fetch_species_distributions#
- sklearn.datasets.fetch_species_distributions(*, data_home=None, download_if_missing=True, n_retries=3, delay=1.0)#
加载Phillips等人(2006年)的物种分布数据集的加载器。
更多信息请参阅 用户指南 。
- Parameters:
- data_homestr 或 path-like, 默认=None
指定数据集的另一个下载和缓存文件夹。默认情况下,所有scikit-learn数据都存储在’~/scikit_learn_data’子文件夹中。
- download_if_missingbool, 默认=True
如果为False,如果数据在本地不可用,则引发OSError,而不是尝试从源站点下载数据。
- n_retriesint, 默认=3
遇到HTTP错误时的重试次数。
Added in version 1.5.
- delayfloat, 默认=1.0
重试之间的秒数。
Added in version 1.5.
- Returns:
- data
Bunch 类字典对象,具有以下属性。
- coveragesarray, shape = [14, 1592, 1212]
这些表示在地图网格的每个点测量的14个特征。 网格的纬度/经度值如下所述。 缺失数据用值-9999表示。
- trainrecord array, shape = (1624,)
数据的训练点。每个点有三个字段:
train[‘species’] 是物种名称
train[‘dd long’] 是经度,以度为单位
train[‘dd lat’] 是纬度,以度为单位
- testrecord array, shape = (620,)
数据的测试点。格式与训练数据相同。
- Nx, Nyintegers
网格中经度(x)和纬度(y)的数量
- x_left_lower_corner, y_left_lower_cornerfloats
左下角的(x,y)位置,以度为单位
- grid_sizefloat
网格点之间的间距,以度为单位
- data
Notes
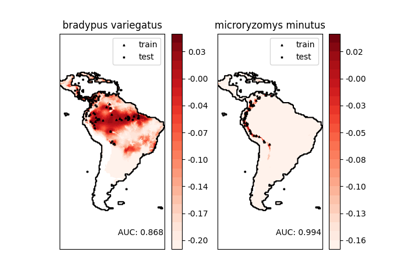
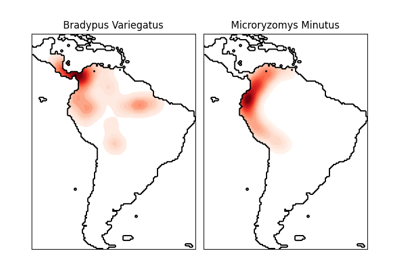
该数据集表示物种的地理分布。 数据集由Phillips等人(2006年)提供。
这两个物种是:
“Bradypus variegatus” , 棕喉树懒。
“Microryzomys minutus” , 也称为森林小稻鼠,一种生活在秘鲁、哥伦比亚、厄瓜多尔、秘鲁和委内瑞拉的啮齿动物。
有关使用此数据集与scikit-learn的示例,请参见 examples/applications/plot_species_distribution_modeling.py 。
References
“Maximum entropy modeling of species geographic distributions” S. J. Phillips, R. P. Anderson, R. E. Schapire - Ecological Modelling, 190:231-259, 2006.
Examples
>>> from sklearn.datasets import fetch_species_distributions >>> species = fetch_species_distributions() >>> species.train[:5] array([(b'microryzomys_minutus', -64.7 , -17.85 ), (b'microryzomys_minutus', -67.8333, -16.3333), (b'microryzomys_minutus', -67.8833, -16.3 ), (b'microryzomys_minutus', -67.8 , -16.2667), (b'microryzomys_minutus', -67.9833, -15.9 )], dtype=[('species', 'S22'), ('dd long', '<f4'), ('dd lat', '<f4')])