Note
Go to the end to download the full example code. or to run this example in your browser via Binder
在 scikit-learn 中可视化交叉验证行为#
选择合适的交叉验证对象是正确拟合模型的关键部分。有很多方法可以将数据分成训练集和测试集,以避免模型过拟合,标准化测试集中的组数等。
此示例可视化了几种常见的 scikit-learn 对象的行为以供比较。
import matplotlib.pyplot as plt
import numpy as np
from matplotlib.patches import Patch
from sklearn.model_selection import (
GroupKFold,
GroupShuffleSplit,
KFold,
ShuffleSplit,
StratifiedGroupKFold,
StratifiedKFold,
StratifiedShuffleSplit,
TimeSeriesSplit,
)
rng = np.random.RandomState(1338)
cmap_data = plt.cm.Paired
cmap_cv = plt.cm.coolwarm
n_splits = 4
可视化我们的数据#
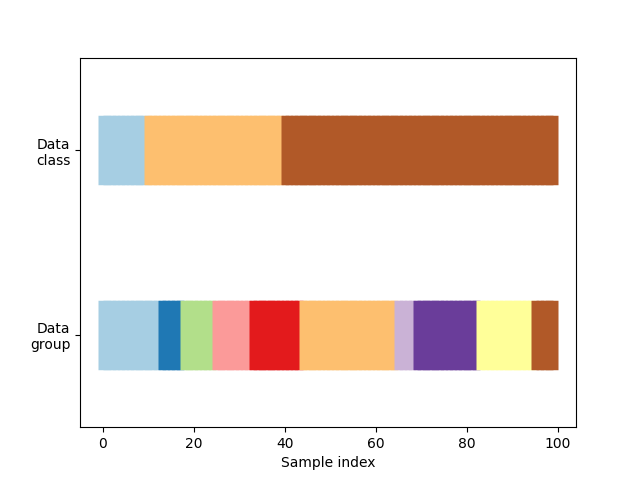
首先,我们必须了解数据的结构。它有100个随机生成的输入数据点,3个不均匀分布在数据点上的类别,以及10个均匀分布在数据点上的“组”。
正如我们将看到的,一些交叉验证对象对有标签的数据执行特定操作,另一些则对分组数据有不同的处理方式,还有一些则不使用这些信息。
首先,我们将可视化我们的数据。
# 生成班级/组数据
n_points = 100
X = rng.randn(100, 10)
percentiles_classes = [0.1, 0.3, 0.6]
y = np.hstack([[ii] * int(100 * perc) for ii, perc in enumerate(percentiles_classes)])
# 生成不均匀的组
group_prior = rng.dirichlet([2] * 10)
groups = np.repeat(np.arange(10), rng.multinomial(100, group_prior))
def visualize_groups(classes, groups, name):
# 可视化数据集组
fig, ax = plt.subplots()
ax.scatter(
range(len(groups)),
[0.5] * len(groups),
c=groups,
marker="_",
lw=50,
cmap=cmap_data,
)
ax.scatter(
range(len(groups)),
[3.5] * len(groups),
c=classes,
marker="_",
lw=50,
cmap=cmap_data,
)
ax.set(
ylim=[-1, 5],
yticks=[0.5, 3.5],
yticklabels=["Data\ngroup", "Data\nclass"],
xlabel="Sample index",
)
