DecisionTreeEncoder#
分类编码是将分类特征的字符串转换为数字的过程。常见的做法是用序号、计数、频率或目标均值替换类别。
我们也可以用基于该类别值的决策树所做的预测来替换类别。
该过程包括使用单一特征拟合决策树来预测目标。决策树将尝试在这些变量之间找到一种关系(如果存在),然后我们将使用这些预测作为映射来替换类别。
这种方法的优势在于,它在编码过程中捕捉了变量之间的一些关系信息。如果分类特征与目标之间存在关系,那么生成的编码变量将与目标具有单调关系,这对线性模型非常有用。
不利的一面是,它可能导致过拟合,并且由于我们为每个特征拟合一棵树,它会增加管道的计算复杂性。如果你计划用决策树编码你的特征,请确保你有适当的验证策略,并用正则化训练决策树。
DecisionTreeEncoder#
该 DecisionTreeEncoder() 用决策树的预测结果替换变量中的类别。
The DecisionTreeEncoder() 在底层使用 Scikit-learn 的决策树。由于这些模型无法处理非数值数据,DecisionTreeEncoder() 首先用序数替换类别,然后拟合树。
您可以选择将分类值编码为任意分配的整数,或根据每个类别的平均目标值进行排序(更多详情,请查看 OrdinalEncoder(),该编码器在 DecisionTreeEncoder() 内部使用)。您可以通过 encoding_method 参数来调节此行为。由于决策树能够识别非线性关系,实践中用任意数字替换类别应该足够了。
之后,转换器使用这个数值变量来拟合一个决策树以预测目标。最后,原始的分类变量被决策树的预测结果所替代。
在属性 encoding_dict_ 中,您将找到从类别到数值的映射。类别是原始值,数值是决策树对该类别的预测。
使用 DecisionTreeEncoder() 的动机是尝试在分类变量和目标之间创建单调关系。
Python 示例#
让我们来看一个使用泰坦尼克号数据集的例子。首先,让我们加载数据并将其分为训练集和测试集:
from sklearn.model_selection import train_test_split
from feature_engine.datasets import load_titanic
from feature_engine.encoding import DecisionTreeEncoder
X, y = load_titanic(
return_X_y_frame=True,
handle_missing=True,
predictors_only=True,
cabin="letter_only",
)
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.3, random_state=0,
)
print(X_train[['cabin', 'pclass', 'embarked']].head(10))
我们将对以下分类变量进行编码:
cabin pclass embarked
501 M 2 S
588 M 2 S
402 M 2 C
1193 M 3 Q
686 M 3 Q
971 M 3 Q
117 E 1 C
540 M 2 S
294 C 1 C
261 E 1 S
我们设置编码器以使用3折交叉验证对上述变量进行编码,并使用网格搜索来找到决策树的最佳深度(这是 DecisionTreeEncoder() 的默认行为)。在这个例子中,我们使用roc-auc指标来优化树。
encoder = DecisionTreeEncoder(
variables=['cabin', 'pclass', 'embarked'],
regression=False,
scoring='roc_auc',
cv=3,
random_state=0,
ignore_format=True)
encoder.fit(X_train, y_train)
使用 fit() 方法,DecisionTreeEncoder() 为每个变量拟合一个决策树。映射存储在 encoding_dict_ 中:
encoder.encoder_dict_
在以下输出中,我们可以看到将用于替换每个变量中每个类别的值:
{'cabin': {'M': 0.30484330484330485,
'E': 0.6116504854368932,
'C': 0.6116504854368932,
'D': 0.6981132075471698,
'B': 0.6981132075471698,
'A': 0.6981132075471698,
'F': 0.6981132075471698,
'T': 0.0,
'G': 0.5},
'pclass': {2: 0.43617021276595747,
3: 0.25903614457831325,
1: 0.6173913043478261},
'embarked': {'S': 0.3389570552147239,
'C': 0.553072625698324,
