Note
Go to the end to download the full example code. or to run this example in your browser via Binder
核岭回归和高斯过程回归的比较#
这个例子说明了核岭回归和高斯过程回归之间的差异。
核岭回归和高斯过程回归都使用所谓的“核技巧”使它们的模型足够有表现力以拟合训练数据。然而,这两种方法解决的机器学习问题有很大不同。
核岭回归将找到最小化损失函数(均方误差)的目标函数。
高斯过程回归不是找到单一的目标函数,而是采用一种概率方法:基于贝叶斯定理定义目标函数的高斯后验分布。因此,目标函数的先验概率与由观察到的训练数据定义的似然函数相结合,以提供后验分布的估计。
我们将通过一个例子来说明这些差异,并且我们还将重点关注调整核超参数。
# 作者:scikit-learn 开发者
# SPDX 许可证标识符:BSD-3-Clause
生成数据集#
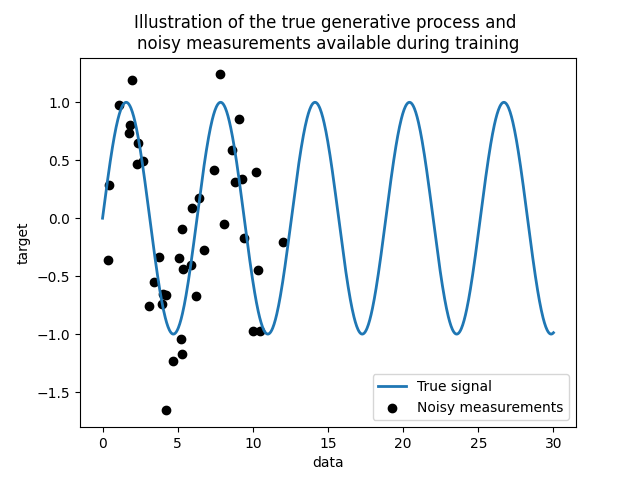
我们创建一个合成数据集。真实的生成过程将采用一个一维向量并计算其正弦值。注意,这个正弦函数的周期是 \(2 \pi\) 。我们将在这个示例中稍后重用这些信息。
import numpy as np
rng = np.random.RandomState(0)
data = np.linspace(0, 30, num=1_000).reshape(-1, 1)
target = np.sin(data).ravel()
现在,我们可以想象一个从这个真实过程获取观测值的场景。然而,我们将增加一些挑战:
测量将会有噪声;
只有信号开始部分的样本可用。
training_sample_indices = rng.choice(np.arange(0, 400), size=40, replace=False)
training_data = data[training_sample_indices]
training_noisy_target = target[training_sample_indices] + 0.5 * rng.randn(
len(training_sample_indices)
)
让我们绘制用于训练的真实信号和噪声测量值。
import matplotlib.pyplot as plt
plt.plot(data, target, label="True signal", linewidth=2)
plt.scatter(
training_data,
training_noisy_target,
color="black",
label="Noisy measurements",
)
plt.legend()
plt.xlabel("data")
plt.ylabel("target")
_ = plt.title(
"Illustration of the true generative process and \n"
"noisy measurements available during training"
)
简单线性模型的局限性#
首先,我们想要强调线性模型在我们的数据集上的局限性。我们拟合了一个 Ridge 模型,并检查该模型在我们数据集上的预测结果。
from sklearn.linear_model import Ridge
ridge = Ridge().fit(training_data, training_noisy_target)
plt.plot(data, target, label="True signal", linewidth=2)
plt.scatter(
training_data,
training_noisy_target,
color="black",
label="Noisy measurements",
)
plt.plot(data, ridge.predict(data), label="Ridge regression")
plt.legend()
plt.xlabel("data")
plt.ylabel("target")
_ = plt.title("Limitation of a linear model such as ridge")
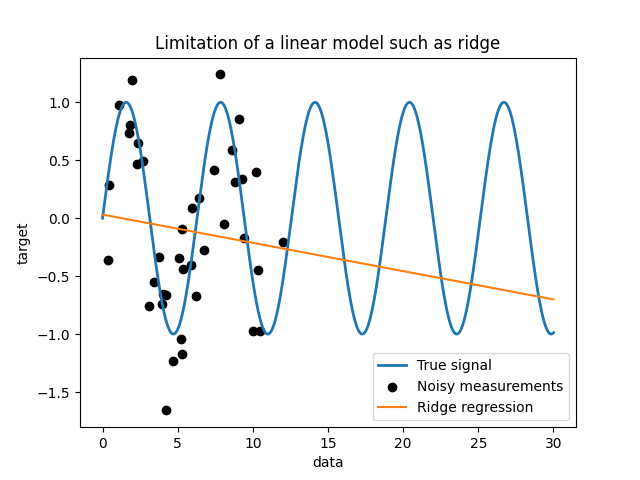
这样的岭回归器对数据拟合不足,因为它的表达能力不够。
核方法:核岭回归和高斯过程#
核岭回归
我们可以通过使用所谓的核函数使之前的线性模型更具表现力。核函数是一种从原始特征空间到另一个特征空间的嵌入。简单来说,它用于将我们的原始数据映射到一个更新且更复杂的特征空间。这个新空间是由核函数的选择明确定义的。