visualize_groups(y, groups, "no groups")
定义一个函数来可视化交叉验证行为#
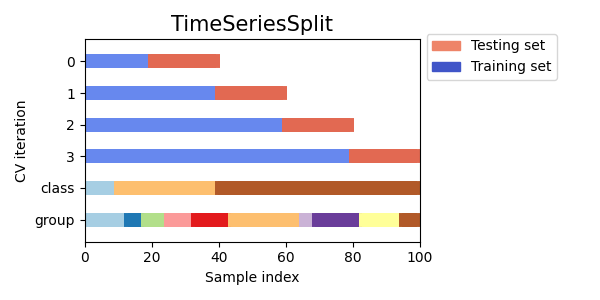
我们将定义一个函数,让我们可视化每个交叉验证对象的行为。我们将对数据进行4次拆分。在每次拆分中,我们将可视化为训练集(蓝色)和测试集(红色)选择的索引。
def plot_cv_indices(cv, X, y, group, ax, n_splits, lw=10):
"""为交叉验证对象的索引创建一个示例图。"""
use_groups = "Group" in type(cv).__name__
groups = group if use_groups else None
# 生成每个交叉验证分割的训练/测试可视化
for ii, (tr, tt) in enumerate(cv.split(X=X, y=y, groups=groups)):
# 用训练/测试组填充索引
indices = np.array([np.nan] * len(X))
indices[tt] = 1
indices[tr] = 0
# 可视化结果
ax.scatter(
range(len(indices)),
[ii + 0.5] * len(indices),
c=indices,
marker="_",
lw=lw,
cmap=cmap_cv,
vmin=-0.2,
vmax=1.2,
)
# 绘制数据类别和组别在末尾
ax.scatter(
range(len(X)), [ii + 1.5] * len(X), c=y, marker="_", lw=lw, cmap=cmap_data
)
ax.scatter(
range(len(X)), [ii + 2.5] * len(X), c=group, marker="_", lw=lw, cmap=cmap_data
)
# Formatting
yticklabels = list(range(n_splits)) + ["class", "group"]
ax.set(
yticks=np.arange(n_splits + 2) + 0.5,
yticklabels=yticklabels,
xlabel="Sample index",
ylabel="CV iteration",
ylim=[n_splits + 2.2, -0.2],
xlim=[0, 100],
)
ax.set_title("{}".format(type(cv).__name__), fontsize=15)
return ax
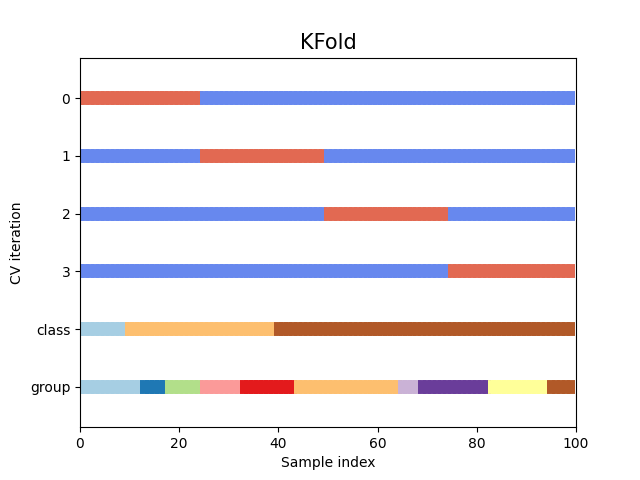
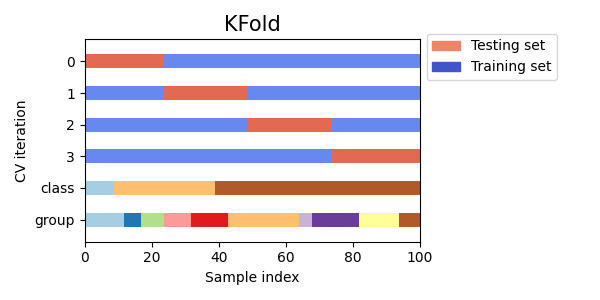
让我们看看 KFold 交叉验证对象的效果如何:
fig, ax = plt.subplots()
cv = KFold(n_splits)
plot_cv_indices(cv, X, y, groups, ax, n_splits)
<Axes: title={'center': 'KFold'}, xlabel='Sample index', ylabel='CV iteration'>
正如你所见,默认情况下,KFold 交叉验证迭代器不会考虑数据点的类别或分组。我们可以通过以下方式进行更改:
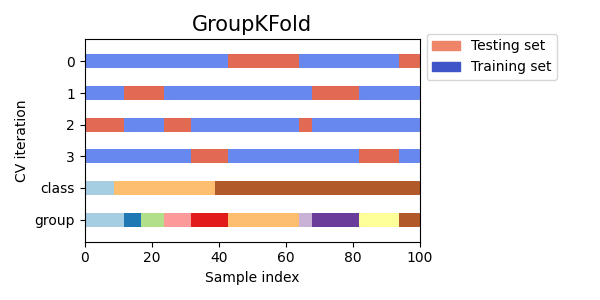
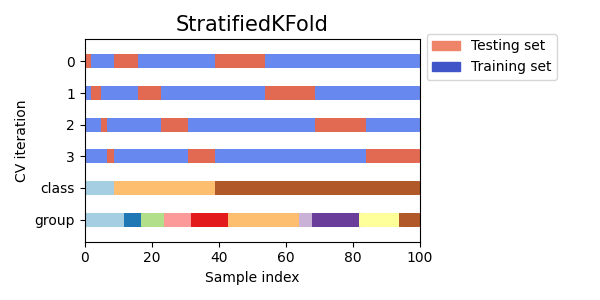
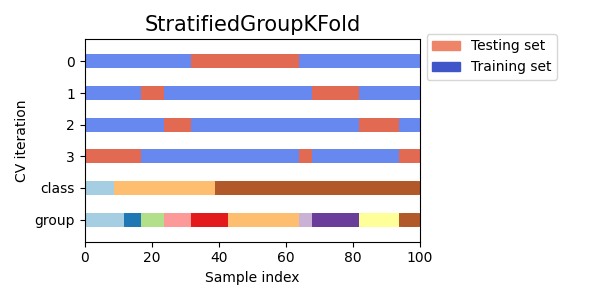
StratifiedKFold用于保持每个类别样本的比例。GroupKFold用于确保同一组不会出现在不同的折叠中。StratifiedGroupKFold用于在保持GroupKFold约束的同时,尝试返回分层折叠。
cvs = [StratifiedKFold, GroupKFold, StratifiedGroupKFold]
for cv in cvs:
fig, ax = plt.subplots(figsize=(6, 3))
plot_cv_indices(cv(n_splits), X, y, groups, ax, n_splits)
ax.legend(
[Patch(color=cmap_cv(0.8)), Patch(color=cmap_cv(0.02))],
["Testing set", "Training set"],
loc=(1.02, 0.8),
)
# 使图例适合
plt.tight_layout()
fig.subplots_adjust(right=0.7)
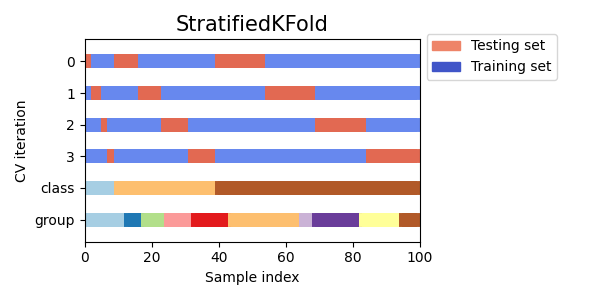
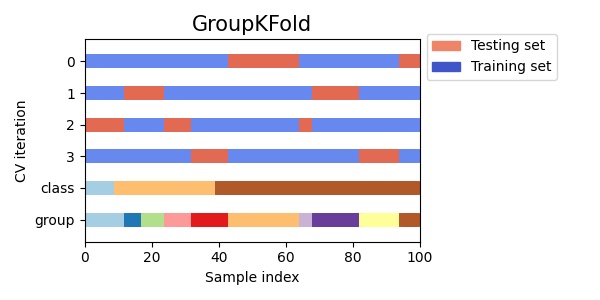
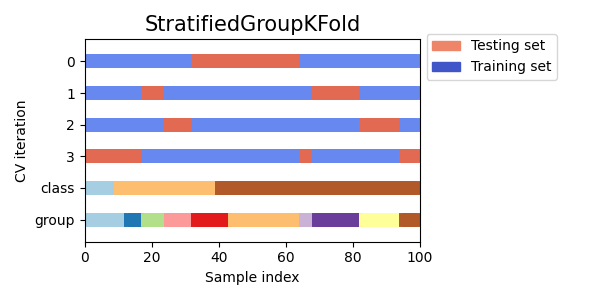
接下来我们将为多个交叉验证迭代器可视化这种行为。
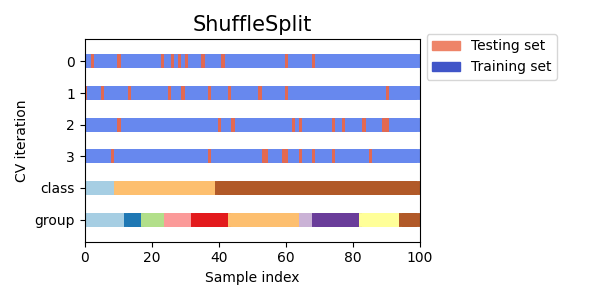
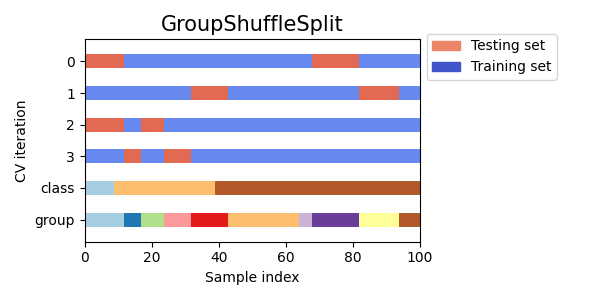
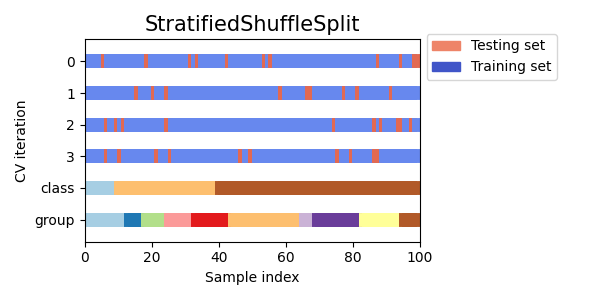
可视化多个交叉验证对象的索引
让我们直观地比较多种 scikit-learn 交叉验证对象的行为。下面我们将遍历几种常见的交叉验证对象,直观地展示每种对象的行为。
注意,有些使用了组/类信息,而有些则没有使用。
cvs = [
KFold,
GroupKFold,
ShuffleSplit,
StratifiedKFold,
StratifiedGroupKFold,
GroupShuffleSplit,
StratifiedShuffleSplit,
TimeSeriesSplit,
]
for cv in cvs:
this_cv = cv(n_splits=n_splits)
fig, ax = plt.subplots(figsize=(6, 3))
plot_cv_indices(this_cv, X, y, groups, ax, n_splits)
ax.legend(
[Patch(color=cmap_cv(0.8)), Patch(color=cmap_cv(0.02))],
["Testing set", "Training set"],
loc=(1.02, 0.8),
)
# 使图例适合
plt.tight_layout()
fig.subplots_adjust(right=0.7)
plt.show()
Total running time of the script: (0 minutes 0.519 seconds)
Related examples