域。默认情况下,它假定与
max_eps相同的值。仅当cluster_method='dbscan'时使用。- xi0 到 1 之间的浮点数, 默认=0.05
确定构成聚类边界的最小陡峭度。例如,可达性图中的向上点定义为从一个点到其后继点的比率最多为 1-xi。仅当
cluster_method='xi'时使用。- predecessor_correctionbool, 默认=True
根据OPTICS计算的前驱修正聚类[2]。此参数对大多数数据集影响最小。仅当
cluster_method='xi'时使用。- min_cluster_sizeint > 1 或 0 到 1 之间的浮点数, 默认=None
OPTICS聚类中的最小样本数,表示为绝对数量或样本数量的分数(四舍五入至少为2)。如果为
None,则使用min_samples的值。仅当cluster_method='xi'时使用。- algorithm{‘auto’, ‘ball_tree’, ‘kd_tree’, ‘brute’}, 默认=’auto’
用于计算最近邻的算法:
‘ball_tree’ 将使用
BallTree。‘kd_tree’ 将使用
KDTree。‘brute’ 将使用暴力搜索。
‘auto’(默认)将尝试根据传递给
fit方法的值决定最合适的算法。
注意:稀疏输入将覆盖此参数的设置,使用暴力搜索。
- leaf_sizeint, 默认=30
传递给
BallTree或KDTree的叶大小。这会影响构建和查询的速度,以及存储树所需的内存。最佳值取决于问题的性质。- memorystr 或 具有 joblib.Memory 接口的对象, 默认=None
用于缓存树的计算输出的内存。默认情况下,不进行缓存。如果给定字符串,则是缓存目录的路径。
- n_jobsint, 默认=None
用于邻居搜索的并行作业数。
None表示 1,除非在joblib.parallel_backend上下文中。-1表示使用所有处理器。有关更多详细信息,请参阅 Glossary 。
- Attributes:
- labels_ndarray of shape (n_samples,)
给定数据集的每个点的聚类标签。噪声样本和未包含在
cluster_hierarchy_的叶聚类中的点标记为 -1。- reachability_ndarray of shape (n_samples,)
每个样本的可达性距离,按对象顺序索引。使用
clust.reachability_[clust.ordering_]按聚类顺序访问。- ordering_ndarray of shape (n_samples,)
样本索引的聚类顺序列表。
- core_distances_ndarray of shape (n_samples,)
每个样本成为核心点的距离,按对象顺序索引。永远不会成为核心点的距离为 inf。使用
clust.core_distances_[clust.ordering_]按聚类顺序访问。- predecessor_ndarray of shape (n_samples,)
样本到达的点,按对象顺序索引。种子点的前驱为 -1。
- cluster_hierarchy_ndarray of shape (n_clusters, 2)
聚类列表,每行形式为
[start, end],所有索引包括。聚类按(end, -start)(升序)排序,使得较大的聚类包含较小的聚类。由于labels_不反映层次结构,通常len(cluster_hierarchy_) > np.unique(optics.labels_)。另请注意,这些索引是ordering_的,即X[ordering_][start:end + 1]形成一个聚类。仅当cluster_method='xi'时可用。- n_features_in_int
在 fit 期间看到的特征数量。
Added in version 0.24.
- feature_names_in_ndarray of shape (
n_features_in_,) 在 fit 期间看到的特征名称。仅当
X的特征名称均为字符串时定义。Added in version 1.0.
See also
DBSCAN一种类似的聚类,指定邻域半径(eps)。我们的实现针对运行时间进行了优化。
References
[1]Ankerst, Mihael, Markus M. Breunig, Hans-Peter Kriegel, 和 Jörg Sander. “OPTICS: ordering points to identify the clustering structure.” ACM SIGMOD Record 28, no. 2 (1999): 49-60.
[2]Schubert, Erich, Michael Gertz. “Improving the Cluster Structure Extracted from OPTICS Plots.” Proc. of the Conference “Lernen, Wissen, Daten, Analysen” (LWDA) (2018): 318-329.
Examples
>>> from sklearn.cluster import OPTICS >>> import numpy as np >>> X = np.array([[1, 2], [2, 5], [3, 6], ... [8, 7], [8, 8], [7, 3]]) >>> clustering = OPTICS(min_samples=2).fit(X) >>> clustering.labels_ array([0, 0, 0, 1, 1, 1])
有关更详细的示例,请参阅 OPTICS聚类算法示例 。
- fit(X, y=None)#
执行OPTICS聚类。
提取有序的点列表和可达距离,并在OPTICS对象实例化时使用指定的
max_eps距离进行初始聚类。- Parameters:
- X{ndarray, sparse matrix} of shape (n_samples, n_features), or (n_samples, n_samples) if metric=’precomputed’
特征数组,或在metric=’precomputed’时为样本之间的距离数组。如果提供的是稀疏矩阵,它将被转换为CSR格式。
- yIgnored
未使用,按惯例为API一致性保留。
- Returns:
- selfobject
返回拟合后的self实例。
- fit_predict(X, y=None, **kwargs)#
执行对
X的聚类并返回聚类标签。- Parameters:
- X形状为 (n_samples, n_features) 的类数组
输入数据。
- y忽略
未使用,为保持API一致性而存在。
- **kwargs字典
传递给
fit的参数。Added in version 1.4.
- Returns:
- labels形状为 (n_samples,),dtype=np.int64 的 ndarray
聚类标签。
- get_metadata_routing()#
获取此对象的元数据路由。
请查看 用户指南 以了解路由机制的工作原理。
- Returns:
- routingMetadataRequest
MetadataRequest封装的 路由信息。
- get_params(deep=True)#
获取此估计器的参数。
- Parameters:
- deepbool, 默认=True
如果为True,将返回此估计器和包含的子对象(也是估计器)的参数。
- Returns:
- paramsdict
参数名称映射到它们的值。