'Q': 0.37349397590361444,
'Missing': 1.0}}
现在我们可以继续将分类变量转换为数字,使用这些树的预测:
train_t = encoder.transform(X_train)
test_t = encoder.transform(X_test)
train_t[['cabin', 'pclass', 'embarked']].head(10)
我们可以在下面看到编码的变量:
cabin pclass embarked
501 0.304843 0.436170 0.338957
588 0.304843 0.436170 0.338957
402 0.304843 0.436170 0.553073
1193 0.304843 0.259036 0.373494
686 0.304843 0.259036 0.373494
971 0.304843 0.259036 0.373494
117 0.611650 0.617391 0.553073
540 0.304843 0.436170 0.338957
294 0.611650 0.617391 0.553073
261 0.611650 0.617391 0.338957
预测的舍入#
决策树的预测结果在小数点后可能有很多位小数。当这种情况发生时,阅读分类变量可能会令人困惑。我们可以控制输出的精度,以减少小数点后的位数,如下所示:
encoder = DecisionTreeEncoder(
variables=['cabin', 'pclass', 'embarked'],
regression=False,
scoring='roc_auc',
cv=3,
random_state=0,
ignore_format=True,
precision=2,
)
encoder.fit(X_train, y_train)
现在,每个类别的映射最多包含2位小数:
encoder.encoder_dict_
在以下输出中,我们可以看到将用于替换每个变量中每个类别的值:
{'cabin': {'M': 0.3,
'E': 0.61,
'C': 0.61,
'D': 0.7,
'B': 0.7,
'A': 0.7,
'F': 0.7,
'T': 0.0,
'G': 0.5},
'pclass': {2: 0.44, 3: 0.26, 1: 0.62},
'embarked': {'S': 0.34, 'C': 0.55, 'Q': 0.37, 'Missing': 1.0}}
现在我们可以继续将分类变量转换为数字,使用这些树的预测:
train_t = encoder.transform(X_train)
test_t = encoder.transform(X_test)
train_t[['cabin', 'pclass', 'embarked']].head(10)
我们可以在下面看到编码的变量:
cabin pclass embarked
501 0.30 0.44 0.34
588 0.30 0.44 0.34
402 0.30 0.44 0.55
1193 0.30 0.26 0.37
686 0.30 0.26 0.37
971 0.30 0.26 0.37
117 0.61 0.62 0.55
540 0.30 0.44 0.34
294 0.61 0.62 0.55
261 0.61 0.62 0.34
我们也可以将数据恢复为其原始表示形式,如下所示:
revert = encoder.inverse_transform(test_t)
revert[['cabin', 'pclass', 'embarked']].head(10)
在以下输出中,我们看到通过逆变换,我们从树预测中获得了原始类别:
cabin pclass embarked
1139 M 3 S
533 M 2 S
459 M 2 S
1150 M 3 S
393 M 2 S
1189 G 3 S
5 C 1 S
231 C 1 S
330 M 2 S
887 M 3 S
碰撞#
此编码器可能导致冲突。冲突是指不同类别被编码为相同数字的情况。它有助于减少基数。另一方面,如果映射没有意义,我们可能会丢失这些类别中包含的信息。
当发生冲突时,inverse_transform 将恢复到仅一个类别,因此在逆变换过程中会丢失一些原始信息。
未见类别#
未见类别是指在测试集或实时数据中出现的标签,这些标签在训练集中不存在。由于决策树是基于训练集进行训练的,因此只会存在已见类别的映射。
默认情况下,DecisionTreeEncoder() 会忽略未见过的类别,这意味着它们在编码后将被替换为 NAN。你可以指示编码器在遇到未见过的类别时抛出错误(参数 unseen)。或者,此编码器允许你设置一个任意数值来替换未见过的类别(参数 fill_value)。
单调变量#
我们之前提到,这种编码的目的是创建特征,其值与目标值单调增长。让我们来探讨一下。我们将使用房价数据集:
import matplotlib.pyplot as plt
from sklearn.datasets import fetch_openml
from sklearn.model_selection import train_test_split
from feature_engine.encoding import DecisionTreeEncoder
# Load dataset
X, y = fetch_openml(name='house_prices', version=1,
return_X_y=True, as_frame=True)
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.3, random_state=42)
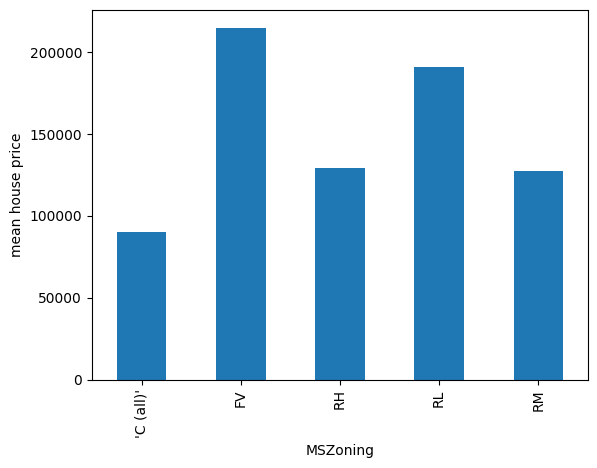
现在让我们绘制变量 MNZoning 每种类别的平均房价:
y_train.groupby(X_train["MSZoning"]).mean().plot.bar()
plt.ylabel("mean house price")
plt.show()
在下图中,我们可以看到类别当前顺序与房价之间没有单调关系:
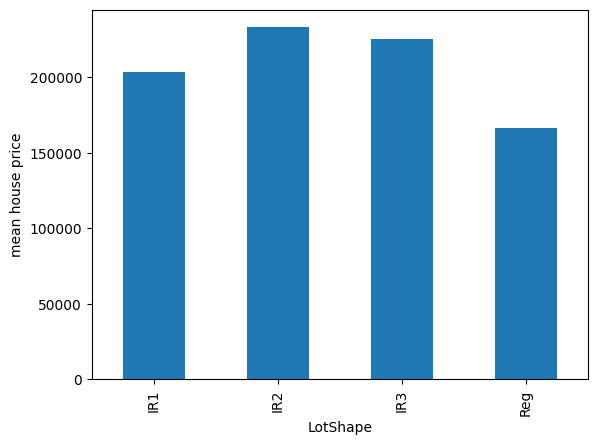
让我们探索另一个变量:
y_train.groupby(X_train["LotShape"]).mean().plot.bar()
plt.ylabel("mean house price")
plt.show()
在下图中,我们看到 LotShape 和房价之间也没有单调关系:
现在让我们使用决策树来编码这些变量:
encoder = DecisionTreeEncoder(
variables=["MSZoning", 'LotShape'],
regression=True,
cv=3,
random_state=0,
ignore_format=True,
precision=0,
)
encoder.fit(X_train, y_train)
让我们查看创建的映射:
encoder.encoder_dict_
下面我们看到的值将用于替换每个类别:
{'MSZoning': {'RL': 191179.0,
'RM': 127281.0,
'FV': 215063.0,
"'C (all)'": 90450.0,
'RH': 129380.0},
'LotShape': {'Reg': 166233.0,
'IR1': 203423.0,
'IR2': 231688.0,
'IR3': 231688.0}}
现在让我们对变量进行编码:
train_t = encoder.transform(X_train)
test_t = encoder.transform(X_test)
print(train_t[["MSZoning", 'LotShape']].head(10))
我们在以下输出中看到编码的变量:
MSZoning LotShape
135 191179.0 166233.0
1452 127281.0 166233.0
762 215063.0 166233.0
932 191179.0 203423.0
435 191179.0 231688.0
629 191179.0 166233.0
1210 191179.0 166233.0
1118 191179.0 166233.0
1084 191179.0 231688.0
158 215063.0 166233.0
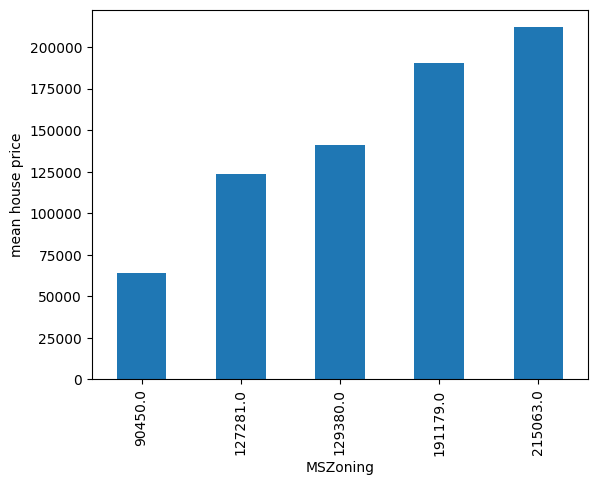
现在,让我们在编码后再次绘制每类房屋的平均价格:
y_test.groupby(test_t["MSZoning"]).mean().plot.bar()
plt.ylabel("mean house price")
plt.show()
在下图中,我们看到类别是按照与目标变量创建单调关系的方式排序的:
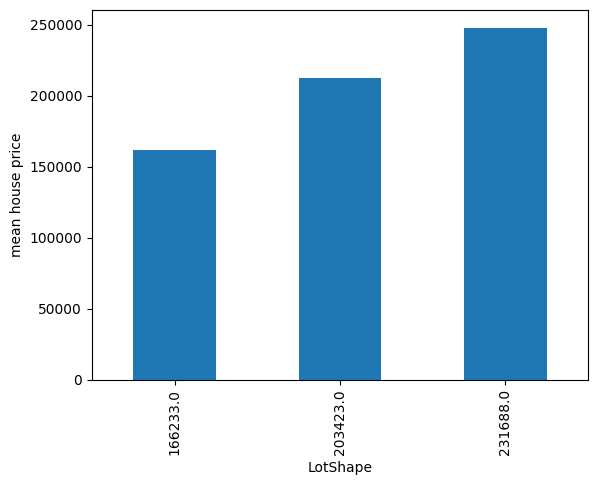
让我们为第二个变量重复一遍:
y_test.groupby(test_t["LotShape"]).mean().plot.bar()
plt.ylabel("mean house price")
plt.show()
在下图中,我们还可以看到编码后的单调关系:
注意#
并非每种编码都会导致单调关系。为此,目标和类别之间需要存在某种可以被决策树捕捉的关系。请谨慎使用。
附加资源#
在下面的笔记本中,你可以找到更多关于 DecisionTreeEncoder() 功能的详细信息以及带有编码变量的示例图:
有关此方法和其他特征工程方法的更多详细信息,请查看以下资源:

机器学习的特征工程#
或者阅读我们的书:

Python 特征工程手册#
我们的书籍和课程都适合初学者和更高级的数据科学家。通过购买它们,您正在支持 Feature-engine 的主要开发者 Sole。