1.2. 线性判别分析和二次判别分析#
线性判别分析(LinearDiscriminantAnalysis )和二次判别分析(QuadraticDiscriminantAnalysis )是两种经典的分类器,正如它们的名字所示,分别具有线性和二次决策面。
这些分类器因其具有封闭形式的解,可以轻松计算,本质上是多类别的,已在实践中证明有效,并且没有需要调整的超参数而受到青睐。
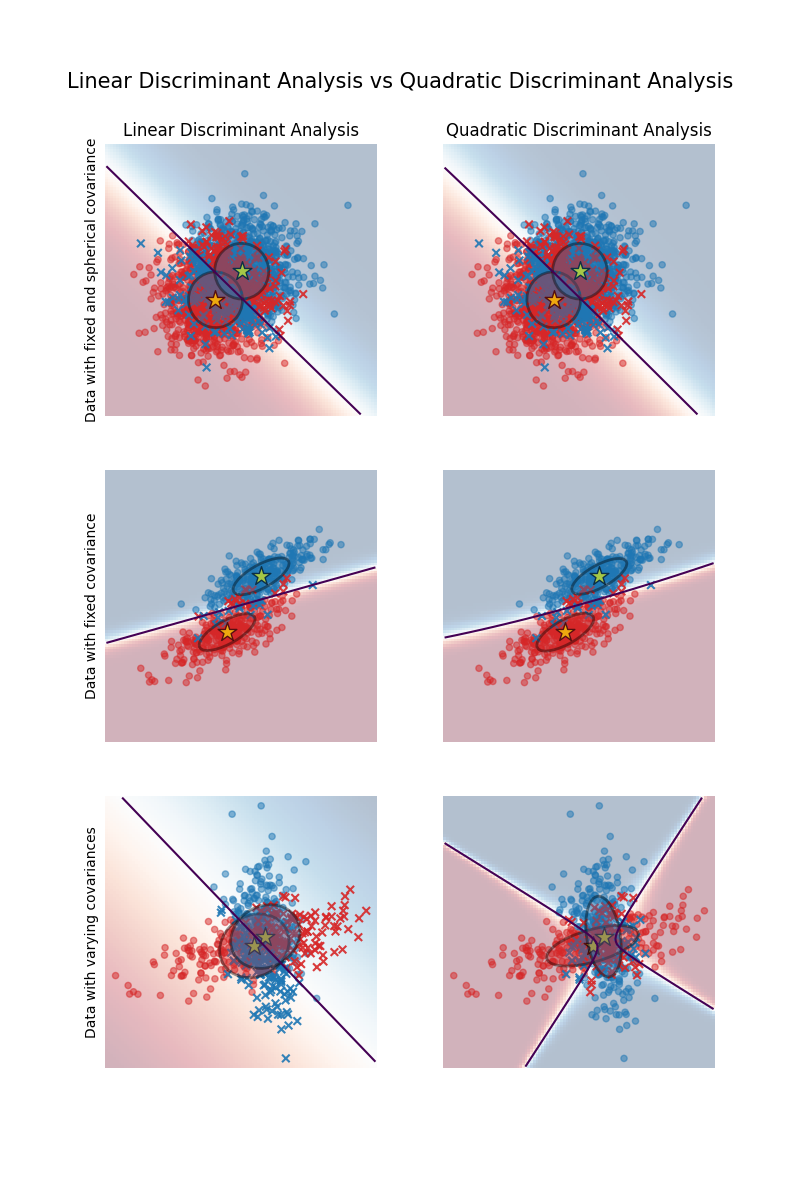
该图显示了线性判别分析和二次判别分析的决策边界。底部行表明,线性判别分析只能学习线性边界,而二次判别分析可以学习二次边界,因此更加灵活。
示例
线性判别分析和二次判别分析的协方差椭球体 : 在合成数据上比较LDA和QDA。
1.2.1. 使用线性判别分析进行降维#
LinearDiscriminantAnalysis 可以用于执行监督降维,通过将输入数据投影到一个线性子空间,该子空间由最大化类别间分离的方向组成(具体含义在下面的数学部分讨论)。输出的维度必然小于类别的数量,因此这在一般情况下是一个相当强的降维,并且仅在多类别设置中有意义。
这是在 transform 方法中实现的。可以通过 n_components 参数设置所需的维度。该参数对 fit 和 predict 方法没有影响。
示例
LDA和PCA在鸢尾花数据集上的二维投影比较 : 比较 LDA 和 PCA 对鸢尾花数据集的降维效果
1.2.2. LDA 和 QDA 分类器的数学表述#
LDA 和 QDA 都可以从简单的概率模型中推导出来,这些模型对每个类别 \(k\) 的数据类条件分布 \(P(X|y=k)\) 进行建模。然后可以通过使用贝叶斯规则获得预测,对于每个训练样本 \(x \in \mathcal{R}^d\) :
我们选择最大化这个后验概率的类别 \(k\) 。
更具体地说,对于线性和二次判别分析,\(P(x|y)\) 被建模为具有密度的多元高斯分布:
其中 \(d\) 是特征的数量。
1.2.2.1. QDA#
根据上述模型,后验的对数为:
其中常数项 \(Cst\) 对应于分母 \(P(x)\) ,以及来自高斯分布的其他常数项。预测的类别是最大化这个对数后验的类别。
Note
与高斯朴素贝叶斯的关系
如果在 QDA 模型中假设协方差矩阵是 diagonal 的,那么就假设输入在每个类别中是条件独立的,
和由此产生的分类器等价于高斯朴素贝叶斯分类器 naive_bayes.GaussianNB 。
1.2.2.2. LDA#
LDA 是 QDA 的一个特例,其中假设每个类的高斯分布共享相同的协方差矩阵:对于所有 \(k\) ,\(\Sigma_k = \Sigma\) 。这减少了对数后验概率为:
其中 \((x-\mu_k)^t \Sigma^{-1} (x-\mu_k)\) 对应于样本 \(x\) 和均值 \(\mu_k\) 之间的 马氏距离 。马氏距离表示 \(x\) 与 \(\mu_k\) 的接近程度,同时考虑了每个特征的方差。因此,我们可以将 LDA 解释为将 \(x\) 分配给在马氏距离上最接近的类别,同时考虑类别先验概率。
