TimeSeriesSplit#
- class sklearn.model_selection.TimeSeriesSplit(n_splits=5, *, max_train_size=None, test_size=None, gap=0)#
时间序列交叉验证器。
提供训练/测试索引来分割时间序列数据样本,这些样本在固定时间间隔内被观察到,分为训练/测试集。 在每次分割中,测试索引必须比之前的更高,因此在交叉验证器中不适合进行洗牌。
这个交叉验证对象是
KFold的一个变体。 在第 k 次分割中,它返回前 k 折作为训练集,第 (k+1) 折作为测试集。请注意,与标准的交叉验证方法不同,连续的训练集是那些之前训练集的超集。
更多信息请参阅 用户指南 。
有关交叉验证行为的可视化以及常见 scikit-learn 分割方法之间的比较,请参阅 在 scikit-learn 中可视化交叉验证行为
Added in version 0.18.
- Parameters:
- n_splitsint, default=5
分割数量。必须至少为 2。
Changed in version 0.22:
n_splits默认值从 3 改为 5。- max_train_sizeint, default=None
单个训练集的最大大小。
- test_sizeint, default=None
用于限制测试集的大小。默认为
n_samples // (n_splits + 1),这是在gap=0时允许的最大值。Added in version 0.24.
- gapint, default=0
在每个训练集结束和测试集开始之间排除的样本数量。
Added in version 0.24.
Notes
训练集在第
i次分割中的大小为i * n_samples // (n_splits + 1) + n_samples % (n_splits + 1),默认情况下测试集的大小为n_samples//(n_splits + 1), 其中n_samples是样本数量。请注意,这个公式仅在test_size和max_train_size保持默认值时有效。Examples
>>> import numpy as np >>> from sklearn.model_selection import TimeSeriesSplit >>> X = np.array([[1, 2], [3, 4], [1, 2], [3, 4], [1, 2], [3, 4]]) >>> y = np.array([1, 2, 3, 4, 5, 6]) >>> tscv = TimeSeriesSplit() >>> print(tscv) TimeSeriesSplit(gap=0, max_train_size=None, n_splits=5, test_size=None) >>> for i, (train_index, test_index) in enumerate(tscv.split(X)): ... print(f"Fold {i}:") ... print(f" Train: index={train_index}") ... print(f" Test: index={test_index}") Fold 0: Train: index=[0] Test: index=[1] Fold 1: Train: index=[0 1] Test: index=[2] Fold 2: Train: index=[0 1 2] Test: index=[3] Fold 3: Train: index=[0 1 2 3] Test: index=[4] Fold 4: Train: index=[0 1 2 3 4] Test: index=[5] >>> # 将 test_size 固定为 2,样本数为 12 >>> X = np.random.randn(12, 2) >>> y = np.random.randint(0, 2, 12) >>> tscv = TimeSeriesSplit(n_splits=3, test_size=2) >>> for i, (train_index, test_index) in enumerate(tscv.split(X)): ... print(f"Fold {i}:") ... print(f" Train: index={train_index}") ... print(f" Test: index={test_index}") Fold 0: Train: index=[0 1 2 3 4 5] Test: index=[6 7] Fold 1: Train: index=[0 1 2 3 4 5 6 7] Test: index=[8 9] Fold 2: Train: index=[0 1 2 3 4 5 6 7 8 9] Test: index=[10 11] >>> # 增加 2 期的间隔 >>> tscv = TimeSeriesSplit(n_splits=3, test_size=2, gap=2) >>> for i, (train_index, test_index) in enumerate(tscv.split(X)): ... print(f"Fold {i}:") ... print(f" Train: index={train_index}") ... print(f" Test: index={test_index}") Fold 0: Train: index=[0 1 2 3] Test: index=[6 7] Fold 1: Train: index=[0 1 2 3 4 5] Test: index=[8 9] Fold 2: Train: index=[0 1 2 3 4 5 6 7] Test: index=[10 11]
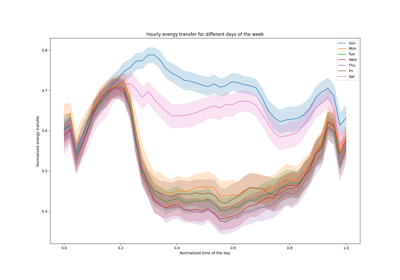
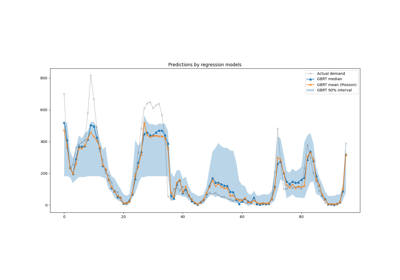
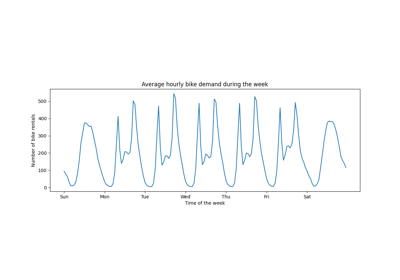
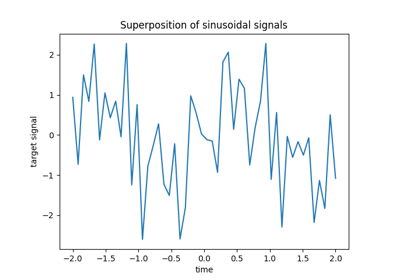
有关更详细的示例,请参阅 时间相关特征工程 。
- get_metadata_routing()#
获取此对象的元数据路由。
请查看 用户指南 以了解路由机制的工作原理。
- Returns:
- routingMetadataRequest
MetadataRequest封装的 路由信息。
- get_n_splits(X=None, y=None, groups=None)#
返回交叉验证器中的分割迭代次数。
- Parameters:
- Xobject
总是被忽略,存在是为了兼容性。
- yobject
总是被忽略,存在是为了兼容性。
- groupsobject
总是被忽略,存在是为了兼容性。
- Returns:
- n_splitsint
返回交叉验证器中的分割迭代次数。
- split(X, y=None, groups=None)#
生成索引以将数据拆分为训练集和测试集。
- Parameters:
- X形状为 (n_samples, n_features) 的类数组
训练数据,其中
n_samples是样本数量 和n_features是特征数量。- y形状为 (n_samples,) 的类数组
总是被忽略,存在以保持兼容性。
- groups形状为 (n_samples,) 的类数组
总是被忽略,存在以保持兼容性。
- Yields:
- trainndarray
该拆分的训练集索引。
- testndarray
该拆分的测试集索引。