在我们的例子中,我们知道真实的生成过程是一个周期函数。我们可以使用 ExpSineSquared 核来恢复周期性。类 KernelRidge 将接受这样的核。
将此模型与核函数一起使用相当于使用核函数的映射函数嵌入数据,然后应用岭回归。实际上,数据并未被显式映射;而是使用“核技巧”计算高维特征空间中样本之间的点积。
因此,让我们使用这样的 KernelRidge 。
import time
from sklearn.gaussian_process.kernels import ExpSineSquared
from sklearn.kernel_ridge import KernelRidge
kernel_ridge = KernelRidge(kernel=ExpSineSquared())
start_time = time.time()
kernel_ridge.fit(training_data, training_noisy_target)
print(
f"Fitting KernelRidge with default kernel: {time.time() - start_time:.3f} seconds"
)
Fitting KernelRidge with default kernel: 0.001 seconds
plt.plot(data, target, label="True signal", linewidth=2, linestyle="dashed")
plt.scatter(
training_data,
training_noisy_target,
color="black",
label="Noisy measurements",
)
plt.plot(
data,
kernel_ridge.predict(data),
label="Kernel ridge",
linewidth=2,
linestyle="dashdot",
)
plt.legend(loc="lower right")
plt.xlabel("data")
plt.ylabel("target")
_ = plt.title(
"Kernel ridge regression with an exponential sine squared\n "
"kernel using default hyperparameters"
)
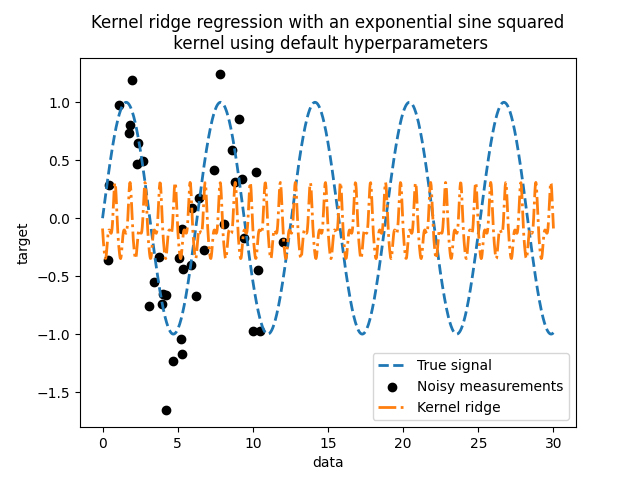
这个拟合模型不准确。实际上,我们没有设置核函数的参数,而是使用了默认参数。我们可以检查这些参数。
kernel_ridge.kernel
ExpSineSquared(length_scale=1, periodicity=1)
我们的核函数有两个参数:长度尺度和周期性。对于我们的数据集,我们使用 sin 作为生成过程,这意味着信号具有 \(2 \pi\) 的周期性。参数的默认值为 \(1\) ,这解释了我们模型预测中观察到的高频。
类似的结论也可以从长度尺度参数中得出。因此,这告诉我们需要调整核函数参数。我们将使用随机搜索来调整核岭模型的不同参数: alpha 参数和核函数参数。
from scipy.stats import loguniform
from sklearn.model_selection import RandomizedSearchCV
param_distributions = {
"alpha": loguniform(1e0, 1e3),
"kernel__length_scale": loguniform(1e-2, 1e2),
"kernel__periodicity": loguniform(1e0, 1e1),
}
kernel_ridge_tuned = RandomizedSearchCV(
kernel_ridge,
param_distributions=param_distributions,
n_iter=500,
random_state=0,
)
start_time = time.time()
kernel_ridge_tuned.fit(training_data, training_noisy_target)
print(f"Time for KernelRidge fitting: {time.time() - start_time:.3f} seconds")
Time for KernelRidge fitting: 1.419 seconds
现在拟合模型在计算上更加昂贵,因为我们必须尝试几种超参数组合。我们可以查看找到的超参数以获得一些直觉。
kernel_ridge_tuned.best_params_