LDA 的对数后验概率也可以写成 [3]:
其中 \(\omega_k = \Sigma^{-1} \mu_k\) 和 \(\omega_{k0} = -\frac{1}{2} \mu_k^t\Sigma^{-1}\mu_k + \log P (y = k)\) 。这些量分别对应于 coef_ 和 intercept_ 属性。
从上述公式可以看出,LDA 具有线性决策面。在 QDA 的情况下,高斯分布的协方差矩阵 \(\Sigma_k\) 没有假设,导致二次决策面。更多细节请参见 [1]。
1.2.3. LDA 降维的数学表述#
首先注意,K 个均值 \(\mu_k\) 是 \(\mathcal{R}^d\) 中的向量,并且它们位于一个维度最多为 \(K - 1\) 的仿射子空间 \(H\) 中(2 个点位于一条线上,3 个点位于一个平面上,等等)。
如上所述,我们可以将 LDA 解释为将 \(x\) 分配给在马氏距离上最接近的类别,同时考虑类别先验概率。 其均值 \(\mu_k\) 在马氏距离意义上最接近,同时考虑类别先验概率。或者,LDA 等价于首先对数据进行 球化 处理,使得协方差矩阵为单位矩阵,然后根据欧氏距离(仍然考虑类别先验概率)将 \(x\) 分配给最近的均值。
在这个 d 维空间中计算欧氏距离等价于首先将数据点投影到 \(H\) 中,并在那里计算距离(因为其他维度将对每个类别的距离贡献相等)。换句话说,如果 \(x\) 在原始空间中最接近 \(\mu_k\) ,那么在 \(H\) 中也是如此。这表明,在 LDA 分类器中隐含着通过线性投影到 \(K-1\) 维空间的降维。
我们可以进一步降低维度,通过投影到线性子空间 \(H_L\) 上,该子空间最大化投影后 \(\mu^*_k\) 的方差(实际上,我们正在对变换后的类别均值 \(\mu^*_k\) 进行一种 PCA)。这个 \(L\) 对应于 transform 方法中使用的 n_components 参数。更多细节请参见 [1]。
1.2.4. 收缩和协方差估计器#
收缩是一种正则化方法,用于在训练样本数量远小于特征数量的情况下改进协方差矩阵的估计。在这种情况下,经验样本协方差是一个糟糕的估计器,而收缩有助于提高分类器的泛化性能。可以通过将 LinearDiscriminantAnalysis 类的 shrinkage 参数设置为 ‘auto’ 来使用收缩 LDA。这将自动在解析上确定最佳收缩参数。
遵循Ledoit和Wolf引入的引理[2]_的方法。请注意,目前仅当将 solver 参数设置为’lsqr’或’eigen’时,收缩才有效。
shrinkage参数也可以在0和1之间手动设置。特别是,值为0对应于无收缩(这意味着将使用经验协方差矩阵),值为1对应于完全收缩(这意味着将使用方差的对角矩阵作为协方差矩阵的估计)。将此参数设置为这两个极值之间的值将估计协方差矩阵的收缩版本。
Ledoit和Wolf的协方差收缩估计器并不总是最佳选择。例如,如果数据的分布是正态分布,Oracle Approximating Shrinkage估计器:class:sklearn.covariance.OAS 产生的均方误差比使用shrinkage=”auto”的Ledoit和Wolf公式给出的要小。在LDA中,假设数据在给定类别下是高斯分布的。如果这些假设成立,使用带有OAS协方差估计器的LDA将比使用Ledoit和Wolf或经验协方差估计器产生更好的分类准确性。
可以使用:class:discriminant_analysis.LinearDiscriminantAnalysis 类的 covariance_estimator 参数选择协方差估计器。协方差估计器应具有:term:fit 方法和 covariance_ 属性,就像:mod:sklearn.covariance 模块中的所有协方差估计器一样。
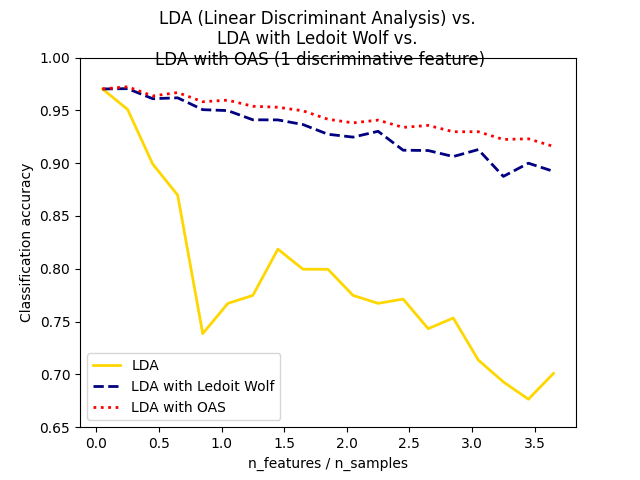
示例
用于分类的普通、Ledoit-Wolf 和 OAS 线性判别分析 : 比较使用经验、Ledoit Wolf和OAS协方差估计器的LDA分类器。
1.2.5. 估计算法#
使用LDA和QDA需要计算依赖于类别先验 \(P(y=k)\) 、类别均值 \(\mu_k\) 和协方差矩阵的对数后验。
‘svd’ 求解器是用于 LinearDiscriminantAnalysis 的默认求解器,并且是唯一可用于 QuadraticDiscriminantAnalysis 的求解器。它可以执行分类和变换(对于LDA)。由于它不依赖于协方差矩阵的计算,因此在特征数量较大的情况下,’svd’ 求解器可能更可取。’svd’ 求解器不能与收缩一起使用。对于QDA,使用SVD求解器依赖于协方差矩阵 \(\Sigma_k\) 根据定义等于 \(\frac{1}{n - 1} X_k^tX_k = \frac{1}{n - 1} V S^2 V^t\) ,其中 \(V\) 来自(中心化的)矩阵的SVD:\(X_k = U S V^t\) 。事实证明,我们可以在不显式计算 \(\Sigma\) 的情况下计算上述对数后验:通过计算 \(X\) 的SVD得到 \(S\) 和 \(V\) 就足够了。对于LDA,计算两个SVD:中心化输入矩阵 \(X\) 的SVD和类均值向量的SVD。
‘lsqr’ 求解器是一种仅适用于分类的高效算法。它需要显式计算协方差矩阵 \(\Sigma\) ,并支持收缩和自定义协方差估计器。该求解器通过求解 \(\Sigma \omega = \mu_k\) 来计算系数 \(\omega_k = \Sigma^{-1}\mu_k\) ,从而避免显式计算逆 \(\Sigma^{-1}\) 。
‘eigen’ 求解器基于类间散布与类内散布比的优化。它可以用于分类和变换,并支持收缩。然而,’eigen’ 求解器需要计算协方差矩阵,因此可能不适用于具有大量特征的情况。
参考文献