{'alpha': np.float64(1.991584977345022), 'kernel__length_scale': np.float64(0.7986499491396734), 'kernel__periodicity': np.float64(6.6072758064261095)}
查看最佳参数,我们发现它们与默认值不同。我们还看到周期性更接近预期值:\(2 \pi\) 。现在我们可以检查调整后的核岭回归的预测结果。
Time for KernelRidge predict: 0.001 seconds
plt.plot(data, target, label="True signal", linewidth=2, linestyle="dashed")
plt.scatter(
training_data,
training_noisy_target,
color="black",
label="Noisy measurements",
)
plt.plot(
data,
predictions_kr,
label="Kernel ridge",
linewidth=2,
linestyle="dashdot",
)
plt.legend(loc="lower right")
plt.xlabel("data")
plt.ylabel("target")
_ = plt.title(
"Kernel ridge regression with an exponential sine squared\n "
"kernel using tuned hyperparameters"
)
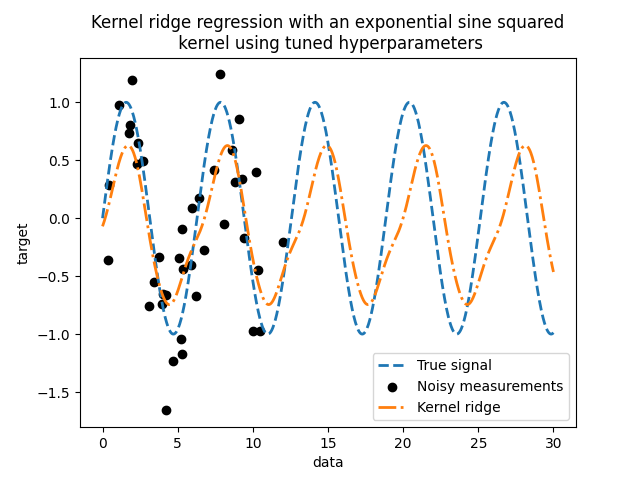
我们得到了一个更准确的模型。我们仍然观察到一些错误,主要是由于添加到数据集中的噪声所致。
高斯过程回归
现在,我们将使用 GaussianProcessRegressor 来拟合相同的数据集。在训练高斯过程时,核的超参数会在拟合过程中进行优化。无需进行外部的超参数搜索。这里,我们创建了一个比核岭回归器稍微复杂一点的核:我们添加了一个 WhiteKernel ,用于估计数据集中的噪声。
from sklearn.gaussian_process import GaussianProcessRegressor
from sklearn.gaussian_process.kernels import WhiteKernel
kernel = 1.0 * ExpSineSquared(1.0, 5.0, periodicity_bounds=(1e-2, 1e1)) + WhiteKernel(
1e-1
)
gaussian_process = GaussianProcessRegressor(kernel=kernel)
start_time = time.time()
gaussian_process.fit(training_data, training_noisy_target)
print(
f"Time for GaussianProcessRegressor fitting: {time.time() - start_time:.3f} seconds"
)
Time for GaussianProcessRegressor fitting: 0.016 seconds
训练高斯过程的计算成本远低于使用随机搜索的核岭回归。我们可以检查我们计算的核参数。
gaussian_process.kernel_
0.675**2 * ExpSineSquared(length_scale=1.34, periodicity=6.57) + WhiteKernel(noise_level=0.182)
确实,我们看到参数已经被优化。查看 periodicity 参数,我们发现了一个接近理论值 \(2 \pi\) 的周期。现在我们可以看看我们模型的预测。
Time for GaussianProcessRegressor predict: 0.001 seconds
plt.plot(data, target, label="True signal", linewidth=2, linestyle="dashed")
plt.scatter(
training_data,
training_noisy_target,
color="black",
label="Noisy measurements",
)
# Plot the predictions of the kernel ridge
plt.plot(
data,
predictions_kr,
label="Kernel ridge",
linewidth=2,
linestyle="dashdot",
)
# Plot the predictions of the Gaussian process regressor
plt.plot(
data,
mean_predictions_gpr,
label="Gaussian process regressor",
linewidth=2,
linestyle="dotted",
)
plt.fill_between(
data.ravel(),
mean_predictions_gpr - std_predictions_gpr,
mean_predictions_gpr + std_predictions_gpr,
color="tab:green",
alpha=0.2,
)
plt.legend(loc="lower right")
plt.xlabel("data")
plt.ylabel("target")
_ = plt.title("Comparison between kernel ridge and gaussian process regressor")
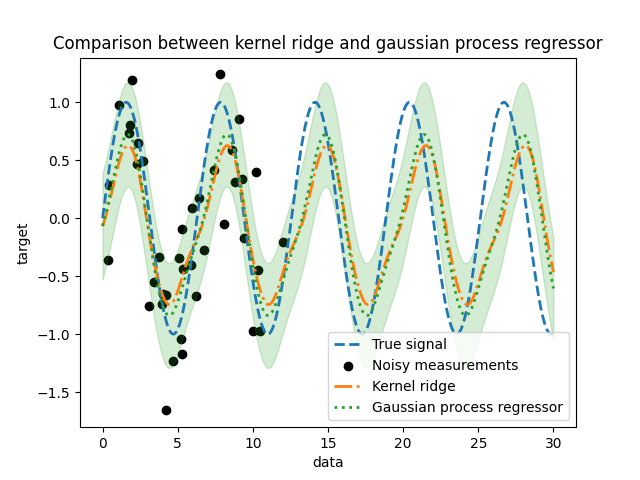
我们观察到核岭回归和高斯过程回归器的结果非常接近。然而,高斯过程回归器还提供了核岭回归无法提供的不确定性信息。由于目标函数的概率论表述,高斯过程可以输出标准差(或协方差)以及目标函数的均值预测。
然而,这需要付出代价:使用高斯过程计算预测的时间更长。
最终结论#
我们可以对这两种模型的外推能力给出一个最终结论。实际上,我们只提供了信号的开头作为训练集。使用周期性核函数迫使我们的模型重复训练集中发现的模式。结合这种核函数信息以及两种模型的外推能力,我们观察到模型将继续预测正弦模式。
高斯过程允许将核函数组合在一起。因此,我们可以将指数正弦平方核与径向基函数核结合起来。
from sklearn.gaussian_process.kernels import RBF
kernel = 1.0 * ExpSineSquared(1.0, 5.0, periodicity_bounds=(1e-2, 1e1)) * RBF(
length_scale=15, length_scale_bounds="fixed"
) + WhiteKernel(1e-1)
gaussian_process = GaussianProcessRegressor(kernel=kernel)
gaussian_process.fit(training_data, training_noisy_target)
mean_predictions_gpr, std_predictions_gpr = gaussian_process.predict(
data,
return_std=True,
)
plt.plot(data, target, label="True signal", linewidth=2, linestyle="dashed")
plt.scatter(
training_data,
training_noisy_target,
color="black",
label="Noisy measurements",
)
# Plot the predictions of the kernel ridge
plt.plot(
data,
predictions_kr,
label="Kernel ridge",
linewidth=2,
linestyle="dashdot",
)
# Plot the predictions of the Gaussian process regressor
plt.plot(
data,
mean_predictions_gpr,
label="Gaussian process regressor",
linewidth=2,
linestyle="dotted",
)
plt.fill_between(
data.ravel(),
mean_predictions_gpr - std_predictions_gpr,
mean_predictions_gpr + std_predictions_gpr,
color="tab:green",
alpha=0.2,
)
plt.legend(loc="lower right")
plt.xlabel("data")
plt.ylabel("target")
_ = plt.title("Effect of using a radial basis function kernel")
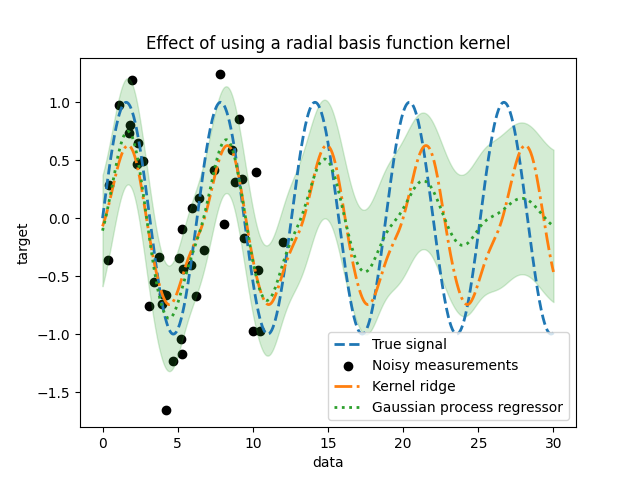
使用径向基函数核的效果会减弱周期性效应,因为在训练中没有样本可用。随着测试样本远离训练样本,预测值会趋向于它们的均值,并且它们的标准差也会增加。
Total running time of the script: (0 minutes 1.783 seconds)
Related examples